






目录
前言
Spark-Shell是一个强大的交互式数据分析工具,初学者可以很好的使用它来学习相关API,用户可以在命令行下使用Scala编写Spark程序,并且每当输入一条语句,Spark-Shell就会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),Spark-Shell支持Scala和Python,如果需要进入Python语言的交互式执行环境,只需要执行“pyspark”命令即可。
一、spark的安装与配置
1.下载spark
为了保证稳定性和安全性,这里采用的是Spark3.5.2版本, 首先打开Spark存档网站:https://archive.apache.org/dist/spark 找到Spark3.5.2版本,点击下载,下载Linux版本的安装文件 spark3.5.2-bin-hadoop3.tgz 然后将下载的文件上传到 hadoop1 机器的 /export/software 目录 中,并在终端里切换到该目录为工作目录:cd /export/software

2.安装spark
在 hadoop1 机器上执行如下指令,进行Spark的安装: tar -zvxf spark-3.5.2-bin-hadoop3.tgz -C /export/servers/ 接着进入到Spark的安装目录,修改Spark的安装目录文件名为: spark-3.5.2 mv spark-3.5.2-bin-hadoop3 spark-3.5.2
3.配置环境变量
使用如下命令编辑环境变量文件: vim /etc/profile 在文件底部添加如下内容:
export SPARK_HOME=/export/servers/spark-3.5.2 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
使用 source 命令使修改的环境变量生效。
source /etc/profile
4.修改spark -env.sh文件
默认是没有这个文件的,只提供了一个模板文件,我们需要复制一 份模板文件作为此配置文件。 cp spark-env.sh.template spark-env.sh
接着我们再使用vim工具在此文件中添加如下内容:
# 配置Java环境 export JAVA_HOME=/export/servers/jdk1.8.0_241
# 指定Master的IP export SPARK_MASTER_HOST=hadoop1
# 指定Master的端口 export SPARK_MASTER_PORT=7077 export HADOOP_HOME=/export/servers/hadoop-3.3.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop 由于我们此前已配置了hosts,因此 SPARK_MASTER_HOST 可以直接设 置为 hadoop1
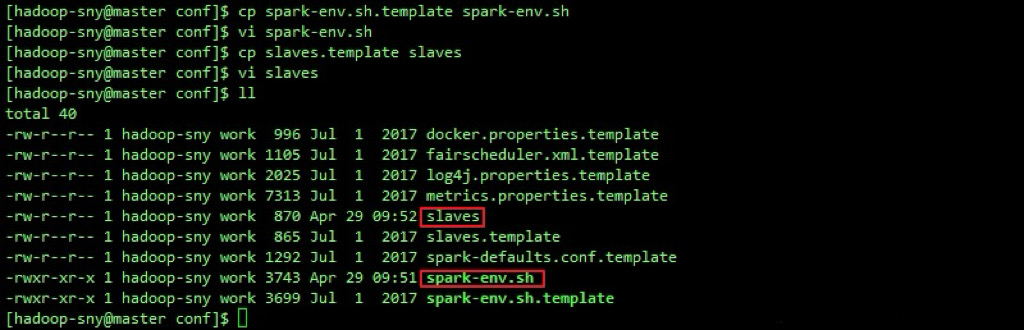
