






目录
前言
本篇文章只适合初步入门学习,更细致的学习需要参考更多的论文,其涉及的代码我并没有深入的研究,所以文章适合理论学习,项目可参考其他开源处理器核,如OpenHw的CVA6或者PULP的官网。图是用visio画的,一些图借用了知乎专栏,侵权删。
难免由疏忽之处还请大佬指正。
参考
开源RISC-V处理器架构分析与验证 ,知乎,超标量处理器,以及网上资料整理。
介绍
取指模块取到分支指令的时候,我们不希望等到执行单元解析出指令后再进行跳转,那会造成流水线停顿。
因此我们引入分支预测,再译码阶段就知道它的是否执行肯定会事半功倍,这样减少了冲刷流水线操作(flush)。
所以,进行分支预测的阶段通常是再译码阶段就要执行,预测分支指令,我们需要预测两个东西。
- 指令是否跳转?
- 指令跳转地址?
分支预测分为静态预测和动态预测:
静态分支预测:
静态预测很好理解,总是默认跳转或者默认不跳转,这种预测方式在硬件上实现简单,但是预测度很低,对于简单的处理器(流水线较少)而言,使用静态分支预测是最划算的方式,即使分支预测失败惩罚也不严重。
如果跳转出现跳转,不跳转,跳转,不跳转,等这样如此的循环,那么预测将会是全错的,所以静态分支预测不适合现代处理器。
动态分支预测:
动态分支预测主要是基于历史预测,根据前面的跳转指令的结果来预测下一次跳转指令是否要跳转,以及跳转地址。
