






1. 为什么要使用索引
索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教科书的目录,通过目录可以找到对应文章的页面,而不用一页一页从头翻到尾.MySQL也是一样的道理.在进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据,如果不符合,则需要全表扫描,一条一条的查找记录,直到查找到目标数据.
为了减少磁盘的I/O次数,提高查询效率,我们就需要用到索引.
2. 索引及其优点
(1). 索引
1). 索引的定义
索引是帮助MySQL高效获取数据的数据结构.
2). 本质
索引是数据结构. 可以简单理解为"排好序的快速查找数据结构". 满足特定的查找算法. 这些数据以某种方式指向数据,这样就可以在这些数据结构的基础上实现高效的查找算法.
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同.(后面我们知道,像InnoDb, MyISAM等存储引擎的索引底层是b+树,而Memory的索引底层是哈希表). 并且每种存储索引不一定支持所有索引类型. 同时,存储引擎可以定义每个表的最大索引数和最大索引长度. 所有索引引擎支持每个表至少16个索引,总索引长度至少256字节.
(2). 优点
- 类似大学图书馆建书目索引. 提高数据检索效率,降低磁盘的i/o次数. 后面我们知道,与磁盘交互的基本单位是页,使用索引时i/o次数是b+树的高度,时间复杂度O(logn),全表扫描的时间复杂度为O(n).
- 通过创建唯一索引,可以保证数据库表中每一行数据记录的唯一性.
- 在实现数据的参考完整性方面,可以加速表与表之间的连接. 换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询速度.
- 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间,降低了CPU的消耗.
(3). 缺点
增加索引也有很多不利的地方.
- 创建和维护索引需要耗费时间,并且随着数据量的增加,所耗费的时间也会增加.
- 索引需要占用磁盘空间,除了数据表占数据空间外,每个索引还需要占用一定的物理空间,存储在磁盘上. 如果有大量的索引,索引文件可能比数据文件更快到达最大文件尺寸.
- 虽然索引大大提高了查询效率,同时会降低更新表的速度. 当对表数据进行增加,删除修改的时候,索引也要动态的维护,这样就降低了数据的维护速度.以InnoDB存储引擎为例,索引底层是b+树,当增加修改删除一条记录时,可能会改变树的结构,让树重新排序,当数据量非常大的时候,将会非常消耗内存.
索引可以提高查询速度,但会影响插入记录的速度.这种情况下,我们可以先删除表中的索引,然后插入数据完成后,再创建索引.
3. InnoDB中索引的推演
(1). 索引之前的查找
比如 : select 列名 from 表名 where 列名=xxx
1). 在一个页中的查找.
假设目前表中的数据非常少,所有数据都可以被放到一个页中(一个页的存储大小为16kb),在查找记录的时候可以根据搜索条件的不同分为两种情况.
- 以主键为搜索条件.可以在页目录(页目录这个结构以后再讲)中使用二分法快速定位到对应的槽slot,然后再遍历该槽对应分组中的记录即可以快速找到指定的记录.
- 以其他列作为搜索条件.因为在数据页中没有对非主键列建立所谓的页目录,所以我们无法通过二分法快速定位到相对应的槽,这种情况只有从最小记录开始依次遍历单链表中的每一条记录.(记录页中,记录以单链表的结构存储在一起,即一条记录不仅存储了列的真实数据,还存储了指向下一条记录的指针,可以通过这个指针找到对应的下一条记录,涉及到行格式,以后再讲)然后依次比对是否符合.这样的效率是非常低的.
2). 在多个页中查找.
大多数情况下我们表中存放的记录是非常多的,需要好多页来存放我们的数据.在多个页中查找记录可以分为两个步骤.
1. 定位到目标记录所在的页.
2. 从所在的页中查找相应的记录.
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们不能快速定位到目标记录所在的页,所以只能从第一个页开始沿着双向链表一直找下去,在每个页中根据上述查找方法去查找目标记录.因为要遍历所有的数据页,这种方式是非常耗时的.
