







🌟🌟作者主页:ephemerals__
🌟🌟所属专栏:C语言
目录
一、函数指针
在c语言中,不仅有变量的指针,也有函数指针。与变量相同,函数指针存放的是函数的地址,通过函数的地址可以调用该函数。
1.函数指针变量的创建
函数指针的创建方法如下:
类型1 (*变量名)(类型2,类型3......);
与数组指针的定义方式一样,函数指针的变量名也是需要先和*号结合的。不同的是,之后的方括号变成了圆括号。详细说明一下这里的要点:
类型1指的是函数指针指向函数的返回值类型;
类型2、类型3等等都是指向函数的参数类型,参数的数量和类型要和函数的参数保持一致,类型之后的形参名可写可不写。
接下来让我们尝试定义一个函数指针变量,存放函数的地址:
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
int a = 3;
int b = 5;
int (*pf1)(int, int) = add;
int (*pf2)(int, int) = &add;
return 0;
}注意:以上代码中,pf1和pf2存放的是完全相同的地址。对于函数来讲,函数名之前是否加取地址符号都表示函数的地址,所以&可写可不写。
2.函数指针变量的使用
接下来我们尝试通过函数指针来调用函数:
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
int a = 3;
int b = 5;
int (*pf)(int, int) = add;
int ret = pf(a, b);//指针变量的使用
printf("%d\n", ret);
return 0;
}这里使用pf接收了add函数的地址,pf就等价于add,直接传参就可以调用函数。
二、typedef关键字
我们学习了复杂的指针类型(例如数组指针、函数指针)之后,会发现它们的定义方式较为复杂。那么是否有办法能够让我们简化定义的代码呢?这就需要用到typedef关键字了。
typedef是c语言中的一个关键字,它用于对类型进行重定义,将复杂的类型简单化。
它的使用方法是:
typedef 类型1 类型2;
进行typedef操作之后,类型2与类型1就是等价的。
接下来我们尝试将一些变量类型进行重定义:
#include <stdio.h>
typedef int t;//类型重定义
t main()
{
t a = 0;
printf("%d\n", a);
return 0;
}运行结果:

这里我们将int类型重定义了一个名字叫 t ,之后的使用当中定义的整形类型都可以用 t 来表示。
对于指针变量,我们也可以这样重定义:
#include <stdio.h>
typedef int* ptr_t;
int main()
{
int a = 0;
ptr_t p = &a;
printf("%p\n", p);
return 0;
}运行结果:
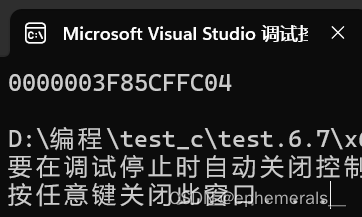
可以看到,程序输出了一个地址,我们将整形指针变量重新起名为ptr_t。
接着,我们尝试对数组指针和函数指针类型重定义: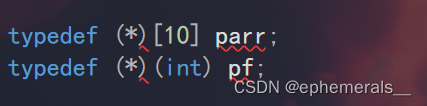
可以看到,对于数组指针或者函数指针类型重定义时,这种语法是不正确的,我们要将新类型名写到*号旁边:

这样,对于一些复杂类型的数组指针或者函数指针,我们就可以用简单的单词来表示。
三、函数指针数组
1.函数指针数组的概念
我们都知道,指针数组就是数组元素都是指针变量。而函数指针数组就是说这个数组当中的元素类型都是函数指针。
2.函数指针数组的定义方式
函数指针数组的定义方式如下:
类型1 (*变量名[元素个数])(类型2,类型3......);
从它的定义方式可以看出,函数指针数组的定义方式就是在函数指针的变量名后加上方括号。这里变量名和[]先结合,说明它是一个数组,而数组的元素就是函数指针类型。代码示例:
#include <stdio.h>
void test1()
{
printf("hehe\n");
}
void test2()
{
printf("haha\n");
}
void test3()
{
printf("hello\n");
}
int main()
{
void (*pfarr[3])() = { test1,test2,test3 };//函数指针数组的定义和初始化
int num = 0;
while (scanf("%d", &num) != EOF)
{
pfarr[num - 1]();
}
return 0;
}运行结果:
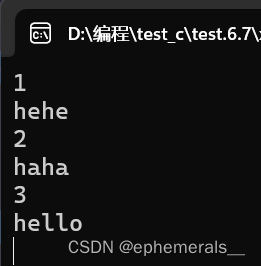
不难看出,程序就可以根据输入的值来调用不同的函数。
注意:我们在使用函数指针数组时,函数指针数组所指向的所有函数的类型必须一致。
四、转移表
刚才我们简单使用了一下函数指针数组,这种通过函数指针数组来实现的调用不同函数的方法叫做转移表。由于计算器这类程序可以有多种运算功能,我们就运用转移表来实现一个简单的计算器。
程序代码:
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mul(int a, int b)
{
return a * b;
}
int div(int a, int b)
{
return a / b;
}
int main()
{
int(*pfarr[5])(int, int) = { NULL,add,sub,mul,div };
int input = 0;
do
{
printf("************************\n");
printf("*** 1.add 2.sub ***\n");
printf("*** 3.mul 4.div ***\n");
printf("*** 5.exit ************\n");
printf("************************\n");
printf("请选择:>>>");
scanf("%d", &input);
if (input >= 1 && input <= 5)
{
int a = 0;
int b = 0;
printf("请输入两个操作数:>>>");
scanf("%d %d", &a, &b);
printf("结果是:%d\n",pfarr[input](a, b));
}
else if (input == 0)
{
printf("退出计算器\n");
}
else
{
printf("输入错误!请重新输入!");
}
} while (input);
return 0;
}当我们使用转移表时,就可以在功能过多的情况下免去使用switch语句和大量的case语句,使得代码更加简洁。
总结
这篇文章我们学习了函数指针,typedef关键字和函数指针数组等知识和应用。之后博主会和大家介绍c语言中的库函数--qsort,并且模拟实现。如果你觉得博主讲的还不错,就请留下一个小小的赞在走哦,感谢大家的支持❤❤❤















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









