







parser.add_argument(‘–valInterval’, type=int, default=1, help=‘Interval to be displayed’)
parser.add_argument(‘–saveInterval’, type=int, default=1, help=‘Interval to be displayed’)
parser.add_argument(‘–adam’, default=True, action=‘store_true’, help=‘Whether to use adam (default is rmsprop)’)
parser.add_argument(‘–adadelta’, action=‘store_true’, help=‘Whether to use adadelta (default is rmsprop)’)
parser.add_argument(‘–keep_ratio’,default=True, action=‘store_true’, help=‘whether to keep ratio for image resize’)
parser.add_argument(‘–random_sample’, default=True, action=‘store_true’, help=‘whether to sample the dataset with random sampler’)
parser.add_argument(‘–teaching_forcing_prob’, type=float, default=0.5, help=‘where to use teach forcing’)
parser.add_argument(‘–max_width’, type=int, default=129, help=‘the width of the featuremap out from cnn’)
parser.add_argument(“–output_file”, default=‘deep_model.log’, type=str, required=False)
opt = parser.parse_args()
trainlist:训练集,默认是train.txt。
vallist:验证集路径,默认是val.txt。
batchSize:批大小,根据显存大小设置。
imgH:图片的高度,crnn模型默认为32,这里不需要修改。
imgW:图片宽度,我在这里设置为512。
keep_ratio:设置为True,设置为True后,程序会保持图片的比率,然后在一个batch内统一尺寸,这样训练的模型精度更高。
lr:学习率,设置为0.00005,这里要注意,不要太大,否则不收敛。
其他的参数就不一一介绍了,大家可以自行尝试。
运行结果:
训练完成后,可以在expr文件夹下面找到模型。
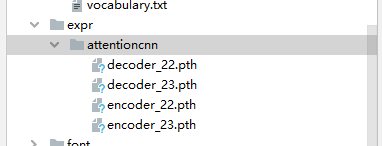
在推理之前,我们还需要确认最长的字符串,新建getmax.py,添加如下代码:
import os
import json
image_path_amount = “./data/train/amount/images”
image_path_date = “./data/train/date/images”
amount_list = os.listdir(image_path_amount)
new_amount_list = []
for filename in amount_list:
new_amount_list.append(image_path_amount + “/” + filename)
date_list = os.listdir(image_path_date)
new_date_list = []
for filename in date_list:
new_date_list.append(image_path_date + “/” + filename)
amount_json = “./data/train/amount/gt.json”
date_json = “./data/train/date/gt.json”
with open(amount_json, “r”, encoding=‘utf-8’) as f:
load_dict_amount = json.load(f)
with open(date_json, “r”, encoding=‘utf-8’) as f:
load_dict_date = json.load(f)
all_list = new_amount_list + new_date_list
from sklearn.model_selection import train_test_split
all_dic = {}
all_dic.update(load_dict_amount)
all_dic.update(load_dict_date)
maxLen = 0
for i in all_dic.values():
if (len(i) > maxLen):
maxLen = len(i)
print(maxLen)
运行结果:28
将test.py中的max_length设置为28。
修改模型的路径,包括encoder_path和decoder_path。
encoder_path = ‘./expr/attentioncnn/encoder_22.pth’
decoder_path = ‘./expr/attentioncnn/decoder_22.pth’
修改测试集的路径:
for path in tqdm(glob.glob(‘./data/测试集/date/images/*.jpg’)):
text, prob = test(path)
if prob<0.8:
count+=1
result_dict[os.path.basename(path)] = {
‘result’: text,
‘confidence’: prob
}
for path in tqdm(glob.glob(‘./data/测试集/amount/images/*.jpg’)):
text, prob = test(path)
if prob<0.8:
count+=1
result_dict[os.path.basename(path)] = {
‘result’: text,
‘confidence’: prob
}
===============================================================
前面提到了数据增强,增强用的百度的StyleText。下载地址:
PaddleOCR: PaddleOCR dome (gitee.com)
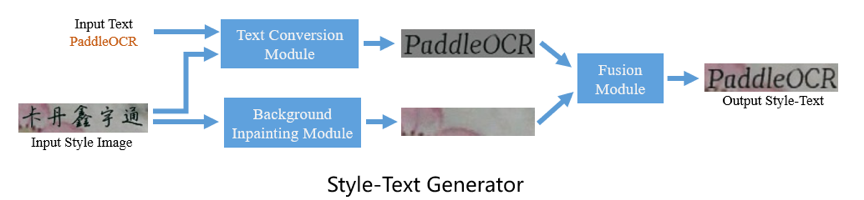

Style-Text数据合成工具是基于百度和华科合作研发的文本编辑算法《Editing Text in the Wild》https://arxiv.org/abs/1908.03047
不同于常用的基于GAN的数据合成工具,Style-Text主要框架包括:1.文本前景风格迁移模块 2.背景抽取模块 3.融合模块。经过这样三步,就可以迅速实现图像文本风格迁移。下图是一些该数据合成工具效果图。

-
安装PaddleOCR。
-
进入
StyleText目录,下载模型,并解压:
cd StyleText
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/style_text/style_text_models.zip
unzip style_text_models.zip
如果您将模型保存再其他位置,请在configs/config.yml中修改模型文件的地址,修改时需要同时修改这三个配置:
bg_generator:
pretrain: style_text_models/bg_generator
…
text_generator:
pretrain: style_text_models/text_generator
…
fusion_generator:
pretrain: style_text_models/fusion_generator
输入一张风格图和一段文字语料,运行tools/synth_image,合成单张图片,结果图像保存在当前目录下:
python3 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/2.jpg --text_corpus PaddleOCR --language en
-
注1:语言选项和语料相对应,目前支持英文(en)、简体中文(ch)和韩语(ko)。
-
注2:Style-Text生成的数据主要应用于OCR识别场景。基于当前PaddleOCR识别模型的设计,我们主要支持高度在32左右的风格图像。
如果输入图像尺寸相差过多,效果可能不佳。
- 注3:可以通过修改配置文件
configs/config.yml中的use_gpu(true或者false)参数来决定是否使用GPU进行预测。
例如,输入如下图片和语料"PaddleOCR":

生成合成数据fake_fusion.jpg:
除此之外,程序还会生成并保存中间结果fake_bg.jpg:为风格参考图去掉文字后的背景;

fake_text.jpg:是用提供的字符串,仿照风格参考图中文字的风格,生成在灰色背景上的文字图片。
批量合成
在实际应用场景中,经常需要批量合成图片,补充到训练集中。Style-Text可以使用一批风格图片和语料,批量合成数据。合成过程如下:
- 在
configs/dataset_config.yml中配置目标场景风格图像和语料的路径,具体如下:
-
Global: -
output_dir::保存合成数据的目录。 -
StyleSampler: -
image_home:风格图片目录; -
label_file:风格图片路径列表文件,如果所用数据集有label,则label_file为label文件路径; -
with_label:标志label_file是否为label文件。 -
CorpusGenerator: -
method:语料生成方法,目前有FileCorpus和EnNumCorpus可选。如果使用EnNumCorpus,则不需要填写其他配置,否则需要修改corpus_file和language; -
language:语料的语种,目前支持英文(en)、简体中文(ch)和韩语(ko);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
项目、讲解视频,并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-pAcfKPKC-1712316094179)]
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









