






一、Spark简介
Apache Spark是一个开源的分布式计算框架,用于快速处理大规模数据。它支持多种数据处理任务,包括批处理、流处理、机器学习和图计算。Spark的核心是RDD(Resilient Distributed Dataset),它提供了容错和高效的数据处理能力。
Spark具有运行速度快、易于使用、通用性、兼容性等特点。
1.速度快
Spark使用DAG(有向无环图)执行引擎,以支持循环数据流和内存计算。它允许将数据存储在内存中,对于迭代式算法和交互式数据挖掘工具来说,速度比Hadoop MapReduce快100倍。即使在磁盘上运行,Spark也能比Hadoop快10倍左右。例如,在处理大规模机器学习算法时,像梯度下降算法需要多次迭代访问数据集,Spark能够快速地从内存中读取数据进行计算。
2.易于使用
Spark支持多种编程语言,包括Scala、Java、Python和R。它提供了丰富的API,使得开发者能够轻松地编写并行程序。例如,使用PySpark,Python开发者可以像操作本地数据一样操作分布式数据集,通过简单的函数调用(如map、reduce)来实现复杂的分布式计算。
3.通用性
Spark提供了一整套丰富的工具来支持各种数据处理任务。它包括Spark SQL(用于结构化数据处理)、Spark Streaming(用于实时数据流处理)、MLlib(机器学习库)和GraphX(图计算库)。这使得Spark可以用于多种场景,从批处理到实时处理,从简单的数据分析到复杂的机器学习模型训练。
4.兼容性
Spark可以与Hadoop生态系统无缝集成。它可以运行在Hadoop YARN上,也可以使用Hadoop的存储系统(如HDFS)。同时,Spark也支持其他存储系统,如Amazon S3、Cassandra、HBase等。这使得企业可以方便地在现有的大数据架构中引入Spark,而不需要大规模地重构系统。
二、Spark的安装
1.环境准备
安装Spark集群之前需要安装Hadoop环境,并设置好三台机器的主机名分别为:hadoop1、hadoop2、hadoop3,并设置好hosts文件。且需要安装JDK,这里使用Spark 3.5.2版本
2.Spark的下载
