






大家好,小编来为大家解答以下问题,用python编写一个微信小程序,python制作小程序制作流程,现在让我们一起来看看吧!
大家好,本文将围绕python编写一个小程序展开说明,python入门小程序编写是一个很多人都想弄明白的事情,想搞清楚如何用python写小程序需要先了解以下几个事情。
1、字符串分隔
描述
•输入一个字符串,请按长度为8拆分每个输入字符串并进行输出;
•长度不是8整数倍的字符串请在后面补数字0,空字符串不处理python 炫酷代码雨。
输入描述:
连续输入字符串(每个字符串长度小于等于100)
输出描述:
依次输出所有分割后的长度为8的新字符串
示例1
输入:abc
输出:abc00000
st = str(input())
while len(st) % 8 != 0: #判断字符串长度是否为8的整数倍
st = st + '0' #整体补0直至长度为8的整数倍
if len(st) == 8:
print(st)
else:
for i in range(0, len(st), 8): #每8个输出一次
print(st[i:i+8])
2、提取不重复的整数
描述
输入一个 int 型整数,按照从右向左的阅读顺序,返回一个不含重复数字的新的整数伪原创小发猫怎么样。
保证输入的整数最后一位不是 0 。
输入描述:
输入一个int型整数
输出描述:
按照从右向左的阅读顺序,返回一个不含重复数字的新的整数
示例1
输入:9876673
输出:37689
from re import L
num = int(input())
lst = list(map(int, str(num))) #将输入的整数转为int类型的列表
l = []
s = str()
if lst[-1] == 0:
print("输入错误")
else:
for i in range(0, len(lst)):
if lst[len(lst)-i-1] not in l: #把列表中值从右向左的顺序提取到空列表中,并剔除重复项
l.append(lst[len(lst)-i-1])
strlist = [str(x) for x in l] #把列表变为str类型的列表
s = int(''.join(strlist)) #把列表转为int
print(s)
3、求最小公倍数
描述
正整数A和正整数B 的最小公倍数是指 能被A和B整除的最小的正整数值,设计一个算法,求输入A和B的最小公倍数。
输入描述:
输入两个正整数A和B。
输出描述:
输出A和B的最小公倍数
示例1
输入:5 7 输入:2 4
输出:35 输出:4
# a,b = map(int, input().split())
# m = min(a, b)
# lst = []
# for i in range(m, a*b+1):
# if i%a == 0 and i%b == 0:
# lst.append(i)
# lst2 = sorted(lst)
# print(lst2[0])
a,b = map(int, input().split())
for i in range(1,a+1):
if (b * i) % a == 0:
print(b * i)
break
4、简单错误记录
描述
开发一个简单错误记录功能小模块,能够记录出错的代码所在的文件名称和行号。
处理:
1、 记录最多8条错误记录,循环记录,最后只用输出最后出现的八条错误记录。对相同的错误记录只记录一条,但是错误计数增加。最后一个斜杠后面的带后缀名的部分(保留最后16位)和行号完全匹配的记录才做算是“相同”的错误记录。
2、 超过16个字符的文件名称,只记录文件的最后有效16个字符;
3、 输入的文件可能带路径,记录文件名称不能带路径。也就是说,哪怕不同路径下的文件,如果它们的名字的后16个字符相同,也被视为相同的错误记录
4、循环记录时,只以第一次出现的顺序为准,后面重复的不会更新它的出现时间,仍以第一次为准
数据范围:错误记录数量满足 1≤n≤100 ,每条记录长度满足 1≤len≤100
输入描述:
D:\zwtymj\xccb\ljj\cqzlyaszjvlsjmkwoqijggmybr 645
E:\je\rzuwnjvnuz 633
C:\km\tgjwpb\gy\atl 637
F:\weioj\hadd\connsh\rwyfvzsopsuiqjnr 647
E:\ns\mfwj\wqkoki\eez 648
D:\cfmwafhhgeyawnool 649
E:\czt\opwip\osnll\c 637
G:\nt\f 633
F:\fop\ywzqaop 631
F:\yay\jc\ywzqaop 631
D:\zwtymj\xccb\ljj\cqzlyaszjvlsjmkwoqijggmybr 645
输出描述:
rzuwnjvnuz 633 1
atl 637 1
rwyfvzsopsuiqjnr 647 1
eez 648 1
