






分片简介
什么是分片
高数据量和高吞吐量的数据库应用会对单机的性能造成较大压力,大的查询会将单机的 CPU 耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存压力转移到磁盘 IO 上。
为了解决这些问题,有两个基本的方法:
- 垂直扩展:增加更多的 CPU 和存储资源来扩展容量
- 水平扩展:将数据集分布在多个服务器上
MongoDB 的分片就是水平扩展的体现,使用分片减少了每个分片需要处理的请求数。通过水平扩展,集群可以提高自己的存储容量和吞吐量。
何时分片
通常来说,不宜过早对数据进行分片,这会增加部署的复杂性;也不应该过晚进行分片,因为很难在不停止运行的情况下对超载的系统进行分片。
通常情况下,分片用于以下情况:
- 增加可用 RAM
- 增加可用磁盘空间
- 减少服务器的负载
- 处理单个 mongod 无法承受的吞吐量
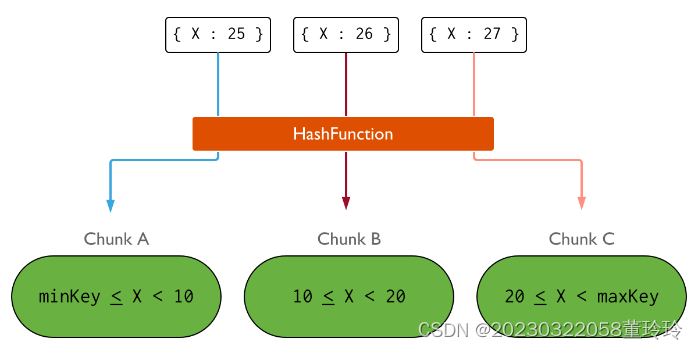
哈希分片
分片过程中可以使用哈希索引作为分片键,其最大的好处是能保证数据在各个节点分布基本均匀。
对于基于哈希的分片,MongoDB 计算一个字段的哈希值,并用这个哈希值来创建数据块。
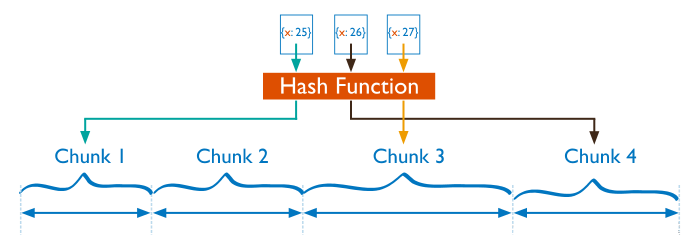
在使用基于哈希分片的系统中,拥有相近分片键的文档很可能不会存储在同一个数据块中,数据的分离性更好一些。
基于哈希分片可以很好地在集群中分配负载,但是,如果随机访问超出了 RAM 大小的数据时,效率会比较低。
范围分片
对于基于范围的分片,MongoDB 按照分片键的范围把数据分成不同部分。
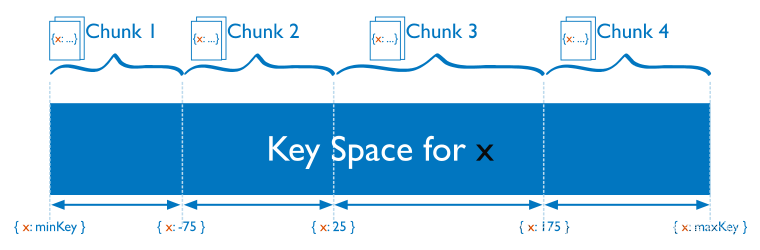
在使用分片键做范围划分的系统中,拥有相近分片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
如果这个分片键是一个自增的值时,将会使 MongoDB 难以保持块的均衡,因为 MongoDB 需要不断将最后一个分片的数据块移动到其他分片上。
哈希和范围的结合
哈希分片更适合随机访问,不适合范围查询;范围分片则是适合范围查询,不适合平衡负载。
一个自定义的方案是,对自增字段构建哈希索引(尽可能是仍然保持有序的哈希算法)即可解决。
准备环境
主要文件夹的节点,IP,数据库路径,日志路径
| 分片 | 节点 | IP:端口 | 数据库路径 | 日志路径 |
| 1 | shard1(主) | localhost:4006 | D:\shard1\shard11\data | D:\shard1\shard11\log |
| 1 | shard2(副) | localhost:4007 | D:\shard1\shard12\data | D:\shard1\shard12\log |
| 2 | shard3(主) | localhost:4008 | D:\shard2\shard21\data | D:\shard2\shard21\log |
| 2 | shard4(副) | localhost:4009 | D:\shard2\shard22\data | D:\shard2\shard22\log |
主要步骤
每一个分片都应该安装MongoDB实例,和前面的主从复制类似,也需要将bin文件夹复制到每个分片中,并创建data文件夹以及log文件夹存放数据库数据和日志数据。
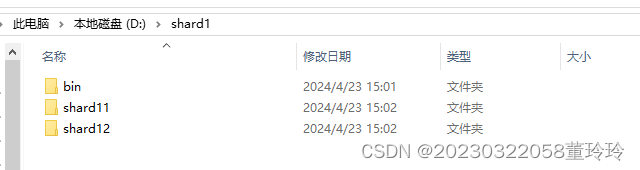


