






爬取商城网站数据
实际中很多网站的网页都不是静态的HTML文档,很多信息都是通过 JavaScript程序处理后才显示出来的动态数据,使用普通的爬虫程序不能爬取这些动态数据。Selenium就是这样一种能模拟浏览器执行JavaScript程序的工具。本项目介绍如何使用Selenium 编写爬虫程序来爬取商城网站动态手机数据。
一、创建任务项目
使用浏览器访问京东商城网站,在搜索文本框中输入“手机”后按Enter键,可以看到图5-1-1所示的页面。分析京东商城的网页发现,很多数据是由JavaScript 程序控制的。在这个项目中将使用selenium设计一个爬虫程序来爬取所有的手机数据与图像。

在爬取京东商城网站数据之前先创建爬取模拟商城网站的数据。创建项目文件夹 project5,在 project5 文件夹中有一个phones.csv文件,文件中存储了手机的数据,其中前面几行数据如下:


1.创建网站模板
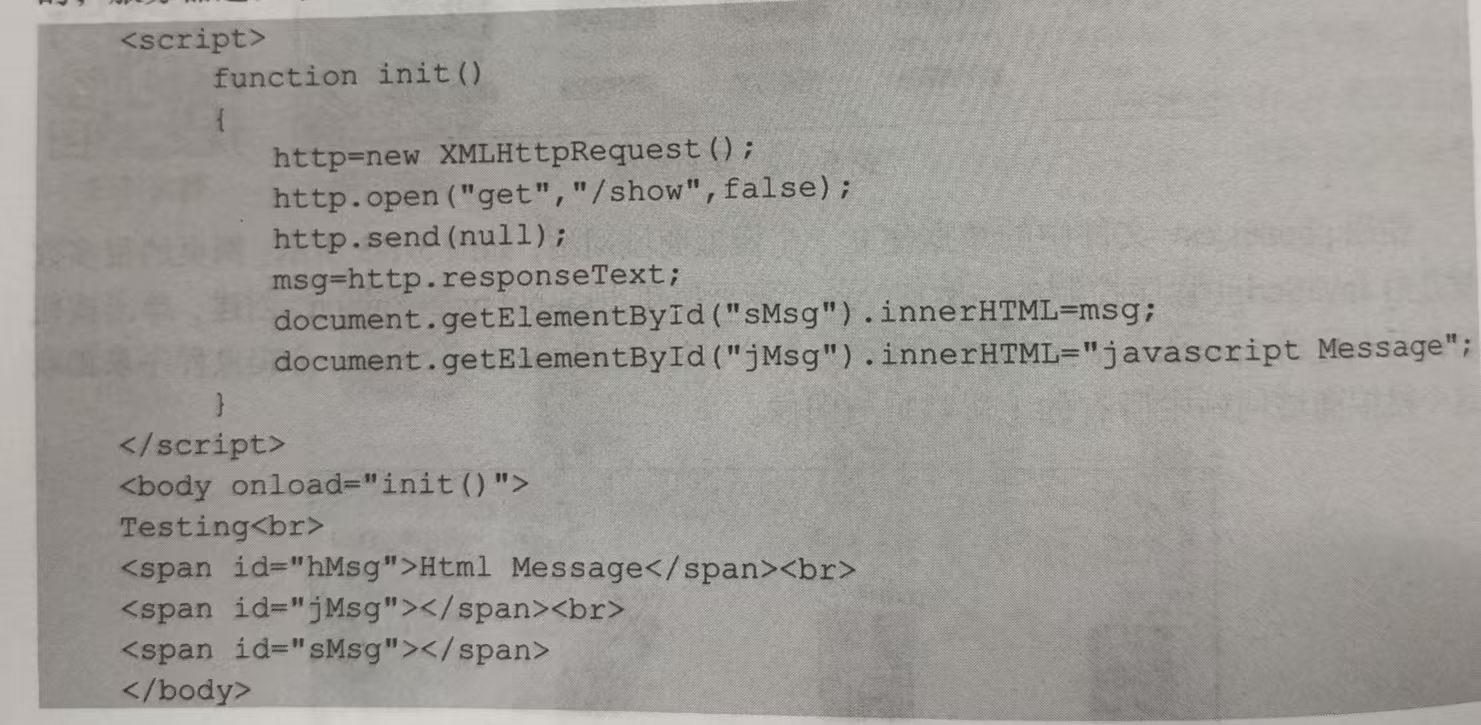
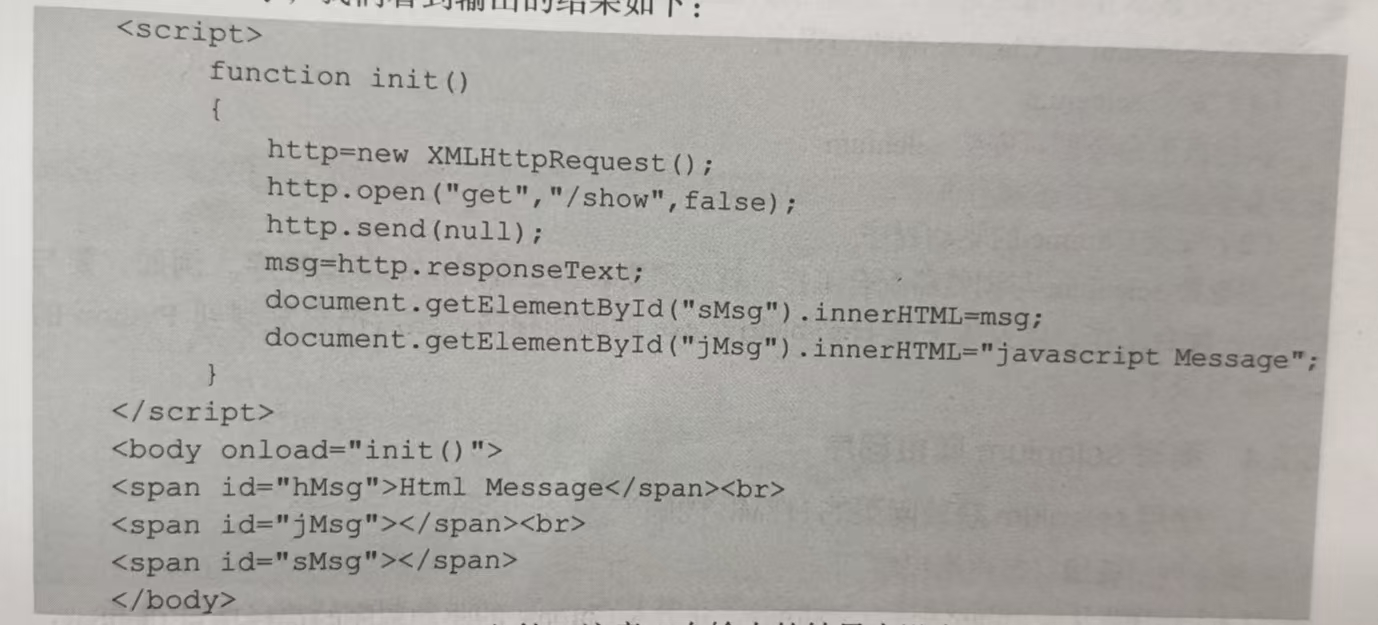
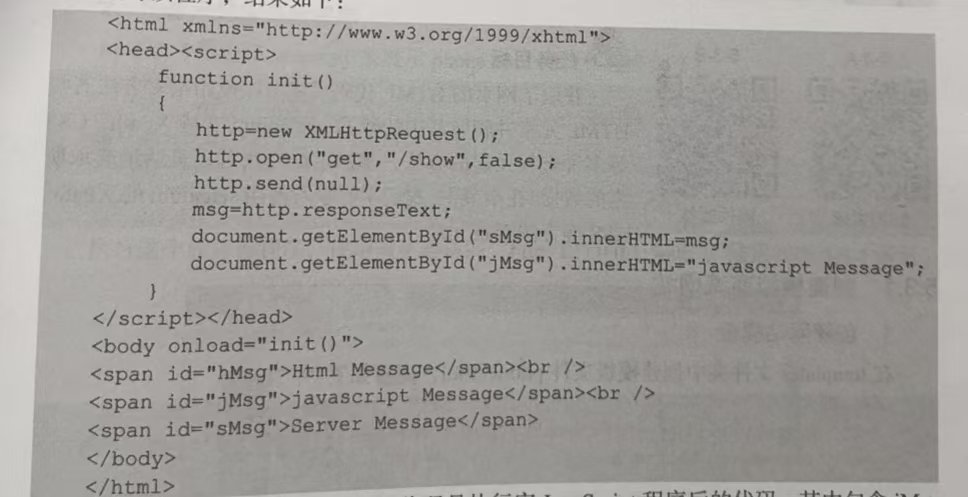
