






1. 二分法查找
思想:
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
时间复杂度:
我们假设数据大小是 n,每次查找后数据都会缩小为原来的一半,也就是会除以 2。最坏情况下,直到查找区间被缩小为空,才停止。

可以看出来,这是一个等比数列。其中 n/2k=1 时,k 的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 n/2k=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
1.1. Python代码
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = left + (right - left) // 2 # 中间索引
if arr[mid] == target:
return mid # 找到目标值,返回索引
elif arr[mid] < target:
left = mid + 1 # 在右半部分查找
else:
right = mid - 1 # 在左半部分查找
return -1 # 没找到
# 示例
nums = [1, 3, 5, 7, 9, 11, 13]
target = 7
index = binary_search(nums, target)
print("索引为:", index) # 输出: 索引为: 3def binary_search_recursive(arr, target, left, right):
if left > right:
return -1 # 递归终止:未找到
mid = left + (right - left) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
return binary_search_recursive(arr, target, mid + 1, right)
else:
return binary_search_recursive(arr, target, left, mid - 1)
# 包装函数,便于调用
def binary_search(arr, target):
return binary_search_recursive(arr, target, 0, len(arr) - 1)
# 示例
nums = [1, 3, 5, 7, 9, 11, 13]
target = 9
index = binary_search(nums, target)
print("索引为:", index) # 输出: 索引为: 41.2. 注意要点
1. 循环退出条件
注意是 low<=high,而不是 low<high。
2.mid 的取值
实际上,mid=(low+high)/2 这种写法是有问题的。因为如果 low 和 high 比较大的话,两者之和就有可能会溢出。改进的方法是将 mid 的计算方式写成 low+(high-low)/2。更进一步,如果要将性能优化到极致的话,我们可以将这里的除以 2 操作转化成位运算 low+((high-low)>>1)。因为相比除法运算来说,计算机处理位运算要快得多。
3.low 和 high 的更新
low=mid+1,high=mid-1。注意这里的 +1 和 -1,如果直接写成 low=mid 或者 high=mid,就可能会发生死循环。比如,当 high=3,low=3 时,如果 a[3] 不等于 value,就会导致一直循环不退出。
1.3. 二分查找应用场景的局限性
1. 二分查找依赖的是顺序表结构,简单点说就是数组
数组按照下标随机访问数据的时间复杂度是 O(1),而链表随机访问的时间复杂度是 O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。
二分查找只能用在数据是通过顺序表来存储的数据结构上。如果你的数据是通过其他数据结构存储的,则无法应用二分查找。
2. 二分查找针对的是有序数据
二分查找对这一点的要求比较苛刻,数据必须是有序的。如果数据没有序,我们需要先排序。前面章节里我们讲到,排序的时间复杂度最低是 O(nlogn)。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
但是,如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。
所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。
3. 数据量太小不适合二分查找
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显。
不过,这里有一个例外。如果数据之间的比较操作非常耗时,不管数据量大小,我都推荐使用二分查找。比如,数组中存储的都是长度超过 300 的字符串,如此长的两个字符串之间比对大小,就会非常耗时。我们需要尽可能地减少比较次数,而比较次数的减少会大大提高性能,这个时候二分查找就比顺序遍历更有优势。