首先打开Spark存档网站:https://archive.apache.org/dist/spark,在里面找到Spark3.5.2版本,点击下载,下载Linux版本的安装文件spark-3.5.2-bin-hadoop3.tgz ,然后将下载的文件上传到hadoop1机器的/export/software目录中。
3.Spark的安装
在hadoop1上执行如下指令,进行Spark的解压,解压命令如下:
tar -zvxf spark-3.5.2-bin-hadoop3.tgz -C /export/servers/
接着进入到Spark的安装目录,将Spark的安装目录文件名修改为spark-3.5.2,命令如下:
mv spark-3.5.2-bin-hadoop3 spark-3.5.24.环境变量的配置
首先编辑环境变量文件,命令如下:
vim /etc/profile
在文件的底部添加如下内容:
export SPARK_HOME=/export/servers/spark-3.5.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
接着使用如下命令使修改的环境变量生效:
source /etc/profile
我们可以验证是否安装成功代码如下:
spark-shell 如果看到 Spark Shell 的提示符,说明安装成功。示例如下: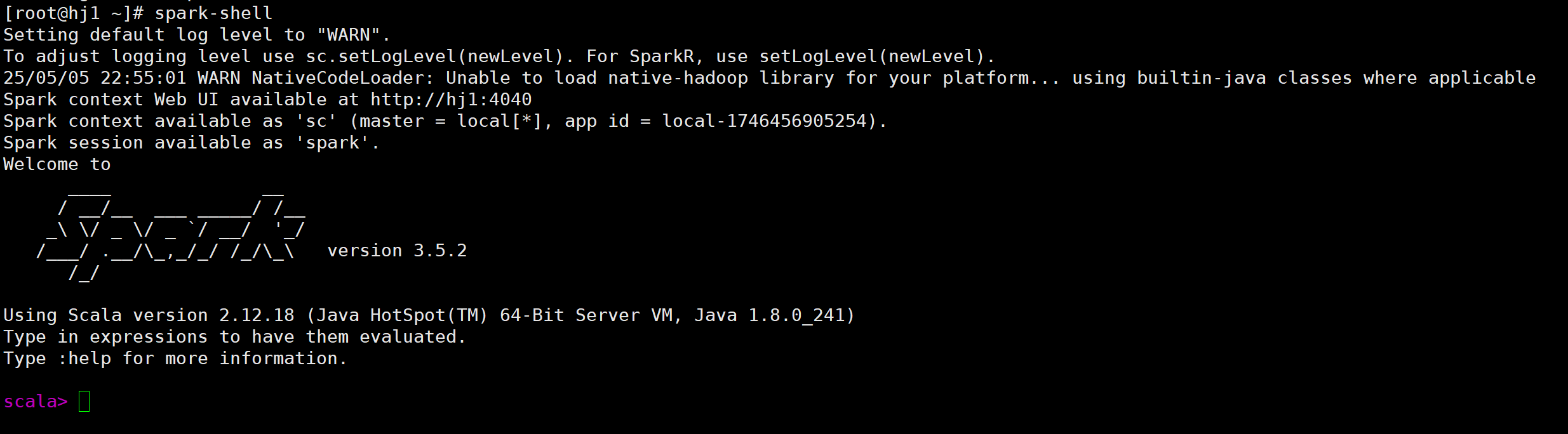
5.Spark相关的配置
我们首先进入1号机器的/export/servers/spark-3.5.2/conf目录,来修改spark-env.sh文件,默认是没有这个文件的,只提供了一个模板文件,我们需要复制一份模板文件作为此配置文件。
cp spark-env.sh.template spark-env.sh接着我们再使用vim工具在此文件中添加如下内容:
# 配置Java环境
export JAVA_HOME=/export/servers/jdk1.8.0_241
# 指定Master的IP
export SPARK_MASTER_HOST=hadoop1
# 指定Master的端口
export SPARK_MASTER_PORT=7077
export HADOOP_HOME=/export/servers/hadoop-3.3.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
