







昨晚我做了一个梦,梦见我实现了这个功能,如下图所示:

功能简介:作对了,能打对号;做错了,能打叉号;没做的,能补上答案。
醒来后,我环顾四周,赶紧再躺下,希望梦还能接上。
二、实现步骤
基本思路
其实,搞定两点就成,第一是能识别数字,第二是能切分数字。
首先得能认识5是5,这是前提条件,其次是能找到5、6、7、8这些数字区域的位置。
前者是图像识别,后者是图像切割。
•对于图像识别,一般的套路是下面这样的(CNN卷积神经网络):

•对于图像切割,一般的套路是下面的这样(横向纵向投影法):

既然思路能走得通,那么咱们先搞图像识别。准备数据->训练数据并保存模型->使用训练模型预测结果。
2.1 准备数据
对于男友,找一个油嘴滑舌的花花公子,不如找一个闷葫芦IT男,亲手把他培养成你期望的样子。
咱们不用什么官方的mnist数据集,因为那是官方的,不是你的,你想要添加±×÷它也没有。
有些通用的数据集,虽然很强大,很方便,但是一旦放到你的场景中,效果一点也不如你的愿。
只有训练自己手里的数据,然后自己用起来才顺手。更重要的是,我们享受创造的过程。
假设,我们只给口算做识别,那么我们需要的图片数据有如下几类:
索引:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
字符:0 1 2 3 4 5 6 7 8 9 = + - × ÷
如果能识别这些,基本上能满足整数的加减乘除运算了。
好了,图片哪里来?!
是啊,图片哪里来?
吓得我差点从梦里醒来,500万都规划好该怎么花了,居然双色球还没有选号!
梦里,一个老者跟我说,图片要自己生成。我问他如何生成,他呵呵一笑,消失在迷雾中……
仔细一想,其实也不难,打字我们总会吧,生成数字无非就是用代码把字写在图片上。
字之所以能展示,主要是因为有字体的支撑。
如果你用的是windows系统,那么打开KaTeX parse error: Undefined control sequence: \Windows at position 3: C:\̲W̲i̲n̲d̲o̲w̲s̲\Fonts这个文件夹,你会发现好多字体。