在 project5\templates文件夹中设计一个模板文件phone.html,它包含 3 个<span>: 第1个<span>的id 是“hMsg”,它的信息是确定的“Html Message”;第 2个<span>的 id是“jMsg”,它的信息是在网页加载时由JavaScript的程序赋予的值“javascript Message”;第3个<span>的id是“sMsg”,它的信息是在网页加载时通过Ajax的方法向服务器提出GET请求获取的,服务器返回字符串值“Server Message”。phone.html 模板文件如下:
2.创建网站服务器程序
服务器程序server.py显示出phone.html 文件的内容,其中,index(函数读取该文件并发送出去,show()函数在接收地址“/show”请求后发送“Server Message”。


3.使用浏览器访问
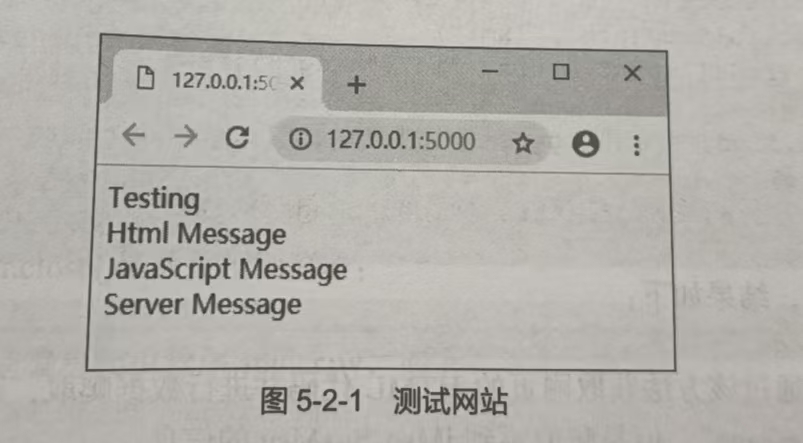
运行服务器程序server.py,使用浏览器访问“http://127.0.0.1:5000”,结果如图 5-2-1所示。
二、普通爬虫程序的问题
1. 编写普通客户端程序
编写一个爬虫程序spider.py,它通过urllib.request 直接访问“http://127.0.0.1:5000”,程序如下:

执行该程序,我们看到输出的结果如下:
得出结果就是phone.html文件。注意,在输出的结果中没有id="jMsg"与 id-"sMsg"的<span>的信息,这些信息在程序运行后产生。
2.编写普通爬虫程序
