






Task1 数据加载
数据载入
在Python环境下安装pandas和numpy这两个库
!pip install pandas
!pip install numpy
导入numpy和pandas
import pandas as pd
import numpy as np
载入数据
相对路径和绝对路径
1.相对路径:指文件相对于当前工作目录所在的位置
/代表根目录 ./代表当前所在的目录 ../代表上一层目录
获取相对路径:
2.绝对路径:总是从根文件夹开始
①Window系统中以盘符(C: 、D:)作为根文件夹
②OS X或者Linux系统中以 / 作为根文件夹
获取绝对路径:
①在windows上可以通过Ctrl+Shift+C获取文件的绝对路径
②
import os
path1 = os.path.abspath('.') # 获取当前所处的文件夹的绝对路径
path2 = os.path.abspath('..') # 获取当前所处的文件夹上一级文件夹的绝对路径(1) 使用相对路径载入数据
df = pd.read_csv('train.csv') #csv文件
(2) 使用绝对路径载入数据
df = pd.read_csv(r'C:\Users\lenovo\Desktop\Pandas\train.csv')
每1000行为一个数据模块,逐块读取
在pandas中,逐块读取通常是通过read_csv函数实现的,该函数提供了chunksize参数,用于指定每次迭代时读取的行数。
当设置了chunksize参数后,read_csv函数返回的不再是一个完整的DataFrame,而是一个可迭代的对象 。
逐块读取后,如果需要将所有块合并回一个完整的DataFrame,可以使用pd.concat函数。
chunker = pd.read_csv('./your_data.csv',chunksize=1000)将表头改成中文,索引改为乘客ID
将表头改成中文
方法一:
# 假设你有一个名为data的DataFrame
data.columns = ['中文名称 1', '中文名称 2', '中文名称 3', ...]1.确保数据文件的编码是UTF-8,这样可以正确处理中文字符。
2.使用read_csv函数读取数据时,可以通过header参数指定使用哪一行作为表头。如果数据文件中第一行已经是中文表头,则设置header=0。
方法二:
使用rename参数:读取数据后,使用rename方法将列名从英文改为中文。可以使用传递一个字典给rename的方法,字典的键是原列名,值是新的中文列名。
df = pd.read_csv('your_data.csv')
new_columns = {'Original English Name 1':'中文名称 1','Original English Name 2':'中文名称 2','Original English Name 3':'中文名称 3',...}
df = df.rename(columns=new_columns)
方法三:
使用names参数:在使用read_csv函数读取数据时,可以通过names参数直接指定一个数组作为新的列名,这些列名将成为DataFrame的表头。
import pandas as pd
df = pd.read_csv('your_data.csv', header=None, names=['中文名称 1', '中文名称 2', '中文名称 3', ...])索引乘客ID
pd.read_csv()参数及其功能:
index_col:指定哪一列或列的编号作为行索引。如果设置为 None,则使用文件中的行号作为索引。
df = pd.read_csv('your_data.csv',index_col='乘客ID')
初步观察
查看数据的基本信息
1.查看DataFrame的形状:使用shape属性可以获得DataFrame的行数和列数。
df.shape 2.查看DataFrame的数据类型:使用dtypes属性可以查看DataFrame中每列的数据类型。
df.dtypes3.查看DataFrame的非空计数:使用info方法可以查看DataFrame中非空值的计数以及每列的数据类型和内存使用情况。
df.info()4.查看DataFrame的汇总统计信息:使用describe方法可以获得数值型列的汇总统计信息(计数、平均值、标准差、最小值、四分位数和最大值)
df.describe()5.查看DataFrame的前几行或后几行数据:使用head和tail方法可以分别查看DataFrame的前几行和后几行数据
df.head(n) # 默认显示前5行
df.tail(n) # 默认显示最后5行判断数据是否为空,为空的地方返回True,其余地方返回False
在Pandas中,可以使用isnull()方法或其别名isna(),这两个方法会返回一个与原DataFrame大小相同的布尔型DataFrame,其中空值的地方返回True,非空值的地方返回False。
df.isnull().head(n) # 前n行数值保存数据
1.确保已经导入了Pandas库,并且有一个名为df的DataFrame变量,它包含了你想要保存的数据。
2.使用to_csv方法将DataFrame保存到一个新的CSV文件中。可以指定文件的路径和文件名。
①如果想在当前工作目录下保存文件,可以直接提供文件名。
②如果不希望在新文件中包含原始DataFrame的索引,可以将index参数设置为False。
import pandas as pd
# 假设df是您已经更改过的DataFrame
# ...(在这里进行数据更改)...
# 将更改后的DataFrame保存到新的CSV文件中,不包含索引
df.to_csv('changed_data.csv', index=False)Task2 Pandas基础
对列的操作
查看DataFrame数据的每列的名称
df.columns查看"Cabin"这列的所有值
df['Cabin']
# 或者
df.Cabin删除某一列
方法一:
使用drop方法:通过指定列名来删除一列。
import pandas as pd
# 假设df是你的DataFrame对象,'column_name'是你想要删除的列的名称
df_dropped = df.drop('column_name', axis=1)
# 打印删除列后的DataFrame
print(df_dropped)方法二:
使用del关键字:使用del关键字直接删除列。这种方法会直接在原DataFrame上进行修改,而不是创建一个新的DataFrame。
import pandas as pd
# 假设df是你的DataFrame对象,'column_name'是你想要删除的列的名称
del df['column_name']
# 打印删除列后的DataFrame
print(df)方法三:
使用pop方法:pop方法也可以用来删除列,并且它会返回被删除的列。
import pandas as pd
# 假设df是你的DataFrame对象,'column_name'是你想要删除的列的名称
popped_column = df.pop('column_name')
# 打印删除列后的DataFrame
print(df)
# 打印被删除的列
print(popped_column)隐藏某一列
在不改变原始DataFrame的情况下临时隐藏数据,可以使用drop函数结合inplace参数,并将axis参数设置为0。这样做不会从DataFrame中移除数据,而是在显示时隐藏它们。
# 假设df是您的DataFrame对象
# 隐藏单个列
df.drop('column_name', axis=0, inplace=True)
# 隐藏多个列
df.drop(['column_name1', 'column_name2'], axis=1, inplace=True)在上述代码中,inplace=True参数指示Pandas直接修改原始的DataFrame,而不是返回一个新的DataFrame对象。axis=1表示操作的是列,axis=0表示操作的是行,因此在这种情况下,它会影响到列的可见性而不是实际删除列。
筛选的逻辑
以"Age"为筛选条件,显示年龄在10岁以下的乘客信息
df[df['Age']<10]以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = df[(df['Age']>10)&(df['Age']<50)]将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage.loc[[100],['Pclass','Sex']]使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.loc[[100,105,108],['Pclass','Name','Sex']]使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.iloc[[100,105,108],[2,3,4]]Task3 探索性数据分析
了解数据
构建一个都为数字的DataFrame数据
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),index=['2', '1'],columns=['d', 'a', 'b', 'c'])
# 【代码解析】
# pd.DataFrame() :创建一个DataFrame对象
# np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
# index=['2, 1] :DataFrame对象的索引列
# columns=['d', 'a', 'b', 'c'] :DataFrame对象的索引行输出结果为:

将你构建的DataFrame中的数据根据某一列,升序排列
在Pandas中,可以使用sort_values()方法根据DataFrame中的某一列对数据进行排列。默认情况下,sort_values()会执行升序排序,但可以通过设置ascending=False参数来进行降序排序。
sort_values函数中by参数指向要排列的列,ascending参数指向排序的方式(升序还是降序)。
frame.sort_values(by='c',ascending=True) # 根据 c 列升序排序
frame.sort_values(by='c',ascending=False) # 根据 c 列降序排序将不同的排序方式做一个总结
1.让行索引升序排序
frame.sort_index()2.让列索引升序排序
frame.sort_index(axis=1)3.让列索引降序排序
frame.sort_index(axis=1,ascending=False)4.让任选两列(a和c列)数据同时降序排序
frame.sort_values(by=['a','c'],ascending=False)利用Pandas计算两个DataFrame数据相加结果
# 创建两个DataFrame
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame1_a
frame1_b输出结果为:
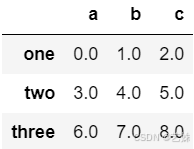
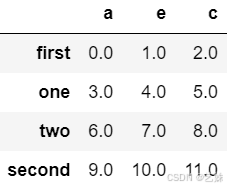
# 方法一:使用 + 运算符
frame1_a + frame1_b
# 方法二:使用add()
frame1_a.add(frame1_b)输出结果为:
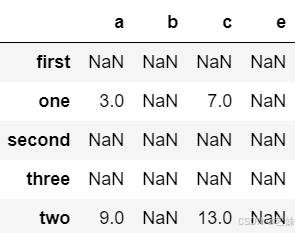
两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
假设你有一个名为text的DataFrame,其中包含'A'和'B'两列,计算'A'和'B'两列和的最大值
max(text['A']+text['B'])Task4
代码解析
分别将单属性与双属性的妖怪在当前目录下存储为不同csv文件
data = pd.read_csv('./pokemon.csv')
single = data[data['属性二'].isnull()]
single.drop(columns=['属性二'])
single.to_csv('./single.csv',index=False)
代码解析:
代码的目的是从原始DataFrame中筛选出具有单个属性的妖怪,并将这些妖怪的数据保存到一个名为 'single.csv' 的CSV文件中。
1.single = data[data['属性二'].isnull()]
这行代码使用了Pandas的布尔索引来选择原始DataFrame data中 '属性二' 列值为 NaN 的所有行。isnull() 函数返回一个布尔系列,指示每个元素是否为缺失值(NaN),然后通过索引操作选择出所有匹配的行,形成一个新的DataFrame single。
2.single.to_csv('./single.csv', index=False)
这行代码将修改后的 single DataFrame 保存到本地文件系统中的当前目录,文件名为 'single.csv'。index=False 参数指示在保存时不包括行索引。
dual = data[data['属性二'].notnull()]
dual.drop(columns=['属性一'])
dual.to_csv('./dual.csv',index=False)代码解析:
代码的目的是从原始DataFrame中筛选出具有双属性的妖怪,并将这些妖怪的数据保存到一个名为 'dual.csv' 的CSV文件中。
①dual = data[data['属性二'].notnull()]
这行代码使用了Pandas的布尔索引来选择原始DataFrame data中 '属性二' 列值不为 NaN 的所有行。notnull()函数返回一个布尔系列,指示每个元素是否为非缺失值(即非 NaN),然后通过索引操作选择出所有匹配的行,形成一个新的DataFrame dual。
②dual.to_csv('./dual.csv', index=False)
这行代码将筛选后的 dual DataFrame 保存到本地文件系统中的当前目录,文件名为 'dual.csv'。index=False 参数指示在保存时不包括行索引。
输出 DataFrame data 中每列有多少个不同的值
print(data.nunique())代码解析:
data: 这是一个 DataFrame 对象,它包含了多个列的数据。 .nunique(): 这是 Pandas DataFrame 的一个方法,用于计算每列中唯一值的数量。它返回一个 Series,其中索引是列名,值是该列中唯一值的数量。

















 8171
8171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









