






环境使用:
-
Python 3.10
-
Pycharm
模块使用:
-
import requests >>> pip install requests
-
import parsel >>> pip install parsel
-
import prettytable >>> pip install prettytable
-
import os
打包exe程序: pyinstaller -> pip install pyinstaller
爬虫基本实现流程
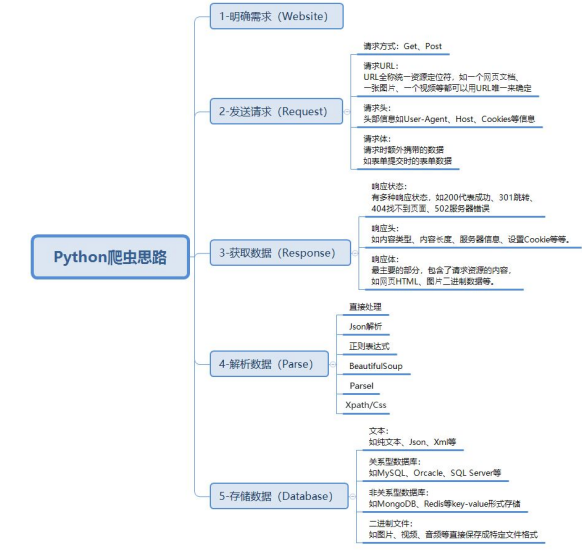
一. 数据来源分析
-
明确需求
明确采集的网站以及数据内容 (实现什么样程序)
程序功能: 通过关键字(歌手/歌名) 进行歌曲搜索, 然后进行对应歌曲内容下载
-
网址: https://www.gequbao.com/
-
数据: 歌曲内容 / 歌曲标题
-
-
抓包分析 (浏览器中进行的操作)
抓包分析: 分析我们需要的数据, 可以请求那个网址能够得到
分析操作: 通过浏览器自带开发者工具
先分析歌曲链接地址 -> 歌曲链接地址从哪里的生成 -> 如何才能实现搜索对应下载功能
-
打开开发者工具: F12
https://www.gequbao.com/music/402856 在网页页面打开开发者工具
-
刷新网页: 让数据内容重新加载一遍
-
快速找到对应歌曲播放地址
https://sy-sycdn.kuwo.cn/af5833d0735b1bba1f86d4ef6c3888d7/65d72918/resource/n
2/70/55/756351052.mp3?from=vip -
通过关键字搜索找到对应数据包位置
爬虫: 批量数据采集
继续分析, 音频链接在那个数据包当中是存在的
关键字: 使用音频链接当中一段参数即可
https://sy-sycdn.kuwo.cn/af5833d0735b1bba1f86d4ef6c3888d7/65d72918/resource/n
2/70/55/756351052.mp3?from=vip比如: 756351052 作为关键字进行搜索
晴天数据包地址: https://www.gequbao.com/api/play_url?id=402856&json=1
阴天数据包地址: https://www.gequbao.com/api/play_url?id=61045&json=1
对比分析: id=xxxx (歌曲ID)
-
晴天ID 402856
-
阴天ID 61045
只要获取到歌曲ID就可以下载对应歌曲内容
-
分析歌曲ID可以请求那个链接获得
搜索链接地址: https://www.gequbao.com/s/%E9%98%B4%E5%A4%A9
- 歌手 / 歌名 / 音乐ID
目的: 根据搜索关键字下载对应歌曲
-
歌曲 -> 专门数据包链接 阴天数据包地址: https://www.gequbao.com/api/play_url?id=xxx&j
son=1 -
获取对应歌曲ID -> https://www.gequbao.com/s/搜索关键字
-
二. 代码实现步骤 (基本四个步骤)
导入的模块
'''
Python学习交流,免费公开课,免费资料,
免费答疑,系统学习加QQ群:926207505
'''
# 导入数据请求模块 (需要安装 pip install requests)
import requests
# 导入数据解析模块 (需要安装 pip install parsel)
import parsel
# 导入制表模块 (需要安装 pip install prettytable)
from prettytable import PrettyTable
# 导入文件操作模块 (无需安装 内置模块)
import os
1. 发送请求
模拟浏览器对于url地址发送请求
while True:
"""发送请求
- 模拟浏览器对于url地址发送请求
"""
# 模拟浏览器
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
# 输入搜索
key = input('请输入你要下载歌曲(00退出): ')
if key == '00':
break
# 请求网址: 搜索链接地址
search = f'https://www.gequbao.com/s/{key}'
# 发送请求
response = requests.get(url=search, headers=headers)
2. 获取数据
获取服务器返回响应数据
# 获取数据: 获取服务器返回响应数据
html = response.text
3. 解析数据
提取我们需要的数据内容
解析方法: 本案例前三个都能用
-
re正则: 对于字符串数据进行提取 字符串数据即可
-
css选择器: 根据标签属性提取数据内容 需要是有标签格式 (√)
-
xpath: 根据标签节点提取数据 需要是有标签格式
-
json数据解析: 一般情况字典取值 (必须json数据格式)
'''
Python学习交流,免费公开课,免费资料,
免费答疑,系统学习加QQ群:926207505
'''
"""解析数据: 提取我们需要的数据内容"""
# 1. 把获取到html字符串数据, 转成可解析对象
selector = parsel.Selector(html)
# 2. 根据标签数据, 提取相关内容 41条数据(第一条和最后一天不是我们需要)
rows = selector.css('.row')[1:-1]
# 实例化对象
tb = PrettyTable()
# 设置字段名
tb.field_names = ['序号', '歌手', '歌名']
# 自定义变量序号
num = 0
# 创建空列表
info = []
# for循环遍历, 提取列表里面元素
for row in rows:
# 3. 进行具体数据解析
title = row.css('.text-primary::text').get().strip() # 歌名
music_id = row.css('.text-primary::attr(href)').get().split('/')[-1] # ID
name = row.css('.text-success::text').get().strip() # 歌手
dit = {
'歌手': name,
'歌名': title,
'ID': music_id,
}
# 添加字典到列表中
info.append(dit)
# 添加字段内容
tb.add_row([num, name, title])
num += 1
print(tb)
key_num = input('请输入你要下载歌曲序号: ')
# 获取歌曲ID -> 传入到歌曲数据包中即可
# 请求网址: 歌曲对应数据包链接
link = f'https://www.gequbao.com/api/play_url?id={info[int(key_num)]["ID"]}&json=1'
# 发送请求 + 获取响应数据
json_data = requests.get(url=link, headers=headers).json()
# 解析数据, 提取歌曲链接
music_url = json_data['data']['url']
4. 保存数据
把数据内容保存本地文件夹 / 数据库 …
"""保存数据"""
music_content = requests.get(url=music_url, headers=headers).content
# 自动创建文件夹
if not os.path.exists('music'): # 判断如果没有文件夹
# 自动创建文件夹
os.mkdir('music')
song_name = info[int(key_num)]["歌名"]
with open(file=f'music\\{song_name}.mp3', mode='wb') as f:
# 保存歌曲内容
f.write(music_content)
print(song_name, '保存成功!')
如果文章看不懂,我还准备了视频教程,同样文末名片获取噢~

▍学习资源推荐
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈




资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取。


















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









