






 本文详细解析了网站文章自动采集的概念,包括其工作原理、应用领域(如新闻、消研和学术界)、优势、面临的挑战(如防爬措施和网页变动),以及合法性、版权问题和未来发展趋势。
本文详细解析了网站文章自动采集的概念,包括其工作原理、应用领域(如新闻、消研和学术界)、优势、面临的挑战(如防爬措施和网页变动),以及合法性、版权问题和未来发展趋势。
对于网站文章自动采集你可能存在疑惑,无须担忧,本文将全面解析此概念。从其含义,运作机制以及应用场景三方面进行细致阐述。
1.什么是网站文章自动采集?
网站文章自动化采集技术,即借助科技实现对互联网文章的智能化收集与整合。该技术采用程序化手段,可便捷且高效率地捕捉各大网站中的文章素材,实现海量数据的采集与加工。
2.网站文章自动采集的工作原理是什么?
此类解决方案主要依赖于网络爬虫技术,一种可模拟网页浏览的软件;利用此类技术获取目标网页的文本内容从而提取所需资料。这些实现过程中可能包括了分析网页架构,运用正则表达式或XPath等手段,精确地定位和提取所需数据。

3.网站文章自动采集有哪些应用领域?
文章自动化搜集在诸多领域均能显现其价值,比如,新闻报道领域,可实现新闻稿件自动摘取以便为编辑提速获取资讯;消研行业,则可收集竞品的产品信息及定价以辅助企业做出明智决策;学术界方面,有助于获取相关文献与研究成果以推动学者们的研究进程。
4.网站文章自动采集有哪些优势?
自动化文章采集系统因其高效、精确及自动化特性,相较于人工采集方式能有效降低时间与人工成本,大幅度提升大数据的处理与分析效率。此外,通过设定适当的筛选参数,可进一步确保数据的高质精准度。
5.网站文章自动采集存在哪些挑战?
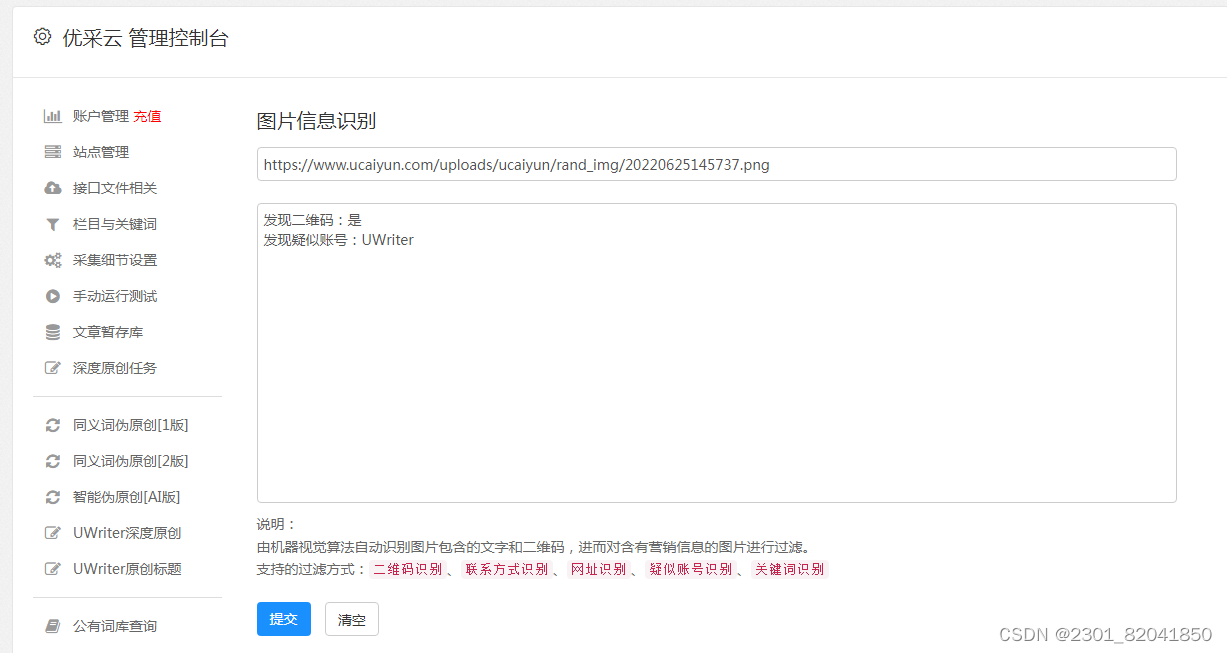
尽管高速采集网站内容具备优点,但是也需应对多种难题。首要问题便是目标网站可能设有防爬措施,如验证码、锁闭IP地址等方式,都会导致爬虫策略收到影响;另一方面,假如目标网站经常变动布局或是进行更新,就必须对应修改爬虫程序以适应网页新结构。
6.如何进行网站文章自动采集?
实施网站文章自动采集需运用特定技术及工具。首先应选择合适的编程语言如 Python 或 Java,并涉及网络爬虫框架的学习;次之,要洞悉目标网站页面结构与数据抽取规则,撰写相应爬虫程式;尤为重要的是需思考数据存储以及处理方案如将数据存入数据库或者转为 Excel 文件等。
7.网站文章自动采集是否合法?
严格来说,网页内容自动收集并不构成违法行为,然而实际操作中必须遵守相应法规与道德标准。例如此举,恪守网站Robots协议,避开禁爬网页;另外务必留意所获数据是否泄漏个人隐私事宜。

8.网站文章自动采集与版权有何关系?
转载引用他人作品须谨慎处理,避免触犯版权法。未经许可的复制和传播行为构成侵权,必须严格遵循相关法律规定,尊重原创者权益。
9.未来网站文章自动采集的发展趋势是什么?
随着科技日新月异的发展,网站文章自动采集将日益智能化与自动化。预计将来更高效的爬虫算法及设备将问世,同时仍需强化相关法律法规以及行业准则,确保网站文章自动采集的健康前行。
希望此文能使您对网站文章自动采集有更深入的理解。如仍有任何疑惑,请随时与我们沟通。

















 9513
9513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









