DQN
1、Core network structure
class DqnConvNet(nn.Module):
"""DQN Conv2d network."""
def __init__(self, state_dim: tuple, action_dim: int):
super().__init__()
self.body = common.NatureCnnBackboneNet(state_dim)
self.value_head = nn.Sequential(
nn.Linear(self.body.out_features, 512),
nn.ReLU(),
nn.Linear(512, action_dim),
)
common.initialize_weights(self)
def forward(self, x: torch.Tensor) -> DqnNetworkOutputs:
x = x.float() / 255.0
x = self.body(x)
q_values = self.value_head(x)
return DqnNetworkOutputs(q_values=q_values)
1.1、Key components
class NatureCnnBackboneNet(nn.Module):
"""DQN Nature paper conv2d layers backbone"""
def __init__(self, state_dim: tuple):
super().__init__()
c, h, w = state_dim
h, w = calc_conv2d_output((h, w), 8, 4)
h, w = calc_conv2d_output((h, w), 4, 2)
h, w = calc_conv2d_output((h, w), 3, 1)
self.out_features = 64 * h * w
self.net = nn.Sequential(
nn.Conv2d(c, 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
2、Agent initialization
class Dqn(types_lib.Agent):
def __init__(
network, optimizer, replay, exploration_epsilon,
batch_size=32, discount=0.99, target_net_update_interval=2500,
...
):
self._online_network = network # 在线网络
self._target_network = copy.deepcopy(network) # 目标网络
self._replay = replay # 经验回放
self._exploration_epsilon = exploration_epsilon # ε-greedy策略
3、Key training logic
3.1、 Experience replay sampling
transitions = self._replay.sample(self._batch_size)
3.2、Loss calculation
def _calc_loss(transitions):
# 当前状态Q值
q_tm1 = self._online_network(s_tm1).q_values
# 目标Q值(使用目标网络)
with torch.no_grad():
target_q_t = self._target_network(s_t).q_values
# TD误差计算
loss = rl.qlearning(q_tm1, a_tm1, r_t, discount_t, target_q_t).loss
3.3、Target network update
def _update_target_network(self):
self._target_network.load_state_dict(self._online_network.state_dict())
4、Exploration strategy
def _choose_action(self, timestep, epsilon):
if random() <= epsilon: # 随机探索
return random_action
else: # 贪心策略
return argmax(q_values)
5、Training process
main_loop.run_single_thread_training_iterations(
num_iterations=100,
num_train_steps=500000,
num_eval_steps=20000,
train_agent=train_agent,
eval_agent=eval_agent
)
6、Key hyperparameters
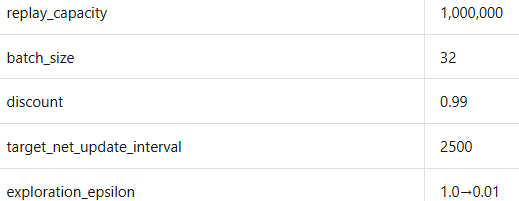
RAINBOW
1、Core Network Structure
class RainbowDqnConvNet(nn.Module):
def __init__(self, state_dim, action_dim, atoms):
super().__init__()
self.action_dim = action_dim
self.num_atoms = atoms.size(0)
self.atoms = atoms
# 特征提取层
self.conv1 = nn.Conv2d(state_dim[0], 32, kernel_size=8, stride=4)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
# 噪声线性层
self.advantage_hidden = NoisyLinear(3136, 512)
self.advantage_out = NoisyLinear(512, action_dim * self.num_atoms)
self.value_hidden = NoisyLinear(3136, 512)
self.value_out = NoisyLinear(512, self.num_atoms)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.size(0), -1)
# Dueling架构
advantage = F.relu(self.advantage_hidden(x))
advantage = self.advantage_out(advantage).view(-1, self.action_dim, self.num_atoms)
value = F.relu(self.value_hidden(x))
value = self.value_out(value).view(-1, 1, self.num_atoms)
# 组合输出
q_logits = value + advantage - advantage.mean(1, keepdim=True)
q_values = torch.sum(F.softmax(q_logits, dim=-1) * self.atoms, dim=-1)