fmwafhhgeyawnool 649 1
c 637 1
f 633 1
ywzqaop 631 2
说明:
由于D:\cfmwafhhgeyawnool 649的文件名长度超过了16个字符,达到了17,所以第一个字符'c'应该被忽略。 记录F:\fop\ywzqaop 631和F:\yay\jc\ywzqaop 631由于文件名和行号相同,因此被视为同一个错误记录,哪怕它们的路径是不同的。 由于循环记录时,只以第一次出现的顺序为准,后面重复的不会更新它的出现时间,仍以第一次为准,所以D:\zwtymj\xccb\ljj\cqzlyaszjvlsjmkwoqijggmybr 645不会被记录。
dic = dict()
while True:
try:
s = input().split("\\")[-1].split()
log = s[0][-16:] + " " + s[1]
dic[log] = dic.get(log, 0) + 1
except:
break
for key, val in list(dic.items())[-8:]:
print(key, val)
5、字符串转化
import sys
a = str(input()).split()
# 第一步:将输入的两个字符串str1和str2进行前后合并
str1=a[0]
str2=a[1]
str3=str1+str2
# print(str3)
# 第二步:对合并后的字符串进行排序,要求为:下标为奇数的字符和下标为偶数的字符分别从小到大排序。
even_chars = sorted(str3[::2])
odd_chars = sorted(str3[1::2])
str4 = ''.join(e+o for e,o in zip(even_chars,odd_chars))
# 处理字符串长度为奇数时,多出的字符
if len(str3)%2 != 0:
str4 += even_chars[-1]
# print(str4)
#第三步:对排序后的字符串中的'0'~'9'、'A'~'F'和'a'~'f'字符,需要进行转换操作。转换规则如下:
#对以上需要进行转换的字符所代表的十六进制用二进制表示并倒序,
#然后再转换成对应的十六进制大写字符(注:字符 a~f 的十六进制对应十进制的10~15,大写同理)。
str5 = ''
for i in str4:
# 筛选字符串中的'0'~'9'、'A'~'F'和'a'~'f'字符
if (i >= '0' and i <= '9') or (i>='A' and i<='F') or (i>='a' and i<='f'):
#使用int()函数将十六进制字符串转换为整数,然后使用bin()函数将整数转换为二进制字符串。但是,请注意,bin()函数返回的二进制字符串前两个字符是0b,因此我们使用切片[2:]来删除这两个字符,只返回纯二进制字符串;zfill(4)填充为4位;[::-1]倒序。
int2 = bin(int(i, 16))[2:].zfill(4)[::-1]
int16 = hex(int(int2,2))[2:].upper()
str5 += ''.join(int16)
else:
str5 += ''.join(i)
print(str5)6、查找两个字符串a,b中的最长公共子串
查找两个字符串a,b中的最长公共子串。若有多个,输出在较短串中最先出现的那个。
注:子串的定义:将一个字符串删去前缀和后缀(也可以不删)形成的字符串。请和“子序列”的概念分开!
数据范围:字符串长度 1≤length≤300
进阶:时间复杂度: O(n3) ,空间复杂度: O(n)
输入描述:
输入两个字符串
输出描述:
返回重复出现的字符
示例1
输入:abcdefghijklmnop
abcsafjklmnopqrstuvw
输出:jklmnop
a = input().strip()
b = input().strip()
if len(a) > len(b):
temp = a
a = b
b = temp
max_sub = ''
for i in range(len(a)):
for j in range(len(a), i, -1): #每循环一次a[i:j] i增大1,j减小1
if (a[i:j] in b) and (len(max_sub) < len(a[i:j])):
max_sub = a[i:j]
print(max_sub)7、奖牌榜的排名
题目描述:奖牌榜的排名算法要求如下,首先是按照金牌总数排序的,如果是同等金牌的情况下,再根据银牌的总数进行排序,同样在金牌跟银牌数量相等的情况下,在根据铜牌的数量进行排名。在遇到金牌了、银牌可跟铜牌数量一样的情况下,根据国家的名称首字母序排序。
输入描述:
第一行输入要排序的国家的个数n,之后n行分别输入国家的名字、金牌总数、银牌总数和铜牌总数以一个空格隔开。
输出描述:
按照降序方式输出国家的名字.
