







最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
author:Dragon少年
获取商品
def get_product(key_word):
# 定位输入框
browser.find_element_by_id(“q”).send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element_by_class_name(‘btn-search’).click()
browser.maximize_window()
# 等待20秒,方便手动登录
time.sleep(20)
# 定位这个“页码”,获取“共100页这个文本”
page_info = browser.find_element_by_xpath(‘//div[@class=“total”]’).text
# findall()返回的是一个列表
page = re.findall(“(\d+)”, page_info)[0]
return page
**获取数据:**
author:Dragon少年
获取数据
def get_data():
# 所有的信息都在items节点下
items = browser.find_elements_by_xpath(‘//div[@class=“items”]/div[@class="item J_MouserOnverReq "]’)
for item in items:
pro_desc = item.find_element_by_xpath(‘.//div[@class=“row row-2 title”]/a’).text
# 价格
pro_price = item.find_element_by_xpath(‘.//strong’).text
# 付款人数
buy_num = item.find_element_by_xpath(‘.//div[@class=“deal-cnt”]’).text
# 店铺
shop = item.find_element_by_xpath(‘.//div[@class=“shop”]/a’).text
# 发货地
address = item.find_element_by_xpath(‘.//div[@class=“location”]’).text
with open(‘{}.csv’.format(key_word), mode=‘a’, newline=‘’, encoding=‘utf-8-sig’) as f:
csv_writer = csv.writer(f, delimiter=‘,’)
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
