







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文

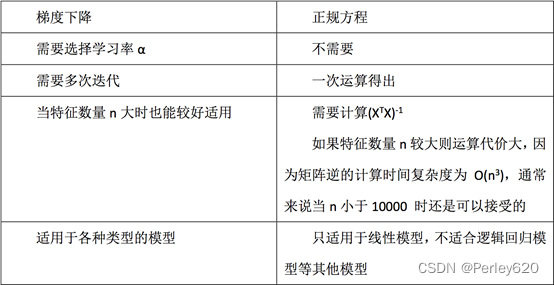
5.代码实现
正规方程:
sklearn.linear_model.LinearRegression()
梯度下降:
sklearn.linear_model.SGDRegressor()

5+.模型保存与加载
from sklearn.externals import joblib
保存训练好的模型
joblib.dump(lr, “./test.pkl”)
# 预测房价结果
model = joblib.load(“./test.pkl”)
y_predict = std_y.inverse_transform(model.predict(x_test))
print(“保存的模型预测的结果:”, y_predict)
6.特点
特点:线性回归器是最为简单、易用的回归模型。
- 从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
- 小规模数据:LinearRegression(不能解决拟合问题)以及其它大规模数据:SGDRegressor
实例:波士顿房价
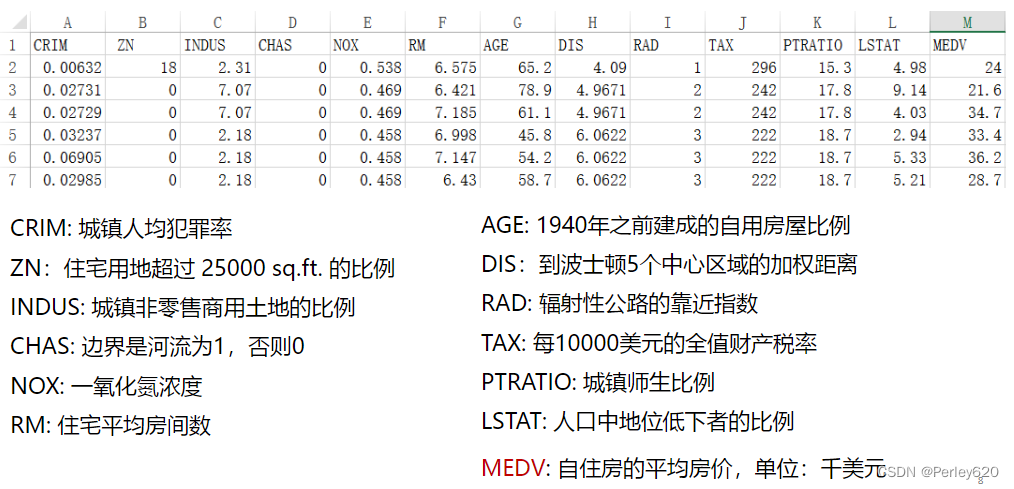

模型训练:
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, classification_report
import numpy as np
def myliner():
‘’’
线性回归直接预测房子价格
:return:None
‘’’
#分隔数据集
lb=load_boston()
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(x_train,x_test)
#标准化处理
特征工程(标准化)
std = StandardScaler()
对测试集和训练集的特征值进行标准化
目标值也需要标准化处理!!!!实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))#要求数据是二维数据
y_test = std_y.transform(y_test.reshape(-1,1))
###########################################
正规方程
lr = LinearRegression()
lr.fit(x_train, y_train)
print(“正规方程的回归系数”,lr.coef_)#得到的回归系数
保存训练好的模型
from sklearn.externals import joblib
joblib.dump(lr, “./test.pkl”)
预测测试集的房子价格#逆操作,逆标准化
y_lr_predict = std_y.inverse_transform(lr.predict(x_test)) # print(“正规方程测试集里面每个房子的预测价格:”, y_lr_predict)
print(“正规方程的均方误差:”, mean_squared_error(std_y.inverse_transform(y_test), y_lr_predict))
###############################
# #梯度下降
std_x1 = StandardScaler()
x_train1 = std_x1.fit_transform(x_train)
x_test1 = std_x1.transform(x_test)
目标值
std_y1 = StandardScaler()
y_train1 = std_y1.fit_transform(y_train.reshape(-1, 1)) # 要求数据是二维数据
y_test1 = std_y1.transform(y_test.reshape(-1, 1))
y_train = y_train1.astype(“int”)
x_train = x_train1.astype(“int”)
sgd = SGDClassifier()
sgd.fit(x_train, y_train)
print(“梯度下降得到的回归系数”,sgd.coef_) # 得到的回归系数
保存训练好的模型
from sklearn.externals import joblib
joblib.dump(sgd, “./test.pkl”)
预测测试集的房子价格
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test)) # 逆操作,逆标准化
print(“梯度下降测试集里面每个房子的预测价格:”, y_sgd_predict)
print(“梯度下降的均方误差:”, mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
if name == ‘__main__’:
myliner()
进行预测
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
加载boston数据
boston = load_boston()
X = boston[‘data’]
y = boston[‘target’]
names = boston[‘feature_names’]
将数据划分为训练集测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state=125)
建立线性回归模型
clf = LinearRegression().fit(X_train,y_train)
print(‘建立的LinearRegression模型为:’,‘\n’,clf)
预测训练集结果
y_pred = clf.predict(X_test)
print(‘预测前20个结果为:’,‘\n’,y_pred[:20])
代码 6-25
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams[‘font.sans-serif’] = ‘SimHei’
fig = plt.figure(figsize=(10,6)) ##设定空白画布,并制定大小
##用不同的颜色表示不同数据
plt.plot(range(y_test.shape[0]),y_test,color=“blue”, linewidth=1.5, linestyle=“-”)
plt.plot(range(y_test.shape[0]),y_pred,color=“red”, linewidth=1.5, linestyle=“-.”)
plt.legend([‘真实值’,‘预测值’])
#plt.savefig(‘…/tmp/聚类结果.png’)
plt.show() ##显示图片
【回归】带有L2正则化的岭回归


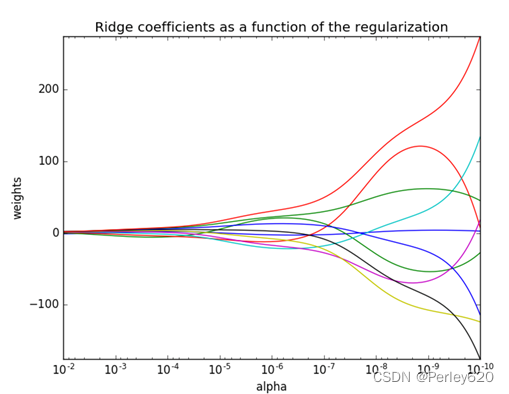 正则化系数越大,权重趋近于0,模型越来越简单。
正则化系数越大,权重趋近于0,模型越来越简单。
线性回归 LinearRegression与Ridge对比

from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, classification_report
from sklearn.externals import joblib
import pandas as pd
import numpy as np
def rd():
“”"
线性回归直接预测房子价格
:return: None
“”"
获取数据
lb = load_boston()
分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
进行标准化处理(?) 目标值处理?
特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1, 1))
y_test = std_y.transform(y_test.reshape(-1, 1))
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-rf3DK0AR-1713355416294)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