我们shard11文件夹、shard12文件夹、shard21文件夹和shard22文件夹的里的data文件夹和log文件夹全都是空的。
启动分片服务
首先关闭之前打开的数据库服务。

启动分片服务1
然后进入shard1文件夹要分片的数据库bin目录中,启动cmd。
mongod --shardsvr --replSet shard1 -port 4006 -dbpath D:\shard1\shard11\data -logpath D:\shard1\shard11\log\shard11.log

然后再shard11文件夹里的log文件夹就会自动生成shard11文件
--shardsvr为分片声明
不要关闭此窗口,最小化即可
再次进入shard1文件夹要分片的数据库bin目录中,启动cmd
mongod --shardsvr --replSet shard1 -port 4007 -dbpath D:\shard1\shard12\data -logpath D:\shard1\shard12\log\shard12.log

启动分片服务2
然后进入shard2文件夹要分片的数据库bin目录中,再再启动cmd。
mongod --shardsvr --replSet shard2 -port 4008 -dbpath D:\shard2\shard21\data -logpath D:\shard2\shard21\log\shard21.log

然后进入要分片的数据库bin目录中,再再再启动cmd
mongod --shardsvr --replSet shard2 -port 4009 -dbpath D:\shard2\shard22\data -logpath D:\shard2\shard22\log\shard22.log

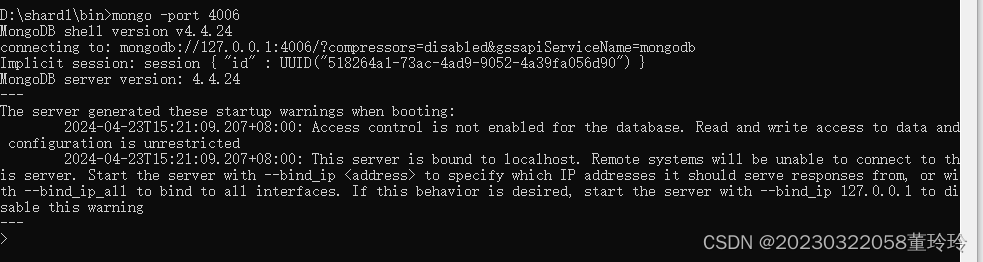
进入分片—初始化分片集
从shard1文件夹的bin启动cmd,进入端口:4006。
mongo -port 4006
config={_id:"shard1",members:[
{_id:0,host:"localhost:4006",priority:2},
{_id:1,host:"localhost:4007",priority:1}
]}
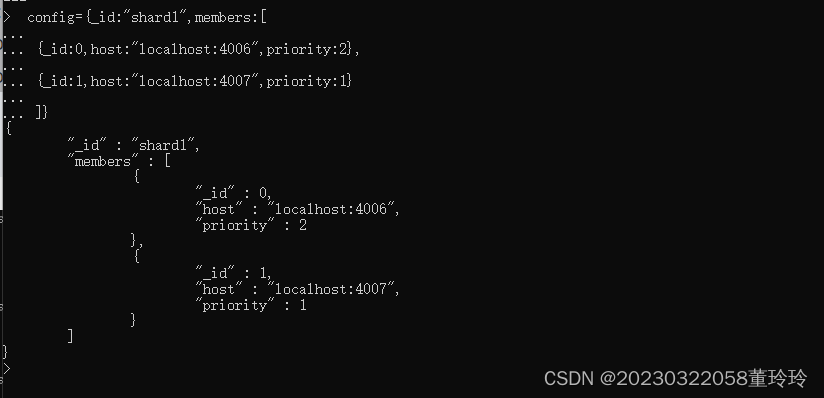
rs.initiate(config)