**selenium模拟爬取:**
author:Dragon少年
key_word = input(“请输入您要搜索的商品:”)
browser = webdriver.Chrome()
browser.execute_cdp_cmd(“Page.addScriptToEvaluateOnNewDocument”, {
"source": """
Object.defineProperty(navigator, ‘webdriver’, {
get: () => undefined
})
“”"
})
browser.get(‘https://www.taobao.com/’)
page = get_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print(“=” * 100)
print(“正在爬取第{}页”.format(page_num + 1))
browser.get(‘https://s.taobao.com/search?q={}&s={}’.format(key_word, page_num * 44))
browser.implicitly_wait(15)
get_data()
page_num += 1
print(“爬取结束!”)
至此我们就可以爬取月饼的数据并保存下来,如下图所示。
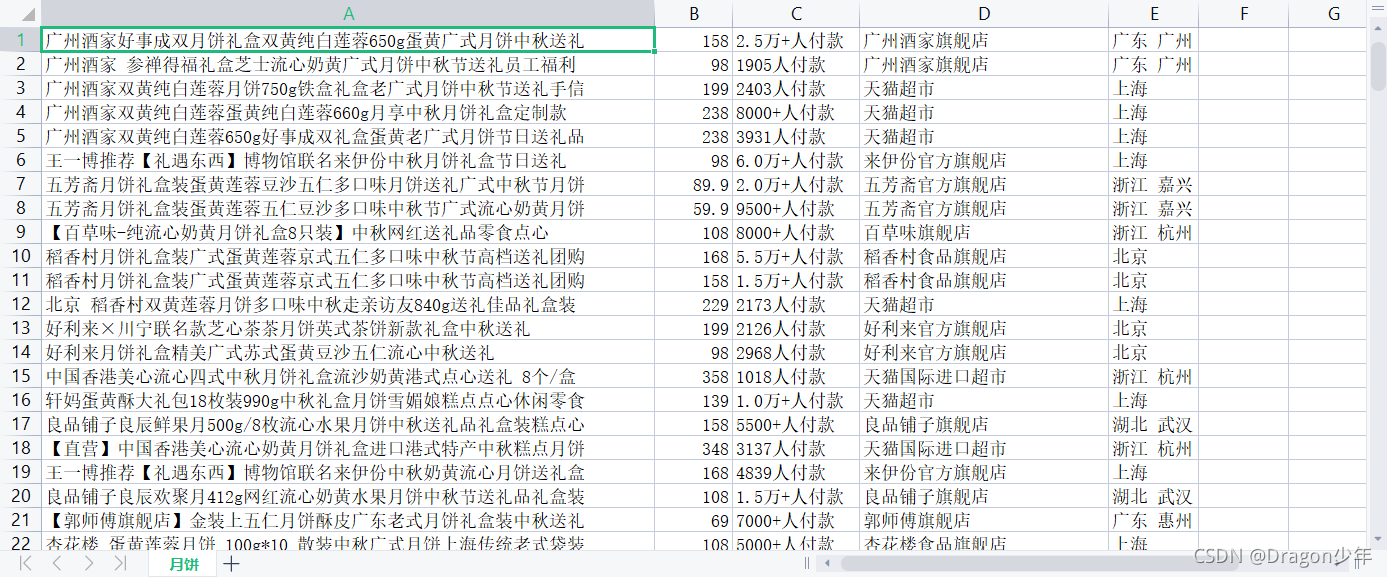
##### 2. 数据清洗
接下来我们需要把爬虫获取的数据进行清洗,首先可以去除重复数据,删除没有人购买的记录。核心代码如下:
author:Dragon少年
读取爬虫数据
df = pd.read_csv(“月饼.csv”, encoding=‘utf-8-sig’, header=None)
df.columns = [“商品名”, “价格”, “购买人数”, “店铺”, “地址”]
去除重复的数据
df.drop_duplicates(inplace=True)
print(df.shape)
删除购买人数0的记录
df[‘购买人数’] = df[‘购买人数’].replace(np.nan,‘0人付款’)
对于购买人数,有些是按照万为单位显示,我们需要将销售量进行统一,并将发货地区进行整理出各个省份信息,最后将这些清洗的数据保存下来。核心代码如下:
df[‘num’] = [re.findall(r’(\d+.{0,1}\d*)', i)[0] for i in df[‘购买人数’]] # 提取数值
df[‘num’] = df[‘num’].astype(‘float’) # 转化数值型
提取单位(万)
df[‘unit’] = [‘’.join(re.findall(r’(万)', i)) for i in df[‘购买人数’]] # 提取单位(万)