由于每次的结果都是更新的,我们称它为动态分支预测。现代处理器基本使用动态分支预测,所以下面介绍常见的动态分支预测算法:
1bit预测器:
1bit预测器主要根据上一次的结果来做这一次的分支预测,因为只能根据上一次的结果(1bit) 所以这种方法直接不适用,故而诞生了2位饱和计数器。(其实只是为了引入2bit计数器)
2位饱和计数器:
2位饱和计数器是现代分支预测算法的基础,所以着重讲述2位饱和计数器的算法。
2位饱和计数器有4个状态,分别是:强跳转,弱跳转,强不跳转,弱不跳转。
如图所示:
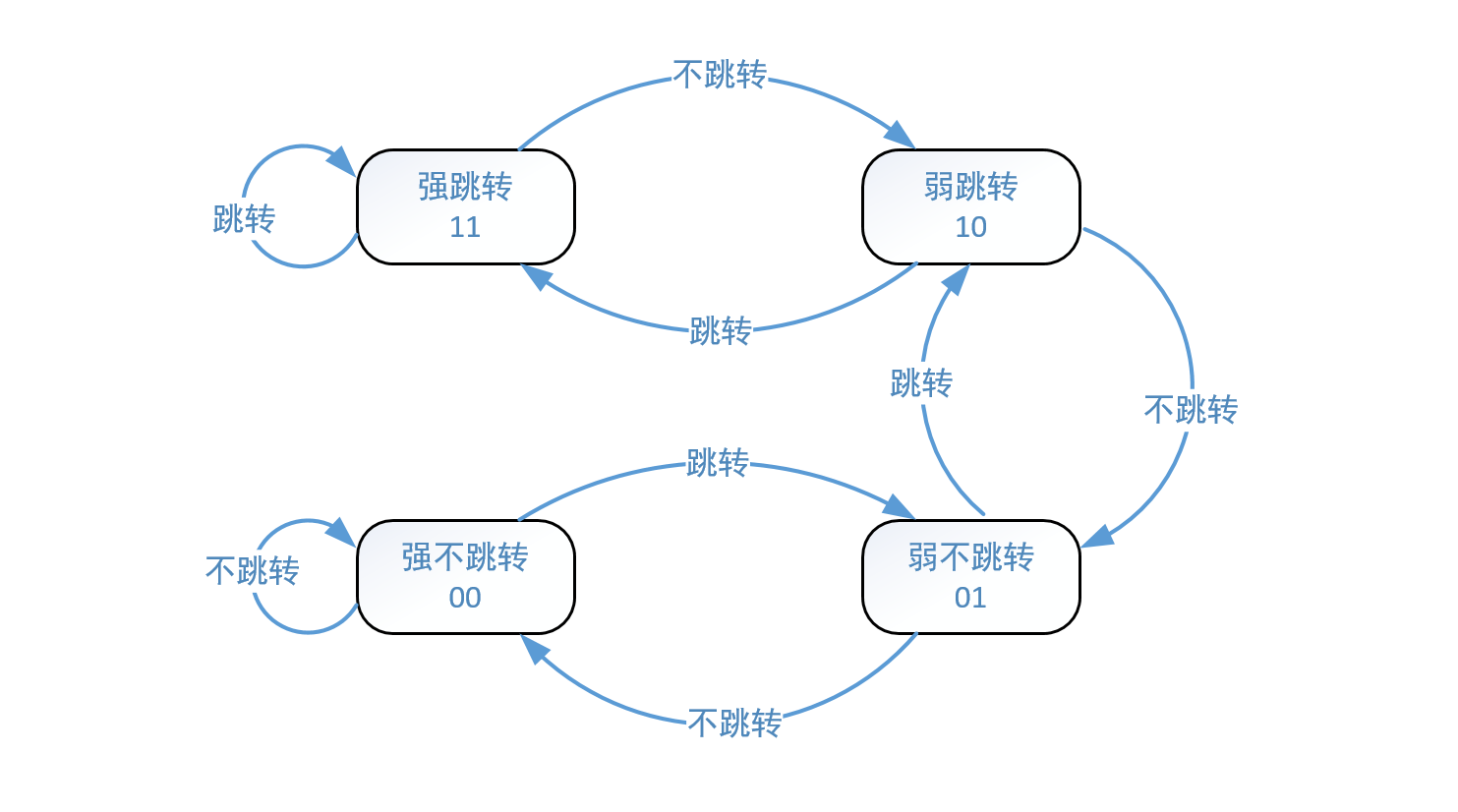
强跳转:计数器饱和,分支预测本次会跳转
弱跳转:计数器不饱和,分支预测本次会跳转
弱不跳转:计数器不饱和,分支预测本次不跳转
强不跳转:计数器饱和,分支预测本次不跳转
饱和计数器初始状态是强不跳转(00),当出现连续三次不跳转才会处于强不跳转状态,反之也是如此。
所以该算法的核心是:在跳转和不跳转之间引入四个状态来细分预测状态,提高预测精度。
由两位饱和计数器衍生出的结构组成结构有很多,比如:
BHT预测:
分支历史表(branch history table) 简写为BHT,配合PC值的低n位索引,所以BHT需要有 个表项才能够PC值索引。
BHT里面存储的是多条分支指令的历史执行结果,使用一个位向量或者一系列位来记录每个分支指令的历史,其中的每一个表项对应一条分支指令的历史执行结果(跳转或不跳转)。
