






catalogue
目录
#ZERO. Data Type( Data Structure)
3. round: 四舍五入(use upper bound)的小数位数
Chapter 2: Data acquisition for FinTech
Chapter 1: Python Fundamental
#ZERO. Data Type( Data Structure)
# i think "data type" should be essential to learn fundamental python, so i put the data type at the beginning.
1. List
(1) def
#1:there can be any data type in the list
messy_list = [1, 7.6, "()", True]#2: list inside list
eg. there are 4 items in the list
item1: 0
item2: 1
item3: 2
item4: ["a", "b", "c"]
list_of_list = [0, 1, 2, ["a", "b", "c"]]index: start at 0 ## when use the index, it can be index[0-n]
value
ticker = ["aapl", "msft", "nvda"]
>>> ticker = ["aapl", "msft", "nvda"]
>>>
>>> ticker[0]
'aapl'
>>> ticker[1]
'msft'
>>> ticker[2]
'nvda'
>>> ticker[-2]
'msft'
>>> ticker[-4]
Traceback (most recent call last):
File "<python-input-6>", line 1, in <module>
ticker[-4]
~~~~~~^^^^
IndexError: list index out of range
>>> ticker[-3]
'aapl'
>>> ticker[-1]
'nvda'
>>> ticker[3]
Traceback (most recent call last):
File "<python-input-9>", line 1, in <module>
ticker[3]
~~~~~~^^^
IndexError: list index out of range(2) initialize a empty list
empty_list = []emptylist=[]
>>> type(emptylist)
<class 'list'>(3) method
catalogue:
| No. | methon | link |
| a | append() | |
| b | remove() | |
| c | extend() | |
| d | check if the item in the list | |
| e | length: len(<list>) | |
| f | combine two list: lst1 + lst2 | |
| g | sort: 2 methods |
a. append()
ticker = ["aapl", "msft", "nvda"]
ticker.append("TSLA")
output:
>>> ticker = ["aapl", "msft", "nvda"]
>>>
>>> ticker.append("TSLA")
>>>
>>> ticker
['aapl', 'msft', 'nvda', 'TSLA']
>>> b. remove()
ticker = ["aapl", "msft", "nvda"]
ticker.remove("nvda")
output:
>>> ticker = ["aapl", "msft", "nvda"]
>>>
>>> ticker.remove("nvda")
>>>
>>> ticker
['aapl', 'msft']c. extend()
ticker = ["aapl", "msft", "nvda"]
ticker.extend(["ma", "v", "ms"])d. check if the item in the list
ticker = ["aapl", "msft", "nvda"]
"ms" in ticker
ticker.extend(["ma", "v", "ms"])
"ms" in tickeroutput:
>>> ticker
['aapl', 'msft']
>>> ticker = ["aapl", "msft", "nvda"]
>>>
>>> "ms" in ticker
False
>>>
>>> ticker.extend(["ma", "v", "ms"])
>>>
>>> "ms" in ticker
True
>>> e. length: len(<list>)
# 3. find the number of items of the list
def find_length(lst):
return len(lst) # replace this with correct logicf. combine two list
# 4. return sorted union of two lists, i.e. a list that contains all elements of both lists
# and sort the result in ascending order, keeping duplicate values
def union_list(lst1, lst2):
union_lst = lst1 + lst2
union_lst.sort()
return union_lstg. sort() & sorted()
>>g1. sort(): in this way, the target list have been sorted
a method to modify the list, but its return value = void
--> lst.sort() returns/output none
correct coding:
# 2. sort the list in accending order
def sort_list(lst):
lst.sort()
return lst # replace this with correct logic
false coding:
watch the return value = none
def sort_list(lst):
lst.sort()
return lst.sort() 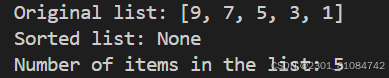
>>g2. sorted() : in this way, the target list doesn't change, remain original value/data
the function will return a sorted list, but it do not modify the initial list.
def sort_list(lst):
return sorted(lst) # replace this with correct logic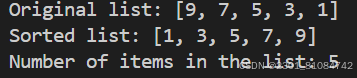
>>> lst = [5,3,1]
>>> ret = []
>>> ret = sorted(lst)
>>> ret
[1, 3, 5]
>>> lst
[5, 3, 1]If you used to experience javascript, you will be familiar with.