我们写代码调用这些字体,然后把它打印到一张图片上,是不是就有数据了。
而且这些数据完全是由我们控制的,想多就多,想少就少,想数字、字母、汉字、符号都可以,今天你搞出来数字识别,也就相
当于你同时拥有了所有识别!想想还有点小激动呢!
看看,这就是打工和创业的区别。你用别人的数据相当于打工,你是不用操心,但是他给你什么你才有什么。自己造数据就相当
于创业,虽然前期辛苦,你可以完全自己把握节奏,需要就加上,没用就去掉。
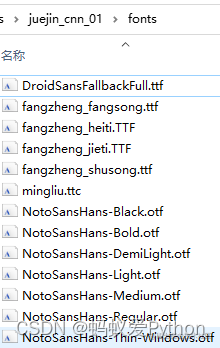
2.1.1 准备字体
建一个fonts文件夹,从字体库里拷一部分字体放进来,我这里是拷贝了13种字体文件。
好的,准备工作做好了,肯定很累吧,休息休息休息,一会儿再搞!
2.1.2 生成图片
代码如下,可以直接运行。
python学习交流Q群:906715085###
from __future__ import print_function
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
import os
import shutil
import time
# %% 要生成的文本
label_dict = {
0: '0', 1: '1', 2: '2', 3: '3', 4: '4', 5: '5', 6: '6', 7: '7', 8: '8', 9: '9', 10: '=', 11: '+', 12: '-', 13: '×', 14: '÷'}
# 文本对应的文件夹,给每一个分类建一个文件
for value,char in label_dict.items():
train_images_dir = "dataset"+"/"+str(value)
if os.path.isdir(train_images_dir):
shutil.rmtree(train_images_dir)
os.makedirs(train_images_dir)
# %% 生成图片
def makeImage(label_dict, font_path, width=24, height=24, rotate = 0):
# 从字典中取出键值对
for value,char in label_dict.items():
# 创建一个黑色背景的图片,大小是24\*24
img = Image.new("RGB", (width, height), "black")
draw = ImageDraw.Draw(img)
# 加载一种字体,字体大小是图片宽度的90%
font = ImageFont.truetype(font_path, int(width\*0.9))
# 获取字体的宽高
font_width, font_height = draw.textsize(char, font)
# 计算字体绘制的x,y坐标,主要是让文字画在图标中心
x = (width - font_width-font.getoffset(char)[0]) / 2
y = (height - font_height-font.getoffset(char)[1]) / 2
# 绘制图片,在那里画,画啥,什么颜色,什么字体
draw.text((x,y), char, (255, 255, 255), font)
# 设置图片倾斜角度
img = img.rotate(rotate)
# 命名文件保存,命名规则:dataset/编号/img-编号\_r-选择角度\_时间戳.png
time_value = int(round(time.time() \* 1000))
img_path = "dataset/{}/img-{}\_r-{}\_{}.png".format(value,value,rotate,time_value)
img.save(img_path)
# %% 存放字体的路径
font_dir = "./fonts"
for font_name in os.listdir(font_dir):
# 把每种字体都取出来,每种字体都生成一批图片
path_font_file = os.path.join(font_dir, font_name)
# 倾斜角度从-10到10度,每个角度都生成一批图片
for k in range(-10, 10, 1):
# 每个字符都生成图片
makeImage(label_dict, path_font_file, rotate = k)
上面纯代码不到30行,相信大家应该能看懂!看不懂不是我的读者。
核心代码就是画文字。
draw.text((x,y), char, (255, 255, 255), font)
翻译一下就是:使用某字体在黑底图片的(x,y)位置写白色的char符号。
核心逻辑就是三层循环。
如果代码你运行的没有问题,最终会生成如下结果:
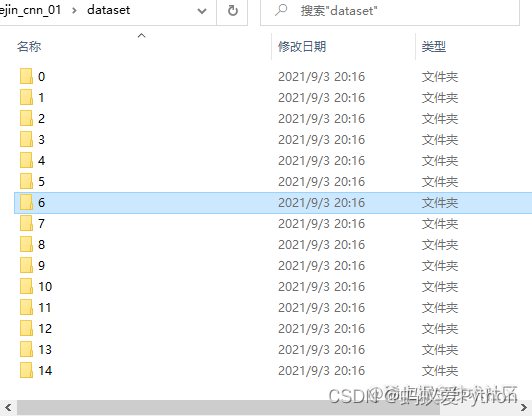
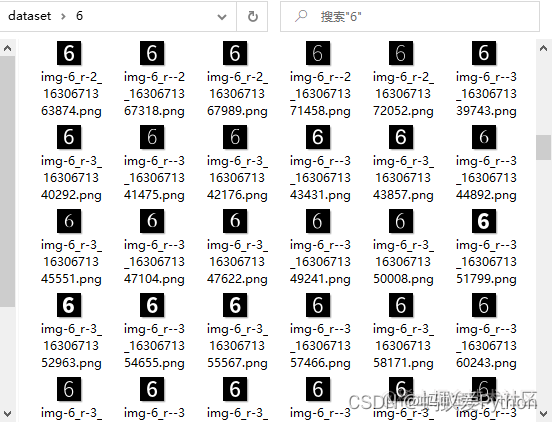
好了,数据准备好了。总共15个文件夹,每个文件夹下对应的各种字体各种倾斜角的字符图片3900个(字符15类×字体13种×角
度20个),图片的大小是24×24像素。
有了数据,我们就可以再进行下一步了,下一步是训练和使用数据。
2.2 训练数据
2.2.1 构建模型
你先看代码,外行感觉好深奥,内行偷偷地笑。
# %% 导入必要的包
import tensorflow as tf
import numpy as np
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import pathlib
import cv2
# %% 构建模型
def create\_model():
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(24, 24, 1)),
layers.Conv2D(24,3,activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64,3, activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(15)]
)
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
### 一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

### 二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

### 三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

### 四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

### 五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