4. 数据量太大也不适合二分查找
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。
2. 跳表
跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度都是 O(logn)。
跳表的空间复杂度是 O(n)。不过,跳表的实现非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。虽然跳表的代码实现并不简单,但是作为一种动态数据结构,比起红黑树来说,实现要简单多了。所以很多时候,我们为了代码的简单、易读,比起红黑树,我们更倾向用跳表。
2.1. 跳表的概念
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
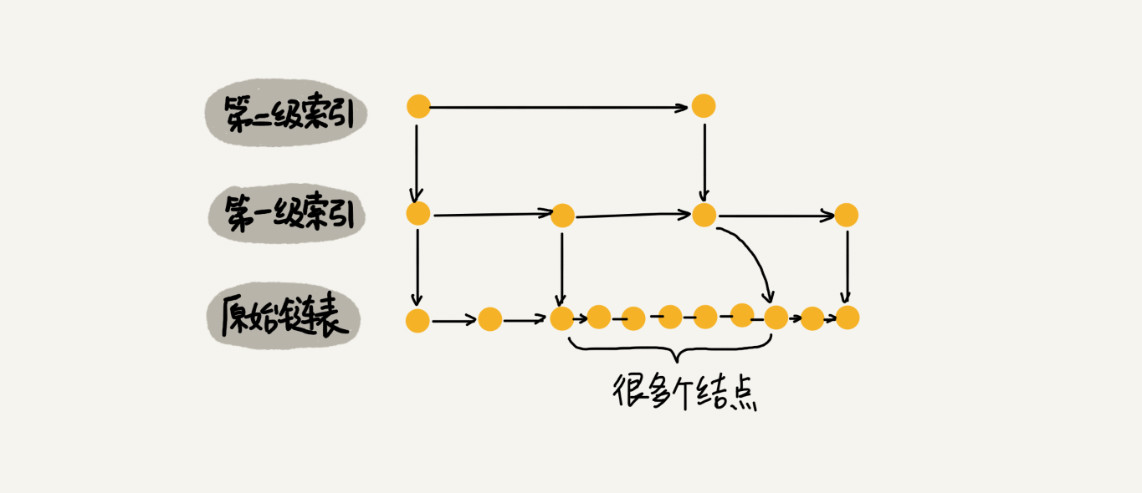
为了提高查找效率,对链表建立一级“索引”,把抽出来的那一级叫作索引或索引层。
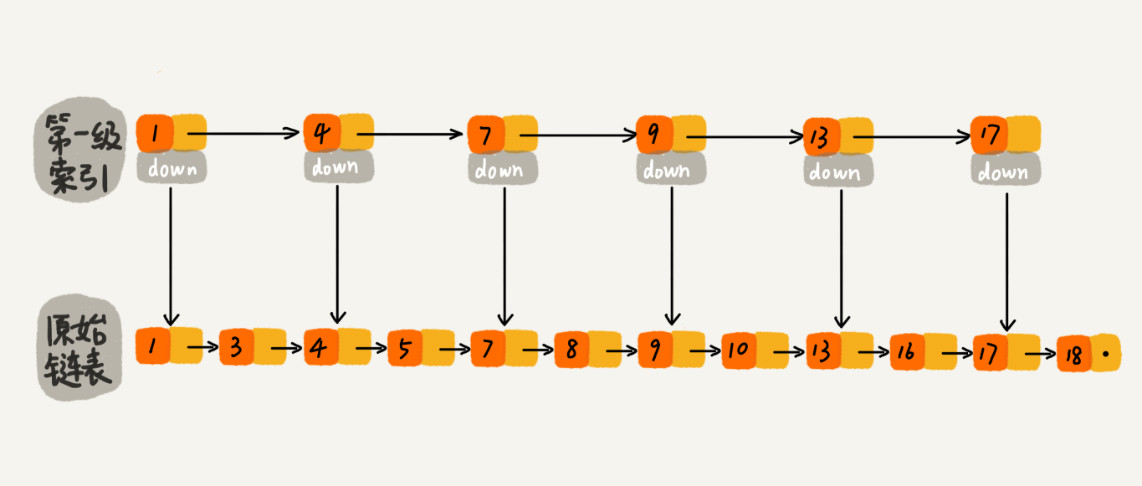
如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。
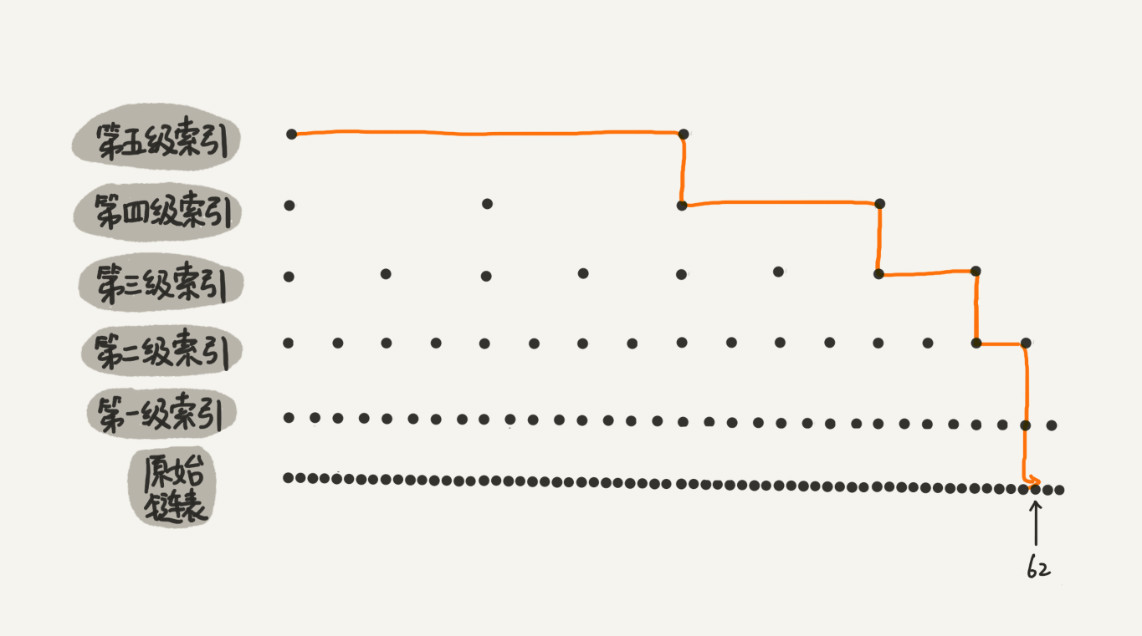
从图中我们可以看出,原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点。当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
这种链表加多级索引的结构,就是跳表。
2.2. 跳表查询的时间复杂度
在一个具有多级索引的跳表中,查询某个数据的时间复杂度:
每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
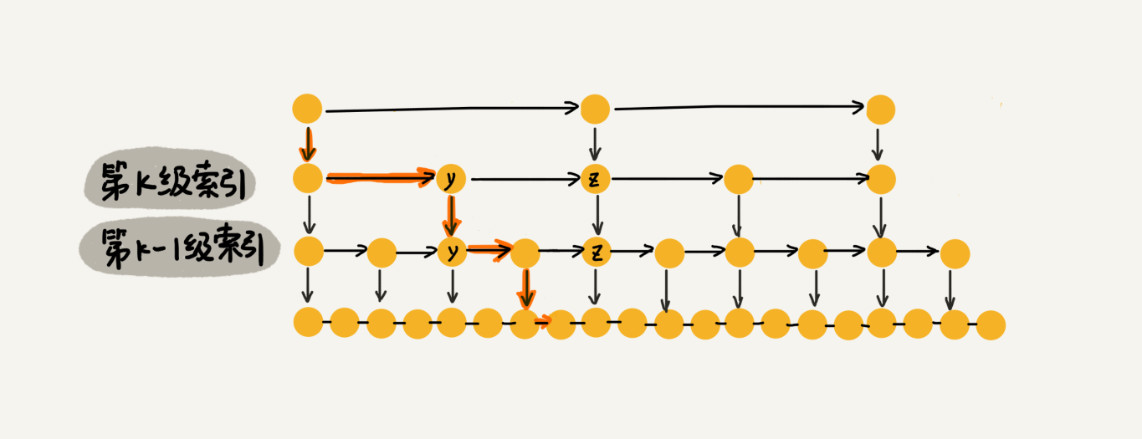
通过分析,得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找。
不过,这种查询效率的提升,前提是建立了很多级索引,也就是空间换时间的设计思路。
2.3. 跳表的空间复杂度
假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。
