






目录
一 程序及Python基本语法
1.程序
1) 程序设计
是用计算机解决一个实际应用问题时的整个处理过程,包括提出问题、去除数据结构、确定算法、编程、调试程序及编写使用说明文档等一系列过程
程序设计方法(模块化分布设计的思想)分为:自顶向下设计; 自底向上执行
- 自顶向下设计是解决问题的有效方法,基本思想是将一个问题细分为多个小问题,逐步将小问题解决,并将解决方法组合起来就是最初始的问题
- 自底向上执行是一个测试答案的最有效方法,基本思想也是将一个程序细分为多个小模块,逐个测试,逐个执行,最后整个程序运行完毕,编写人员也能很快确认问题出现的范围
2) 程序的格式框架
结构化程序设计框架 强调程序的逻辑结构,通常遵循“自顶向下,逐步求精”的设计思想。其基本框架为IPO(input输入 process处理 output输出),其中处理的方法也叫算法,算法也是一个程序的核心内容
面向对象程序设计框架 面向对象程序设计(OOP)以类和对象为核心,强调封装、继承和多态。其基本框架包括:类定义、对象实例化、方法调用
模块化程序设计框架 将程序分解为多个独立的模块,每个模块负责完成特定的功能。其基本框架包括:模块定义、模块调用、主模块
3)程序设计语言分类
机器语言 由0和1组成的机器能直接识别的二进制程序语言或者指令代码,不需要经过翻译,直接操作计算机硬件,执行速度极快
汇编语言(符号语言) 用于微处理器、微控制器或者其他的编程器件的低级语言.在汇编语言中,他用字母、单词等代替一些特定的机器语言指令.执行速度快
高级语言 更贴切自然语言,易理解,易编写.目前使用最广泛的高级语言有python、C语言、JAVA等.使用高级语言编写的程序称之为源程序.高级语言不依赖计算机的硬件系统 及指令系统,容易学习掌握,易于理解.它的执行速度较慢
- 脚本语言: 解释方法执行,包括python、PHP等
- 静态语言: 使用编译方式执行,包含C语言、JAVA等.
编译是将一个源代码转换成目标代码的过程,一般来说,源代码都是高级语言代码,目标代码是机器语言代码;
解释是将源代码逐条转换成目标代码并同时逐条运行的过程
总之,编译和解释的区别在于编译是将程序整体进行编译,编译完成后再一次性执行,一旦编译完成,就不在需要源代码和编译器.而解释则是解释一句,执行一句,每一次执行程序都需要源代码和解释器
2. python基本语法
1) 缩进
无论缩进多少,必须保证的是整个程序的缩进规则必须保持一致
2) 注释
- # 用于注释一行代码,从此符号出现开始的字符到下一行之前
- """" 文档字符串,用于对多行代码的注释
3) 变量
4) 保留字(35个)
| and | as | assert | break | class |
| del | elif | else | except | False |
| True | continue | finally | for | from |
| global | if | import | in | is |
| lambda | None | nonlocal | not | or |
| pass | raise | return | True | try |
| while | with | yield | async | await |
5) 赋值语句
3种格式
- <变量> = <表达式>
- <变量1>=<变量2>=...=<表达式>
- <变量1>,<变量2>,...,<变量N> = <表达式1>,<表达式2>,...,<表达式N>
赋值将左边的变量和右边的对象关联起来,即变量与对象一一对应