对于每个分支指令,BHT中的对应位或者几位都会随时更新以反映最新的历史执行结果,这个更新来源于分支指令的执行结果反馈。
由于PC值的最低位没有任何意义,所以舍弃不要了。
如图所示: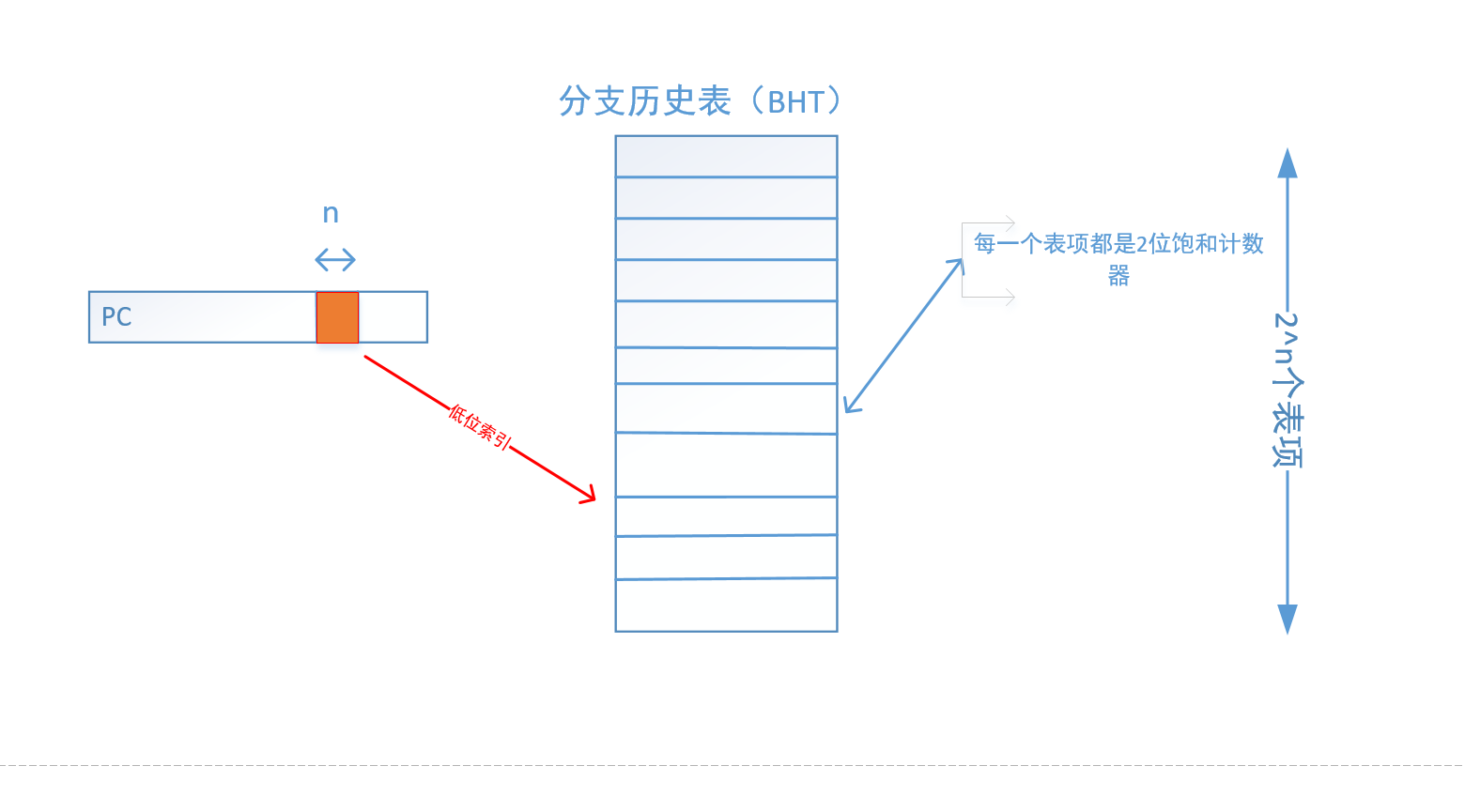
可以看出BHT预测的是分支指令跳转或者不跳转,而不是预测地址。
两级分支预测器:(PHT)
两级分支预测器是基于局部历史的,所以我们也叫它:基于局部历史的分支预测器(其实上面的BHT也是局部历史)。
局部历史预测器很明显,只能基于以前局部的分支指令结果来做预测,因此局部历史记录多少限制了预测的准确性。
如图所示: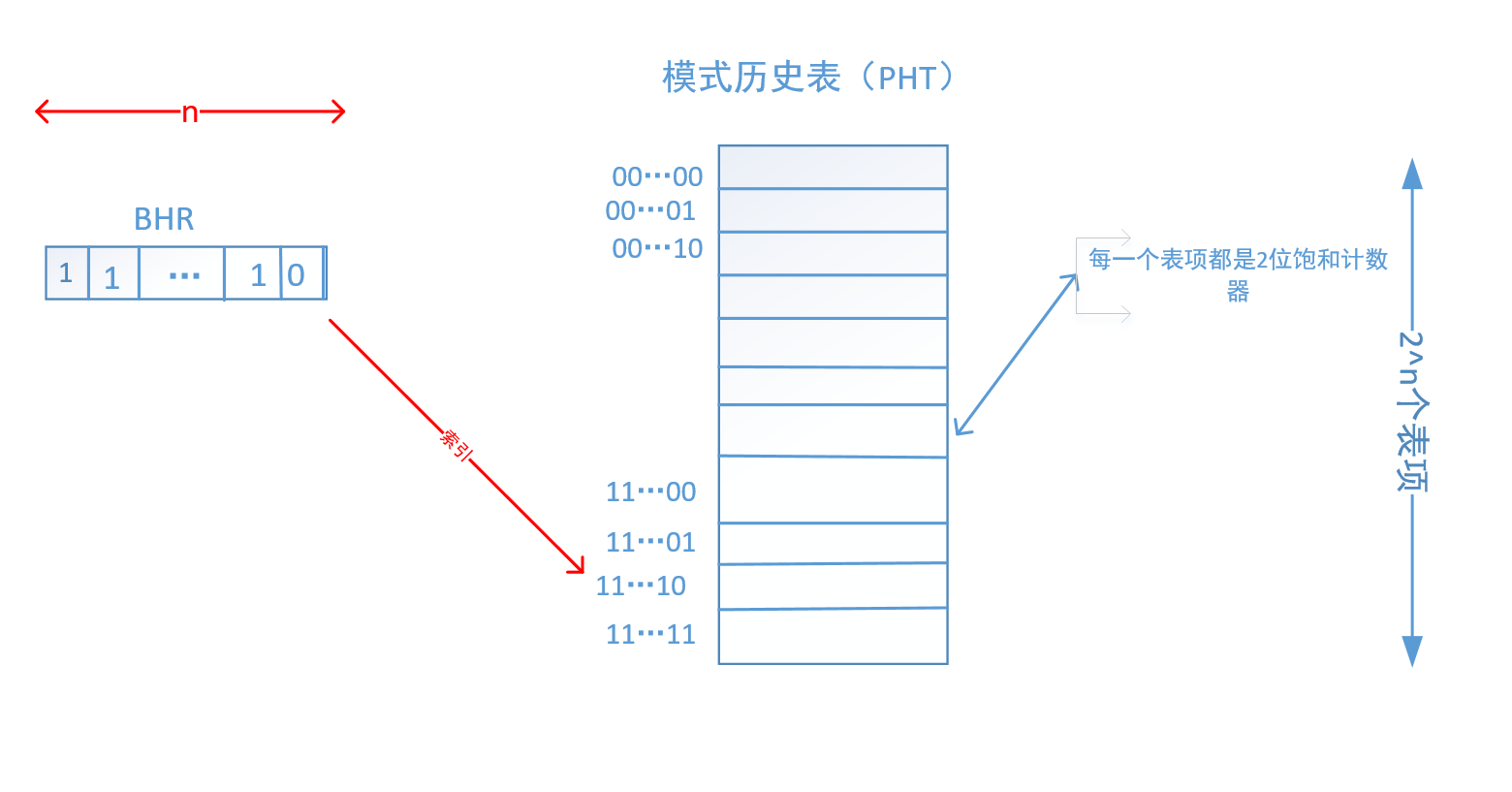
两级分支预测器由分支历史寄存器(branch history register,简称BHR) 和模式历史表(pattern history table ,简称PHT)组成。
PHT是一个记录分支历史跳转信息的表格,每个表项都可以用2位饱和计数器实现,里面存储着BHR每种数值对应的两位饱和计数器的值。
BHR是一个寄存器(准确的说是移位寄存器),里面记录了一条分支指令在过去的历史状态,即该指令前几次的执行结果(跳转还是不跳转)。
里面有n个bit ,每个bit 的数值为0 就是没有跳转,1就是代表跳转。