return q_values, q_logits
2、Agent Initialization
def __init__(self, network, optimizer, atoms, replay, transition_accumulator,
batch_size, min_replay_size, learn_interval, target_net_update_interval,
n_step, discount, clip_grad, max_grad_norm, device):
self._online_network = network.to(device)
self._target_network = copy.deepcopy(network).to(device)
self._optimizer = optimizer
self._replay = replay
self._transition_accumulator = transition_accumulator
self._atoms = atoms.to(device)
# 训练参数
self._batch_size = batch_size
self._min_replay_size = min_replay_size
self._learn_interval = learn_interval
self._target_net_update_interval = target_net_update_interval
self._n_step = n_step
self._discount = discount
self._clip_grad = clip_grad
self._max_grad_norm = max_grad_norm
3、Key Training Logic
def _learn(self):
# 从优先回放中采样
transitions, indices, weights = self._replay.sample(self._batch_size)
# 计算损失并更新
self._optimizer.zero_grad()
losses, priorities = self._calc_loss(transitions)
loss = torch.mean(losses * weights.detach())
loss.backward()
# 梯度裁剪
if self._clip_grad:
torch.nn.utils.clip_grad_norm_(
self._online_network.parameters(),
self._max_grad_norm
)
self._optimizer.step()
# 更新目标网络
if self._update_t % self._target_net_update_interval == 0:
self._update_target_network()
# 更新优先级
self._replay.update_priorities(indices, priorities)
4、Exploration Strategy
class NoisyLinear(nn.Module):
def reset_noise(self):
epsilon_in = self._scale_noise(self.in_features)
epsilon_out = self._scale_noise(self.out_features)
self.weight_epsilon.copy_(epsilon_out.ger(epsilon_in))
self.bias_epsilon.copy_(epsilon_out)
def forward(self, x):
if self.training: # 训练时添加噪声
return F.linear(x,
self.weight_mu + self.weight_sigma * self.weight_epsilon,
self.bias_mu + self.bias_sigma * self.bias_epsilon)
else: # 评估时使用确定性权重
return F.linear(x, self.weight_mu, self.bias_mu)
5、Training Process
def step(self, timestep):
self._step_t += 1
# 1. 选择动作
a_t = self._choose_action(timestep)
# 2. 存储转移
for transition in self._transition_accumulator.step(timestep, a_t):
self._replay.add(transition, priority=self._max_seen_priority)
# 3. 学习
if self._replay.size >= self._min_replay_size and self._step_t % self._learn_interval == 0:
self._learn()
return a_t
6、Key Hyperparameters
# 从文档2中提取的主要超参数
flags.DEFINE_integer('num_atoms', 51, 'Number of atoms for distributional RL')
flags.DEFINE_float('v_min', -10.0, 'Minimum value for support')
flags.DEFINE_float('v_max', 10.0, 'Maximum value for support')
flags.DEFINE_integer('n_step', 5, 'TD n-step bootstrap')
flags.DEFINE_integer('replay_capacity', int(1e6), 'Replay buffer size')
flags.DEFINE_integer('batch_size', 32, 'Training batch size')
flags.DEFINE_float('discount', 0.99, 'Discount factor')
flags.DEFINE_float('learning_rate', 0.00025, 'Learning rate')
flags.DEFINE_integer('target_net_update_interval', 2500, 'Target network update interval')
flags.DEFINE_float('priority_exponent', 0.6, 'Priority exponent')
PPO
1、Core Network Structure
class ActorCriticConvNet(nn.Module):
def __init__(self, state_dim, action_dim):
self.body = common.NatureCnnBackboneNet(state_dim) # 3层CNN + Flatten
self.policy_head = nn.Sequential(
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, action_dim)
