







1.前期安装Hadoop集群,确保HDFS和YARN服务正常运行。
确保 Hadoop 集群正常运行:
启动 Hadoop 集群所有节点上的 HDFS 和 YARN 服务。
格式化HDFS(如果您是第一次启动Hadoop集群或者在更改配置后需要重新格式化):
hdfs namenode -format
然后,启动HDFS服务:
start-dfs.sh
2. 启动YARN服务
启动YARN服务:
start-yarn.sh
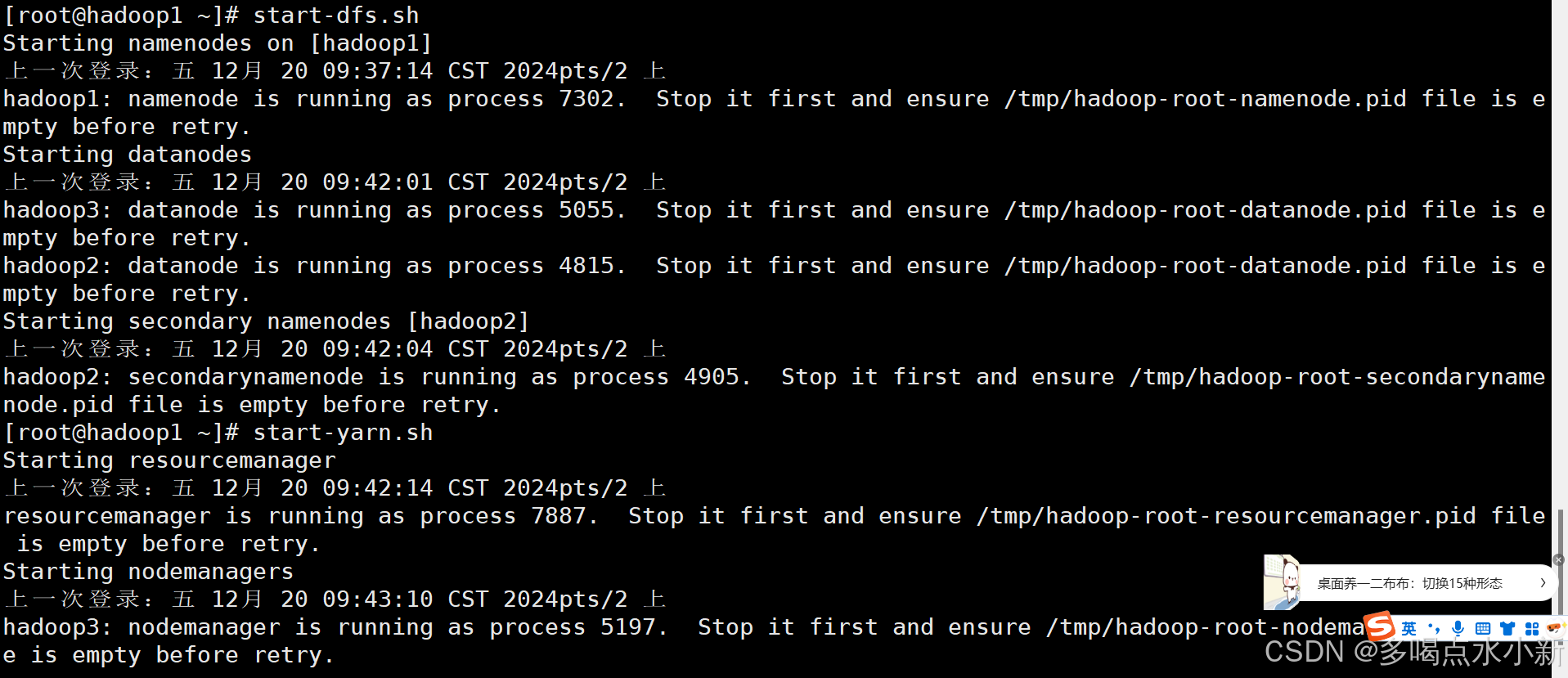
