








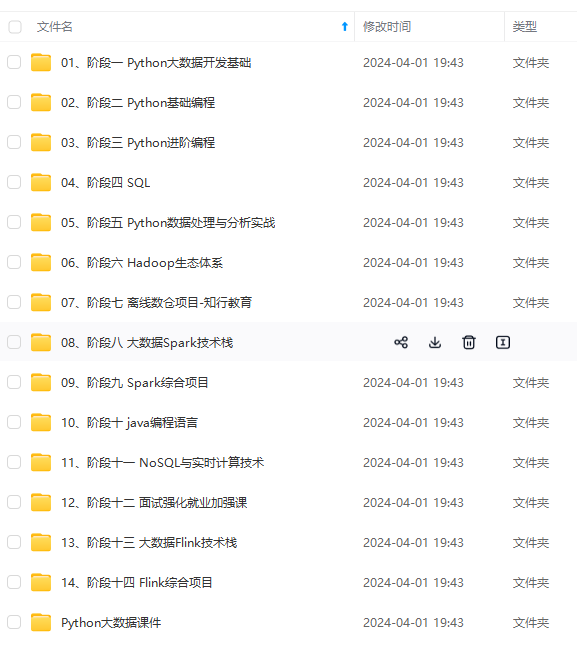
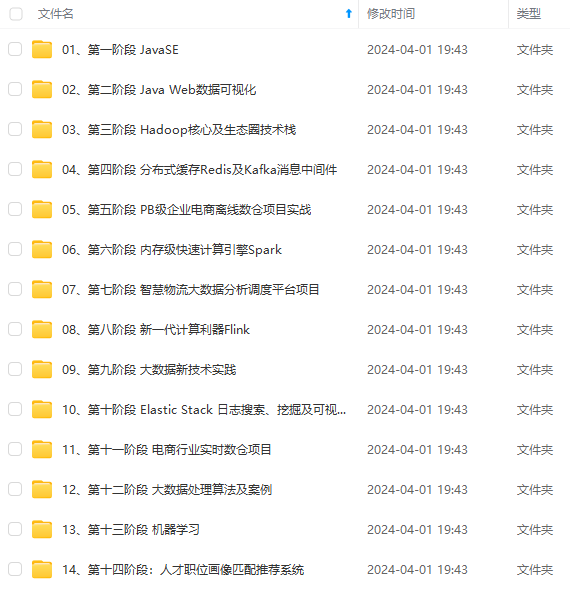
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

本栏目大数据开发岗高频面试题主要出自
大数据技术专栏的各个小专栏,由于个别笔记上传太早,排版杂乱,后面会进行原文美化、增加。
文章目录
停🤚
不要往下滑了,
默默想5min,
看看这5道面试题你都会吗?
面试题 01、请简述LSM模型的设计思想
面试题02、什么是Flush,什么时候会触发Flush?
面试题 03、什么是Compaction,什么时候会触发Compaction?
面试题04、什么是Spit,什么时候会触发Split?
面试题05、MapReduce读取Hbase数据的原理及返回值是什么?


以下答案仅供参考:
面试题 01、请简述LSM模型的设计思想
•step1:数据写入的时候,只写入内存
•step2:将数据在内存构建有序,当数据量大的时候,将有序的数据写入磁盘,变成一个有序的数据文件
•step3:基于所有有序的小文件进行合并,合并为一个整体有序的大文件
面试题02、什么是Flush,什么时候会触发Flush?
•Flush是指将memstore中的数据写入HDFS,变成StoreFile
•2.0之前:判断memstore存储大小,单个memstore达到128M就会触发Flush,或者整个memstore达到95%就会触发
•2.0之后:根据平均每个memstore的存储大小与16M取最大值计算水位线,高于水位线就Flush,不高于就不Flush,都不高于全部Flush
面试题03、什么是Compaction,什么时候会触发Compaction?
•Compaction的功能是将多个单独有序StoreFile文件进行合并,合并为整体有序的大文件并且删除过期数据,加快读取速度
•2.0之前:通过minor compaction和major compaction来实现
–minor compaction:用于合并最早生成的几个小文件,不清理过期数据
–major compaction:用于将所有storefile合并为一个StoreFile,并清理过期数据
•2.0之后:除了minor compaction和major compaction,添加了in-memory-compaction
–In-memory compaction:在内存中进行合并,合并以后的结果再进行flush,有四种配置
•none:不开启
•basic:开启,但是合并时不删除过期数据
•eager:开启,合并时并清理删除过期数据
•adaptive:开启,并在合并时根据数据量来自动判断是否清理过期数据

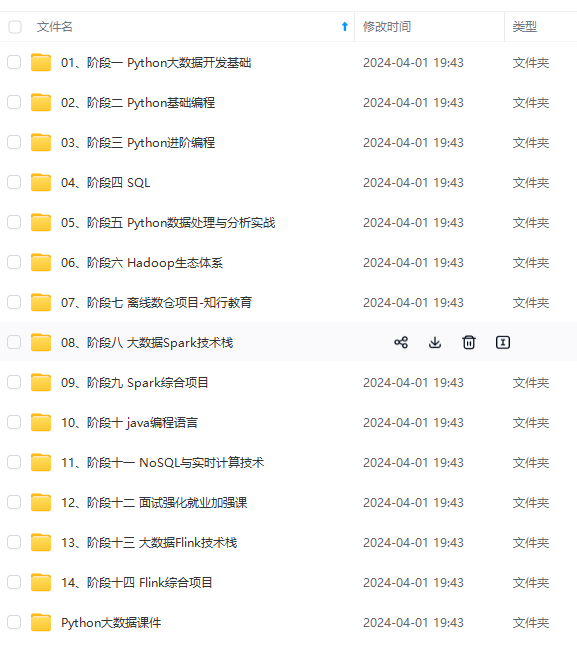
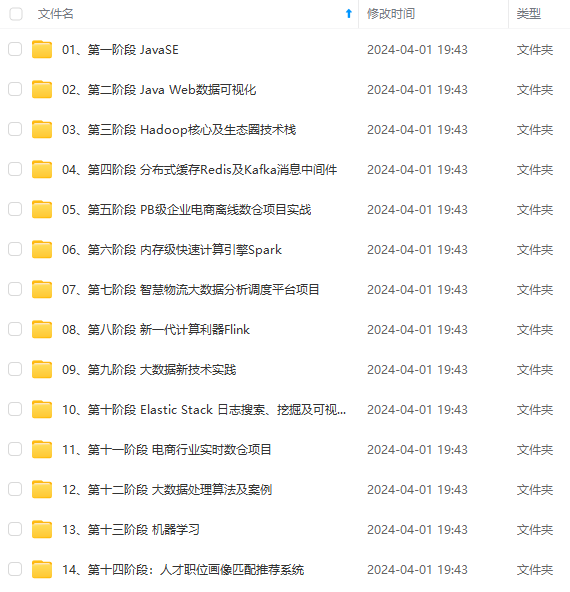
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
解视频,并且后续会持续更新**















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