接着我们要修改workers文件,与spark-env.sh一样,我们需要先复制一份出来。
cp workers.template workers接着用vim工具在直接在文件中添加workers机器的主机名:
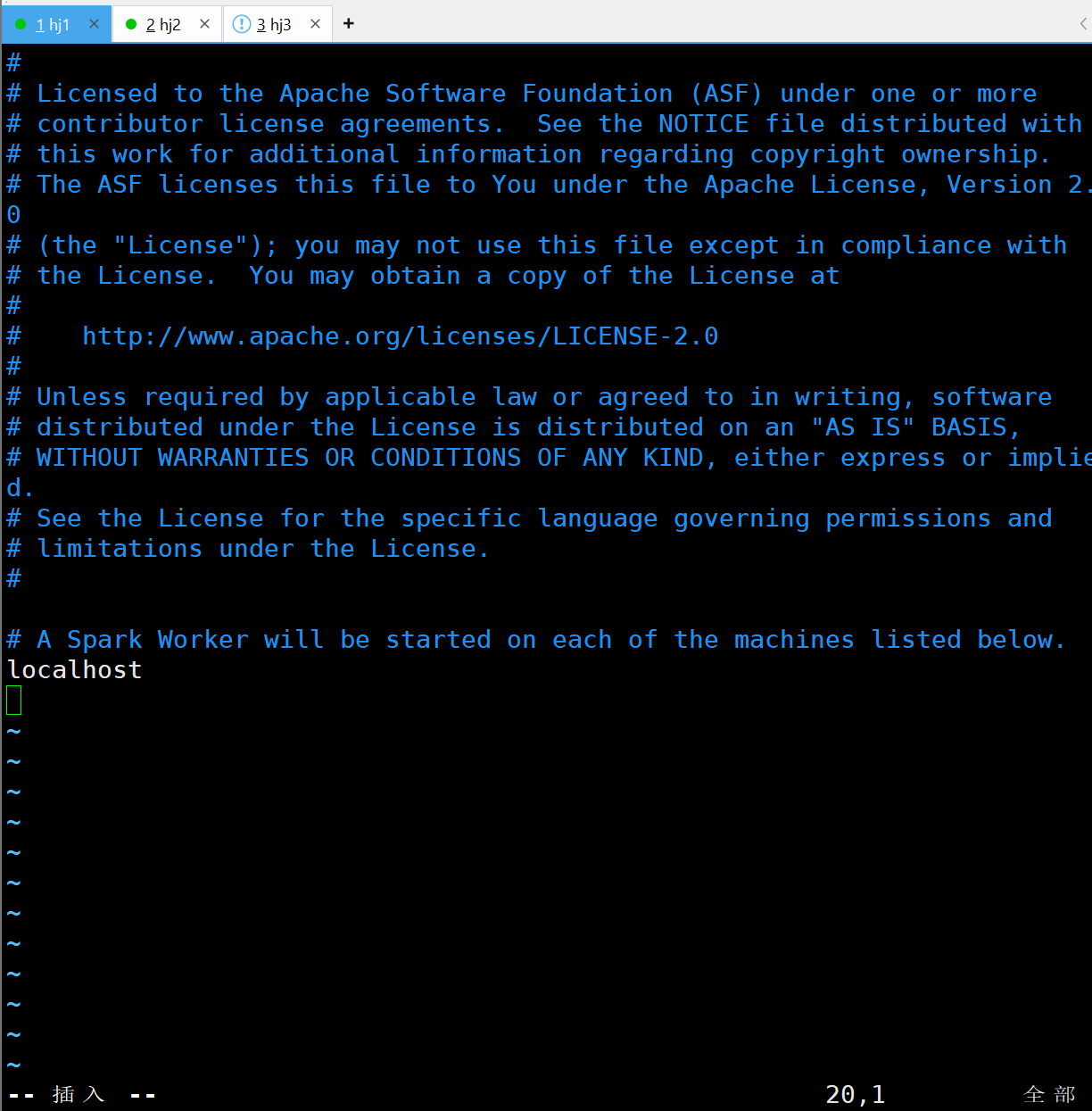
hadoop2
hadoop3 这里需要注意的是,如果这里添加了hadoop1就要删除localhost,不然hadoop1机器将既做master(主节点)又做slave(从节点)。
我们为了避免重复配置环境,进行分发操作,在hadoop1机器上执行如下指令,就可以将文件传输到另外两台机器上:
scp -r /export/servers/spark-3.5.2/ hadoop2:/export/servers/
scp -r /export/servers/spark-3.5.2/ hadoop3:/export/servers/
scp -r /etc/profile hadoop2:/etc/
scp -r /etc/profile hadoop3:/etc/这里需要分别在hadoop2,hadoop3里使用source命令来使环境变量生效。
6.启动Spark集群
启动命令:
export/servers/spark-3.5.2/sbin/start-all.sh
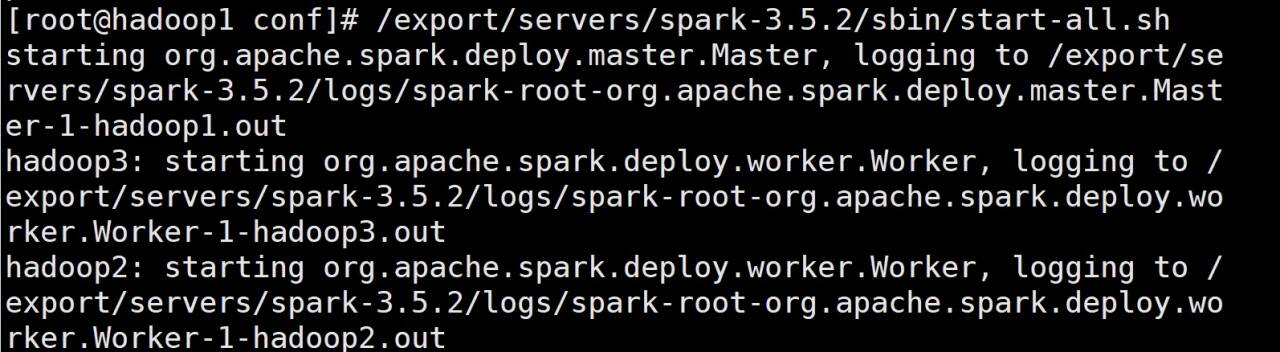
可以使用jps命令查看各节点进程:
一号机器:

二号机器:

三、常见问题及解决方案
1. Java环境未配置
如果在启动 Spark 时提示 java not found,请检查 Java 是否已正确安装并配置环境变量。
2. Spark集群启动失败
检查 spark-env.sh 和 slaves 文件的配置是否正确。确保所有节点的网络连接正常,并且防火墙未阻止相关端口。
四、总结
通过以上步骤,你已经成功在 CentOS 系统上安装并配置了 Spark,接下来你可以进一步尝试使用 Spark Shell命令进行学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