示例:
输入:
4
China 32 28 34
England 12 34 22
France 23 33 2
Jrance 23 33 2
输出:
China
Jrance
France
England
import operator
n = int(input())
lst = []
for i in range(n):
lst.append(list(input().split()))
print(lst) #输入的每一行作为一个[]一共n个组成lst
lst2 = sorted(lst, key=operator.itemgetter(1, 2, 3, 0), reverse=True) 按照每个域中第2、3、4、1个元素进行排序,rever=True为从大到小顺序
#lst2 = sorted(lst, key=lambda x: (x[1], x[2], x[3], x[0]), reverse=True) 同上
for i in range(n):
print(lst2[i][0])
#以下是输出结果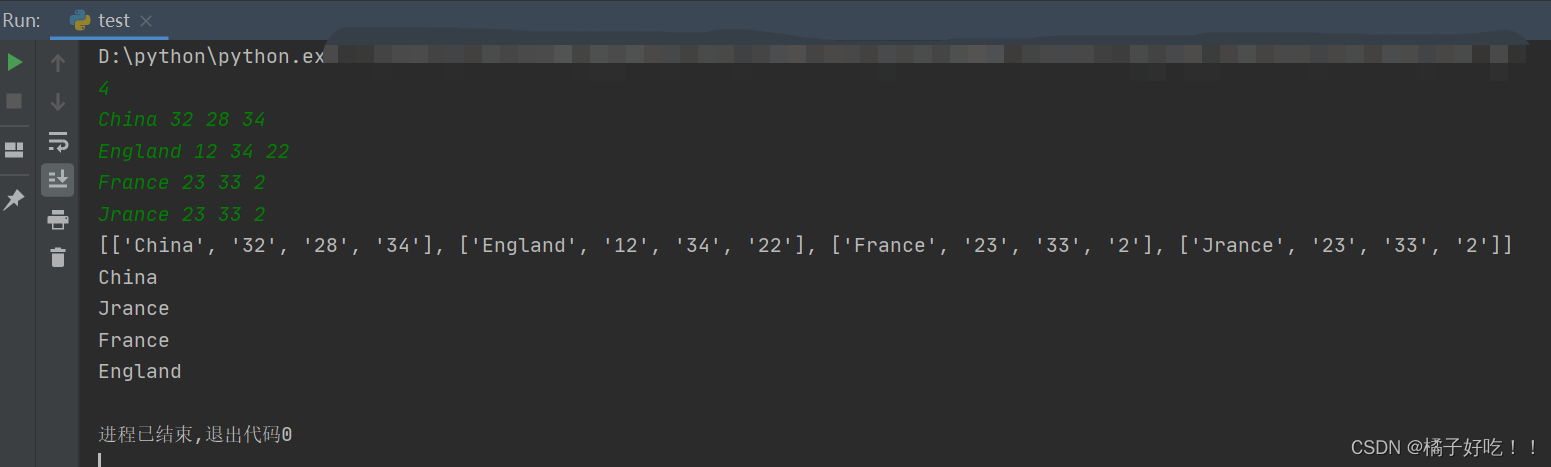
8、简单密码转换
描述:
现在有一种密码变换算法。
九键手机键盘上的数字与字母的对应: 1--1, abc--2, def--3, ghi--4, jkl--5, mno--6, pqrs--7, tuv--8 wxyz--9, 0--0,把密码中出现的小写字母都变成九键键盘对应的数字,如:a 变成 2,x 变成 9.