(2). 设计索引
主键列聚簇索引.
CREATE TABLE index_demo(
c1 INT,
c2 INT,
c3 varchar(10),
PRIMARY KEY(c1)
) ROW_FORMAT=COMPACT;依据主键列c1创建了聚簇索引.记录行格式为COMPACT.规定了一条记录的组成部分为变长字段长度列表,null值列表,记录头信息,以及真实的数据.其中记录头信息包含record_type和next_record字段.下图简化了行格式,略去不必要的信息.
- record_type : 记录有信息的一项属性,表示记录的类型.0表示普通记录,1表示目录项记录,2表示最小记录,3表示最大记录.
- next_record : 记录头信息的一项属性. 表示下一条记录的地址相对于本记录地址的偏移量,即指针.
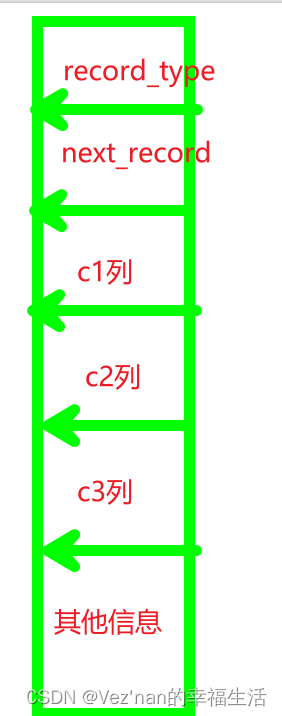
把一些记录放在页里的示意图就是 :
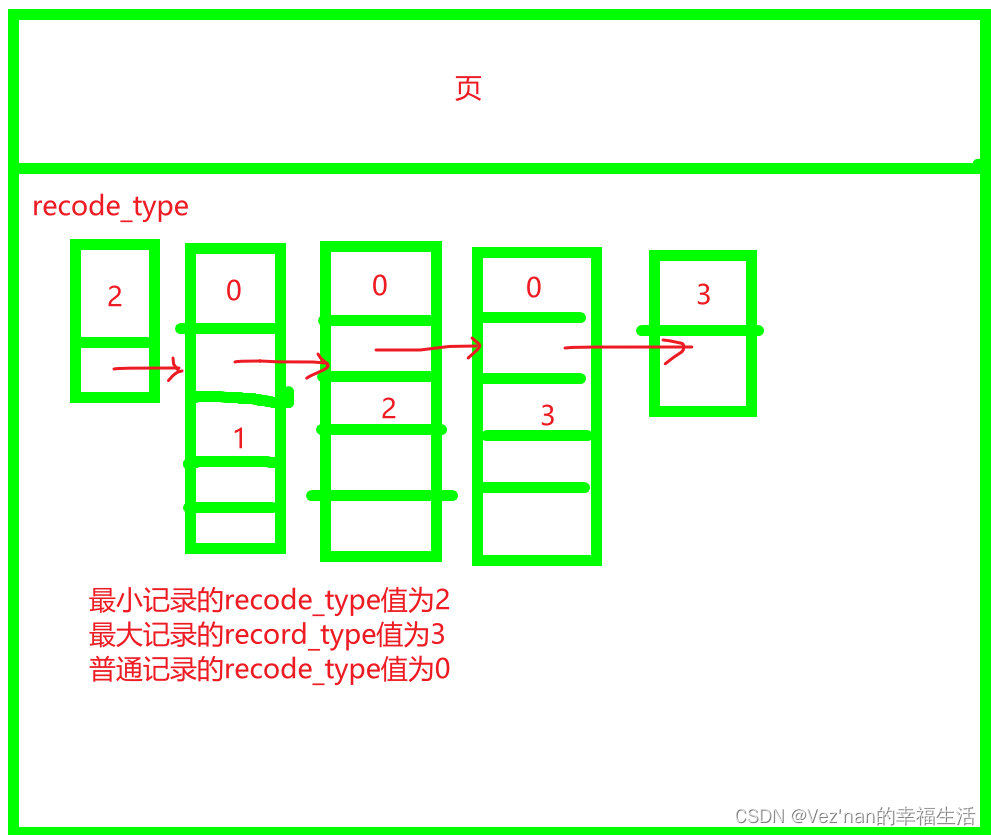
依据主键值的大小串成一个单向链表.