其结构如上图所示,可以看到它和BHT预测其实并没有多大的差别,无非就是把PC索引换成了BHR而已,然后再把BHT改个名。
分支目标缓冲器:(BTB)
分支目标缓冲器是由PC索引和分支目标缓冲器( branch target buffer ,简称BHB)实现的,其功能可以说是最为简单的。
如图所示: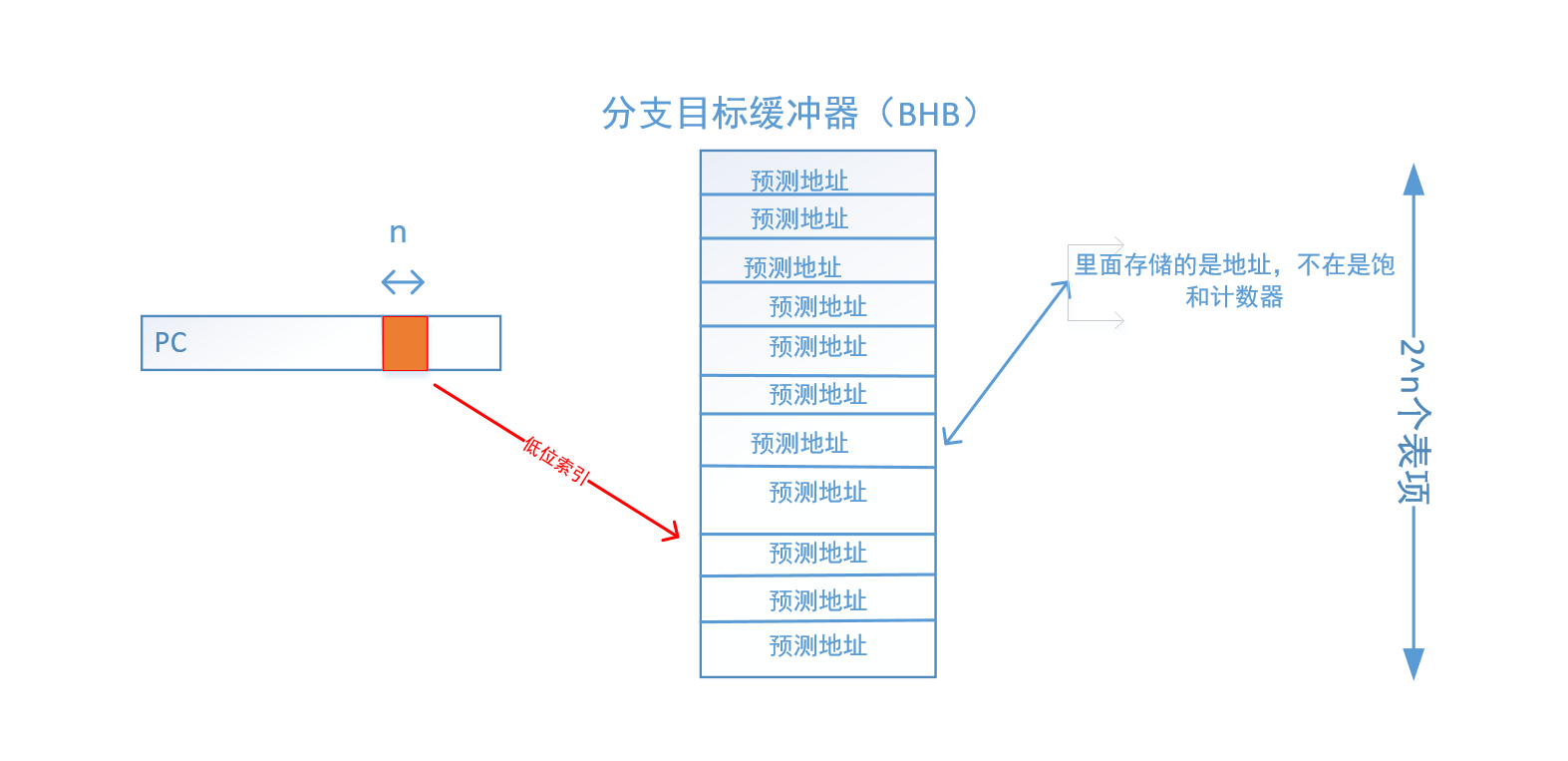
BTB预测最大的问题在于多个分支指令共用一个表项的情况,这会造成分支干扰或者数据冒险,结构冒险等。
这是由于BTB内容是有限的,恰好有多条分支指令跳转的地址恰好相同,于是出现竞争冒险情况。
BTB预测的是地址,而不是跳转方向。
以上的的分支预测都是基于局部的分支历史来进行预测的,那么对应的就是基于全局历史进行预测的全局历史预测器。
基于全局历史的分支预测器:
除了记录自己这条指令的历史执行状况,还可以记录其他指令的历史情况来辅助判断,这种预测算法就叫做全局历史预测。
全局历史预测是局部历史的扩展,将局部历史扩展到全局,相应的我们需要一个GHR(global history branch)寄存器,用来记录所有分支指令的结果。
GHR预测器:
全局历史预测只是局部历史预测的扩展而已,相当于把BHR换成GHR而已,其内部存储的数据基本上是一样的,只是位宽更大。
如知乎图所示:
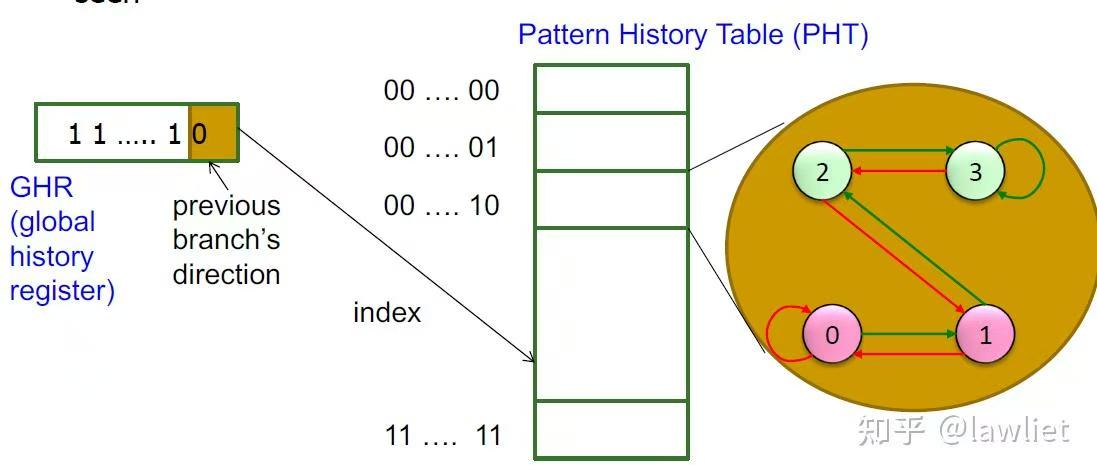
Gshare分支预测器:
两级分支预测器BHR在对PHT进行索引时,会存在严重的别名冲突(比如存在多个BHR或GHR组件的共用一个PHT时就会出现一个PHT里的值对应多个BHR的值或者GHR的值,这个时候就会出现别名冲突。)
所以我们需要引入一个更加精密的索引机制,哈希。
如图所示,通过预测分支的PC值与BHR的值先做一次哈希运算后,再把结果作为PHT的索引,其结果会更加准确。
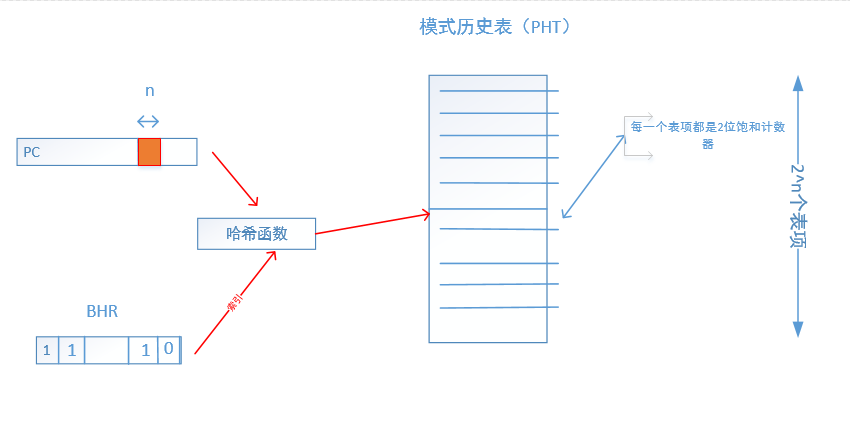
然而这样也会发生别名冲突,所以缓解别名冲突的方法有:
- 增加BHR的长度,记录更多这条分支指令的历史状态
- 改进哈希函数
- 结合多种预测技术(全局历史,局部历史,两级预测器等)实现混合预测。
看到这里你需要理解的是:
1. BHR记录的是某条特定分支指令的最近执行结果,通常是跳转,或者不跳转
2. PHT记录的是该条分支指令执行结果映射到2位饱和计数器或着状态机表示的预测结果,也就是说,它里面存储的是预测状态(强跳转,弱跳转,弱不跳转,强不跳转)。
3.可以认为BHR和PHT就是简单的针对同一条分支指令,但实际上它们可以支持多条分支指令,只需要增加更多的BHR 和PHT就好,没准还能实现并行预测。
混合预测:
使用BHT ,BHR,GHR,BTB等预测方式搭配起来实现混合预测,目的就在于提高精度。