而密码中出现的大写字母则变成小写之后往后移一位,如:X ,先变成小写,再往后移一位,变成了 y ,例外:Z 往后移是 a 。
数字和其它的符号都不做变换。
数据范围: 输入的字符串长度满足 1≤n≤100
lst = list(str(input()))
lst1 = []
dict1 = {
"1": '1',
"abc": '2',
"def": '3',
"ghi": '4',
"jkl": '5',
"mno": '6',
"pqrs": '7',
"tuv": '8',
"wxyz": '9',
"0": '0',
}
for i in lst:
if i == 'Z':
lst1.append('a')
elif i.isdigit():
lst1.append(i)
elif i.isupper():
lst1.append(chr(ord(i.lower()) + 1)) #把大写字母小写后往后移动一位
elif i.islower:
for j in dict1.keys(): #遍历字典的所有key,i在key里取value
if i in j:
lst1.append(dict1[j])
lst1 = ''.join(lst1) #把list[str]转化为string
print(lst1)
9、合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
res = []
interval_lst = sorted(intervals, key = lambda x: x[0])
n = len(interval_lst)
for i in range(n):
if i == 0:
res.append(interval_lst[0])
else:
interval = interval_lst[i]
if res[-1][1] >= interval[0]:
res[-1][1] = res[-1][1] if res[-1][1] >= interval[1] else interval[1]
else:
res.append(interval)
return res10、保证文件名唯一
给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。
由于两个文件 不能 共享相同的文件名,因此如果新建文件夹使用的文件名已经被占用,系统会以 (k) 的形式为新文件夹的文件名添加后缀,其中 k 是能保证文件名唯一的最小正整数 。
返回长度为 n 的字符串数组,其中 ans[i] 是创建第 i 个文件夹时系统分配给该文件夹的实际名称。
输入:names = ["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece"]
输出:["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece(4)"]
解释:当创建最后一个文件夹时,最小的正有效 k 为 4 ,文件名变为 "onepiece(4)"
class Solution:
def getFolderNames(self, names: List[str]) -> List[str]:
ans = []
memo = set()
for name in names:
if name not in ans: #先把不重复的都提到空列表和空集合里
ans.append(name)
memo.add(name)
else:
k = 1
while True: #如果有重复,后面加(k),加完再比较在不在集合里面,在的话k+1
tmp = f"{name}({k})"
if tmp not in memo:
ans.append(tmp)
memo.add(tmp)
break
k += 1
return ans11、最短回文串
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
示例 1:
输入:s = "aacecaaa"
输出:"aaacecaaa"
示例 2:
输入:s = "abcd"
输出:"dcbabcd"
class Solution:
def shortestPalindrome(self, s: str) -> str:
if not s:
return s
n = len(s)
s_r = s[::-1]
ps = ""
for sft in range(n):
left = s_r[sft:]
right = s[:n-sft]
if left == right:
return ps + s
ps += s_r[sft]12、蛇形矩阵
描述
蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形。
例如,当输入5时,应该输出的三角形为:
1 3 6 10 15
2 5 9 14
4 8 13
7 12
11
输入描述:
输入正整数N(N不大于100)
输出描述:
输出一个N行的蛇形矩阵。
输入:4
输出:
1 3 6 10 2 5 9 4 8 7
# num = int(input())
# for i in range(num):
# k = 0
# for j in range(num):
# if k <= num - i - 2:
# k += 1
# print((i + j + 2) * (i + j + 1) // 2 - i, end=" ")
# else:
# print((i + j + 2) * (i + j + 1) // 2 - i, end="\n")
# break
n = int(input())
list1 = []
# 思路
# 1、输入一个n
# 2、列表解析输出第一行,用到求和公式因为是差递增数列 (首项+末项)*I//2
for j in range(n):
if j == 0:
for i in range(1, n + 1):
list1.append((1 + i) * i // 2)
print(" ".join(map(str, list1)))
else:
list1 = [i - 1 for i in list1[1:]] # 这里非常巧妙 第二行到最后一行是上一行去除第一个元素的结果,就是用一个截取就好
print(" ".join(map(str, list1)))















 3896
3896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