此时我们insert插入数据.假设一个页只能存放三条记录,只是假设,实际上可能存放很多条记录.
INSERT INTO index_demo
VALUES (1, 10, 'yy'),
(3, 100, 'xx'),
(2, 1000, 'zz');即使我们添加的记录主键值并不是递增的,但也会调整为主键值递增的.如果我们此时再增加一条主键值为2的记录.由于要求下一条数据页中的记录大于上一条数据页中的记录,所以在插入主键值为2的记录时需要伴随一次记录移动,也就是把主键值为3的记录移动到主页11,把主键为2的记录移动到页10.这个过程称为页的分裂.
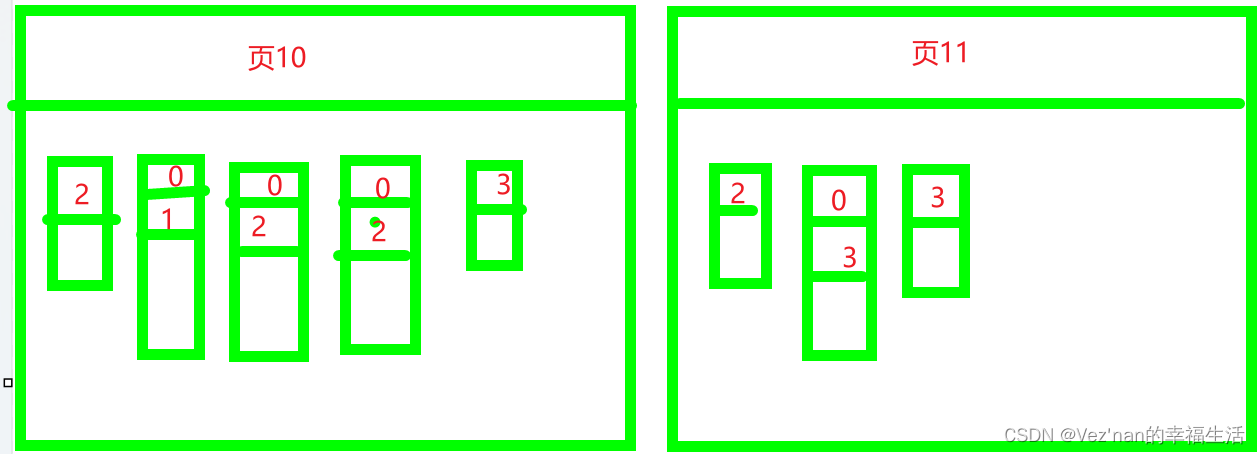
给所有页建立目录项.
这些16kb的页在物理存储上是双向链表,是不连续的,所以如果想从这么多页中根据主键值快速定位某些记录所在的页,我们需要给它们做个目录,每个页对应一个目录项,每个目录项包含两个部分.
- 页用户记录的最小的主键值(也可以是最大),我们用key来表示.
- 页号,我们用page_no表示.