启动服务后,您可以使用以下命令来验证HDFS和YARN服务的状态:
对于HDFS:
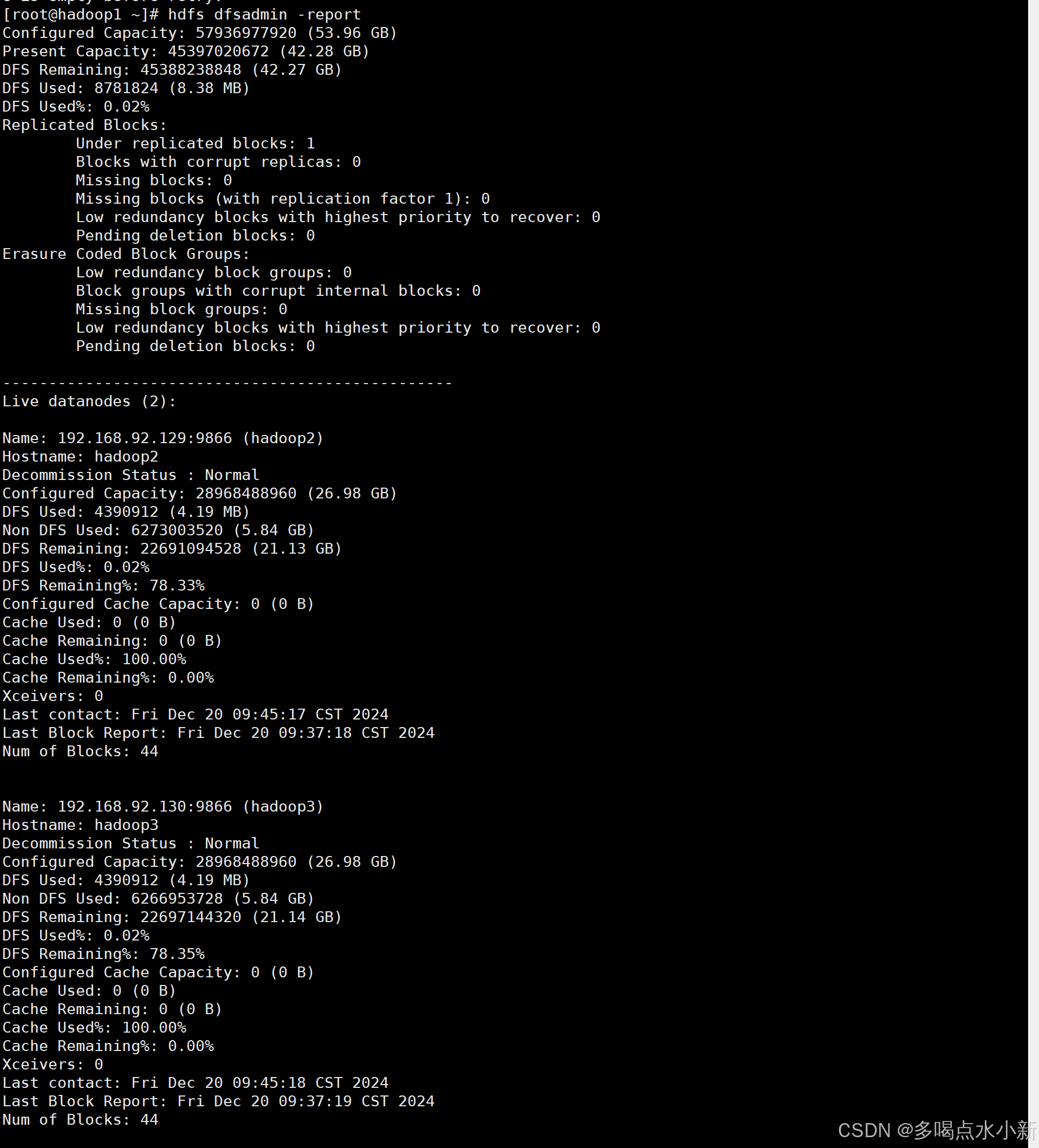
hdfs dfsadmin -report
对于YARN:
yarn node -list
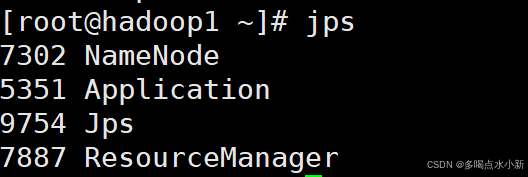
或者使用jps命令查看Java进程,确认NameNode、DataNode、ResourceManager和NodeManager是否都在运行:
jps