配置启动Config Server
值得注意的是:在MongoDB 3版本后config服务必须配置为凑副本集,所以直接用前面设置好了的副本启动即可
老样子,每个文件夹添加data和log

| config实例 | 端口号 | 数据库路径 | 日志路径 |
| config1 | 4002 | D:\config\config1\data | D:\config\config1\log |
| config2 | 4003 | D:\config\config2\data | D:\config\config2\log |
两个实例共两个cmd窗口
启动Config1:
进入要分片的数据库bin目录中
mongod --configsvr --replSet confset -port 4002 -dbpath D:\config\config1\data -logpath D:\config\config1\log\conf1.log
--configsvr这里我们完全可以启动普通MongoDB服务一样启动,不需要添加--shardsvr和configsvr参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以了。
三个实例共三个cmd窗口[一次性启动服务,不要关闭cmd窗口,最小化即可]

启动Config2:
mongod --configsvr --replSet confset -port 4003 -dbpath D:\config\config2\data -logpath D:\config\config2\log\conf2.log

进入任何一个配置服务器的节点初始化配置服务器的群集
重新打开一个cmd,在bin目录下
mongo -port 4002
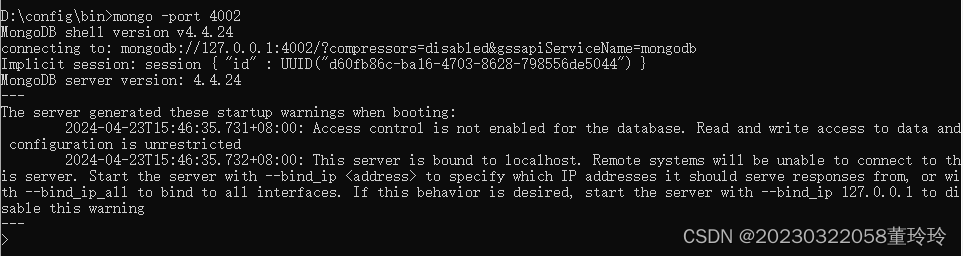
配置设置
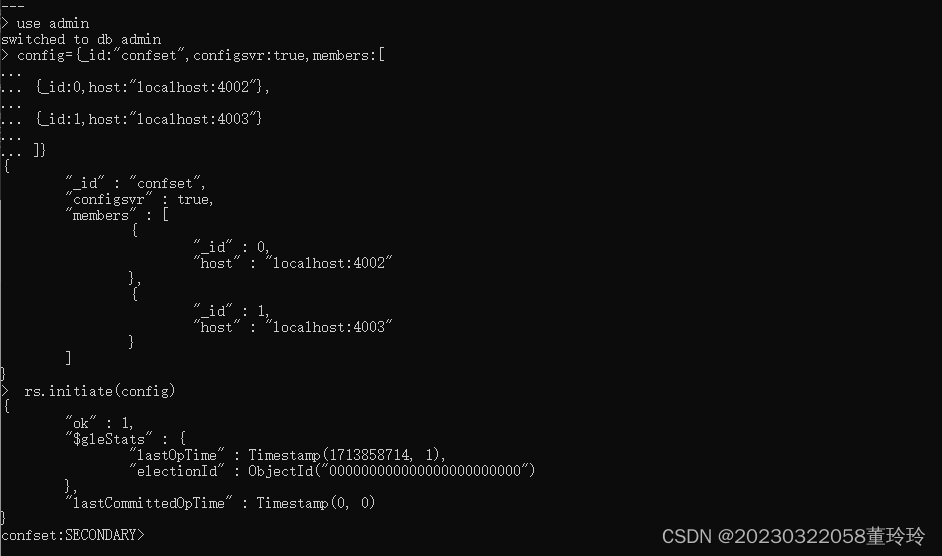
use admin
config={_id:"confset",configsvr:true,members:[
{_id:0,host:"localhost:4002"},
{_id:1,host:"localhost:4003"}
]}
rs.initiate(config)
配置路由服务器Route Process
可以创建窗口专门的文件夹放日志
在进入要分片的数据库bin目录中启动cmd
mongos --configdb confset/localhost:4002,localhost:4003 --logpath D:\mongos\log\mongos.log -port 4000
mongos:mongos就是一个路由服务器,它会根据管理员设置的“片键”将数据分摊到自己管理的mongod集群,数据和片的对应关系以及相应的配置信息保存在“config服务器”上。
 配置分片sharding,添加分片索引
配置分片sharding,添加分片索引
bin目录下使用MongoDB Shell登录到mongos,添加节点
mongo -port 4000
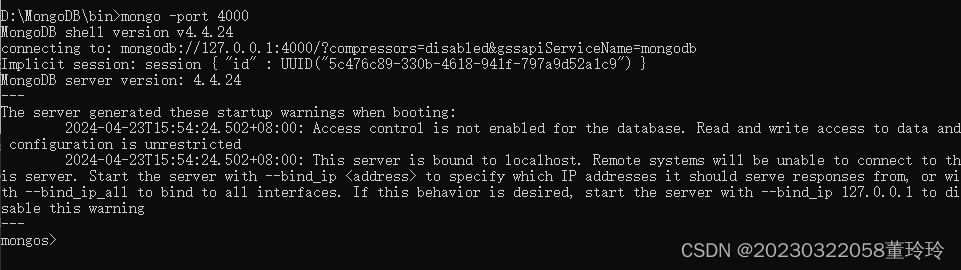
sh.addShard("shard1/localhost:4006,localhost:4007")

