






目录
一、AdaBoost的标准实现中是否支持使用不同类型的基分类器?
(五) 网格调参寻找Adaboost中最优参数:n_estimators和learning_rate
本文旨在深入探索AdaBoost算法的标准实现,并解释如何通过网格搜索(GridSearchCV)对其及其基分类器(如决策树)的参数进行优化,以在分类任务中达到更高的准确率。我们将从AdaBoost的基本概念讲起,介绍其在Python中的实现方式,并通过一个实例详细展示如何划分训练集、选择基分类器、创建AdaBoost分类器、调参优化以及评估预测性能。本篇博客将帮助读者理解AdaBoost算法的调优步骤,并能够运用网格搜索技术寻找最优的模型参数,从而提高模型在实际应用中的预测精度。
一、AdaBoost的标准实现中是否支持使用不同类型的基分类器?
在标准的AdaBoost实现中,由于算法设计时假设所有的基分类器都是同质的,因此通常所有的基分类器都是同一类型。这意味着在同一个AdaBoost模型中,通常所有基分类器都是决策树、KNN或其他单一类型的分类器。
然而,一些变体的集成学习方法允许使用不同类型的基分类器。例如,Stacking(堆叠)是一种集成学习方法,它可以在不同的层中使用不同类型的分类器。在Stacking中,第一层的分类器可以是不同类型的,而第二层的分类器则使用第一层的分类器的输出作为输入。
对于AdaBoost来说,如果你想在一个模型中同时使用决策树和KNN,你需要使用一个允许混合不同类型基分类器的集成学习方法,而不是标准的AdaBoost。例如,你可以手动实现一个自定义的集成学习方法,它结合了AdaBoost的权重更新机制和不同类型的基分类器。
二、Adaboost的参数
在机器学习领域,Adaboost算法是一个强大的集成学习技术,它结合多个弱学习器来生成一个强大的预测模型。为了优化Adaboost算法的性能,有几个关键参数需要调整:
1. 估计器数量(n_estimators):此参数决定集成中包含的弱学习器的数量。增加估计器的数量通常能提高模型的性能,但也会增加计算时间和可能引起过拟合。通过交叉验证选择最优的估计器数量是一种常见的做法。
2. 学习率(learning_rate):学习率决定了每个弱学习器对最终模型的贡献比例。较小的学习率能使训练过程更慢,但有助于防止过拟合;较大的学习率虽然能加快训练速度,但也可能导致过拟合。这个参数通常与估计器数量一起调整以找到最佳平衡点。
3. 基础估计器选择(estimator):选择合适的基础估计器(弱学习器)非常关键,常用的如决策树桩(一层浅决策树)或简单的线性模型。不同的基础估计器可能对不同数据集的适应性各不相同,因此尝试多种基础估计器是有益的。
4. 基础分类器超参数:如果基础估计器有超参数(例如决策树的max_depth),调整这些参数也会影响AdaBoost模型的性能。
5. 随机种子(random_state):设置一个固定的随机种子可以确保实验的可重复性。但在超参数调优时,尝试不同的随机种子可以测试模型在不同随机初始化下的稳定性。
6. 交叉验证:交叉验证是超参数调整中不可或缺的一部分,可以帮助评估模型在未见数据上的性能,并防止在训练集上过拟合。使用网格搜索或随机搜索等技术可以有效探索超参数空间。
通过精心调整这些参数,可以显著提升Adaboost模型的性能,实现在各种数据集上的最优表现。
三、Python实现Adaboost
(一)导入库和数据集
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold# 导入鸢尾花数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 类别
feature_names = iris.feature_names # 特征名称
class_names = iris.target_names # 类别名称(二) 划分训练集
# 将数据集划分为训练集和测试集,比例为 8:2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)(三)选择基分类器--决策树
# 首先创建基础分类器
base_estimator = DecisionTreeClassifier(criterion="entropy", max_depth=2, min_samples_split=2, min_samples_leaf=2, random_state=0)(四)创建Adaboost分类器
# 然后创建 AdaBoost 分类器实例
ada_classifier = AdaBoostClassifier(estimator = base_estimator,random_state=0)
# ada_classifier.base_estimator = base_estimator(五) 网格调参寻找Adaboost中最优参数:n_estimators和learning_rate
# 定义参数网格
param_grid = {
'n_estimators': [10, 20, 30,40,50],
'learning_rate': [0.01, 0.02,0.001]
}
(六)创建 GridSearchCV 对象并执行网格搜索
# 创建 GridSearchCV 对象
grid_search = GridSearchCV(estimator=ada_classifier, param_grid=param_grid, cv=5, scoring='accuracy')
# 执行网格搜索
grid_search.fit(X_train, y_train)(七)获取最优参数和最佳准确率
# 获取最佳参数和最佳准确率
best_params = grid_search.best_params_
best_score = grid_search.best_score_(八) 打印最佳参数和最佳准确率
# 打印最佳参数和最佳准确率
print("Best parameters:", best_params)
print("Best cross-validation score (accuracy):", best_score)(九) 使用最佳参数训练AdaBoost分类器
best_ada_classifier = AdaBoostClassifier(estimator = base_estimator,random_state=0,n_estimators=best_params['n_estimators'], learning_rate=best_params['learning_rate'])
best_ada_classifier.fit(X_train, y_train)
(十) 进行预测并计算准确率
# 使用训练好的AdaBoost分类器进行预测
predictions = best_ada_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
# 打印准确率
print("Accuracy with best parameters:", accuracy)![]()
(十一) 输出评估报告
from sklearn.metrics import accuracy_score, classification_report
print('模型的准确率为:\n', accuracy_score(y_test, predictions))
print('模型的评估报告:\n', classification_report(y_test, predictions))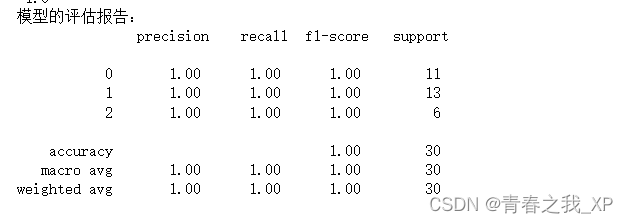
补充:为什么改变基础弱分类器的参数,Adaboost的准确率不变?
当你改变决策树(base_classifier)的参数,例如criterion、max_depth、min_samples_split和min_samples_leaf,实际上是在改变每个基础分类器的性能。然而,AdaBoostClassifier的fit方法会根据给定的estimator(这里就是基础弱分类器)训练多个弱分类器,并对它们的权重进行调整。如果这些基础模型的性能变化不明显,或者它们之间有很好的互补性,那么整个AdaBoost模型的组合效果可能不会显著提升准确率。
















 2003
2003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