a=(b=8), 这种表述是错误的,括号将作为整体赋值给a,但是b=8并不是表达式
6) 引用
python使用import保留字导入当前程序以外的函数库
3种引用方式
- import <函数库名称>
- from <函数库名称> import * ,导入函数库所有的函数,此时无需<函数库名称>.做前导,例如from numpy as * ,此时可以直接使用array(),无需numpy.array()
- import <函数库名称> as m 将库换了个别称,例如import numpy as np, numpy.array()的调用时,可以使用np.array(),效果一致
3. 基本输入输出函数
input()、eval()、print()
- input(): 提示关键信息,参数只能是字符串类型; 输入信息回车时,自动结束input()函数 ;
- eval():去掉字符串两侧的引号,并按照语句要求执行去掉引号的字符内容;
(1)对字符串有效表达进行计算,并返回结果,如eval('1+2'),返回整数3
(2)将字符串去除引号并转成相应的对象,(如list、tuple、dict和string之间转换)
eval('(1,2,3)'),返回元组(1,2,3)
3. print(): 输出结果
(1)包含参数结束符end='\n' ; 变量之间空格sep=' '
(2)可以输出多个变量,输出的变量间以空格分隔
(3)常用format函数格式化输出效果
print('{:{1}^5}'.format(1,'#'))
输出 ##1##
4. 源程序的书写风格。
清晰第一,效率第二
5. Python语言的特点。
二 基本数据类型
1. 数字类型
- 整数类型
python语言没有限制整数类型的大小,但实际上由于计算机内存有限,整数类型不可能无限大或无线小
| 进制形式 | 引导符号 | 描述 |
| 二进制 | 0b或0B | 由0和1构成 |
| 八进制 | 0o或0O | 由0~7构成 |
| 十进制 | 无 | 由0~9构成 |
| 十六进制 | 0x或0X | 由0~9、a~f或A~F构成 |
bin() 转化成二进制数字 | oct()转化成八进制数字 | hex()转换成十六进制数字
- 浮点数类型
python中无小数的说法,带小数点的数统称为浮点数
(1) 浮点数有明确的取值范围
(2) 0.3 + 0.1== 0.4,为False,这是因为计算机对于0.1+0.3的计算结果会多出一个'尾巴',其原因是二进制和十进制不存在严格对等关系
- 复数类型
.real和.imag得到复数的实数部分和虚数部分,可以进行四则运算
2. 数字类型的运算
1) 数字运算操作符
- 数字类型运算符,如下所示
- % 参与运算的可以是浮点数,结果可能是浮点数,如4.2%2 结果为2.1
- / 参与运算的都是整数,结果只能是浮点数或者复数
- ** 指数运算
- ^ 异或运算
- // 整除运算(结果是整数)
2. 比较运算符,如 ==、!= 等
3. 逻辑运算符,如and、or、not等
2) 数字运算函数
| 运算函数 | 功能说明 |
| abs(x) | 返回绝对值或者复数的模 |
| divmod(x,y) | 返回包含整商和余数的元组((x-x%y)/y,x%y) |
| min(x)/max(x) | 返回可迭代对象x的最小值/最大值 |
3. 真假无
True、False、None
除了数字0的bool值为false,其余数字都是True,如 bool(-1)返回的值是True
4. 字符串类型及格式化
(1)可以使用单引号、双引号、三单引号、三双引号互相转换,用来表示复杂的字符串
