







目录
引言:
本文主要围绕C语言浮点数的相关知识,就浮点数在内存中的存储,浮点数的double和float类型书写时的注意以及《C语言深度解剖》这本书中“浮点数与0 的比较”章节的内容展开。
浮点数在内存中的存储
对于浮点数的储存就是搞懂三个量,我们知道常见的浮点数有3.14159,有用科学计数法写的1E10等,包括的类型也比较丰富如float ,double,long double。并且当我们使用printf函数分别借助%f,%d打印同一个数时,结果也会不同,原因还是归结于整型和浮点型在内存中不同的存储形式。浮点数在内存中的存储由国际标准IEEE(电气和电子工程协会)754规定,虽然刚开始可能难以理解,但确实可以从中发觉到人类智慧的结晶。

对于浮点数的存储分如图三个部分,用于表示正负的数存在第一位,有效数字,即将待存储的二进制数字转化成科学计数法表示后,小数点后的所有数字,应该注意的是这里不包括小数点前面的那一位数字,因为对于小数点前的数,在使用科学计数法时,只要储存的不是0.0000000,那么这个数就一定是1。这就是最体现智慧的地方,为了尽可能的多存储数字,省略储存这个1 的 位,把空间留给小数点后面的数,也就是有效数字。(以下是32位浮点数和64位浮点数在内存中的分配情况)
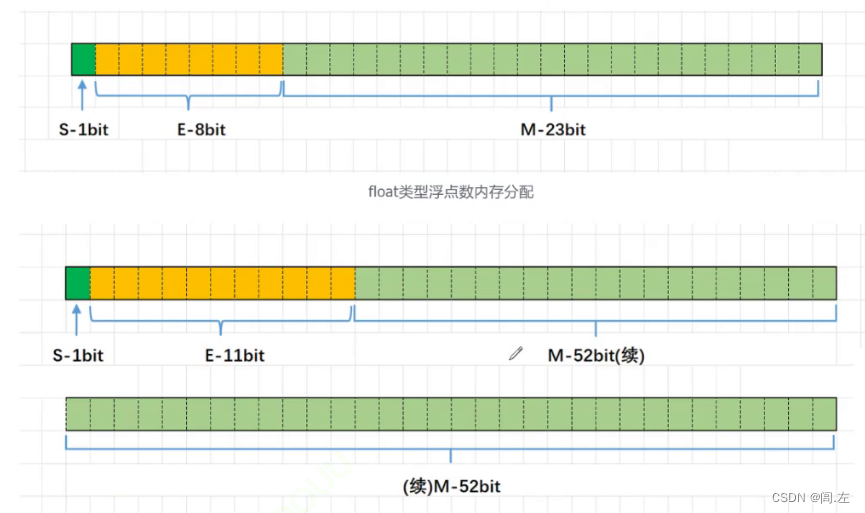
对于E我们先给结论,规定当存入E的真实值之前,对32位浮点型需加上127,对4位,需加上1023用E表示指数位,正好与科学计数法互补,同时E的值也会更复杂,因为在前面的科学计数法中如果待存储的数是一个很大的数,那自然E会是一个正数,如果这个数字很小,E就有可能是负数。所以,为解决这个问题,IEEE754创造性的提出了中间数来弥补这个漏洞,因为如果我们也像存储整个待存储的数字的符号一样,又使用一个S势必会浪费一个空间。
值得注意的是在32位浮点数的存储中,E可以占到8个比特位,可表示的正数范围是0~255,而中间数字是127,所以实际E的值可以是-127~128,可能是考虑到E如果在[ -255,-127 )和( 128,255 ]以内的话,表示的数字太小或太大,故规定中间数为127,真的十分巧妙。64位同理。
