







复习日
仔细回顾一下之前14天的内容,没跟上进度的同学补一下进度。
作业:
尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项目,这样你也是独立完成了一个专属于自己的项目。
要求:
1.有数据地址的提供数据地址,没有地址的上传网盘贴出地址即可。
2.尽可能与他人不同,优先选择本专业相关数据集
3.探索一下开源数据的网站有哪些?
对于数据的认识,很重要的一点是,很多数据并非是为了某个确定的问题收集的,这也意味着一份数据你可以完成很多不同的研究,自变量、因变量的选取取决于你自己-----很多时候针对现有数据的思考才是真正拉开你与他人差距的最重要因素。
现在可以发现,其实掌握流程后,机器学习项目流程是比较固定的,对于掌握的同学来说,工作量非常少。所以这也是很多论文被懂的认为比较水的原因所在。所以这类研究真正核心的地方集中在以下几点:
1.数据的质量上,是否有好的研究主题但是你这个数据很难获取,所以你这个研究有价值
2.研究问题的选择上,同一个数据你找到了有意思的点,比如更换了因变量,做出了和别人不同的研究问题
3.同一个问题,特征加工上,是否对数据进一步加工得出了新的结论-----你的加工被证明是有意义的。
后续我们会不断给出,在现有框架上,如何加大工作量的思路。
进阶思考:
1.数据本身是否能够支撑起这个研究?---数据的数目、质量
2.数据的来源是否可靠?
3.什么叫做数据的质量?
4.筛选数据源的标准是什么?
一、数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
column_names = ["buying", "maint", "doors", "persons", "lug_boot", "safety", "class"]
data = pd.read_csv('car.data', names=column_names)
# buying v-high, high, med, low
# maint v-high, high, med, low
# doors 2, 3, 4, 5-more
# persons 2, 4, more
# lug_boot small, med, big
# safety low, med, high
# class unacc, acc, good, v-good
#print(data.info())
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
#print(discrete_features)
print(data['class'].unique())
buying_mapping = {
'low': 1,
'med': 2,
'high': 3,
'vhigh': 4
}
data['buying'] = data['buying'].map(buying_mapping)
maint_mapping = {
'low': 1,
'med': 2,
'high': 3,
'vhigh': 4
}
data['maint'] = data['maint'].map(maint_mapping)
lug_boot_mapping = {
'small': 1,
'med': 2,
'big': 3,
}
data['lug_boot'] = data['lug_boot'].map(lug_boot_mapping)
safety_mapping = {
'low': 1,
'med': 2,
'high': 3,
}
data['safety'] = data['safety'].map(safety_mapping)
class_mapping = {
'unacc': 0,
'acc': 1,
'good': 2,
'vgood': 3
}
data['class'] = data['class'].map(class_mapping)
doors_mapping = {
'2': 2,
'3': 3,
'4': 4,
'5more': 5
}
data['doors'] = data['doors'].map(doors_mapping)
persons_mapping = {
'2': 2,
'4': 4,
'more': 5
}
data['persons'] = data['persons'].map(persons_mapping)
print(data.head())
print(data.isnull().sum())二、划分数据集
from sklearn.model_selection import train_test_split
X = data.drop(['class'], axis=1)
y = data['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # (1382, 6) (346, 6) (1382,) (346,)三、默认参数模型与带权重模型对比
import numpy as np # 引入 numpy 用于计算平均值等
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_validate
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
import time
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore")
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time
start_time = time.time()
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
print("SMOTE过采样后训练集的形状:", X_train_smote.shape, y_train_smote.shape)
print("--- 2. 带权重随机森林 + 交叉验证 (在训练集上进行) ---")
counts = np.bincount(y_train)
minority_label = np.argmin(counts)
majority_label = np.argmax(counts)
print(f"训练集中各类别数量: {counts}")
print(f"少数类标签: {minority_label}, 多数类标签: {majority_label}")
rf_model_weighted = RandomForestClassifier(
random_state=42,
class_weight='balanced'
cv_strategy = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scoring = {
'accuracy': 'accuracy',
'precision_minority': make_scorer(precision_score, average='macro', zero_division=0),
'recall_minority': make_scorer(recall_score, average='macro'),
'f1_minority': make_scorer(f1_score, average='macro')
}
print(f"开始进行 {cv_strategy.get_n_splits()} 折交叉验证...")