(2)python中的反斜杠字符\,其表示一些特殊含义,如'\n'换行,'\\' 表示一个斜杆\
(3)字符串可以使用正向索引或者反向索引获取具体字符串值,即可以读,但是不能对字符串赋值
(4)[start:stop:step]对字符串进行切片,且stop值取不到,默认step为1
(5)字符串格式化输出------format()
1. 基本使用: <字符串模版>.format(<参数1>,...,<参数n>)
print('{}的年龄是{}'.format('李华','18'))
输出 李华的年龄是182. format格式控制: {<参数序号>:<格式控制标记>}.format()
格式控制标记:用于控制参数显示时的格式,包括<填空><对齐><宽度><精度><类型>
- <对齐>有三种形式包括'^'居中 ''<''左对齐 ''>'' 右对齐
- <精度>如果实际长度(位数)大于有效长度(位数)就要对参数做截断处理,如果小,则以实际长度为准
print('{:{1}^11.3%}'.format(1.1011,'&'))
输出 &&&1.101&&&
print('{:b}'.format(8)) #二进制
输出 1000
print('{:o}'.format(16)) # 十六进制
输出 f15. 字符串类型的操作
(1)字符串操作符
| 操作符 | 功能说明 |
| x in s | x 是 s 的子字符串,返回True,否则返回False |
| x not in s | x 不是 s 的子字符串,返回True,否则返回False |
| s + i | 连接字符串s和 i |
| s * n 或 n * s | 重复n次字符创 |
(2)操作函数和操作方法
| 方法 | 功能说明 |
| str.center(width) | 返回以str为中心,长度为width的字符串 |
| str.count(sub[,start[,end]) | 返回start,end]内子字符串sub的出现次数 |
| str.join(iterable) | 将iterable中的元素通过str拼接成一个字符串 |
6. 类型判断和类型间转换。
(1) type(x)函数,返回x的数据类型
print(type([1,2,3]))
输出 <class 'list'>
(2) 特殊的: 字符串类型的浮点数不能转换成整数类型, 如int('1.22') 会直接报错
(1)complex(re,im) 生成实数部分为re,虚数部分为im的复数,im默认零,如complex(1,2),结果1+2j
(2) float(x) 将x转换成浮点数,如float(1),结果为1.0
(3)int(x) 将x转换成整数,如int(1.0),结果为1
str(x) 将x转换成字符串,如str(1.0),结果为'1.0'
三 程序的控制结构
(1)顺序结构、分支结构、循环结构、异常处理
(2)顺序结构就是最基本的程序结构,基本结构就是按照顺序自上而下依次执行语句,这里不在单独讲解
1. 程序流程图
编写程序的前提是对程序的算法有清晰的表示,即要先清楚程序的流程,这样在编写代码时仅仅是对算法或者流程的实现,将会大大降低编程的复杂度
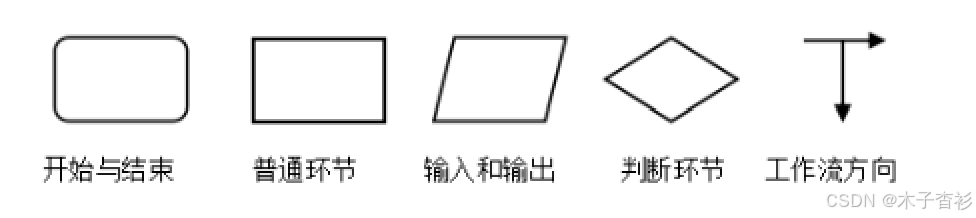
2. 程序的分支结构
分为 单分支结构、二分支结构、多分支结构
(1) 二分支精简结构的表示: 表达式1 if 条件 else 表达式2
(2) 注意: 条件之后含冒号':', 且多分支最后的else是不包含''条件判断"的
# 多分支
if <条件1>:
<语句块1>
elif <条件2>:
<语句块2>
...