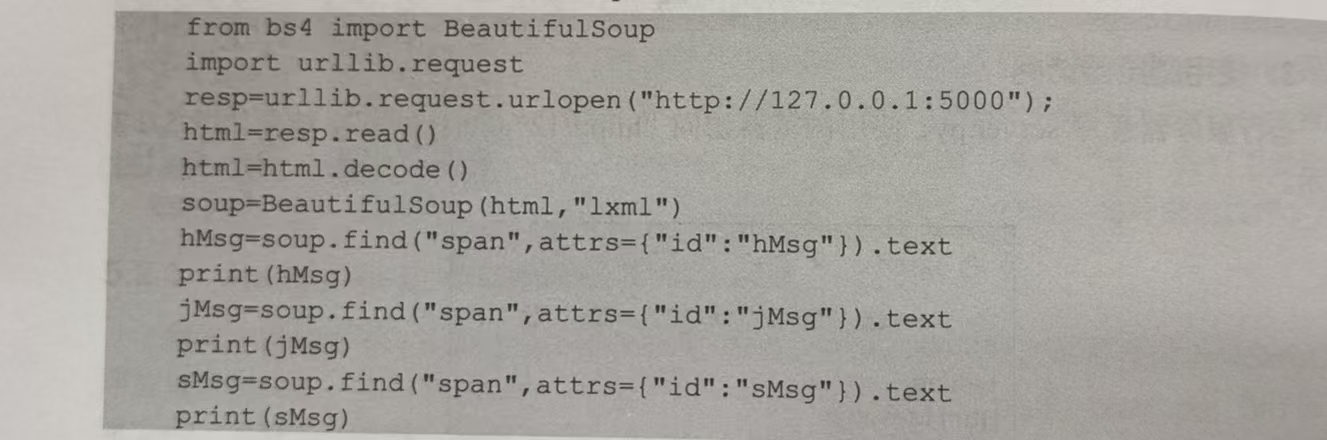
编写一个爬虫程序spider.py,它通过urllib.request 直接访问“http://127.0.0.1:5000”来获取 HTML代码,使用BeautifulSoup解析得到数据,程序如下:
执行该程序,结果如下:
Html Message 显然,如果通过该方法获取网页的HTML代码并进行数据爬取,那么只能爬取 hMsg的信息“Html Message”,但是爬取不到jMsg与sMsg的信息。
因为jMsg与sMsg的信息不是静态地嵌入在网页中的,而是通过JavaScript与Ajax动态产生的。通过urllib.request.urlopen得到的网页中没有这样的动态信息,如果要得到这些信息,就必须让爬虫程序能够执行对应的JsvaScript程序,selenium框架能实现这个功能。
3.安装selenium与Chrome 驱动程序
前面已经分析了要获取jMsg与sMsg的信息就必须使客户端在获取网页后能按要求执行对应的JavaScript程序。显然,一般的客户端程序没有这个能力去执行JavaScript程序,因此必须寻找一个能像浏览器那样工作的插件来完成这个工作,它就是selenium。selenium是一个没有显示界面的浏览器,它能与通用的浏览器(如Chrome、Firefox等)配合工作。下面安装selenium与Chrome的驱动程序。