(4)comprehension
a. first ticker: the item append to the [ ]
b. for ticker in tickers: do the loop
c. if ticker not in excluded: condiction
def exclude_tickers(tickers):
# do something here
excluded = ['MSFT', 'AAPL', 'GOOGL']
return [ticker for ticker in tickers if ticker not in excluded]without comprehension
def exclude_tickers(tickers):
# do something here
ret = []
for i in tickers:
#if(i not in ['MSFT', 'AAPL', 'GOOGL']):
if(i != 'MSFT' and i !='AAPL' and i !='GOOGL'):
ret.append(i)
return ret# replace this line with your code(5) pointer 指针
if you just use "another = numbers", then the two lists will call the same index
>>> numbers = [1, 2, 3, 4, 5]
>>> another = numbers
>>> another
[1, 2, 3, 4, 5]
>>> numbers
[1, 2, 3, 4, 5]
>>> numbers.append(6)
>>> numbers
[1, 2, 3, 4, 5, 6]
>>> another
[1, 2, 3, 4, 5, 6]solution: using copy()
>>> cloned_list = numbers.copy()
>>> cloned_list
[1, 2, 3, 4, 5, 6]
>>> numbers.append(7)
>>> numbers
[1, 2, 3, 4, 5, 6, 7]
>>> cloned_list
[1, 2, 3, 4, 5, 6]I. Data Type
1.check data type
type(100)
>>> <class 'int'>
type(100.0)
>>> <class 'float'>
type('c')
>>> <class 'str'>
type('hello')
>>> <class 'str'>
type(False)
>>> <class 'bool'>2. case-sensitive
distinguish lowercase and uppercase
3. Identifiers (Variable Names)
10 + '10'
>>> Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'b. NameError
op
>>> Traceback (most recent call last):
File "<input>", line 1, in <module>
NameError: name 'op' is not definedII. Function
1. print
a = 100
print(a)
print('hello world')100
hello world(2) seperate the input by comma","
-- 每个输出之间会自动空格
print("hello", 'world', '!!!!')hello world !!!!(3) print in two way: use "+" ; use "{}", can avoid "space" (not like(2))
>>> op = "a"
>>> hello="b"
>>> world="c"
>>> print(f"{op}{hello}{world}")
abc#1
print('this year is ' + str(year) + ". Next tear is " + str(year+1))
this year is 2025. Next tear is 2026
#2
print(f'this year is {year}. Next tear is {year+1}')
this year is 2025. Next tear is 2026(4) use {}
def generate_random_numbers(n):
# do something here
lst = []
for i in range(n):
lst.append(random.randint(1, 100))
return lst# replace this line with correct logic
def main():
print("{}".format(generate_random_numbers(3)))2. function and reuse
(a) define a function
key word: def
def bmi_calculator_menu():indentation "tab"
inside code should have the indentation
def bmi_calculator_menu():
print('BMI Calculator')
print('Welcome to the tool')
print('Hello Bonnie')
print('====================')
print('Menu')
print('1. - Calculator')
print('2. - Help')(b) input value of a function
def bmi_calculator_menu(name):
print('BMI Calculator')
print('Welcome to the tool')
print(f'Hello {name}')
print('Hello ' + name)
print('====================')
print('Menu')
print('1. - Calculator')
print('2. - Help')
#heigth = input("")
bmi_calculator_menu('bonnie')(c) return value
def area_square(length):
return length * length
def area_rectangle(length, height):
return length * height2. input
(1) a return value of input is a string
try:
height = input("input height in cm")/100error occur:

solution:
should transmit the data type to <int>
height = int(input("input height in cm"))/100example:
#height = input("input height in cm")/100
height = int(input("input height in cm"))/100
weight = int(input("input weight om kg"))
user_bmi = weight/height**2
print("your bmi is " + str(user_bmi))
print(f"Your BMI is {user_bmi}")
3. round: 四舍五入(use upper bound)的小数位数
The round() function in Python is used to round a number to a specified number of decimal places.
syntax:
round(number, ndigits)
-
number: The number to be rounded. -
ndigits(optional): The number of decimal places to round to. If omitted, it defaults to 0, meaning the number will be rounded to the nearest integer.