)
self.value_head = nn.Sequential(
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, 1)
)
2、Agent Initialization
# 创建学习器
learner_agent = agent.Learner(
policy_network=policy_network,
policy_optimizer=policy_optimizer,
clip_epsilon=clip_epsilon_scheduler,
discount=FLAGS.discount,
gae_lambda=FLAGS.gae_lambda,
total_unroll_length=int(FLAGS.unroll_length * FLAGS.num_actors),
update_k=FLAGS.update_k,
entropy_coef=FLAGS.entropy_coef,
value_coef=FLAGS.value_coef,
clip_grad=FLAGS.clip_grad,
max_grad_norm=FLAGS.max_grad_norm,
device=runtime_device,
shared_params=shared_params,
)
# 创建多个actor
actors = [
agent.Actor(
rank=i,
data_queue=data_queue,
policy_network=copy.deepcopy(policy_network),
unroll_length=FLAGS.unroll_length,
device=actor_devices[i],
shared_params=shared_params,
)
for i in range(FLAGS.num_actors)
]
3、Key Training Logic
#训练更新逻辑
def _calc_loss(self, transitions: Transition) -> torch.Tensor:
# 计算策略损失
pi_logprob_a_t = pi_dist_t.log_prob(a_t)
ratio = torch.exp(pi_logprob_a_t - behavior_logprob_a_t)
policy_loss = rl.clipped_surrogate_gradient_loss(ratio, advantage_t, self.clip_epsilon).loss
# 计算价值函数损失
value_loss = rl.value_loss(returns_t, v_t).loss
# 计算熵损失
entropy_loss = pi_dist_t.entropy()
# 组合损失
loss = -(policy_loss + self._entropy_coef * entropy_loss) + self._value_coef * value_loss
return loss
4、Exploration Strategy
# 动作选择逻辑
@torch.no_grad()
def _choose_action(self, timestep: types_lib.TimeStep) -> Tuple[types_lib.Action]:
s_t = torch.from_numpy(timestep.observation[None, ...]).to(device=self._device, dtype=torch.float32)
pi_output = self._policy_network(s_t)
pi_logits_t = pi_output.pi_logits
# 从策略分布中采样动作
pi_dist_t = distributions.categorical_distribution(pi_logits_t)
a_t = pi_dist_t.sample() # 随机采样实现探索
logprob_a_t = pi_dist_t.log_prob(a_t)
return a_t.cpu().item(), logprob_a_t.cpu().item()
5、Training Process
# 主训练循环
main_loop.run_parallel_training_iterations(
num_iterations=FLAGS.num_iterations,
num_train_steps=FLAGS.num_train_steps,
num_eval_steps=FLAGS.num_eval_steps,
learner_agent=learner_agent,
eval_agent=eval_agent,
eval_env=eval_env,
actors=actors,
actor_envs=actor_envs,
data_queue=data_queue,
checkpoint=checkpoint,
csv_file=FLAGS.results_csv_path,
use_tensorboard=FLAGS.use_tensorboard,
tag=FLAGS.tag,
debug_screenshots_interval=FLAGS.debug_screenshots_interval,
)
6、Key Hyperparameters
# 超参数设置
flags.DEFINE_integer('num_actors', 16, 'Number of worker processes to use.')
flags.DEFINE_float('learning_rate', 0.00045, 'Learning rate.')
flags.DEFINE_float('discount', 0.99, 'Discount rate.')
flags.DEFINE_float('gae_lambda', 0.95, 'Lambda for the GAE general advantage estimator.')
flags.DEFINE_float('entropy_coef', 0.0025, 'Coefficient for the entropy loss.')
flags.DEFINE_float('value_coef', 0.5, 'Coefficient for the state-value loss.')
flags.DEFINE_float('clip_epsilon_begin_value', 0.12, 'PPO clip epsilon begin value.')
flags.DEFINE_float('clip_epsilon_end_value', 0.02, 'PPO clip epsilon final value.')
flags.DEFINE_integer('unroll_length', 128, 'Collect N transitions before send to learner.')
flags.DEFINE_integer('update_k', 4, 'Run update k times when do learning.')

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









