






关联规则综述
基本概念
关联分析用于描述多个变量之间的关联,如果两个或者多个变量之间存在一定的关联,那么其中一个变量的状态就能通过其他变量进行预测。

自然界中某种事物发生时其他事物也会发生,则这种联系称之为关联。
反映事件之间依赖或关联的知识称为关联型知识(又称依赖关系)。
关联分析的目的是找出数据集合中隐藏的关联网,是离散变量因果分析的基础。
关联规则的原理
支持度与置信度
- 设关联规则: A=>B,{A}或 {B}为项集,项集{A} 可以认为为前因,项集 {B}可以认为为后果。
- 支持度表示的是两个事件同时发生的概率,也就是表示同时包含A、B事务占总事务的百分比。
- 置信度是预测性指标,是在前因发生的条件下,后果发生的概率,表示同时发生A、B事务的概率占事务 A发生概率的百分比
- 支持度为对称指标,即{A,B}的支持度 与{B,A}的支持度都 一样,
- 而置信度为非对称指标,二者不同,即 置信度(A=>B)与 置信度 (B=>A)不一样。
支持度与置信度案例
啤酒和尿布案例
假设有1000条交易记录,其中有100条交易同时包含啤酒和尿布,假设有100条交易中有30条交易中包含了啤酒,其中有10条交易同时购买了尿布,计算支持度和置信度。
- 支持度可以表示为:
支持度 (啤酒,尿布) = (啤酒和尿布同时出现的次数) / (总的交易记录数)
100/1000=0.1
- 置信度可以表示为:
置信度 (啤酒 > 尿布) = (啤酒和尿布同时出现的次数) / (啤酒出现的次数)
10/30=0.33
- 通过计算支持度和置信度,可以得出结论:购买尿布的顾客中,有10%的顾客也购买了啤酒,并且购买啤酒的顾客中有33%的顾客也购买了尿布。
场景应用
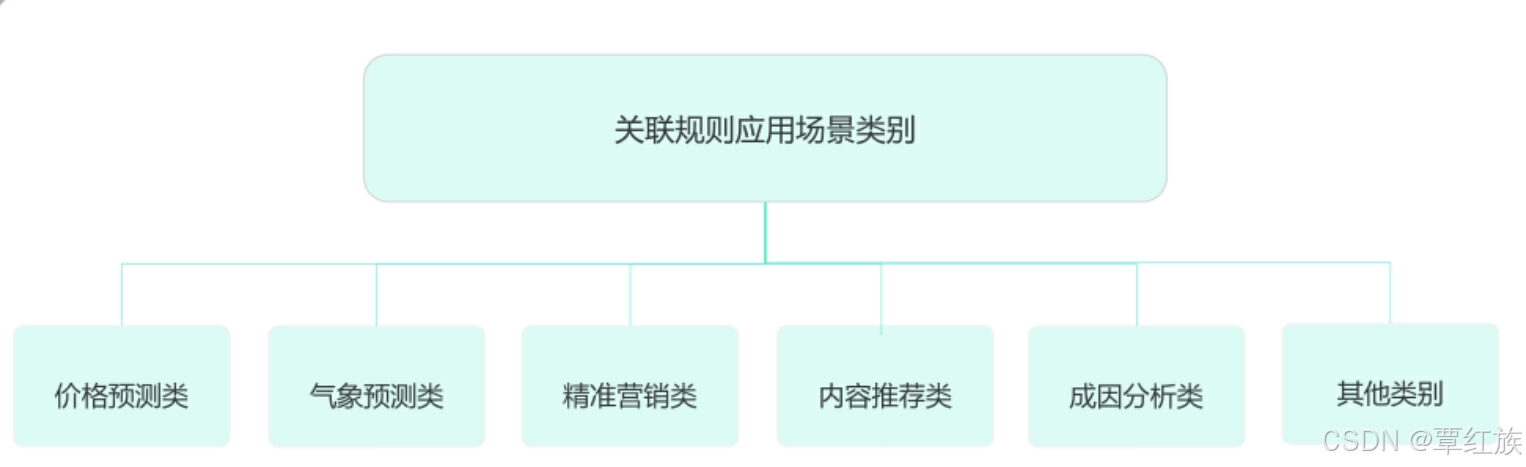
关联规则常规算法
Apriori 算法概述
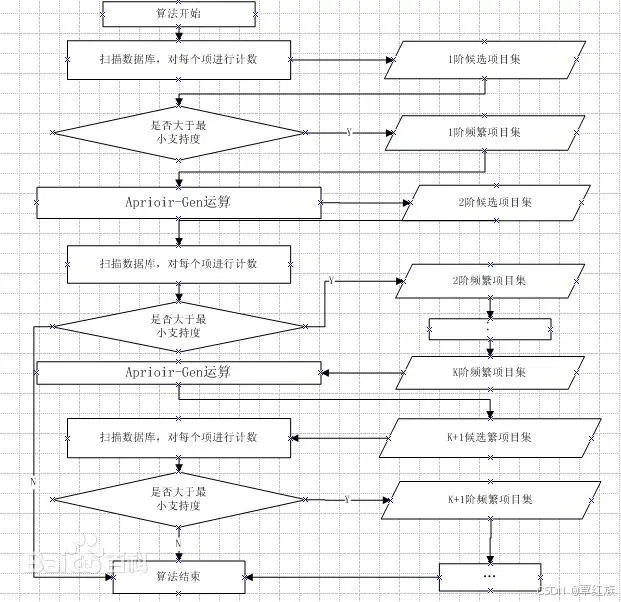
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
Apriori 算法的应用场景
- 商业领域:Apriori算法可以用于发现商品之间的关联规则,帮助商家制定营销策略,如推荐系统、交叉销售等。通过对商品集合进行挖掘,可以发现些有趣的关联模式,如购买尿布的同时也购买啤酒的客户群体,从而制定更加精准的营销策略。
- 网络安全领域: Apriori 算法可以用于检测网络入侵和异常行为。通过对网络流量和日志数据进行挖掘,可以发现异常模式和关联规则,从而及时发现潜在的攻击行为。
- 高校管理领域: Apriori 算法可以用于高校贫困生资助工作。通过对贫困生相关数据的挖掘,可以发现一些关联规则和群体特征,从而为资助工作提供更加科学和精准的决策支持。
Apriori 算法原理及步骤
- Apriori 的原理: 如果某个项集是频繁项集,那么它所有的子集也是频繁的。即如果(0,1}是频繁的,那么{0},{1}也一定是频繁的。