Examples:
(1) Rounding to the nearest integer
print(round(4.567)) # Output: 5
(2) Rounding to a specified number of decimal places:
print(round(4.567, 2)) # Output: 4.57
(3) Rounding negative numbers:
print(round(-4.567, 2)) # Output: -4.57III. Operator
| math operator | in python | example |
| ^ | ** | |
| \land | and | |
| \lor | or | |
| \neg | not | |
IV. Condiction Statement
A. IF-ELSE
1. IF
bmi = 15
if bmi < 16:
print("you are underweight")2. IF-ELSE
bmi = 22
if bmi < 16:
print("oh")
print("you are underweight")
else:
print("you are not severe thinnese")3. Else-If
## in python, the keyword should be " elif "
bmi = 19
if bmi < 16:
print("oh")
print("you are underweight")
elif bmi < 17:
print("you are moderate thinnese")
elif bmi < 18.5:
print("you are mild thinnese")
else:
print("you are not severe thinnese")4. condiction statement in a function
def evalultate_bmi(bmi):
if bmi < 16:
print("oh")
print("you are underweight")
elif bmi < 17:
print("you are moderate thinnese")
elif bmi < 18.5:
print("you are mild thinnese")
else:
print("you are not severe thinnese")5. more detailed with indentation
(1) code outside the function
def evalultate_bmi(bmi):
if bmi < 16:
print("oh")
print("you are underweight")
elif bmi < 17:
print("you are moderate thinnese")
elif bmi < 18.5:
print("you are mild thinnese")
else:
print("you are not severe thinnese")
print("OPOP")
evalultate_bmi(19)(2) code inside function but outside if-else
def evalultate_bmi(bmi):
if bmi < 16:
print("oh")
print("you are underweight")
elif bmi < 17:
print("you are moderate thinnese")
elif bmi < 18.5:
print("you are mild thinnese")
else:
print("you are not severe thinnese")
print("opop")
evalultate_bmi(19)(3) code inside function and if-else
def evalultate_bmi(bmi):
if bmi < 16:
print("oh")
print("you are underweight")
elif bmi < 17:
print("you are moderate thinnese")
elif bmi < 18.5:
print("you are mild thinnese")
else:
print("you are not severe thinnese")
print("OPOP")
evalultate_bmi(19)B. Comparison
1.
| math operator | in python | example |
| \land | and | |
| \lor | or | |
| \neg | not | |
2. tips:
(1) 45 < weight < 90
45 < weight < 90V. Library Import