else:
<语句块N>
# 双分支
if <条件>:
<语句块1>
else:
<语句块2>
# 单分支
if <条件>:
<语句块>
ss = [2,3,6,9]
for i in ss:
ss.remove(min(ss)) #注意移除列表中的数的同时,列表长度也在变换,进而影响遍历的次数
print(min(ss),end=',')
输出: 3,6,3. 循环结构及循环控制
(1) python中包含两种循环: 遍历循环for 、无限循环while,
且两者通常是可以相互转换的,while无需知道循环次数,只要不满足条件,便跳出循环;
for <循环变量> in <遍历结构>:
<语句块>
可以遍历任何序列的元素,如字符串、列表、元组、字典、数字序列和文件
while <条件>:
<语句块>
条件为False则终止循环,跳出while循环执行后续语句
(2) break、continue只能在循环内部使用,它们的作用只适用于离它们最近的一层循环
- break的作用跳出当前循环或者说离得最近的循环并结束本层循环,继续后续的代码
- continue则是结束本次循环,也就是跳出语句块中尚未执行的语句,对于while循环,继续判断循环条件;对于for循环,继续遍历循环结构
4. 程序的异常处理
- 错误是程序设计阶段的问题,包括语言错误,逻辑错误,与预期结果不符,运行时错误
常见的缩进错误SyntaxError属于逻辑错误
- 异常是在运行时出现的错误,一种特殊的错误,可通过try-except快捕获,使得程序可以接着运行或者采取适当的措施
(1) try-except-else-finally-
当在try块中的语句块1捕获到了异常,则进入到except中的语句块2去处理异常.对于finally中的语句块4,不论程序有没有异常都会执行,当只有语句块1无异常时,才会执行else中的语句块3
try:
<语句块1>
except:
<语句块2>
else:
<语句块3>
finally:
<语句块4>
四 函数和代码复用
1. 前言
1) 函数:用于执行特定操作的可重用代码块
2) 函数可以在模块、类或其他函数内定义,类内定义的函数成为方法
3) 函数的优点
- 减少代码重复编写
- 把复合问题分为简单的部分
- 提高代码的清晰度
- 代码的重用
- 信息的隐藏
def 函数名(形参):
'''函数文档字符串''''
''''函数功能与内容'''
return [表达式]
#调用
函数名(实参)形参:形式参数,是在函数定义的时候再圆括号中定义的一种特殊变量
实参:实际参数,是在调用已经定义好的函数时实际传入的值,该值将给形参中的变量赋予具体的值
特殊地: 函数可以无参数,也可以有一个或多个参数
(1)函数的返回值
- 函数可以有0个或多个函数运算的结构给函数被调用处的变量
- 对于只有return,后无表达式的相当于返回None
- return语句可以出现在函数中的任何部分
- 当返回多个值赋值给一个变量,返回值形成元组数据类型
2. 函数的参数传递
位置参数 默认参数 关键字参数 可变参数
非可选参数一定房子啊可选参数前面
# 位置参数
def my_func0(a, b):
return a+b # 返回1+2后的值
my_func0(1,2) # 按照传入的实值1和2依次传值给a和b
# 默认参数
def my_func1(name,inclass='1'):
print('{}:{}'.format(name,inclass))
my_func1('李莉') # 没有传递inclass的值,便会使用参数默认的值1
输出 李莉:1
my_func('王','2') # 当传入值时,将覆盖原默认值,使用传递的值
输出 王 2
#关键字参数
def my_func2(name,inclass='1'):
print('{}:{}'.format(name,inclass))
my_func2(inclass='2',name='王') # 可以不用考虑参数的顺序,给需要赋值的参数传值即可
输出 王:2
# 可变参数 指的是可以指定任意数量的参数调用函数
(1)一个*通常会将这些参数打包成元组
def my_func3(name,*args):
print(name,end='')
for i in args:
print(i,end=' ')
my_func2('Jone各科成绩:',23,12,32)
输出 Jone各科成绩:23 12 32
(2)二个**通常会将参数转换成字典
def my_func3(**args):
print(args)
my_func3(Jone=21,lili=23)
输出 {'Jone':21,'lili':23}特殊的函数: lambda匿名函数
格式 <函数名> = lambda <形式参数列表>:<表达式>
如 a = 10
b = lambda c:c*a
print(b(5)) # 输出 50
解析: 将5赋值给c,c与a的乘积赋值给b,最后print打印输出
3.序列解包
1.
保证运算符左边的变量数目与右边序列中的元素数目相等即可
x,y,z = 10,20,30
print(x) # 值为 10
print(y) # 值为 20
print(z) # 值为30
2.
(1)可以通过'*'表达式给单个变量赋值多个元素,'*'获取的值默认为list
x,y,*z = 10,20,30,40
print(x) # 值为 10
print(y) # 值为 20
print(z) # 值为[30, 40]
(2)也可以利用'*'表达式编写函数调用,从参数从列表或者元组中解包
list(range(1,10)) 等价于 list(range(*a)) 其中a=[1,10]
输出相等 [1,2,3,4,5,6,7,8,9]
3.