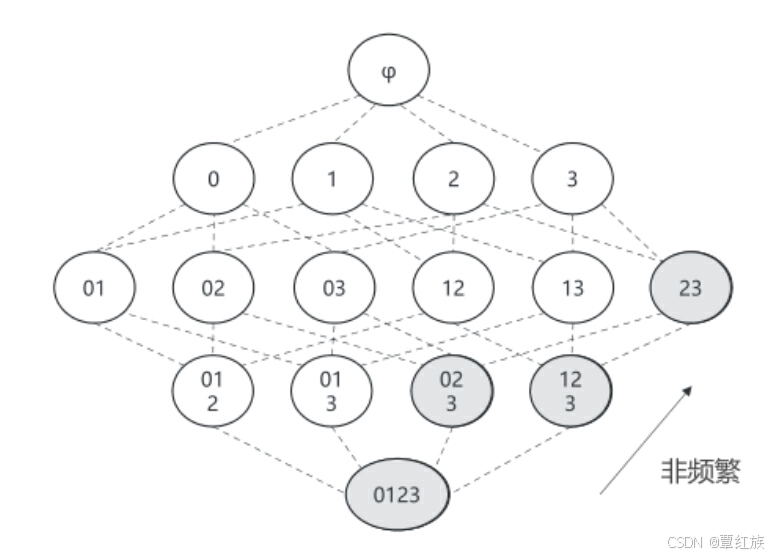
图中给出了所有可能的项集,其中非频繁项集用灰色表示由于集合 {2,3} 是非频繁的,因此 {0,2,3}、{1,2,3} 和(0,1,2,3}也是非频繁的,它们的支持度根本不需要计算。
- 频繁项集的主要步骤:
首先会生成所有单个物品的项集列表;扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉;对剩下的集合进行组合以生成包含两个元素的项集;接下来重新扫描交易记录,去掉不满足最小支持度的项集,重复进行直到所有项集都被去掉。 - Apriori 关联算法计算步骤:
Apriori 算法 python 实现
# Apriori 算法实现
def apriori(dataSet, minSupport=0.5):# 获取所有不重复的项值
def createCldataSet):
C1 =[
for transaction in dataSet:
for item in transaction:
if not itemin Cl:
C1.append(item)
C1.sort()
return list(map(frozenset,C1))# 过滤掉不满足最小支持度的项集
def scanD(D,Ck,minSupport):
ssCnt =fl
for tid in D:
for can in Ck:
if can.issubset(tid):
if not can in ssCnt:
ssCnt[can]=1
else:
ssCnt[can]+=1
numItems = float(len(D))
retList =[]
supportData={}
for key in ssCnt:
support =ssCntkey/numItems
if support >= minSupport:
retList.insert(0,key)
supportDatakey]= support
return retList, supportData# 生成候选项集
def aprioriGen(Lk,k):
retList =[]
lenLk= len(Lk)
for i in range(lenLk):
for jin range(i + l, lenLk):
L1 = list(Lk[i])[:k21
L2 = list(Lk[j])[:k27
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i]Lk[j])
公
return retList# Apriori 算法主函数
D= list(map(set, dataSet))
C1= createCl(dataSet)
L1,supportData =scanD(D,Cl,minSupport)
L =[L1]