VI. Random
1. library
import randomgive a abbreviation
import pandas
import pandas as pd2.funtion
(1)random.random(): random floating number between 0.0 and up to but not including 1.0 | [ 0, 1 ).
import random
for i in range(10):
x=random.random()
print(x)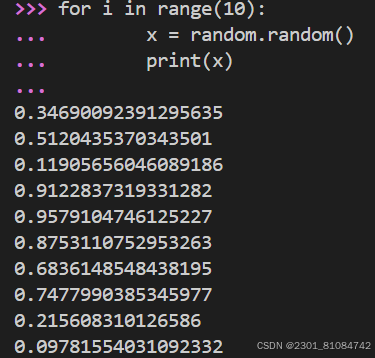
(2) random.uniform(a,b): return a random floating number over [a,b)
for i in range(10):
... x = random.uniform(0,10)
... print(x)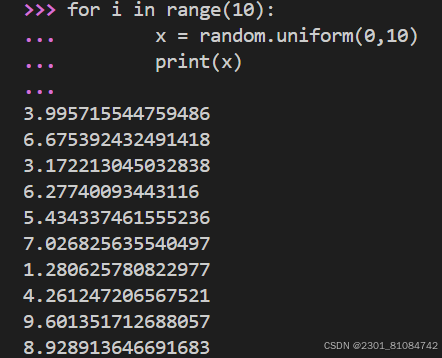
(3) random.randint(a,b): The function randint takes the parameters low and high, and returns an integer between low and high(including both)
for i in range(10):
... x = random.randint(0,10)
... print(x)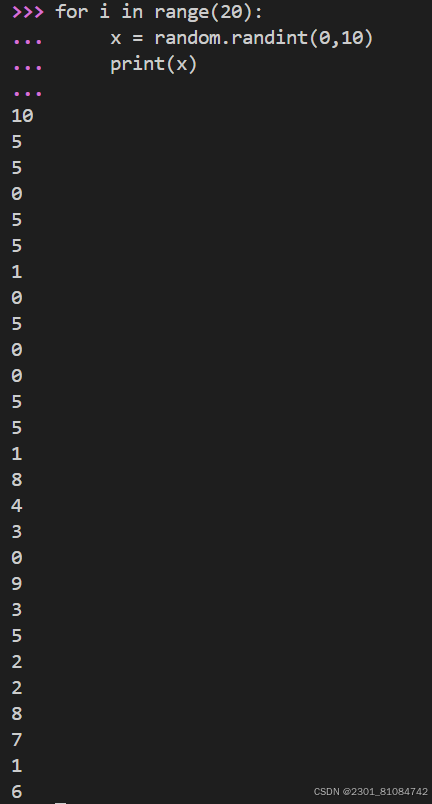
(4) random.choice(): to choose an element from a sequence at random, you can use choice
#string, list, tuple all can be chosen, they all are sequence type( not a special data type)
string: choose a char
list: choose a value
tuple: choose a value
import random
print(random.choice('python'))
print(random.choice(['aaa', 'bbb', 'ccc', 'ddd', 'eee']))
print(random.choice(('aaa', 'bbb', 'ccc'))) 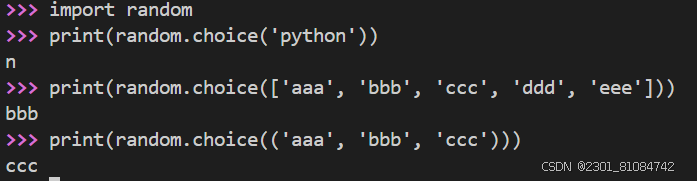
VII. Loop
[1] for
1. loop in list
fruits = ['apple', 'banana', 'orange']
for fruit in fruits:
if(fruit != 'banana'):
print('i like ' + fruit)
else:
print('i hate '+ fruit)numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for n in numbers:
if n%2:
print(f'{n} is odd')
else:
print(f"{n} is even")2. iteration
(1) range(i, j) :
produces i, i+1, i+2, ..., j-1
#notice the period is [ i , j -1] / [ i , j -1)
for n in range(1, 10):
if n%2:
print(f'{n} is odd')
else:
print(f"{n} is even")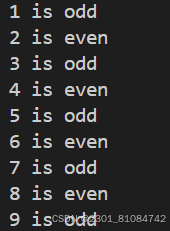
(2) range(n)
produce n numbers, but it start from 0
0, 1, 2, 3, ..., n-1
start defaults to 0, and stop is omitted! range(4) produces 0, 1, 2, 3.
These are exactly the valid indices for a list of 4 elements.
When step is given, it specifies the increment (or decrement).
for n in range(10):
if n%2:
print(f'{n} is odd')
else:
print(f"{n} is even") 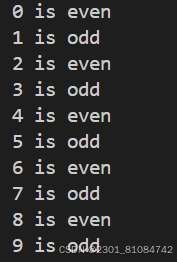
3. stop a loop
(1) return : it will also stop the whole function, so it is not preferable.