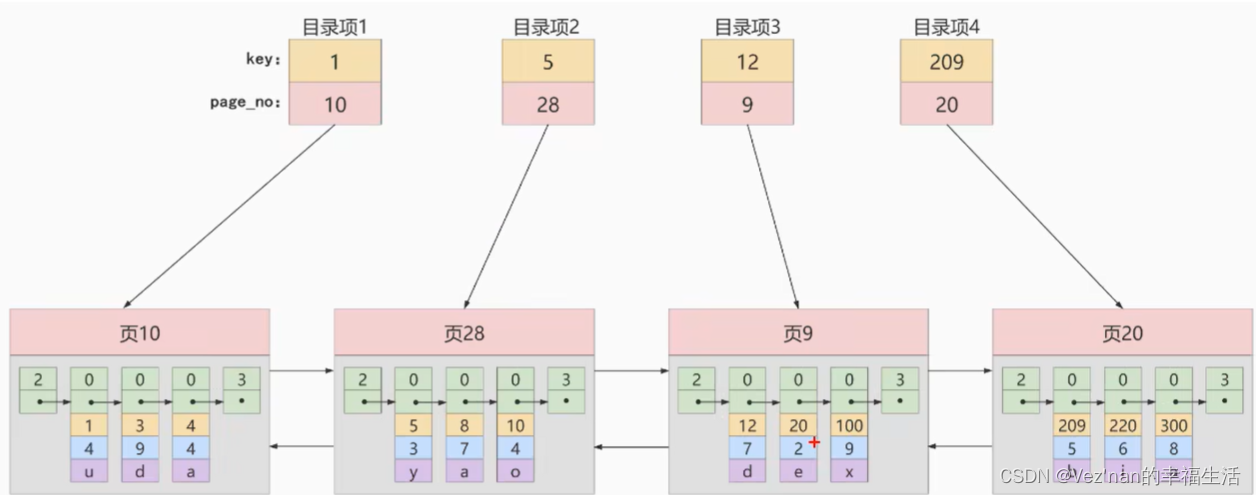
4. InnoDB中索引的方案
可以为目录项建立目录页.目录项之间以单向链表存储.
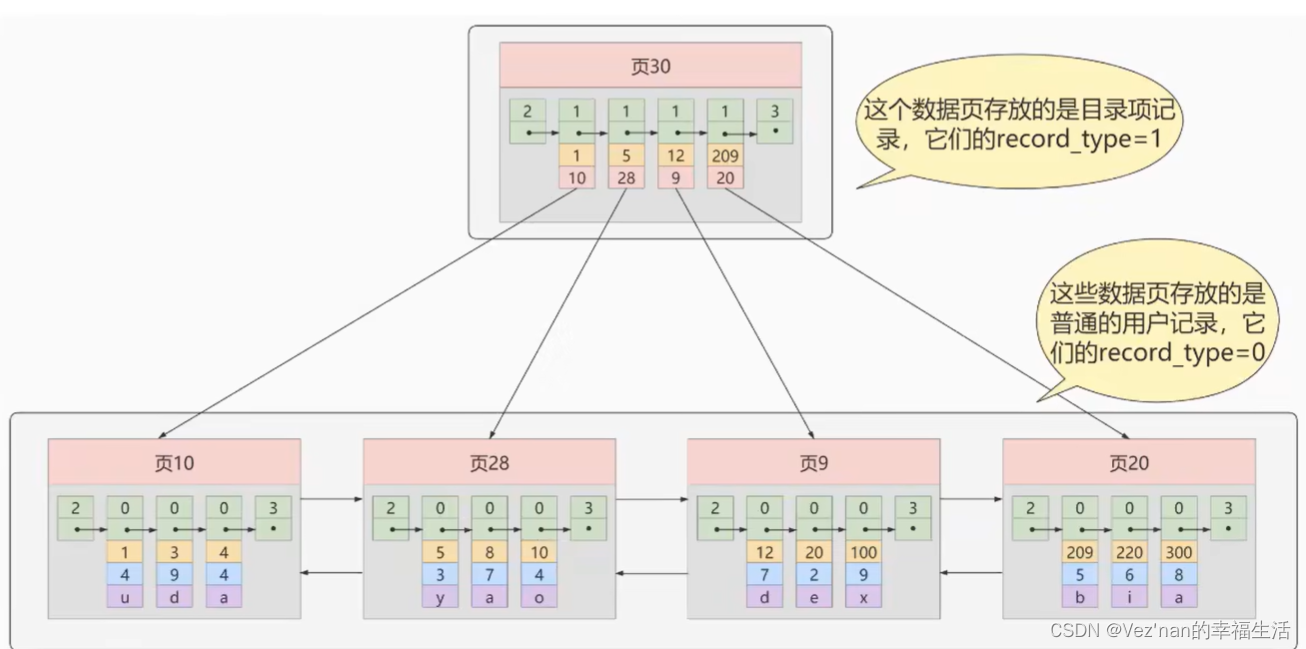
从图中可以看出,我们新分配了一个页号为30的页专门存储目录项记录.