借用知乎图来说就是: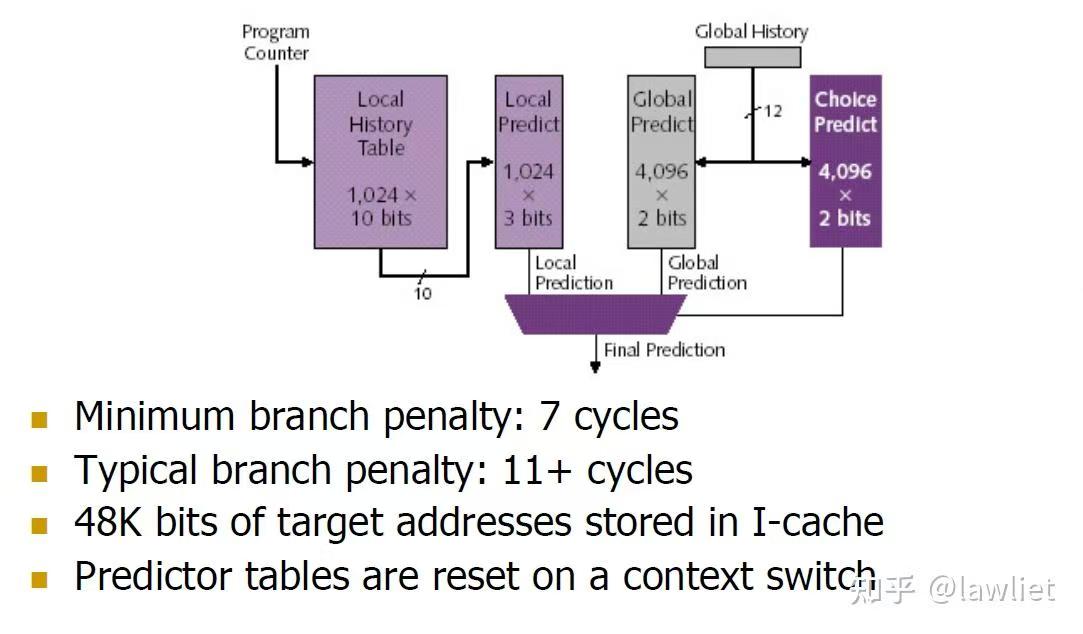
可以看出混合预测就是将上述的预测器综合起来,不过这也没什么好说的。
感知机预测:
感知预测是现代分支预测器中的一种,主要是通过函数运算得到的,当跳转成线性变化时很有效,如果不是线性变化那么预测会变得很差。
感知预测是通过BHR或者GHR寄存器中的每一个bit 作为输入,然后通过加权求和得出结果,权重越大代表跳转概率越大,反之就是不跳转。
如知乎图所示: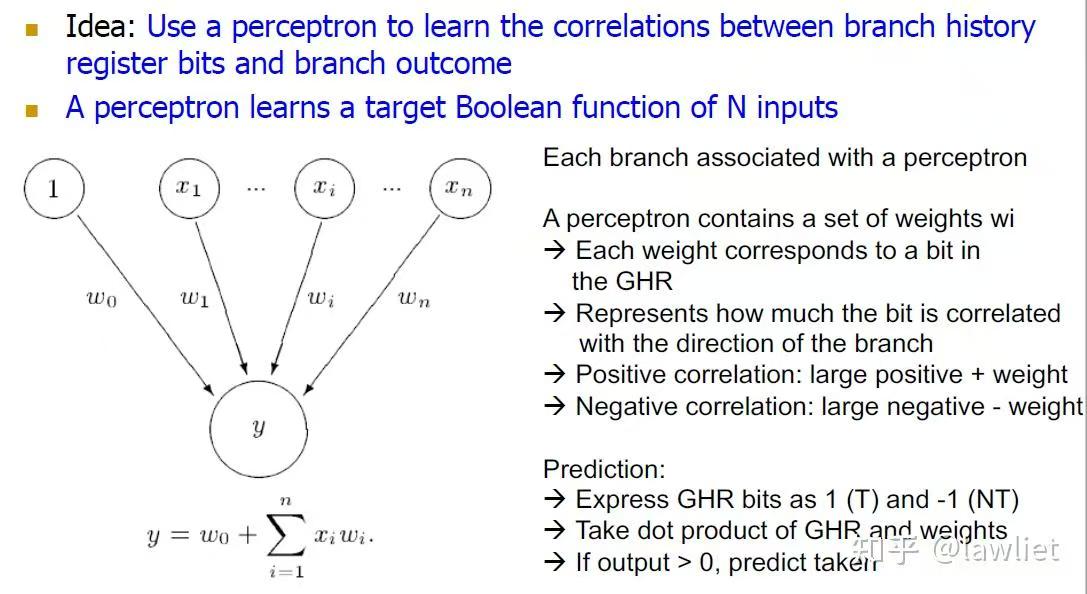
需要注意的是,BHR 和GHR寄存器每一bit 输入不是按照原数据输入的,而是:
当前位为1(跳转) ,输入1 ;
当前位为0(不跳转),输入-1 ;
输出Y是一个点积,>0 预测为跳转, <0 预测为不跳转。
所以感知机预测通常只能预测是否要跳转,就是说:在当前BHR或GHR的值的输入基础上预测下一次是否要跳转,但是无法预测出跳转地址。
如果想要预测地址,需要更加复杂的模型,比如多层感知机或者神经网络,或者专门的地址预测器(分支目标缓冲器BTB,分支预测缓冲器BHB,两级分支预测器PHT,Gshare分支预测器等等)
此外感知机需要训练,类似于人工智能一样,更多信息还请参考其他书籍吧。
TAGE分支预测器:
TAGE 预测器主要应用于现代处理器中,其组成由基础预测器和多个TAGE(标签表)组成全局预测器。
使用同一分支指令的不同历史长度的GHR去索引PHT,从而得出每一段历史长度的跳转预测值,再把它们级联的输出,最后得出结果。
需要注意的是:
- tage预测器针对的同一分支指令的不同历史长度长度,也就是根据同一分支指令不同阶段下的跳转情况来预测的
- Tage 预测器输出的数据同样是是否跳转,而不是一个具体的跳转地址,这个前面的感知机的输出是类似的。
- Tage 预测器输出是由命中的tag最长的那个TN表进行输出,不是由最后一个TN表才会输出。图中所示就不要理解为要在T4才会输出就行,如果命中了T3 ,而T4 没有命中,那么还是由T3输出。
配合上下文来看:
如图所示来看,T0是使用PC直接索引2位饱和计数器的表项;
T1 ~ TN都是使用PC和不同的全局分支历史长度进行哈希索引,索引的是表项中的tag。
内部解释:
- Pred: 3位符号饱和计数器,符号位代表是否要跳转,0代表不跳转,1代表跳转,这个其实就是在2位饱和计数器下多加了一位用于输出跳转信息罢了。
- Tag : 内部存储着分支指令过去的执行结果,这个PHT(模式历史表)或BHT(分支历史表)内部的信息差不多。
- U : 2位计数器,表示当前的tag 的有用程度,因为可能索引的时候一个也没索引到,没有索引到就没有命中。
