






引言
大规模语言模型(LLMs)是近年来机器学习领域的一个重要突破。通过构建具有数十亿甚至数千亿参数的模型,这些模型在语言生成、问答系统、文本总结等任务中展现出超越人类水平的能力。本文深入探讨LLMs的关键原理、技术细节,以及代码实现。
在具体技术层面,我们将以Transformer架构为核心展开,结合一些流行的模型(如GPT、BERT、LLaMA),并提供从零构建一个简化Transformer模型的代码示例。
一、大规模语言模型的原理
Transformer的核心原理
Transformer模型是LLMs的基石,其架构基于注意力机制(Attention),摆脱了传统循环神经网络(RNN)的序列处理限制。
Transformer的核心模块包括:
- 自注意力机制(Self-Attention): 用于捕捉输入序列中不同位置之间的全局依赖关系。
- 前馈神经网络(Feed-Forward Network, FFN): 用于对每个序列位置进行独立的特征变换。
- 层归一化(Layer Normalization): 加速训练并稳定梯度。
以下代码实现了一个基本的Transformer块:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim=embed_size, num_heads=heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Self-Attention
attention = self.attention(x, x, x, attn_mask=mask)[0]
x = self.dropout(self.norm1(attention + x))
# Feed Forward Network
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
位置编码(Positional Encoding)
由于Transformer缺少RNN的顺序信息,需要通过位置编码将序列的位置关系注入到模型中。位置编码的公式为: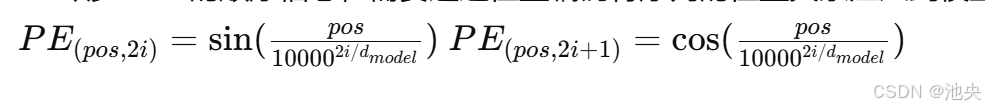 以下是位置编码的代码实现:
以下是位置编码的代码实现:
class PositionalEncoding(nn.Module):
def __init__(self, embed_size, max_len=5000):
super(PositionalEncoding, self).__init__()
self.encoding = torch.zeros(max_len, embed_size)
positions = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-torch.log(torch.tensor(10000.0)) / embed_size))
self.encoding[:, 0::2] = torch.sin(positions * div_term)
self.encoding[:, 1::2] = torch.cos(positions * div_term)
self.encoding = self.encoding.unsqueeze(0)
def forward(self, x):
# Add position encoding to input embeddings
seq_len = x.size(1)
return x + self.encoding[:, :seq_len].to(x.device)
全局模型结构
一个完整的Transformer模型包括多个Transformer块(通常为6层或12层)堆叠而成。以下是一个简化Transformer模型的代码示例:
class Transformer(nn.Module):
def __init__(self, src_vocab_size, trg_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):
super(Transformer, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = PositionalEncoding(embed_size, max_length)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size, heads, dropout=dropout, forward_expansion=forward_expansion
)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
out = self.word_embedding(x)
out = self.position_embedding(out)
for layer in self.layers:
out = layer(out, mask)
out = self.fc_out(out)
return out
二、当前LLMs技术进展
参数扩展与训练优化
- 模型扩展: GPT-4和LLaMA等模型参数数量达到数千亿甚至万亿级。参数扩展提高了模型的表达能力,但带来了训练和推理效率的挑战。
- 混合精度训练(Mixed Precision Training): 使用16位浮点数(FP16)或8位量化(INT8)来减少计算负担。
- 稀疏化(Sparsity): 通过动态稀疏技术提升模型的计算效率。
示例:使用PyTorch的混合精度训练代码。
from torch.cuda.amp import autocast, GradScaler
model = Transformer(
src_vocab_size=5000, trg_vocab_size=5000, embed_size=512,
num_layers=6, heads=8, device="cuda", forward_expansion=4,
dropout=0.1, max_length=100
).to("cuda")
optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
scaler = GradScaler()
for epoch in range(10):
for batch in dataloader: # Assuming you have a DataLoader instance
src, trg = batch
src, trg = src.to("cuda"), trg.to("cuda")
optimizer.zero_grad()
with autocast():
output = model(src, mask=None)
loss = F.cross_entropy(output.view(-1, output.size(-1)), trg.view(-1))
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
三、LLMs面临的挑战
尽管大规模语言模型(LLMs)在自然语言处理领域取得了显著进展,但它们仍面临许多挑战。以下我们将从训练资源的瓶颈、泛化能力的局限以及社会伦理的争议三个角度深入探讨。