'**'表达式编写函数调用,将参数从字典中解包
def a(x,y,z):
print(x,y,z)
b = {'x':1,'y':2,'z':3}
a(**b)
输出 1 2 3
4.
在实际中,经常遇到多种参数的组合使用,这时候参数的使用顺序就必须是位置参数、默认参数、可变参数和关键字参数
def test(a,b,c=1,*p,**k):
print('a=',a,'b=',b,'c=',c,'p=',p,'k=',k)
test(3,4) # 输出结果 a=3 b=4 c=1 p=() k={}
test(3,4,5) # 输出结果 a=3 b=4 c=5 p=() k={}
test(3,4,5,'a','b') # 输出结果 a=3 b=4 c=5 p=('a','b') k={}
test(3,4,5,'a','b',x=7,y=8) # 输出结果 a=3 b=4 c=5 p=('a','b') k={'x':7,'y':8}4. 变量的作用域
变量的作用域: 不同种类的变量的访问权限不同,这里的访问权限取决于这个变量是在哪里定义和赋值的.python中最基本的变量作用域分别是全局变量和局部变量
(1)局部变量
(1) 定义在函数体内的变量,只拥有一个局部的作用域
(2) 当函数执行完毕,就会销毁局部变量;函数创建并不意味着函数被调用,只有调用时才会执行函数体
(2)全局变量
(1) 定义在函数体外的,拥有全局的作用域。
(2) 在函数体内、外部都可以被调用(但函数体内不能将其直接赋值);全局变量在函数内部进行修改时,需要用关键字global提前声明,且该变量名与全局变量相同
声明格式: global <全局变量名>
(3) 全局变量是在函数体外被赋值后才可以使用,并不是在整个程序中全局有效
5. 函数递归的定义和使用
(1) 函数递归: 函数在执行过程中调用自身来解决问题
(2)典型例题:斐波那契数列
def factorial(n):
# 递归终止条件
if n == 0:
return 1
# 递归关系
else:
return n * factorial(n - 1)
# 测试
print(factorial(5)) # 输出:1206.内置函数
| python内置函数 | 功能 |
| all(iterable) | iterable迭代参数中的所有元素都为True,则返回True |
| dict() | 生成空字典 |
| sorted() | print(sorted([1,4,2])) 输出[1,2,4] |
| ord()/chr() | 返回字符的ASCII数值/接受0-255内的整数作为参数返回对应的字符 |
| isinstance() | isinstance('1',str),返回值为True |
| reverse() | print([1,2,3].reverse()) 输出 [3,2,1] |
五 组合数据类型
python 中字符编码以Unicode编码存储,chr(x)和ord(x)函数用于在单字符和Unicode编码值之间进行转换
1. 组合数据类型的基本概念
(1)组合数据类型是指由多个数据项组合而成的数据类型,常见的组合数据类型包括列表、元组、字典、集合。
(2) 还可以分成集合类型,序列类型,映射类型, 序列类型包括字符串、列表、元组等,字典类型属于映射类型,且映射类型仅有字典类型
2. 列表类型
(1)列表是一种有序的集合,可以存储多个元素,这些元素可以是不同类型的数据。列表是可变的,即可以修改列表中的元素。允许重复
my_list = [1, 2, 3, "hello", True]
print(my_list[0]) # 访问第一个元素,输出:1
my_list.append("world") # 添加元素
print(my_list) # 输出:[1, 2, 3, "hello", True, "world"]
my_list[1] = 10 # 修改元素
print(my_list) # 输出:[1, 10, 3, "hello", True, "world"]3. 集合类型
集合是一个无序的集合,包含多个唯一的元素。集合中的元素必须是不可变类型(如整数、字符串、元组等),并且集合中的元素是唯一的。
my_set = {1, 2, 3, "hello", True}
print(my_set) # 输出:{1, 2, 3, "hello", True}
my_set.add("world") # 添加元素