k= 2
while(len(Lk-2)>0):
Ck = aprioriGen(Lk2],k)
Lk,supK =scanD(D,Ck,minSupport)
supportData.update(supK)
L.append(Lk)
k += 1
return L,supportData 上述代码中,`createC1()函数用于生成单个项的候选项集,scanD()函数用于过滤不满足最小支持度的项集,`aprioriGen()函数用于生成候选项集,apriori()函数是Apriori算法的主函数用于挖掘频繁项集和关联规则。在主函数中,我们首先将数据集转换为可处理的数据格式,然后生成初始的候选项集C1,并过滤掉不满足最小支持度的项集。接着,我们根据Lk-1生成候选项集Ck,并再次过滤不满足最小支持度的项集,然后重复此步骤直到没有更多的频繁项集为止。最后,我们将所有的频繁项集和支持度数据返回。
注意,上述代码仅供参考,实际应用中可能需要根据具体需求进行一些修改。
Partition 算法概述
partition 算法是一种基于数据分区的频繁项集挖掘算法。它将数据集划分成若干个不相交的子集,然后在每个子集中进行频繁项集挖掘最后将所有子集中的频繁项集合并得到全局频繁项集。
Partition 算法背景
Partition 关联算法的特点
- 对数据库的扫描次数过多
每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,这种扫描比较会大大增加计算机系统的 I/O 开销 - 会产生大量的中间项集
在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元
素
Partition 算法流程
- 将数据集分为若干个不相交的子集
- 在每个子集中进行频繁项集挖掘,得到局部频繁项集
- 将所有子集中的局部频繁项集合并得到全局频繁项集
Partition 算法实现方法
- 数据分区:可以采用随机划分、轮换划分等方式将数据划分为若干个不相交的子集。
- 局部频繁项集挖掘:可以采用 Apriori 算法等经典算法进行挖掘。
- 全局频繁项集合并:可以采用多种方式进行合并,例如简单合并位图压缩等。
Partition 算法实例演示
假设有如下购物清单:
{牛奶,面包,黄油)
{面包,黄油}
{牛奶,面包,可乐}
{牛奶,黄油}
{面包,可乐}
{可乐}
将数据集划分为两个子集:
S1:{牛奶,面包,黄油}{面包,黄油}{牛奶,面包,可乐}
S2:{牛奶,黄油}(面包,可乐}{可乐}
在每个子集中进行频繁项集挖掘:
S1 中的频繁项集为:{面包}、{黄油}、{牛奶,面包}、{面包,黄油}
S2 中的频繁项集为:{牛奶}、{黄油}、{可乐}
将所有子集中的局部频繁项集合并得到全局频繁项集
全局频繁项集为 :{面包}、{黄油}、{牛奶,面包}、{面包,黄油}、{牛奶}{(可乐}
DHP 算法概述