1. 训练资源的瓶颈
训练LLMs需要巨大的计算资源、存储容量和能源投入,这不仅带来了技术难题,还对可持续发展提出了挑战。
1.1 计算需求的指数增长
大规模语言模型通常包含数十亿至数千亿个参数,例如GPT-4的参数量已达万亿级别。这种规模的模型训练涉及大量的矩阵乘法操作,对硬件的要求极高。
瓶颈与解决方案
- 计算资源不足: 即使高性能GPU(如NVIDIA A100)支持并行计算,单次完整训练仍可能耗时数月。
- 解决方案:
- 分布式训练: 通过分布式数据并行(Data Parallelism)和模型并行(Model Parallelism)技术分摊计算任务。
- 混合精度计算: 使用FP16或更低精度(如INT8)减少计算量。
- 稀疏模型: 引入稀疏技术,限制参数的活跃部分。
示例代码:使用PyTorch实现数据并行训练。
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
# 假设已经初始化分布式环境
model = Transformer(
src_vocab_size=5000, trg_vocab_size=5000, embed_size=512,
num_layers=6, heads=8, device="cuda", forward_expansion=4,
dropout=0.1, max_length=100
).to("cuda")
model = DDP(model)
optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
for epoch in range(10):
for src, trg in dataloader: # DistributedSampler需要确保数据均分
src, trg = src.to("cuda"), trg.to("cuda")
optimizer.zero_grad()
output = model(src, mask=None)
loss = F.cross_entropy(output.view(-1, output.size(-1)), trg.view(-1))
loss.backward()
optimizer.step()
1.2 数据质量与规模的矛盾
大规模模型依赖海量数据,但高质量的数据难以获取。大量数据往往包含噪声、不均衡分布,甚至可能带有偏见。
解决方案
- 数据清洗: 使用更智能的预处理工具去除噪声。
- 数据增强: 生成额外合成数据或使用低资源语言任务的数据扩充技术。
- 小样本学习: 优化模型以在较少数据上取得更好性能,如零样本学习(Zero-Shot)和少样本学习(Few-Shot)。
2. 泛化能力的局限
2.1 缺乏真实理解
虽然LLMs在许多任务上表现优秀,但它们在某些情况下仍显得机械化,难以真正“理解”文本。尤其是在面对罕见现象、复杂推理或多领域问题时,泛化能力明显不足。
症状
- 上下文依赖: 模型可能无法根据历史上下文生成合理的回答。
- 领域适应性差: 在技术性领域或小众领域表现有限。
解决方案
- 微调(Fine-Tuning): 针对特定任务或领域微调模型以提高性能。
- 提示优化(Prompt Engineering): 利用更精确的输入设计引导模型更好地输出结果。
- 多模态模型: 结合视觉、音频等其他模态的信息提升语言理解能力。
示例代码:基于微调的自定义训练。
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 自定义训练数据
data = [{"input_text": "机器学习的定义是", "output_text": "一种研究算法使机器具备智能行为的学科。"}]
def preprocess_function(data):
return tokenizer(data["input_text"], text_target=data["output_text"], padding="max_length", truncation=True)
train_data = [preprocess_function(item) for item in data]
trainer = Trainer(
model=model,
train_dataset=train_data,
args=TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
save_steps=10,
save_total_limit=2,
),
)
trainer.train()
2.2 可解释性不足
LLMs通常被视为“黑箱”模型,其内部工作原理难以解析,给结果验证和错误分析带来了困难。
解决方案
- 注意力机制可视化: 提供模型生成过程中自注意力权重的可视化分析。
- 特征归因方法: 使用SHAP或LIME等工具揭示输入特征对输出的贡献。
3. 社会伦理问题
随着LLMs的广泛应用,其潜在的社会影响和伦理问题也愈发显著。
3.1 偏见与歧视
LLMs在训练时可能从数据中继承偏见(如性别、种族偏见),并在生成文本中放大这些偏见。
实例
- 语言偏见: 模型可能在性别词汇上表现出偏向,如将“工程师”关联为男性。
解决方案
- 去偏算法: 在训练中引入去偏正则化或对抗性数据。
- 人类校正: 通过人类反馈迭代改进模型输出。
示例:结合人类反馈微调(Reinforcement Learning with Human Feedback, RLHF)。
from transformers import PPOTrainer, PPOConfig
config = PPOConfig(model_name_or_path="gpt2", learning_rate=1e-5)
ppo_trainer = PPOTrainer(config)
# 模拟人类反馈
human_feedback_data = [
{"input": "Describe a scientist.", "output": "A man in a lab coat.", "reward": -1},
{"input": "Describe a scientist.", "output": "A person working in a lab.", "reward": 1},
]
# 训练改进模型
ppo_trainer.train(human_feedback_data)
3.2 滥用风险
大规模语言模型可以生成高质量的虚假信息(Deep Fake)或被用于恶意用途,例如:
- 生成虚假新闻: 可能助长信息传播中的不实内容。
- 自动化网络攻击: 用于生成钓鱼邮件、恶意代码等。
应对措施
- 模型使用限制: 严格控制模型的访问权限,仅授权可信用户。
- 内容检测: 开发LLM生成内容的检测工具。
结论
尽管当前LLMs在技术上取得了突破性进展,但在训练资源、泛化能力和社会伦理方面仍然面临重大挑战。为应对这些问题,研究者和开发者需要持续探索更高效、更公平和更可控的技术路径。
未来,随着模型架构的优化、训练方法的改进以及伦理政策的完善,LLMs有望在科学研究、教育、医疗等更多领域发挥积极作用,同时降低潜在风险。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