配置 Hadoop 环境变量:
编辑 /etc/profile 文件,添加以下内容:
export HADOOP_HOME=/export/servers/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.前期安装Zookeeper集群
1上传安装包
2.在hadoop里面查看并解压安装包
解压ZooKeeper压缩包,在 hadoop1 虚拟机上,使用 Xftp 将 zookeeper-3.4.8.tar.gz 文件上传到 /root 目录。
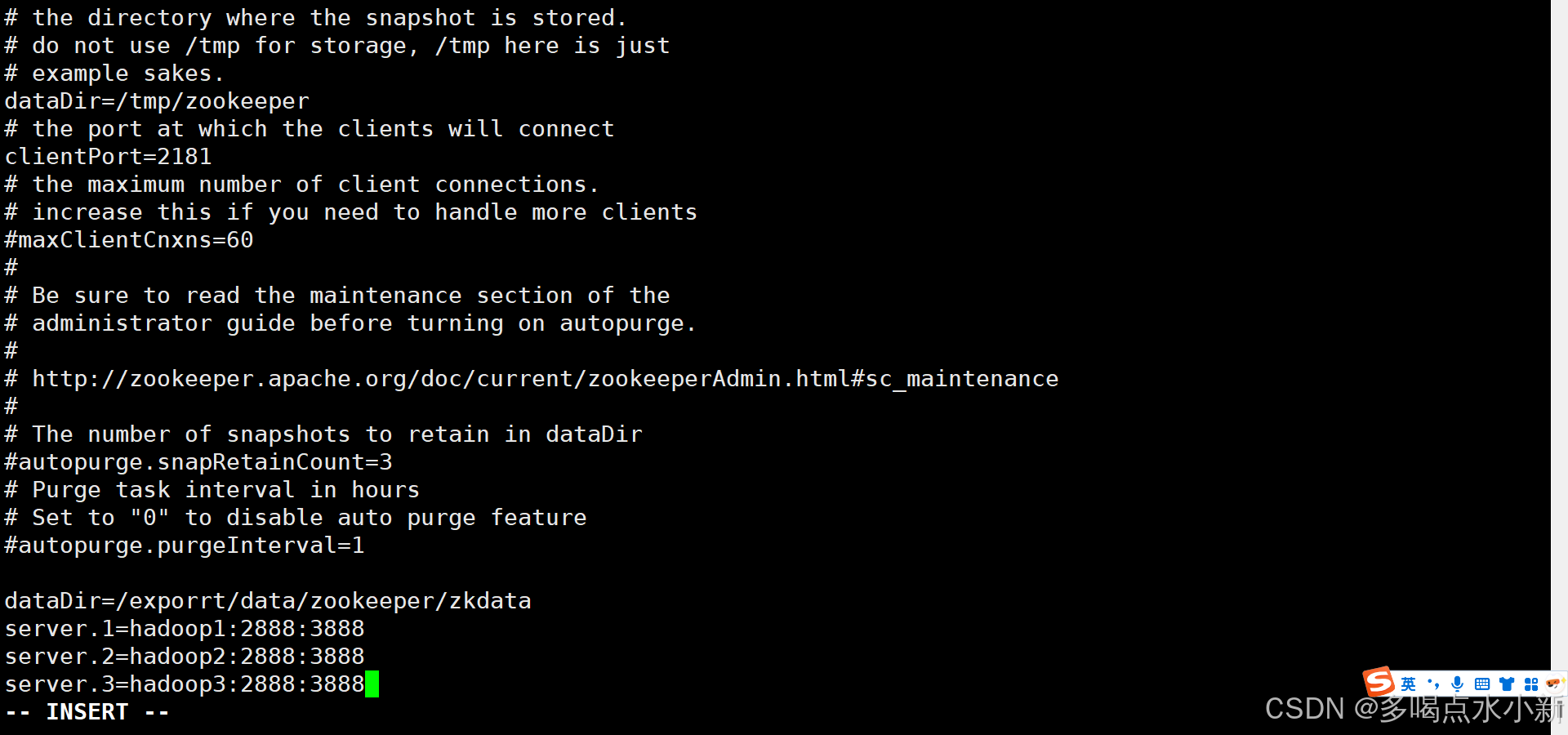
配置cfg文件