sh.addShard("shard2/localhost:4008,localhost:4009")
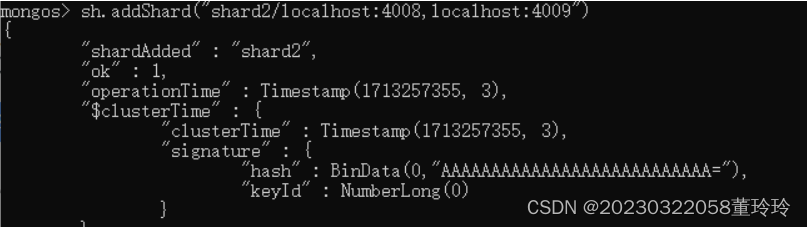
查看分片集
db.getSiblingDB("config").shards.find()

mongodb分片测试
登录4000端口
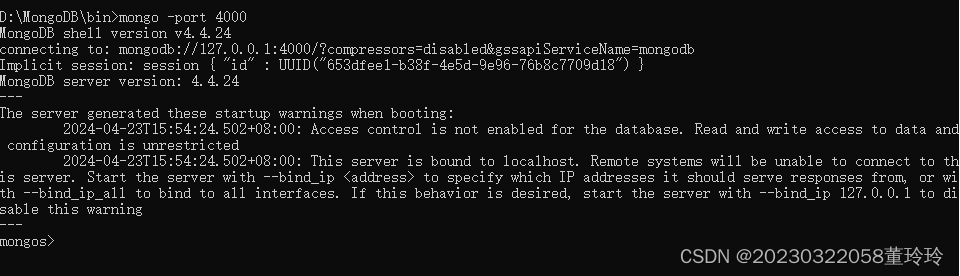
指定要分片的数据库
sh.enableSharding("test")
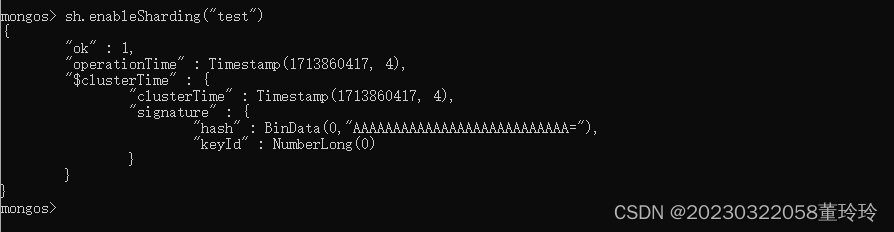
指定数据库里需要分片的集合和片键,片键根据实际情况选择
sh.shardCollection("test.c2",{"id":1})//1 表示范围分片,“hashed”表示哈希分片
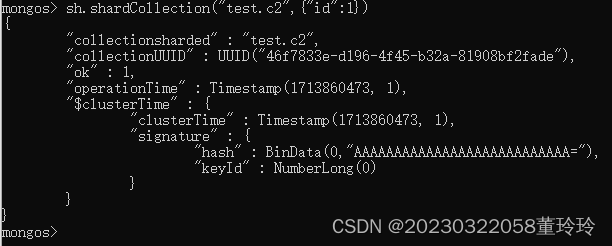
如果集合已经包含数据,则必须在分片集合之前创建一个支持分片的索引,如果集合为空,则mongodb将创建索引。
向test库里的c2集合插入10000条数据
for (var i=1;i<=10000;i++) db.c2.save({id:i,"test1":"testval1"+i})