df[‘unit’] = df[‘unit’].apply(lambda x:10000 if x==‘万’ else 1)
计算销量
df[‘销量’] = df[‘num’] * df[‘unit’]
删除没有发货地址的店铺数据 获取省份
df = df[df[‘地址’].notna()]
df[‘省份’] = df[‘地址’].str.split(’ ').apply(lambda x:x[0])
删除多余的列
df.drop([‘购买人数’, ‘地址’, ‘num’, ‘unit’], axis=1, inplace=True)
重置索引
df = df.reset_index(drop=True)
df.to_csv(‘月饼清洗数据.csv’)
至此我们就可以把爬取的月饼数据整理清洗完毕,如下图所示。
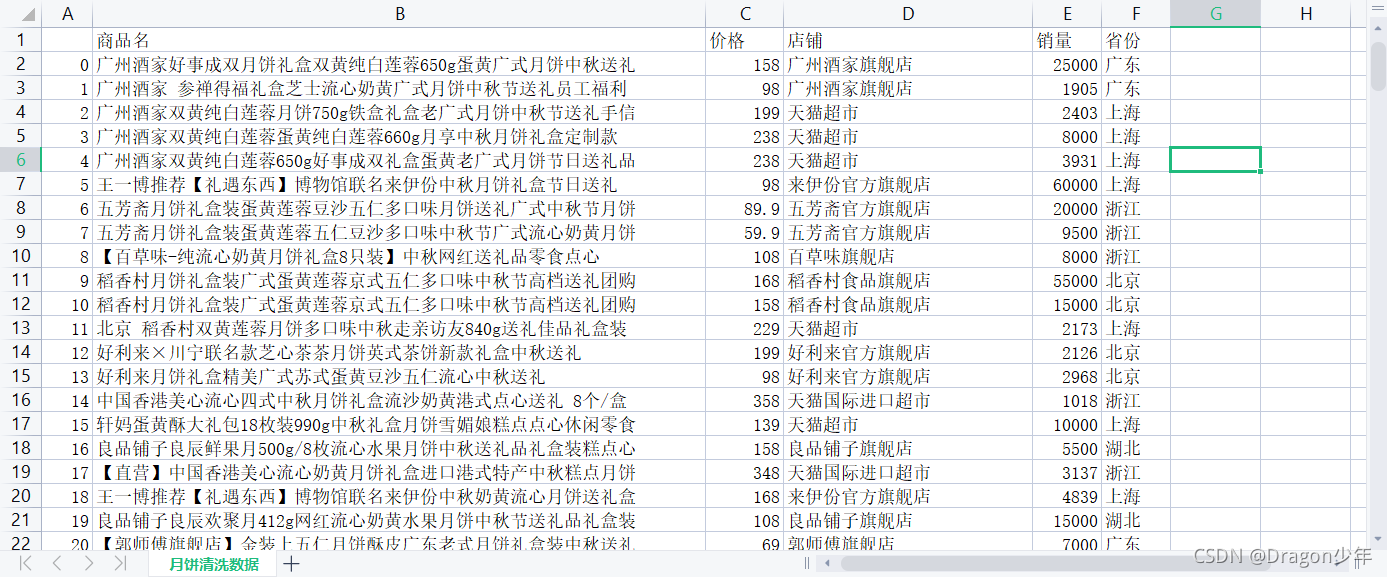
##### 3. 可视化分析
接下来我们就需要对数据进行可视化显示, 这里使用的是**pyecharts**,是一个用于生成Echarts图表的类库,便于在Python中根据数据生成可视化的图表。
之前博主有写过一篇关于pyecharts的文章,里面很详细的介绍了各类图表的使用方法和案例,不会的可以先去学习下pyecharts相关的内容。[【一文学会炫酷图表利器pyecharts】](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)
**销量Top10店铺:**
下面我们可以读取清洗结束的数据,通过对店铺分组获取各个店铺的月饼销量数据,统计出销量前十的店铺,通过柱状图显示。核心代码如下:
计算月饼总销量Top10的店铺
shop_top10 = df.groupby(‘店铺’)[‘销量’].sum().sort_values(ascending=False).head(10)
绘制柱形图
bar1 = Bar(init_opts=opts.InitOpts(width=‘600px’, height=‘450px’))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis(‘销量’, shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title=‘销量Top10店铺-Dragon少年’),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar1.render(“销量Top10店铺-Dragon少年.html”)
bar1.render_notebook()
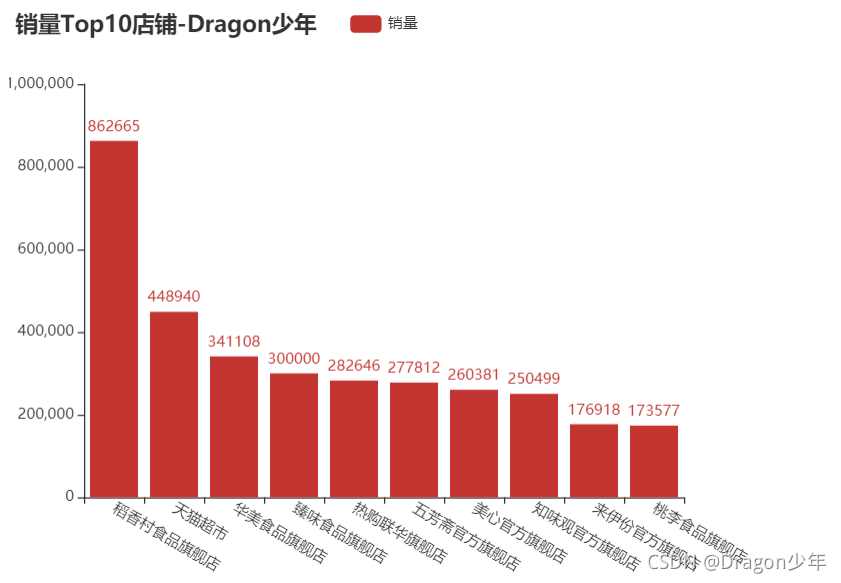