目录项记录与普通用户记录的不同点.
- 目录项记录是record_type是1,而普通记录的是0.
- 目录项记录只有主键值和页的编号两个列,而普通用户的有些列是自己定义的,还有些列是InnoDB自己添加的隐藏列.比如大名鼎鼎的row_id.
目录项记录与普通用户记录的相同点.
- 二者使用的都是一样的数据页,都会为主键值生成页目录,从而在按照主键值进行查找时可以使用二分法来加快查找速度.
虽然说目录项记录只存储主键值和对应的页号,但不论怎么说,一个页只有16kb大小,存放的目录项记录也是有限的,如果表数据太大,以至于一个数据页不足以存放所有的目录项记录.所以有必要再产生目录页.
这些目录页是不连续的,如果我们表中数据记录非常多则会产生很多的存储目录项记录的页,那么我们怎么根据主键值快速定位一个存储目录项记录的页呢?所以有必要为这些存储目录项记录的页再生成一个更高级的目录.就像是一个多级目录,大目录里嵌套小目录.小目录里才是实际的数据.
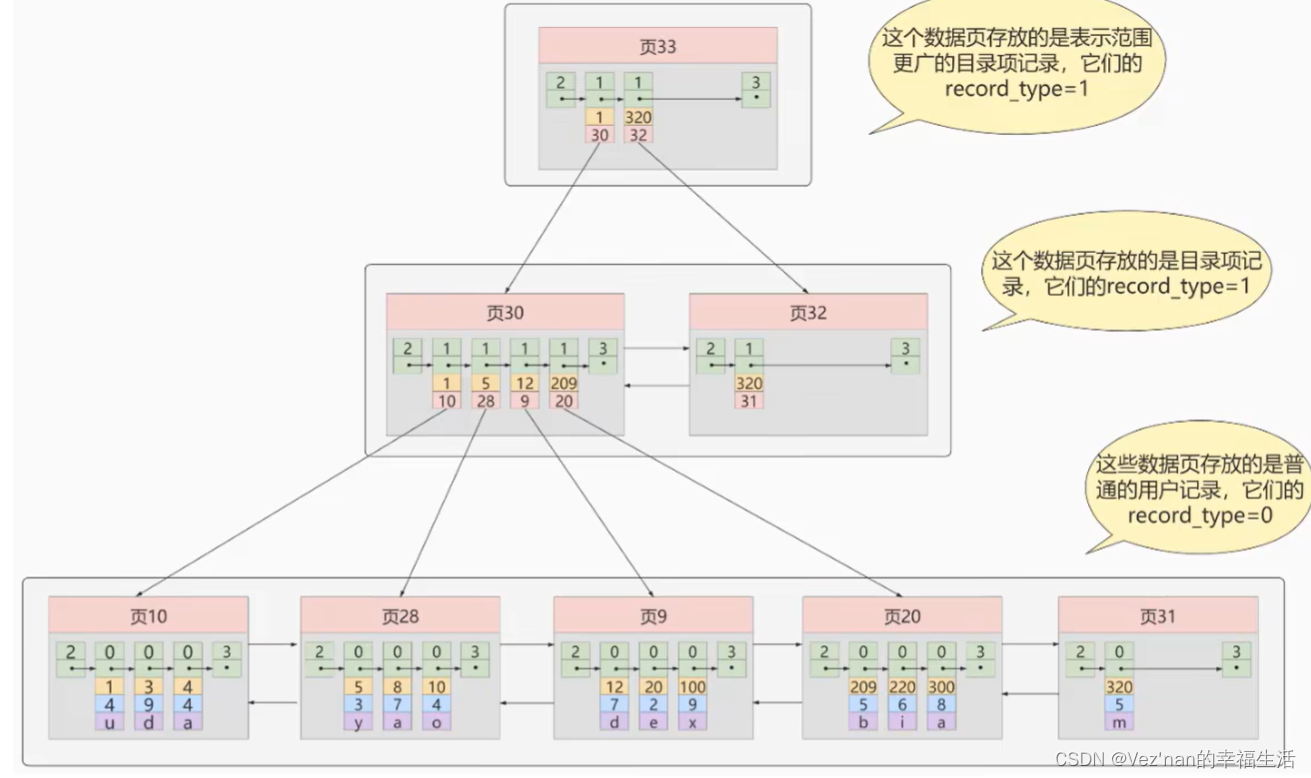
我们可以用图来描述索引.