(2) break
[2] while
1. example
>>> cnt =0
>>> while cnt<5:
... print(cnt)
... cnt +=12. condiction
cnt<5
# should remenber to increase the cnt --> 死循环
3. advantage:
do not need to calculate the numbers/bound
numbers = [90, 6, 7, 5, 3, 4]
first_2_odd = []
i = 0
while i < len(numbers) and len(first_2_odd) < 2:
if numbers[i] % 2 == 1:
first_2_odd.append(numbers[i])
i += 1
VIII. Dictionary
1. definition
a. key
b. value
c. not allow duplicated key, but allow duplicated values
like a class/struct
phonebook = {"Henry": 111, "Amy":222, "Phoebe": 333}explanation:
item = key: value
key: "Henry", "Amy", "Pheobe"
value: 111, 222, 333
2. add a new item
just give a new key and value to the dictionary
phonebook["Michael"]=99999999
3. empty dictionary
empty_dict = {}4. check key and value
(1) chek if is a key to dictionary
#only can check key
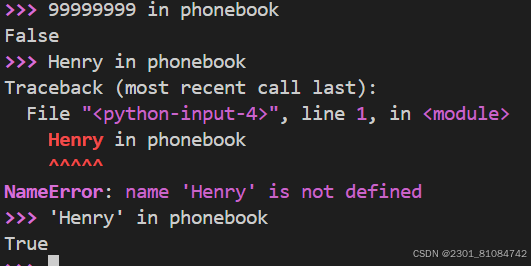
(2) check if is a value in the dictionary
![]()
(3) look for all the key in the dictionary
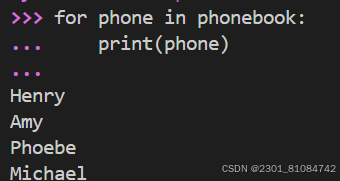
(4) look for all the value in the dictionary
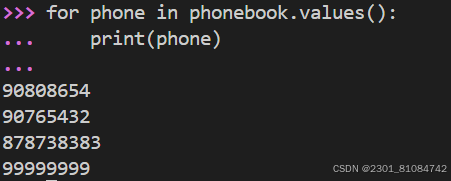
5. append new value into recent key index
# 创建一个包含列表的字典
my_dict = {'key1': ['value1', 'value2'], 'key2': ['value3']}
# 添加一个新的值到键 'key1' 的列表
my_dict['key1'].append('new_value1')
# 打印字典
print(my_dict)
# 输出: {'key1': ['value1', 'value2', 'new_value1'], 'key2': ['value3']}
6. the value of a key can also be a dictionary
IX. Error Handling
1. introduction
An error may damage the whole program.
If we want to continue the program, we should handle the error.
2. simple syntax
try:
x = int(input("Enter a number: "))
result = 10 / x
except ZeroDivisionError:
print("Cannot divide by zero!")
except ValueError:
print("Invalid input! Please enter a valid number.")
else:
print(f"Result is {result}")
finally:
print("Execution complete.")
3. Exception Class ( Error Class)
try:
# 可能引发任何异常的代码
x = 1 / 0 # 这会引发一个 ZeroDivisionError
except Exception as e:
print(f"Caught an error: {e}")
Chapter 2: Data acquisition for FinTech
I. pip
1. yfinance
2. nasdaq
II. API
1. API with python library
1) api key
import nasdaqdatalink
nasdaqdatalink.ApiConfig.api_key = ()#input your api key, which is a string 2) sample code
nasdaqdatalink.get_table('QDL/ODA', date = '2022-12-31', indicator = 'HKG_LE')
nasdaqdatalink.get_table('QDL/ODA', date = {'gte': '2015-01-01', 'lte': '2025-12-31'}, indicator = 'HKG_LE')
nasdaqdatalink.get_table('QDL/ODA', date = {'gte': '2015-01-01', 'lte': '2025-12-31'}, indicator = 'USA_GGXWDG_NGDP')3) sample