start_time_cv = time.time()
cv_results = cross_validate(
estimator=rf_model_weighted,
X=X_train_smote,
y=y_train_smote,
cv=cv_strategy,
scoring=scoring,
n_jobs=-1,
return_train_score=False
end_time_cv = time.time()
print(f"交叉验证耗时: {end_time_cv - start_time_cv:.4f} 秒")
print("\n带权重随机森林 交叉验证平均性能 (基于训练集划分):")
for metric_name, scores in cv_results.items():
if metric_name.startswith('test_'):
clean_metric_name = metric_name.split('test_')[1]
print(f" 平均 {clean_metric_name}: {np.mean(scores):.4f} (+/- {np.std(scores):.4f})")
print("-" * 50)
print("--- 3. 训练最终的带权重模型 (整个训练集) 并在测试集上评估 ---")
start_time_final = time.time()
rf_model_weighted_final = RandomForestClassifier(
random_state=42,
class_weight='balanced'
)
rf_model_weighted_final.fit(X_train_smote, y_train_smote)
rf_pred_weighted = rf_model_weighted_final.predict(X_test)
end_time_final = time.time()
print(f"最终带权重模型训练与预测耗时: {end_time_final - start_time_final:.4f} 秒")
print("\n带权重随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_weighted)) # , target_names=[f'Class {majority_label}', f'Class {minority_label}'] 如果需要指定名称
print("带权重随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_weighted))
print("-" * 50)
print("性能对比 (测试集上的少数类召回率 Recall):")
recall_default = recall_score(y_test, rf_pred, average='macro')
recall_weighted = recall_score(y_test, rf_pred_weighted, average='macro')
print(f" 默认模型: {recall_default:.4f}")
print(f" 带权重模型: {recall_weighted:.4f}")四、输出shap特征重要性图
import shap
import matplotlib.pyplot as plt
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
print(shap_values)
#print("shap_values shape:", shap_values.shape)
print("shap_values[0] shape:", shap_values[0].shape)
#print("shap_values[:, :, 0] shape:", shap_values[:, :, 0].shape)
print("X_test shape:", X_test.shape)
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[0], X_test, plot_type="bar",show=False)
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()
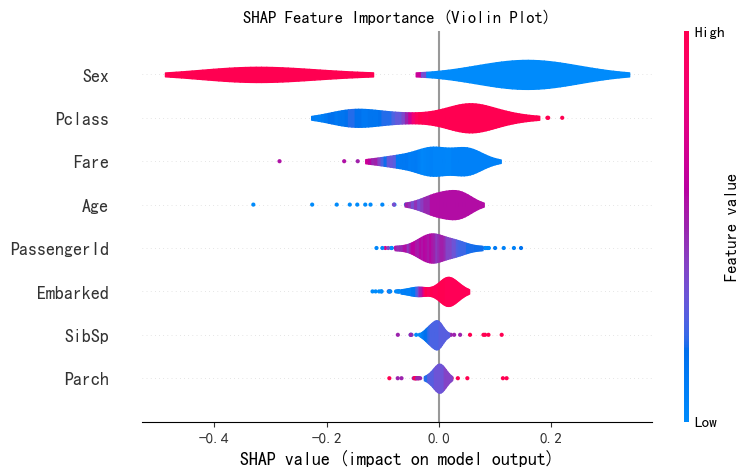
print("--- 2. SHAP 特征重要性蜂巢图 ---")
shap.summary_plot(shap_values[0], X_test,plot_type="violin",show=False,max_display=10)
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()
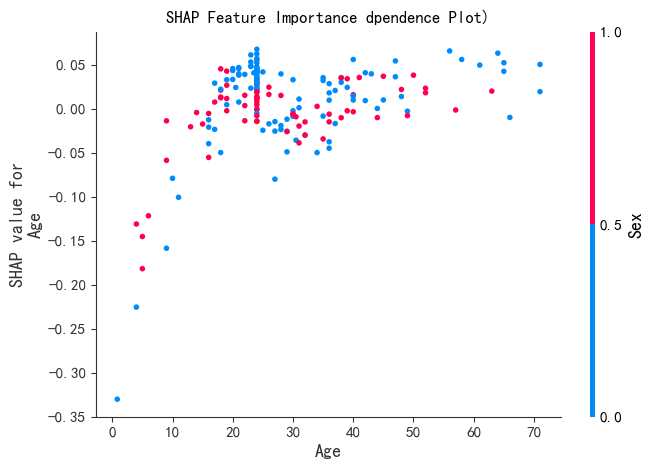
print("--- 3. SHAP 特征重要性dependence plot ---")
shap.dependence_plot('doors',shap_values[0], X_test,show=False)
plt.title("SHAP Feature Importance (dependence plot)")
plt.show()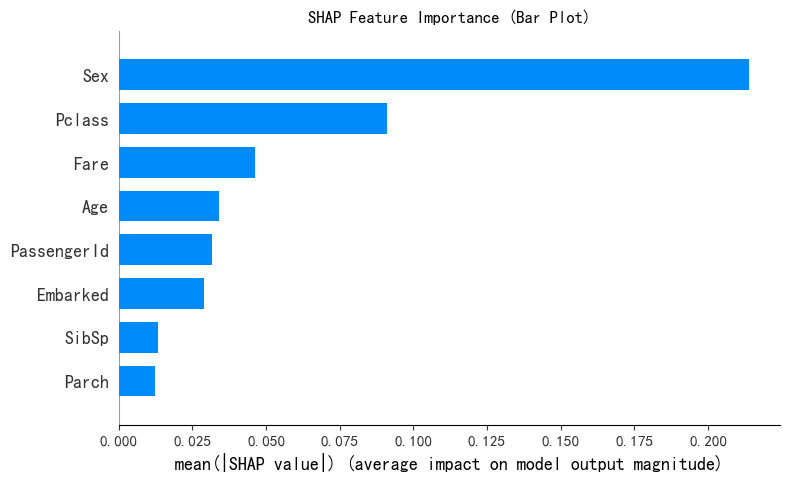


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