#查看c2信息
sh.status()
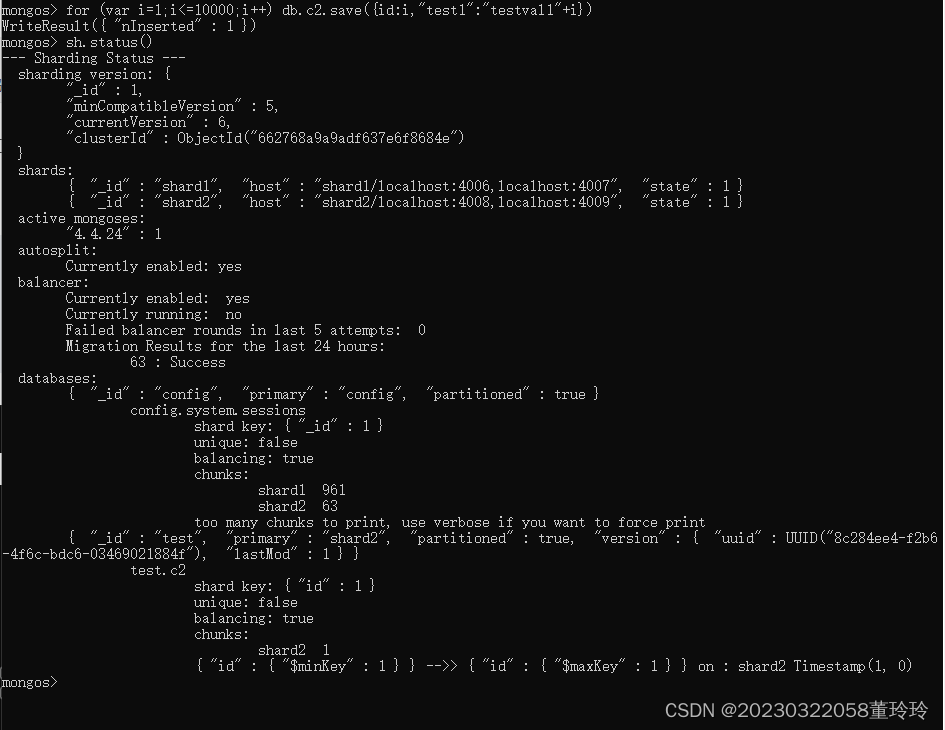
这里可能是数据太少了,出来的结果并不是我想象的那样,根据官方说明,单调变化的键上进行分片,考虑使用哈希分片。
robo 3T查看分片集
robo 3T链接4000端口进行查看
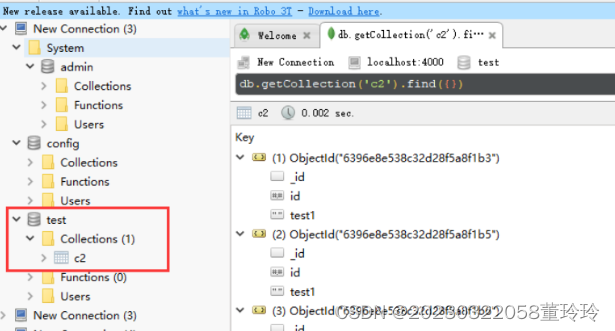
也可以连接两个shard端口查看分片情况
最后
重新打开mongodb服务,即可像原来一样使用,但是数据存储方式已经和原来不一样了,变成了分布式的分片存储。
tips:
电脑版本比较高,所以的cmd需要使用管理员身份运行
启动服务器均为一次性服务,关闭cmd既为关闭服务,所以在未完成前,请勿关闭
实例均未添加至系统环境变量,请在bin目录下启动
虽然窗口很多,操作很多,操作不太友好,但是在win系统下,还是多有耐心一点,linux会简单一些,详细看书上















 1939
1939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