5.修改slaves文件
与 spark-env.sh 一样,默认值提供了 slaves.template 文件,所 以,我们需要先复制一份出来。 cp slaves.template slaves
接着用vim工具在直接在文件中添加slave机器的主机名: hadoop2 hadoop3 这里需要注意的是,如果这里添加了 hadoop1 或者没有删除 localhost ,那么hadoop1机器将既做master又做slave ,这里是不建议这样做的。
6.启动spark
/export/servers/spark-3.5.2/sbin/start-all.sh
二、spark shell操作
1.启动与关闭spark shell
a.启动 spark shell
spark-shell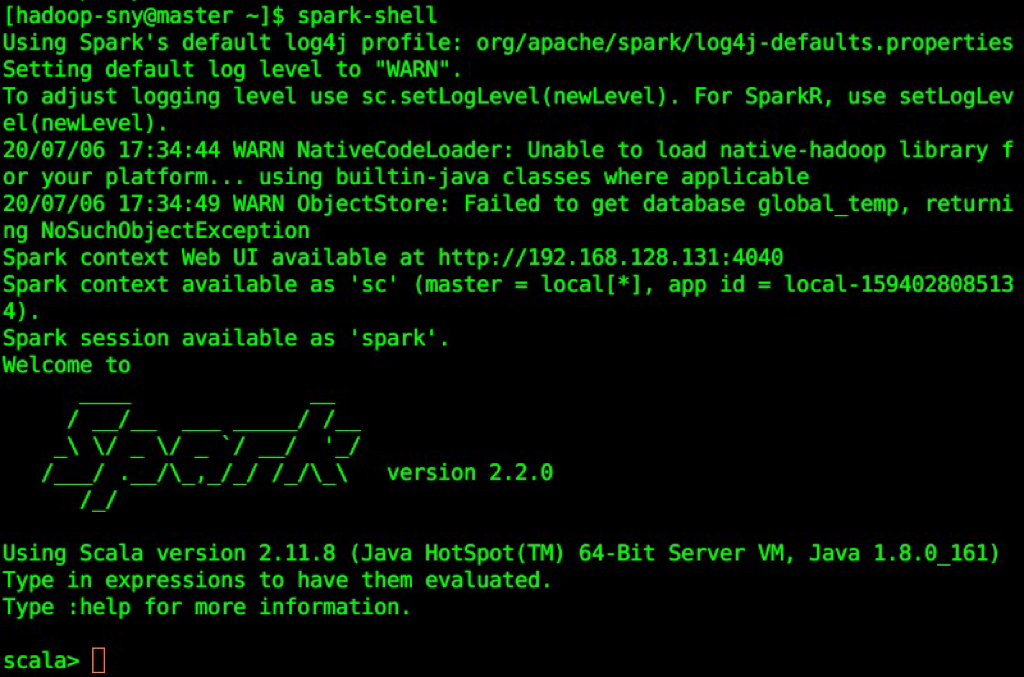
b.关闭spark shell
按ctrl+D即可退出
三、使用spark shell进行scala编程
1.读取spark内置数据
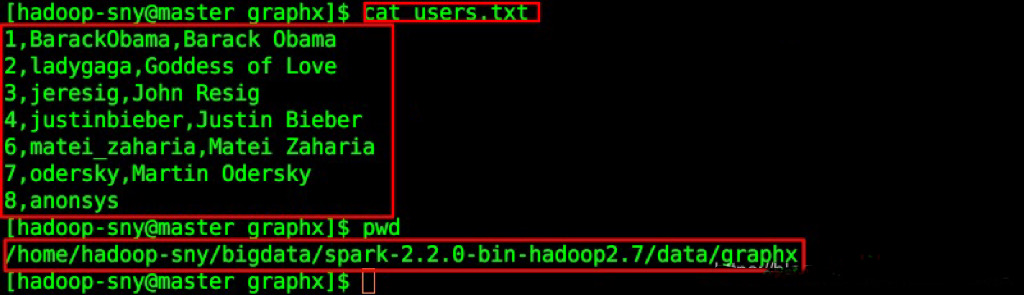
$SPARK_HOME/data/graphx/users.txt,
如我的位置是(需替换成自己实际的路径):/home/hadoop-sny/bigdata/spark-2.2.0-bin-hadoop2.7/data/graphx/users.txt
查看内容:
2.示例
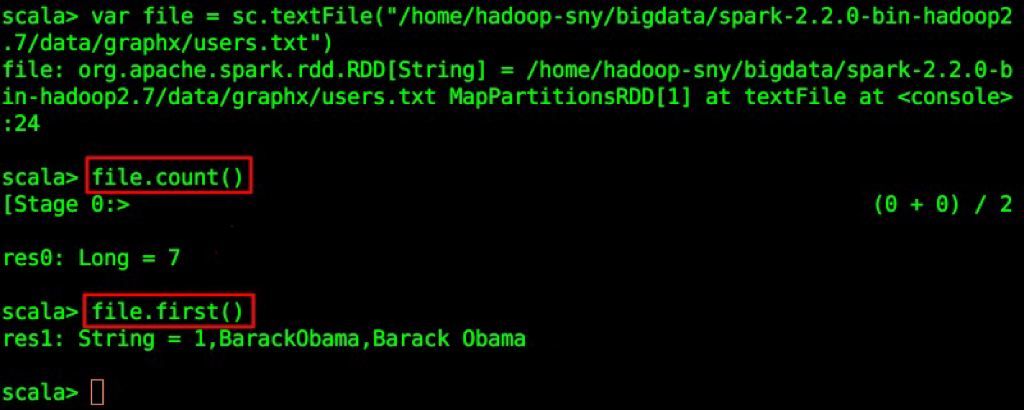
我们来统计一下users.txt文件一共有多少行,并且打印第一行内容,进入Spark Shell界面,输入内容:
var file = sc.textFile("/home/hadoop-sny/bigdata/spark-2.2.0-bin-hadoop2.7/data/graphx/users.txt")
file.count()
file.first()
代码解释:
创建了一个 RDD file;
count()获取 RDD 的行数;
first()获取第一行的内容。
四、pyspark初体验
1.启动与关闭pyspark
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
启动:pyspark
2.执行pyspark并查看结果
file = sc.textFile("/home/hadoop-sny/bigdata/spark-2.2.0-bin-hadoop2.7/data/graphx/users.txt")
file.count()
file.first()

总结
谢谢观看

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