a. yfinance
1. Install yfinance library using pip
2. Create a function get_price_lastweek(ticker) that get the price of a US stock ticker for last week (Monday to Friday)
3. Call the function to get the prices of AAPL, MSFT, NVDA, TSLA, MS, GS for last week .
4. Find which one has the highest return (i.e. Friday close price over Monday open price) during last week.#1. Install yfinance library using pip
pip install yfinance#2. Import yfinance
import yfinance as yf#3. first to consider how to generate the stock history/information
a. function: Ticker()
'AAPL' is the ticker's name
apple is the variable
apple = yf.Ticker('AAPL')b. function: ticker.history()
apple.history(start = '2025-02-24' , end = '2025-03-01') output:

c. get prices
>>> prices = apple.history(start = '2025-02-24' , end = '2025-03-01')
>>> prices['Open']
Date
2025-02-24 00:00:00-05:00 244.929993
2025-02-25 00:00:00-05:00 248.000000
2025-02-26 00:00:00-05:00 244.330002
2025-02-27 00:00:00-05:00 239.410004
2025-02-28 00:00:00-05:00 236.949997
Name: Open, dtype: float64
>>> prices.iloc[0]['Open']
np.float64(244.92999267578125)d. to get the Mon-Open and Fri-Close
prices.iloc[-1]['Close'] / prices.iloc[0]['Open']
np.float64(0.9873841651480351)#sample code (including generate csv & txt)
# console(cmd): pip install yfinance
import yfinance as yf
from datetime import datetime, timedelta
#import pytz
#eastern = pytz.timezone('US/Eastern')
import os
print(os.getcwd())
import pandas as pd
pd.set_option('display.max_colwidth', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
def get_price_lastweek(ticker):
stock = yf.Ticker(ticker)
#last week (Monday to Friday)
#today = datetime.now(eastern)
today = datetime.today()
last_monday = today - timedelta(days=today.weekday() + 7) # Last Monday
last_friday = last_monday + timedelta(days=4)
#test
#print(f'test: last_monday: {last_monday} & last_friday: {last_friday}')
dat = stock.history(start=last_monday.strftime('%Y-%m-%d'), end=(last_friday + timedelta(days=1)).strftime('%Y-%m-%d'))#including the data of the whole friday
return dat
def calculate_return(t):
data = get_price_lastweek(t)
#ensure the data is avilable
if (len(data)) >= 1:
#print('test')
# get monday open price and frinday close price
monday_open = data.iloc[0]['Open']
friday_close = data.iloc[-1]['Close']
return_value = (friday_close / monday_open) - 1
return return_value
else:
return None # Not enough data
#save the data
def writeData(t):
#get dataFrame
dat = get_price_lastweek(t)
# Set the file path dynamically based on the ticker
# Get the directory of the current Python file
current_dir = os.path.dirname(os.path.abspath(__file__))
#save to csv
function_file_path_csv = os.path.join(current_dir, f'data_{t}.csv')
dat.to_csv(function_file_path_csv)
#save to txt
function_file_path_txt = os.path.join(current_dir, f'data_{t}.txt')
with open(function_file_path_txt, 'w+') as file:
file.write(str(dat))
return function_file_path_txt
# List of tickers to analyze
tickers = ['AAPL', 'MSFT', 'NVDA', 'TSLA', 'MS', 'GS']
# Store returns for each stock
returns = {}
#call the function
#get the prices of AAPL, MSFT, NVDA, TSLA, MS, GS for last week
for t in tickers:
#3. calculate return
stock_return = calculate_return(t)
if stock_return is not None:
returns[t] = stock_return
else:
print(f"Not enough data for {t}")
#2. get the prices
print(get_price_lastweek(t))
file_name = writeData(t)
print(f'File saved: {file_name}')
#highest return
if(returns):
max_return_stock = max(returns, key=returns.get)
max_return_value = returns[max_return_stock]
# Print the result
print(f"The stock with the highest return during last week is {max_return_stock} with a return of {max_return_value * 100:.2f}%")
else:
print('The data of last week is empty')2. API without python library
(1) Rapid API
Rapid API Marketplace & Management Tools: Rapid API Marketplace & Management Tools
(2) example:
Live Metal Prices: https://rapidapi.com/not-null-solutions1-not-null-solutions-default/api/live-metal-prices/playground
link website: https://goldprice.org/
endpoind = api's function
import requests
url = "https://live-metal-prices.p.rapidapi.com/v1/latest"
headers = {
'x-rapidapi-key': "(put your own apikey)",
'x-rapidapi-host': "live-metal-prices.p.rapidapi.com"
}
response = requests.get(url, headers=headers)
print(response.json())III. Web Scraping
eg. URL: https://www.28hse.com/en/
1. extract the title of a house "property info" from a website
# html
(1) use url to get back to html using "import requests"
import requests
import bs4
#1. use the url
url = "https://www.28hse.com/en/rent/residential/property-3363466"
response = requests.get(url)
text = response.text
print(text)(2) import bs4
convert the text to html
html = bs4.BeautifulSoup(text, 'html.parser')
html.find("div", class_ = "header")
html.find_all("div", class_ = "header")
html.find_all("div", class_ = "header")[0]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