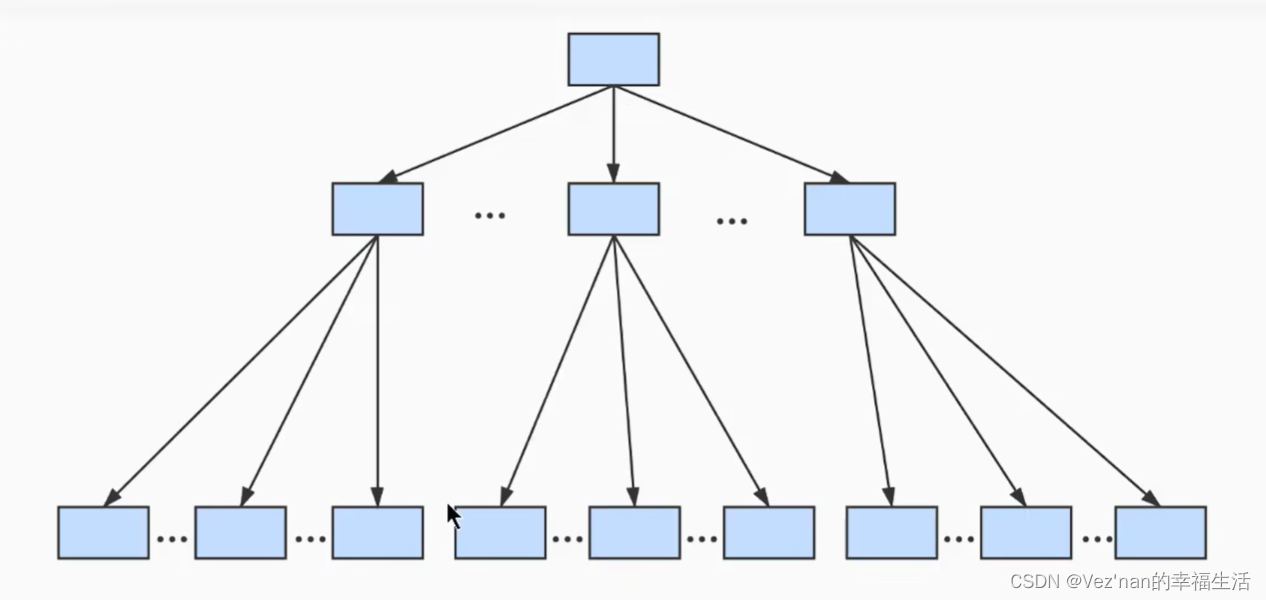
叶子节点存放真实的数据,非叶子节点存放目录项.
页与页之间以双向链表存储,记录与记录(不论是数据项记录还是目录项记录)之间是以单向链表存储.















 3366
3366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