注意
E的值有时会出现极端情况,比如全是1,或者全是0,对于这个的解释为个人理解,但结论正确。其实这种情况很好理解,全为0时,不是这个数有问题,其实只要E再多给几位空间,就可以看到这个数真正的E值了,即这个数字太小,小到它的指数位已经超过了E所能存储的最小数(该数的E为负),这样的数已经是不常用的了,所以将它们打包为一个抽象的数,即接近于0的很小的数字,同理全为1,表示无穷大的数。
总结
总的来说,就是浮点数在内存中的存储分三个部分,用来记录数字正负的S,用来表示科学计数法处理后,数字的小数位的E,但注意加中间数32位是127,64位是1023。然后是表示科学计数法处理后,小数点后的二进制数字的值的M。
感想
其实万物都是相通的,人类对一类问题能想到的解决方法也是类似的,就比如色环电阻,因为对于一个实际生产出来的电阻,肯定是有误差值,实际电阻值,和理论电阻值的,而有时候电阻的实际大小不允许将这些值刻在电阻元件上。为了解决这些问题,仍然是使用类似于内存存储浮点数的方法。通过编码,即不同的色环代表不同的数字,将这些环划分成两个区域,四个色环,离另外三个色环较远的色环储存的是误差范围,另外三个中,前两个是理论电阻的有效位,第三个是指数位,这一次的对象是几种常见的颜色(虽然对色盲不太友好),听起来和浮点数在内存中的存储很相似。可能对于我们存在的这物理世界,问题从来都不是孤立的,一类钥匙打开一类门的锁。这也提醒我们知识的学习与储备,更应该是T字型的,要有广度,对于非专业领域而言,又要有深度,对自己深耕的领域。
double与float的书写注意
在书写C语言代码中我们经常看到诸如"float a = 2.718281828f"的写法,但使用double时却不用多写f,原因是根据规定,当我们输入带小数点的数字的时候,C语言就默认其为double类型。而double类型在内存中的存储和float是有差别的,必须先有空间再有数据,这里空间和数据的大小不匹配,就可能发生数据的截断如图:

这里编译器识别到这个错误,并且报警告,为了不让编译器报警告,我们人为的在float类型定义的小数后面加字母f,目的是告诉编译器我需要的是一个float类型的空间。
“浮点数与0 的比较”
本节参考《深度解剖C语言》,介绍了当浮点数与浮点数之间比较会发生的现象,及其原因。有兴趣的可以直接观看比特蛋哥讲解的浮点数部分,也可以听我细细道来。
由上两节可知计算机对浮点数的储存是有别于人的主观直觉以及整型变量的,但不可谓不是人类智慧的结晶,让人热血澎湃。这也就带来了一系列与浮点数有关的独特现象,而透过这些现象,我们也更能对浮点数有一个深刻领悟。
现象
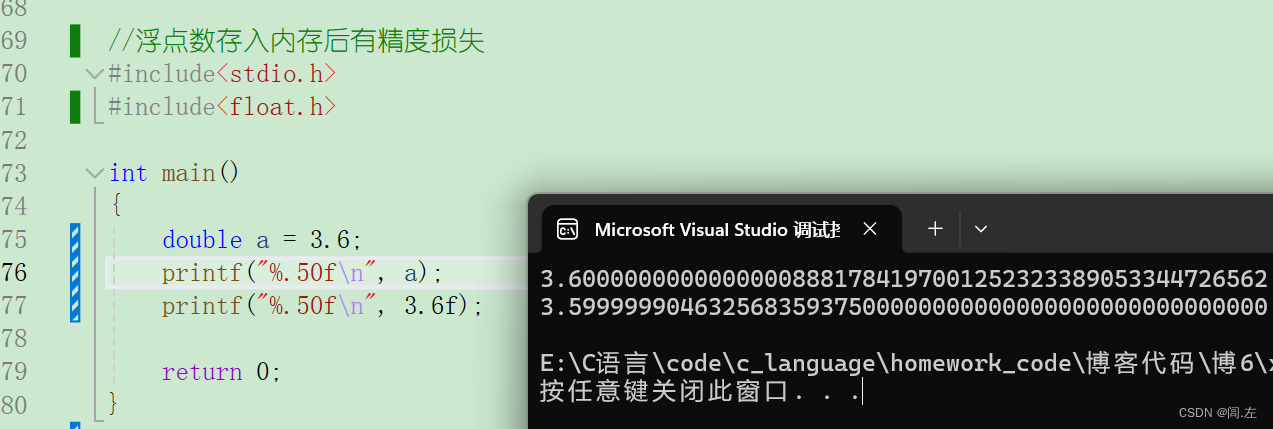
- 浮点数在存入内存后,因为浮点数特殊的存储规则,会有精度损失,这种损失不一定是减小,还有可能使得原数字增大如图所示:
- 浮点数是不能直接用" == "号比较的代如图所示:
 可见如果按常理,1-0.9答案就是0.1,这里就应该输出“Yes”,但因为浮点数在内存中有精度损失,使得==失效,需要注意的是,浮点数不能用==比较不是说==不起作用,而是不能用其直接进行比较,在这里如果需要比较两个浮点数的大小,可以通过自己拟定一个精度区间,或者使用C语言自带的系统精度区间,只要待比较的操作数相减得到的值在目标的精度区间内,就视为两数相等。下文将着重对这一点进行介绍。
可见如果按常理,1-0.9答案就是0.1,这里就应该输出“Yes”,但因为浮点数在内存中有精度损失,使得==失效,需要注意的是,浮点数不能用==比较不是说==不起作用,而是不能用其直接进行比较,在这里如果需要比较两个浮点数的大小,可以通过自己拟定一个精度区间,或者使用C语言自带的系统精度区间,只要待比较的操作数相减得到的值在目标的精度区间内,就视为两数相等。下文将着重对这一点进行介绍。
精度区间
本节将具体介绍如何使用自主拟定的精度区间和C语言头文件中给我们定义好的精度(需要引用<float.h>头文件)DBL_EPSLION(double类型比较),FLT_EPSILON(float类型比较),同时会涉及到一个新函数fabs求绝对值函数,需要引用头文件<math.h>。
