







第一章 Hadoop介绍
1.1什么是Hadoop:
Hadoop是一个开源的、可靠的、可伸缩的、用于处理大数据的分布式计算框架。
1.2常见的知识点概括:
-
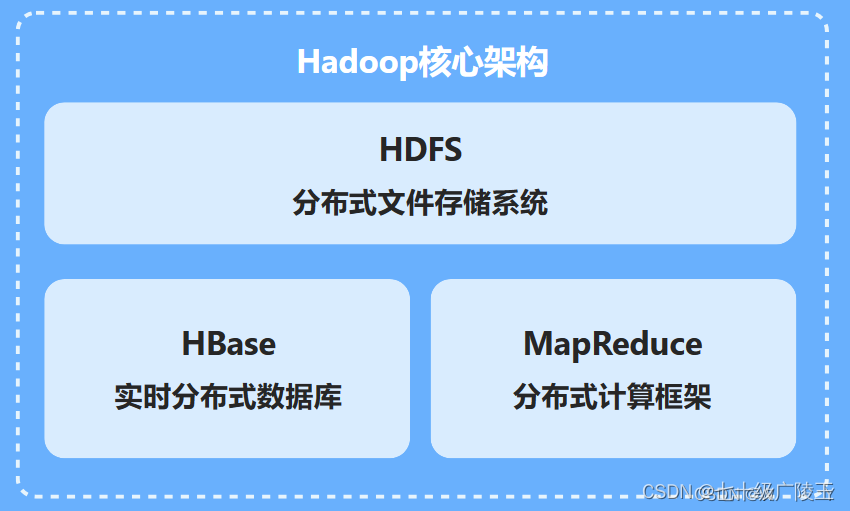
Hadoop HDFS(Hadoop Distributed File System):Hadoop集群中的存储系统,用于大数据的分布式存储。
-
Hadoop MapReduce:Hadoop的原始计算模型,用于并行处理大量数据。
-
Hadoop YARN(Yet Another Resource Negotiator):Hadoop集群中的资源管理系统,用于管理集群中的计算资源。
-
Hadoop Ozone:Hadoop的下一代分布式文件系统项目,设计目标是提供百万级别的小文件支持。
-
Hadoop Common:Hadoop项目中的通用工具库,其他Hadoop模块如HDFS、MapReduce、YARN等都依赖这个库。
-
Hadoop Ecosystem:除了Hadoop自身的组件外,还包括了Spark、Flink等其他大数据处理引擎,以及Hive、Pig、Impala等数据处理工具。
-
Hadoop Security:Hadoop提供的安全机制,如Kerberos认证,用于保障数据处理过程中的安全性。
-
Hadoop Archive:一个可以将HDFS中的一部分数据归档到较小的存储单元中的工具,适用于冷热分离的存储策略。
-
Hadoop DistCp:一个用于在Hadoop集群间复制数据的工具,可以处理大规模的数据复制任务。
-
adoop Ozone:Hadoop的下一代分布式文件系统项目,设计目标是提供百万级别的小文件支持。