我们可以看到稻香村食品店、天猫超市、华美食品、臻味食品等销量居前,其中销量最好的是稻香村,总销量遥遥领先。
**销量Top10月饼:**
我们还可以通过对月饼名称进行月饼分组获取销量最好的月饼,统计出销量前十的月饼,通过柱状图显示。核心代码如下:
计算销量top10月饼
shop_top10 = df.groupby(‘商品名’)[‘销量’].sum().sort_values(ascending=False).head(10)
绘制柱形图
bar0 = Bar(init_opts=opts.InitOpts(width=‘750px’, height=‘450px’))
bar0.add_xaxis(shop_top10.index.tolist())
bar0.add_yaxis(‘销量’, shop_top10.values.tolist())
bar0.set_global_opts(title_opts=opts.TitleOpts(title=‘销量Top10月饼-Dragon少年’),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar0.render(“销量Top10月饼-Dragon少年.html”)
bar0.render_notebook()
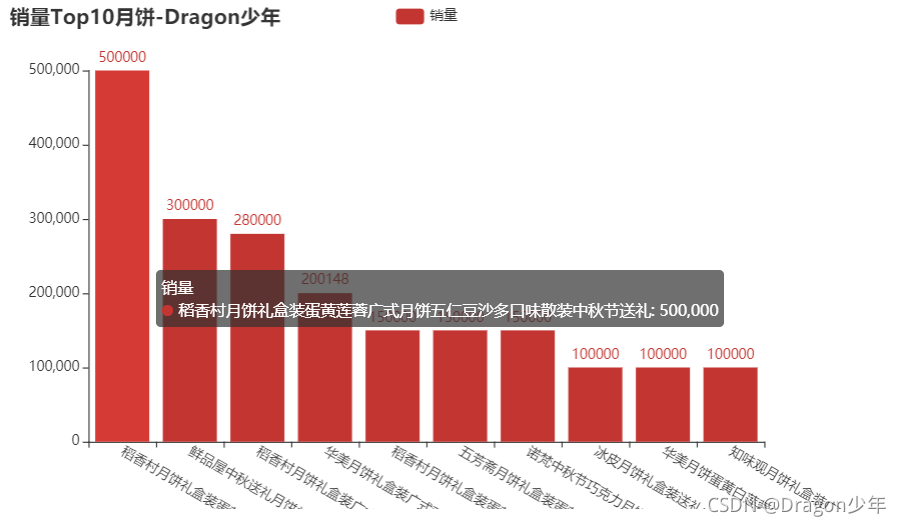
我们可以看到最受欢迎的10种月饼,其中的稻香村月饼礼盒装最受欢迎,销量达到了50w份。
**不同价格月饼销量占比:**
我们接下来还可以根据月饼的价格区间进行划分,统计50元以下,50-150元,150-500元,500元以上的各个价格区间月饼的销量分布,并通过饼图进行可视化显示。核心代码如下:
def price_range(x): #按照淘宝推荐划分价格区间
if x <= 50:
return ‘50元以下’
elif x <= 150:
return ‘50-150元’
elif x <= 500:
return ‘150-500元’
else:
return ‘500元以上’
df[‘price_range’] = df[‘价格’].apply(lambda x: price_range(x))
price_cut_num = df.groupby(‘price_range’)[‘销量’].sum()
data_pair = [list(z) for z in zip(price_cut_num.index, price_cut_num.values)]
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 9520
9520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