其实精度区间就相当于整型比较时的0,所以这个“ 0 ”应该越小越好,两个整数相减大于零则减数大,被减数小。而为了弥补浮点数的精度损失,在比较时才需要这个区间,所以不管是人为定义的,还是使用本身定义好的,其本质目的都是需要精度区间充当0的作用。
自主设置精度区间
结果如图:
使用#define 定义EPS作为精度,注意111行 也可以优化使用fabs这个函数,取绝对值。
也可以优化使用fabs这个函数,取绝对值。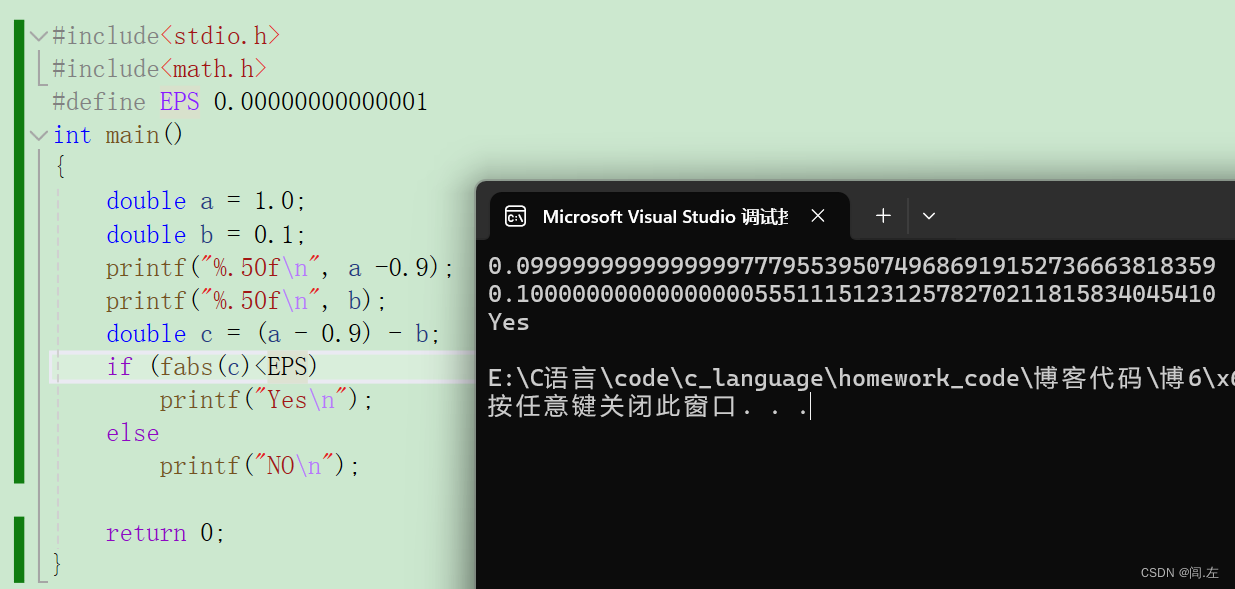
使用C语言自带的精度区间
在<float.h>头文件中,分别定义了DBL_EPSLION,FLT_EPSILON,用来帮助我们比较double和float类型的浮点数。EPSILON实际是希腊字母ε,中文读作伊普西隆,在数学中一般指非常小的数,普朗克常数也是这个符号。
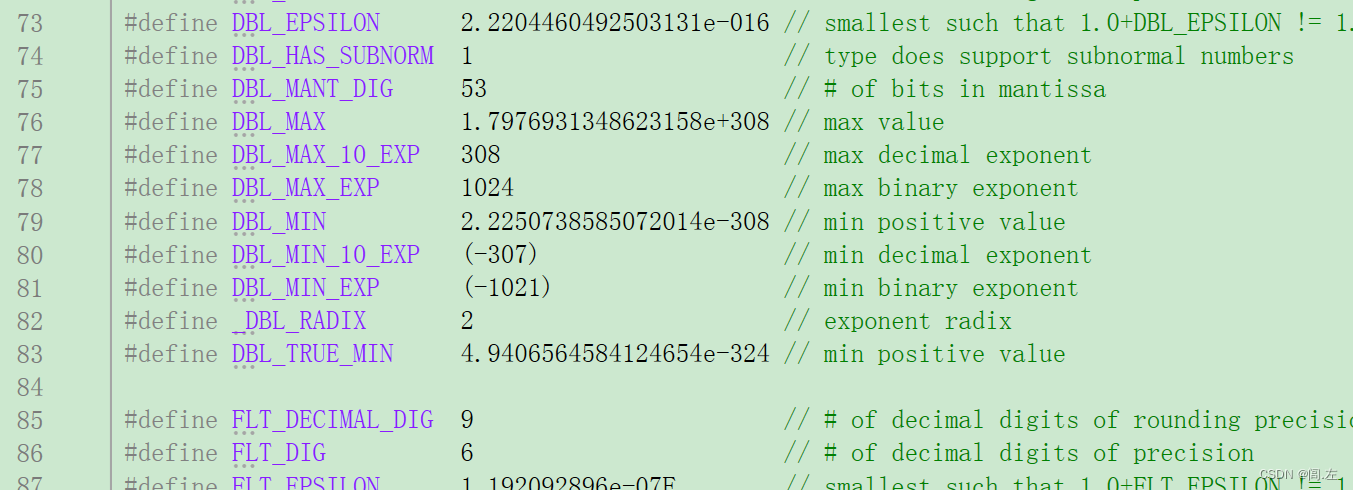
转到C语言定义,在73行,简而言之就是1加上任何数字都会大于1本身,但这里的DBL_EPSLION是任何数字中那个最小的数字,这也符合精度区间越小越好的规律。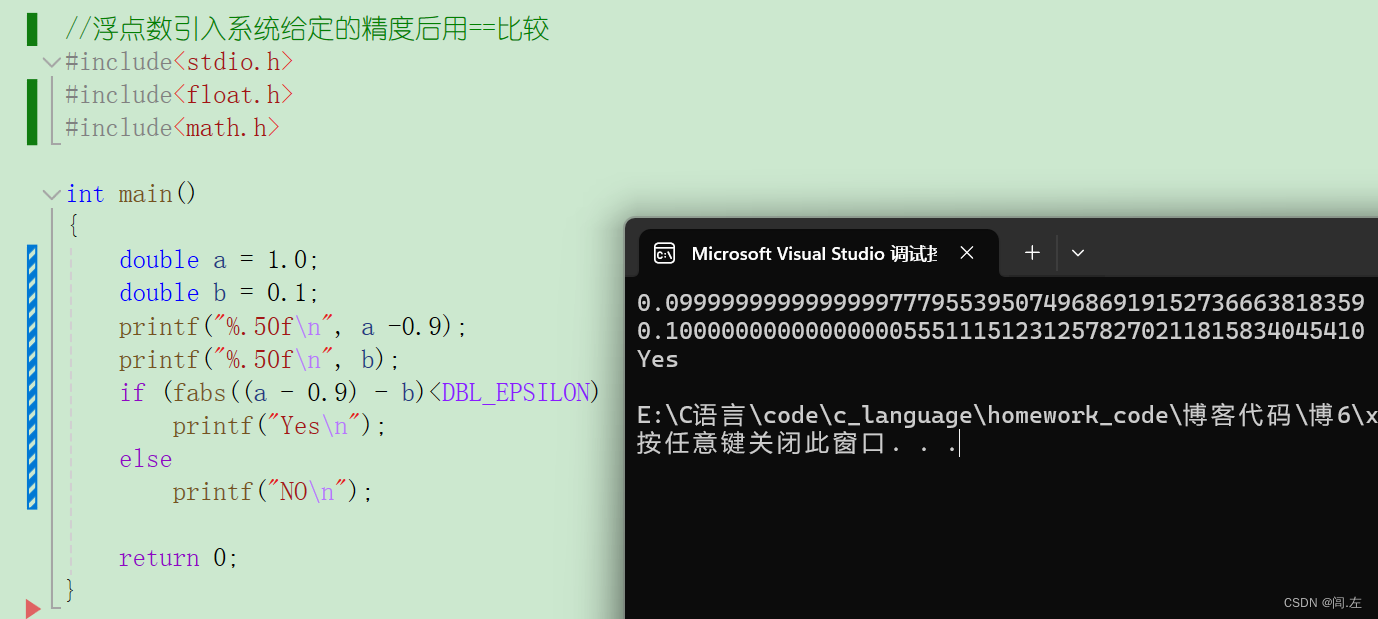
如图使用DBL_EPSLION结果正确。
最后回到标题浮点数与0的比较,其实这个就更简单了,只需要再上图的基础上将fabs函数中的内容改为待比较的数字就完成了。
补充
在这里,我们还可以思考一个比较细的内容,在fabs((a - 0.9) - b)< DBL_EPSILON中是使用小于号好还是使用小于等于号好?这就要强调之前讲过的一个问题, DBL_EPSILON的作用是充当浮点数比较时的0,也就是说,这个区间越小越好,最好就是0,而如果加上等号无疑是扩大了范围,所以建议是不要加上等号。
幸甚至哉,歌以永志。















 2299
2299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