第二章Hadoop集群的搭建和配置
2.1安装及配置虚拟机
- 配置虚拟机参数。在新建虚拟机时选择“自定义”,设置硬件兼容性,稍后安装操作系统,选择Linux,Ubuntu 64位作为客户机操作系统。给虚拟机命名,处理器配置内核数量改为2,内存大小根据需要调整,网络类型选择使用桥连接网络(或网络地址转换),I/O控制器类型选择LSI Logic,磁盘类型选择SCSI,创建新虚拟磁盘,指定磁盘容量和文件。
- 安装操作系统。使用下载的Ubuntu ISO文件安装操作系统,配置网络连接,确保虚拟机可以访问外部网络。
- 安装Hadoop。解压Hadoop安装包到指定目录,并将Hadoop添加至环境变量。修改环境变量文件,添加Hadoop相关路径到PATH环境变量中,重新加载环境变量使更改生效,测试Hadoop是否安装成功,输入命令hadoop version查看版本信息。
- 配置Hadoop目录结构。查看Hadoop目录结构,了解各个重要目录的用途。
- 运行Hadoop示例。创建输入文件夹并准备输入数据,运行Hadoop官方案例WordCoun。
2.2搭建Hadoop完全分布式集群
2.2.1搭建Hadoop完全分布式集群的步骤如下:
-
准备硬件
-
安装操作系统
-
配置网络
-
安装Java环境
-
配置SSH免密登录
-
配置Hadoop环境
-
配置Hadoop集群
-
启动Hadoop集群
-
2.2.2具体示例:
-
安装Java环境:sudo apt-get update
sudo apt-get install openjdk-8-jdk -
配置SSH免密登录:ssh-keygen -t rsa
ssh-copy-id <hostname> -
下载并解压Hadoop:wget https://archive.apache.org/dist/hadoop/core/hadoop-3.2.2/hadoop-3.2.2.tar.gz
tar -xzvf hadoop-3.2.2.tar.gz -
配置环境变量:export HADOOP_HOME=/path/to/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
配置Hadoop的
core-site.xml:<configuration><property>
<name>fs.defaultFS</name>
<value>hdfs://<NameNode-hostname>:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/path/to/hadoop-tmp</value>
</property>
</configuration> -
配置Hadoop的
hdfs-site.xml:<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value><NameNode-hostname>:50090</value>
</property>
</configuration> -
配置Hadoop的
mapred-site.xml(如果是YARN):<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> -
配置Hadoop的
yarn-site.xml:<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourc
第三章Hadoop基础操作
3.1认识Hadoop安全模式
Hadoop的安全模式是HDFS(Hadoop分布式文件系统)的一种状态,在这种状态下,集群进入安全模式是为了执行系统检查和数据恢复过程,在此期间不允许对文件系统进行修改操作。
安全模式的主要目的是:
-
数据恢复:集群启动时,NameNode会进入安全模式,此时不允许对数据进行修改,直到数据状态达到安全模式标准。
-
数据校验:在此模式下,DataNode会向NameNode汇报自己所拥有的数据块信息,如果某个数据块的副本数量低于设定的最小副本数,NameNode会指示DataNode进行数据副本的复制。
如何进入和退出安全模式:
-
手动进入:可以通过命令行工具
hadoop dfsadmin -safemode enter进入安全模式。 -
自动退出:当集群达到安全模式标准时(如满足最小副本数要求),将自动退出安全模式。
检查Hadoop是否处于安全模式:
hadoop dfsadmin -safemode get
如果输出结果是"Safe mode is ON",则表示HDFS处于安全模式。
退出安全模式:
Ps:使用这个命令后,HDFS将尝试退出安全模式,允许对文件系统进行正常操作。
3.2查看Hadoop集群的基本
为了查看Hadoop集群的基本状态,你可以使用Hadoop的命令行工具。以下是一些常用的命令:
-
查看HDFS状态:hdfs dfsadmin -report
-
查看YARN(MapReduce)状态:yarn rmadmin -getServiceState rm1
-
查看NameNode状态:hdfs haadmin -getServiceState nn1
-
查看所有DataNode的基本信息:hdfs dfs -datanode -list
查看所有NodeManager的基本信息:yarn node -list确保你有正确的权限和配置来运行这些命令,并且替换命令中的nn1, rm1等为你集群中实际的NameNode和ResourceManager的名字。这些命令会提供集群的健康状况、各节点的状态以及资源使用情况等信息。
第四章MapReduce入门编程
MapReduce是一种编程模型,用于处理和生成大型数据集。以下是MapReduce编程的关键概点和示例代码。
关键概点:
-
Mapper函数:接收输入的键值对,产生中间格式的键值对。
-
Reducer函数:接收来自Mapper的中间格式键值对,进行聚合操作,产生最终输出。
-
配置作业:设置输入数据的位置、设置MapReduce任务的作业。
-
运行作业:提交MapReduce作业到集群执行
4.1在Intellij IDEA中搭建
(待续)
















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