(1)安装selenium
执行以下命令即可安装selenium。
pip install selenium(2)安装Chrome的驱动程序
要想使selenium与浏览器配合工作,就必须安装浏览器对应的驱动程序。例如,要与 Chrome配合工作,就要先下载chromedrive.exe的驱动程序,然后把它复制到Python 的 scripts 目录下。
4.编写 selenium 爬虫程序
1.使用 selenium 获取网页的 HTML 代码按下列步骤编写客户端程序。
程序先从 selenium引入webdriver.并引入Chrome的驱动程序的选择项目Options:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options2.设置启动Chrome浏览器时不可见:
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')3.创建Chrome 浏览器:
driver= webdriver.Chrome(chrome_options=chrome_options)这样创建的Chrome浏览器是不可见的,如果仅仅使用:
driver= webdriver.Chrome()创建 Chrome 浏览器,那么在程序执行时会弹出一个Chrome浏览器。
4.使用driver.get(url)函数访问网页:
driver.get("http://127.0.0.1:5000")5.通过driver.page_source获取网页的 HTML 代码:
html=driver.page_source
print(html)6.使用driver.close()函数关闭浏览器:
driver.close()根据这样的规则编写爬虫程序spider.py,如下:
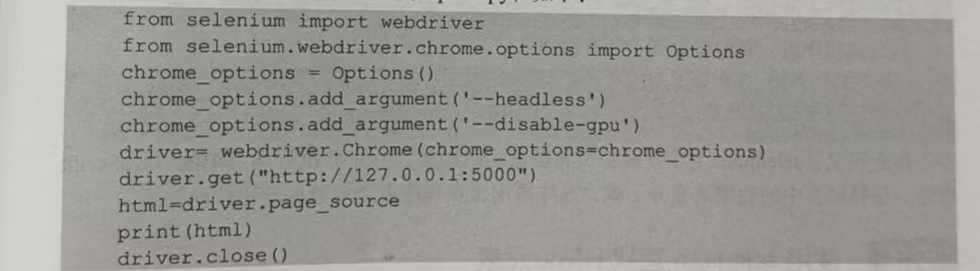
由此可见,我们得到的HTML代码是执行完JavaScript程序后的代码,其中包含jMsg与sMsg的信息。
5.编写 selenium爬虫程序
selenium 模拟浏览器访问网站的方法来获取网页的HTML代码,然后从中爬取需要的数据,这样的爬虫程序功能就比较强大了。编写爬虫程序spider.py,如下:
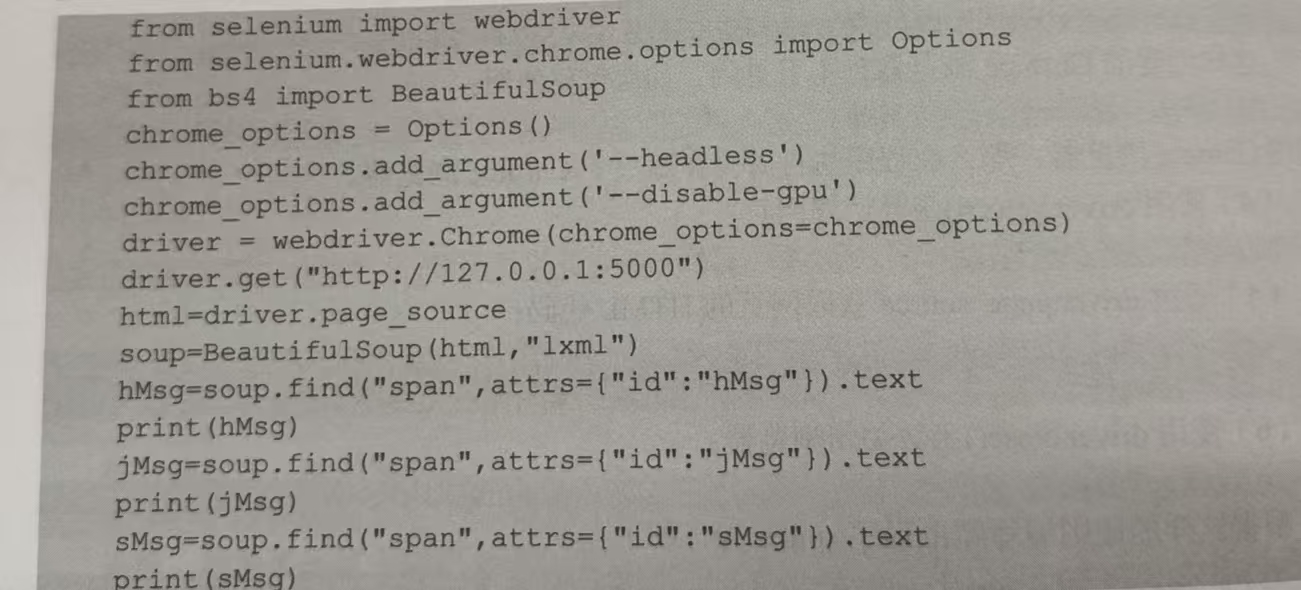
执行该程序后,我们爬取到了所有数据:
Html Message
javascript Message
Server Message由此可见,selenium主要是模拟浏览器去访问网页,并充分执行网页中的JavaScript程序,使得网页中的数据被充分下载,这样再用爬虫程序去爬取数据就比较稳妥了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