如果我们每三个结点或五个结点,抽一个结点到上级索引,把每级索引的结点个数都写下来,也是一个等比数列。通过等比数列求和公式,总的索引结点大约就是 n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是 O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
2.4. 高效的动态插入和删除
跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。
对于跳表来说,查找某个结点的的时间复杂度是 O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是 O(logn)。
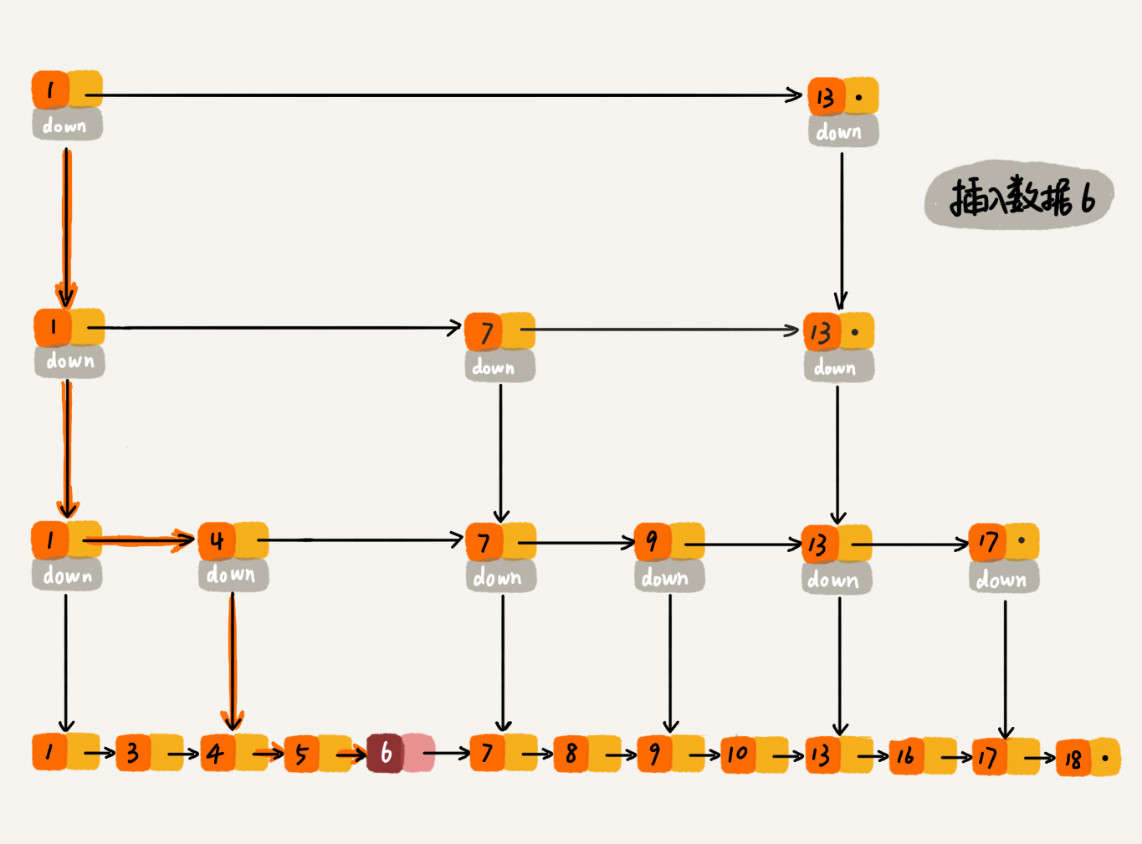
如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果我们用的是双向链表,就不需要考虑这个问题了。
2.5. 跳表索引动态更新
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。
通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
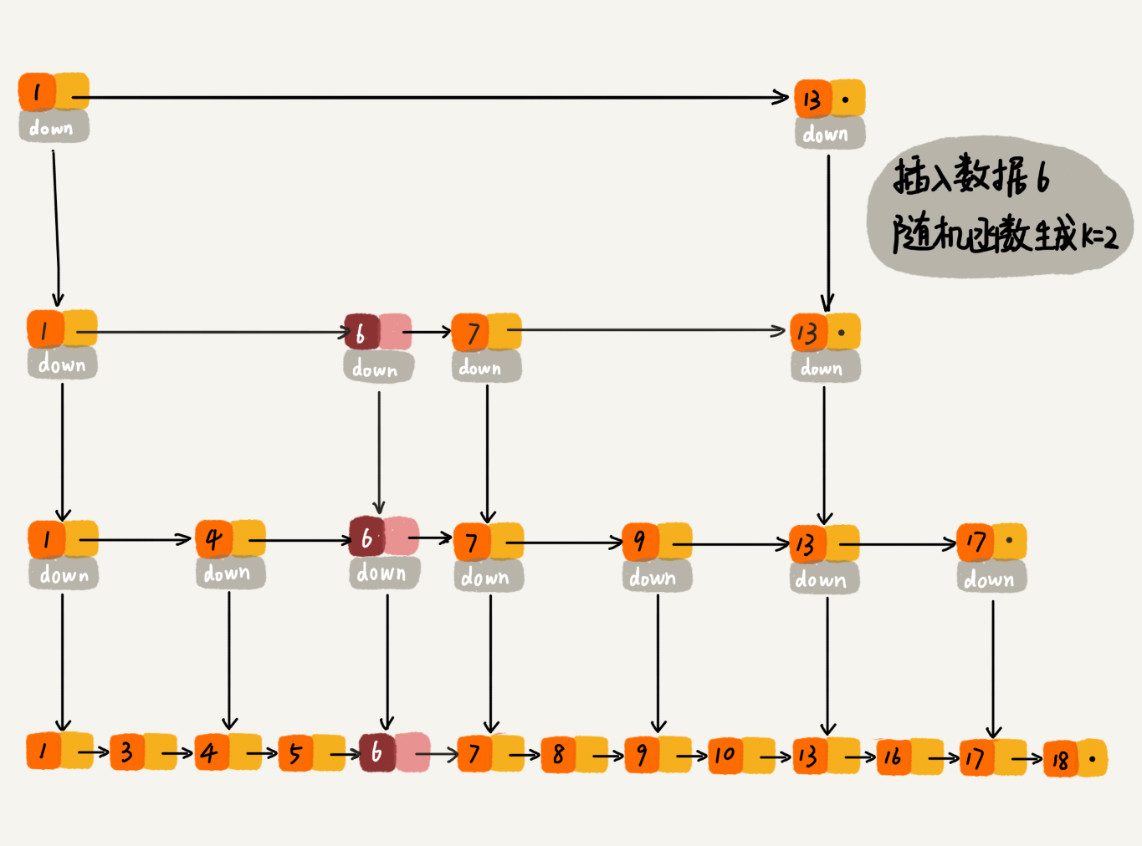
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。
2.6. 跳表的Python代码
(不要求)
import random
MAX_LEVEL = 4 # 最大层数
class Node:
def __init__(self, val, level):
self.val = val
self.forward = [None] * (level + 1) # 每层的前进指针
class SkipList:
def __init__(self):
self.head = Node(-float('inf'), MAX_LEVEL) # 虚拟头结点
self.level = 0 # 当前跳表最大层级
def random_level(self):
lvl = 0
while random.random() < 0.5 and lvl < MAX_LEVEL:
lvl += 1
return lvl
def search(self, target):
curr = self.head
for i in reversed(range(self.level + 1)): # 从顶层向下
while curr.forward[i] and curr.forward[i].val < target:
curr = curr.forward[i]
curr = curr.forward[0]
return curr and curr.val == target
def insert(self, val):
update = [None] * (MAX_LEVEL + 1)
curr = self.head
for i in reversed(range(self.level + 1)):
while curr.forward[i] and curr.forward[i].val < val:
curr = curr.forward[i]
update[i] = curr
lvl = self.random_level()
if lvl > self.level:
for i in range(self.level + 1, lvl + 1):
update[i] = self.head
self.level = lvl
new_node = Node(val, lvl)
for i in range(lvl + 1):
new_node.forward[i] = update[i].forward[i]
update[i].forward[i] = new_node
def delete(self, val):
update = [None] * (MAX_LEVEL + 1)
curr = self.head
for i in reversed(range(self.level + 1)):
while curr.forward[i] and curr.forward[i].val < val:
curr = curr.forward[i]
update[i] = curr
curr = curr.forward[0]
if curr and curr.val == val:
for i in range(self.level + 1):
if update[i].forward[i] != curr:
continue
update[i].forward[i] = curr.forward[i]
while self.level > 0 and self.head.forward[self.level] is None:
self.level -= 1
















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