print(my_set) # 输出:{1, 2, 3, "hello", True, "world"}
my_set.remove(2) # 删除元素
print(my_set) # 输出:{1, 3, "hello", True, "world"}4. 字典类型
(1)字典是一种无序的键值对集合,每个键值对由一个键和一个值组成。字典的键必须是不可变类型()如整数、字符串、元组等),并且键是唯一的
my_dict = {"name": "Alice", "age": 25, "city": "New York"}
print(my_dict["name"]) # 访问键为 "name" 的值,输出:Alice
my_dict["age"] = 26 # 修改值
print(my_dict) # 输出:{"name": "Alice", "age": 26, "city": "New York"}
my_dict["country"] = "USA" # 添加新的键值对
print(my_dict) # 输出:{"name": "Alice", "age": 26, "city": "New York", "country": "USA"}5. 数据之间的转换
list():将其他类型转换为列表tuple():将其他类型转换为元组dict():将其他类型转换为字典set():将其他类型转换为集合
六 文件和数据格式化
utf-8编码中一个汉字占用3个字节 |gbk、cp936编码中一个汉字需要2个字节
1. 文件的使用
示例一:
with open('file_path','r+') as f:
print(f.read())
示例二:
f = open('file_path')txt = f.read()
f.close()
| 模式 | 含义 |
| r | 只读方式打开文件 |
| w | 覆盖写;如果文件不存在则创建 |
| x | 执行文件新建写入,如果文件存在,则抛出异常 |
| a | 追加写;如果文件不存在则创建 |
| r+/w+ | 可读可写 |
| b/t | 打开二进制文件模式/打开文本文件模式 |
2. 数据组织的维度
一维数据、二维数据、高维数据
(1) 集合不能表示高维数据,任何表现为集合或者序列的内容都可以被认为一维数据
(2) 列表可以表示一维和二维数据
(3)JSOn和字典可以表示高维数据
3. 文件函数
| seek() | 控制文件指针位置,seek(0)表示文件开头,seek(1)表示当前指针开始;seek(2)为文件末尾 |
| tell() | 返回当前文件位置(字节数) |
| readlines() | 返回一个列表,每一行作为列表的一个元素 |
七 Python程序设计方法
- 1. 过程式编程方法。
- 2. 函数式编程方法。
- 3. 生态式编程方法。
- 4. 蒙特卡洛计算方法。
- 5. 递归计算方法。
八 Python计算生态
1. 标准库的使用
(1)turtle库
略(应用题必考,需要自行练习考试真题)
(2)random库
- random库中的randrange(start,stop[,step])函数是生成一个[start,stop)之间以step为步长的随机整数
(3)time库
- 其中包含的strftime()函数的返回值是一个格式化字符串;如果使用time()函数,需要先使用如import time 语句导入time库;time函数可以获取当前时间戳;sleep()可以让程序暂时停止的目的,可以起到延时作用,单位是秒
2. pip命令
| pip -h | 查询帮助信息 |
| pip search <库名字> | 查询关键字 |
| pip install <库名字> | 安装库 |
| pip download <库名字> | 下载库包 |
3. 第三方库应用的领域
(一般考选择题)
(1)开发用户界面第三方库是 PyQt、PyGObject、PyGTK
(2) Web开发第三方库是 Django、Pyramid、Flask
(3) Pygame 游戏开发方向
(4) openpyxl 文本处理方向
(5) TensorFlow 机器学习方向
(6) PIL 图像处理方向
(7) scrapy是网络爬虫方向的第三方库
(8) doit是任务管理和自动化的第三方库
(9) pandas、numpy数据分析的第三方库
(10) NLTK自然语言处理的第三方库


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