返回地址堆栈(RAS):
对于函数调用和函数返回指令,虽然也可以使用BTB进行分支预测,但是这纯属于绕弯路多此一举,因为和函数有关的地址大多简单,使用堆栈处理更加高效快捷。
发生函数调用时,将函数调用的下一条指令的PC值压入堆栈,在函数返回时,直接从堆栈中弹出一个PC值作为返回地址的预测结果。
这才成对的函数调用返回下十分契合。
涉及入栈出栈的知识不做讲解,读者可以自行搜索。
总结:
| 指令 | 类型 | 是否预测 | 是否预测地址 | 分支预测组件 | 备注 |
| Is_branch | 条件跳转 | Y | N | BHT 感知机,TAGE等 | 预测方向 |
| Is_jump | 无条件直接跳转 | N | N | 无需预测 | |
| Is_jalr | 无条件间接跳转 | N | Y | BTB | 预测地址 |
| Is_return | 函数返回 | N | Y | 堆栈 | 出栈 |
| Is_call | 函数调用 | N | N | 堆栈 | 入栈 |
Y代表是 , N 代表否。
上述的分支预测中可以看出,很多预测组件只预测是否需要跳转,对地址预测我只简述了BTB组件。
你需要理解2比特饱和计数器,这是最基础的,是分支预测的关键,也是课题的基础。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