 在每个虚拟机上,执行以下命令:
在每个虚拟机上,执行以下命令:
mkdir -p /exporrt/data/zookeeper/zkdata
建立目录并在三台虚拟机上都echo 1 > /export/data/zookeeper/zkdata/myid # hadoop2 和 hadoop3 分别使用 2 和 3

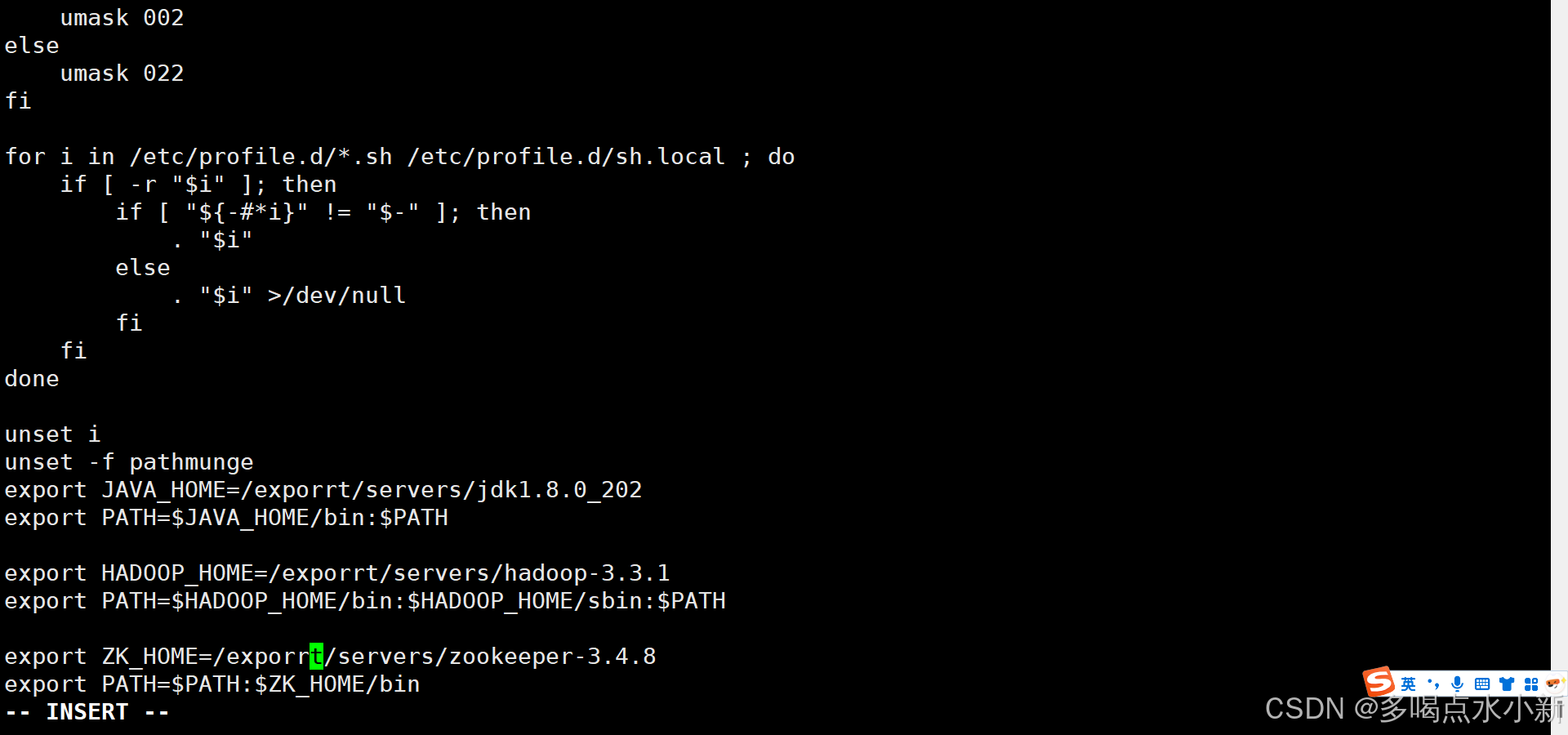
在 hadoop1 虚拟机上,执行以下命令:
vi /etc/profile
export ZK_HOME=/export/servers/zookeeper-3.4.8
export PATH=$PATH:$ZK_HOME/bin
source /etc/profile

在 hadoop1 虚拟机上,执行以下命令:
scp -r /export/servers/zookeeper-3.4.8/ hadoop2:/export/servers/
scp -r /export/servers/zookeeper-3.4.8/ hadoop3:/export/servers/
scp /etc/profile root@hadoop2:/etc/
scp /etc/profile root@hadoop3:/etc/



在 hadoop2 和 hadoop3 虚拟机上,执行以下命令:
source /etc/profile


启动 ZooKeeper 集群:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