DHP 结构式是一种基于数据、假设、原则(Data,Hypothesis,Principles)的分析框架,用于解决复杂问题。它的目标是通过分析数据、建立假设并应用基本原则来识别问题的根本原因,并制定解决方案。
DHP 结构式的基本原则
- 数据驱动决策 DHP 结构式强调以数据为基础进行决策。它要求收集和分析可靠的数据,以支持假设的建立和解决方案的制定。数据可以是定性的或定量的,可以来自各种来源,如调查、实验、统计数据等。基于数据的决策能够提高决策的准确性和效果。
- 建立假设 DHP结构式要求在问题分析过程中建立假设。假设是对问题根本原因的推测或猜测,可以在数据的基础上建立。通过建立假设,可以指导进一步的数据收集和分析,从而找到问题的真正原因。
- 应用基本原则
DHP结构式使用基本原则来引导问题解决过程。基本原则是在特定情境中普遍适用的原则。它们可以是科学原理、管理原则、伦理准则等。应用基本原则有助于更好地理解问题,并制定可行的解决方案。
DHP 结构式的应用步骤
- 收集和分析数据
在使用 DHP 结构式解决问题时,首先需要收集和分析相关的数据。数据可以包题的具体情况、相关统计数据、专家意见等。通过分析数据,可以了解问题的背关键因素和影响因素。 - 建立假设
基于收集和分析的数据,需要建立假设来解释问题的原因。假设需要具备科学性和可验证性。建立假设时,可以借鉴已有的理论和经验,也可以进行数据的运算和模拟。 - 应用基本原则 在问题分析和解决过程中,需要应用基本原则。基本原则可以指导问题的理解、分析和解决。根据具体情境,选择适合的基本原则,并运用到问题分析和解决中。
- 验证和调整假设
建立的假设需要经过验证。验证可以通过实验证据或数据的分析来进行。如果假设得到验证,可以接受并继续分析和解决问题。如果假设不成立,需要调整假设或重新建立假设。 - 制定解决方案
在验证假设后,可以制定解决方案。解决方案应该基于事实和基本原则,并考虑至成本、风险等因素。解决方案应该能够解决问题的根本原因,并达到预期的效果。
DHP 结构式的优势和应用领域
DHP 结构式具有以下优势:
- 数据驱动决策,能够提高决策的准确性和效果。
- 建立假设,能够指导进一步的数据收集和分析。
- 应用基本原则,有助于理解问题和制定解决方案。
DHP 结构式适用于解决复杂问题,特别是涉及多个因素和变量的问题。它可以应用于各种领域,如科学研究、工程项目、企业管理等。在这些领域中,DP结构式能够提供一种系统化和科学化的方法,帮助人们更好地理解问题和制定解决方案。
MSApriori 算法概述
Apriori算法是一种经典的关联规则挖掘算法,用于发现数据集中的频繁项集。频繁项集是指在数据集中经常出现的物品的集合Apriori算法的主要思想是基于先验知识,即如果一个项集是频繁的,那么它的所有子集也必须是频繁的。该算法通过迭代的方式来发现频繁项集,然后利用频繁项集来生成关联规则。
Apriori算法的工作流程大致可以分为以下几个步骤:
- 扫描数据集,找出所有的单个物品作为候选项集。
- 计算候选项集的支持度,即在数据集中出现的频率。
- 根据最小支持度阈值,筛选出频繁项集。
- 使用频繁项集生成候选项集,进一步迭代计算支持度,直到无法生成更多的频繁项集为止。
- 根据频繁项集生成关联规则,并计算它们的置信度。
Apriori算法的优点是简单易懂,并且能够有效地挖掘出频繁项集和关联规则。然而,该算法也存在一些缺点,例如在大规模数据集上的计算开销较大,同时对于稀疏数据集的处理效果不佳。
在实际应用中,Apriori算法被广泛应用于市场篮分析、推荐系统、生物信息学等领域。同时,也有一些改进的算法被提出,如FP-growth算法等,用于克服 Apriori算法的一些缺点。
总的来说,Apriori算法作为一种经典的关联规则挖掘算法,对于发现数据集中的潜在关联关系具有重要意义,但在实际应用中需要根据具体情况选择合适的算法并进行优化。
FP-Growth 算法概述
- FP-growth 算法不产生候选集而直接生成频繁集的频繁模式增长算法,该算法采用分而治之的策略
- 第一次扫描数据库,把数据库中的频繁项目集压缩到一棵频繁模式树中,形成投影数据库,同时保留其中的关联信息
- 第二次扫描数据库,将 FP-tree 分化成一些条件库,每个库和一个长度为1的频集相关,然后再对这些条件库分别进行挖掘。
FP-Growth 算法原理及步骤
FP 树的构建
| 事务 | 项ID列表 | 事务 | 项ID列表 |
| T100 | I2,I1,I5 | T600 | I2,I3 |
| T200 | I2,I4 | T700 | I1,I3 |
| T300 | I2,I3 | T800 | I2,I1,I3,I5 |
| T400 | I2,I1,I4 | T900 | I1,I1,I3 |
| T500 | I1,I3 |
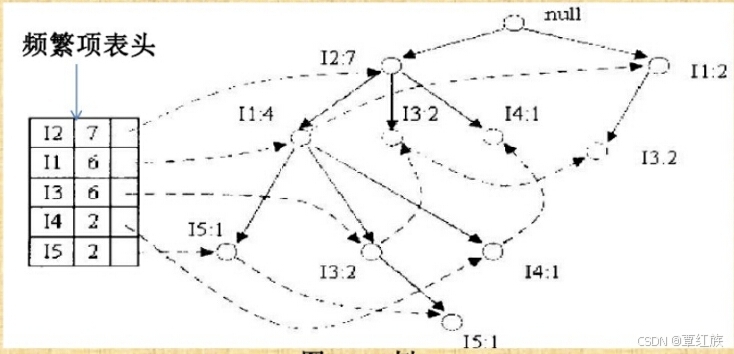
定义1.2:项11,12..k,(k>1). (11,12,..,k}是子树T的前缀路径,若每个j(1<=」<=k-1)出现在从根到子树的根节点N的路径中,T称为具有前缀(11,2,…k}的一棵前缀树,{11.,12....,.k}是其前缀。
T或者N称为路径(11,12....k}的后缓项集或者后缀模式。
定义1.2:具有相同前缀(11,12...k}的所有前缀子树表示为PSF(11,12...k),作具有前缀(11,12..….k)的一个前缀子森林。
FP-Growth 算法特点
- 不产生候选集
- 两次扫描数据库
第1次扫描获得当个项目的频率,去掉不满足支持度要求的项,并对剩下的项排序,第2次扫描建立一颗 FP-Tree树 - 内存开销大,适用于挖掘单维的布尔关联规则 算法要递归生成条件 FP-tree,所以内存开销大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









