







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
}
最后`test.cpp`和`test.h`会合并在一起
(ps:一个工程中的test.h和上面test.cpp中两个N1会被合并成一个)
>
> 💥注意:一个命名空间就定义了一个新的作用域,**命名空间中的所有内容**都局限于该命名空间中
>
>
>
#### 🌈2.2 命名空间使用
命名空间中成员该如何使用呢?比如:
命名空间的使用有三种方式:
1. 💦加命名空间名称及作用域限定符: `名字`+`::`
int main()
{
printf(“%d\n”, N::a);
return 0;
}
* `::`前指定作用域,能很好的隔离
* 但是缺点也很明显,每个都要手动加上
2. 💦使用using将命名空间中某个**常用成员**引入
using N::b;
int main()
{
printf(“%d\n”, N::a);
printf(“%d\n”, b);
return 0;
}
* 指定展开项,比如`常用的项`,其他的不展开
3. 💦使用using namespace 命名空间名称 引入
using namespce N;
int main()
{
printf(“%d\n”, N::a);
printf(“%d\n”, b);
Add(10, 20);
return 0;
}
* 把整个命名空间**全部展开**,用起来方便
* 同时也展开到了全局,一句话:`自己用很爽,一起用不建议`
**🔥std命名空间的使用惯例:✅**
* 在**日常练习🎓**中,建议`直接using namespace std`即可,这样就很方便。
* 用using namespace std展开,标准库就全部暴露出来了。如果我们定义跟库重名的类型/对象/函数,就会存在冲突问题。然而这个问题在日常练习中很少出现,但是在代码较多、规模大的项目开发中就很容易出现。所以建议在**项目开发🤝中使用**`std::cout` 指定命名空间 + `using std::cout`展开常用的库对象/类型等方式。
### 🌍 3. C++输入&输出
C++是否也应该向这个美好的世界来声问候呢?我们来看下C++是如何来实现问候的

#include
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{
cout<<“Hello world!!!”<<endl;
return 0;
}
结果如下:👇🏻
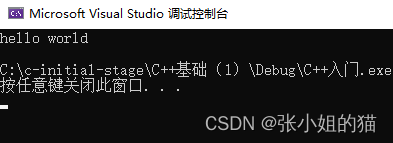
那么这两行代码究极是干嘛的呢?
说明:
* 使用**cout**标准输出对象(控制台)和**cin**标准输入对象(键盘)时,**c**代表**控制台**,必须包含`< iostream >头文件`以及按命名空间使用方法使用std。
* cout和cin是全局的流对象,`endl`是特殊的C++符号,**表示换行输出**,他们都包含在包含< iostream >头文件中。
* **`<<`是流插入运算符,`>>`是流提取运算符。**
* 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
举例子:
int main()
{
//特点:自动识别类型
int i;
double d;
// >> 流提取:提取数据放到i、d中 in代表提取、c代表控制台
cin >> i >> d;//
// << 流插入:提取到的数据插入到控制台里
cout << i << endl;
//cout << d << '\n'; //endl 代表换行 等价与“\n”
cout << d << endl;
//关于精度的c++太麻烦,c++可以兼任c的,所以还是可以用c的
return 0;
}
结果如下:👇🏻
>
> 
>
>
>
究竟是使用C还是cpp的输入输出方式,取决于哪个更加方便❓
🔥cout和cin也可以控制输出数据的精度、按照格式去输出进制格式等,但是实现起来比较复杂,主要是因为**C++兼容C语法**,这些用的又不是很多,就不展开学习了。后续如果有需要,再配合文档学习一下。
* 实际上cout和cin分别是ostream和istream类型的对象,`>>`和`<<`也涉及运算符重载等知识,这些知识我们我们**后续才会学习**,所以我们这里只是简单学习他们的使用。后面我们还有有一个章节更深入的学习IO流用法及原理。
>
> 注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此**推荐使用**`<iostream>+std`的方式。
>
>
>
### 🌍 4.缺省参数(备胎)
#### 🌈4.1 缺省参数概念
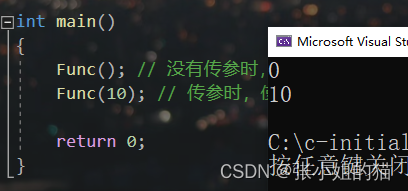
缺省参数是**声明或定义函数时**为函数的**参数指定一个缺省值**。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。(省流:没有实参就取缺省值)
#include
using namespace std;
void Func(int a = 0)
{
cout<<a<<endl;
}
int main()
{
Func(); // 没有传参时,使用参数的默认值
Func(10); // 传参时,使用指定的实参
return 0;
}
#### 🌈4.2 缺省参数分类
1.💦 全缺省参数
//全缺省参数
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
TestFunc();// 没有传参时,使用参数的默认值
TestFunc(1);//从左往右给,传给第1个参数,第2、3个参数缺省用默认值
TestFunc(1, 2); // 传参时,使用前两个指定的实参
TestFunc(1, 2, 3); //都使用指定实参
//TestFunc(,1);这样不可以,也没有为什么,因为语法是规定死的,我们只能学习,不能更改人家规定
return 0;
}
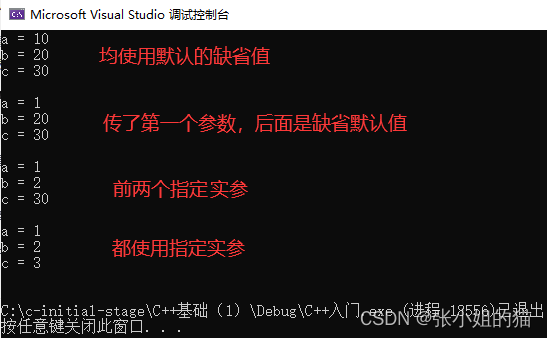
* 注意传值默认`从左向右依次给`,很多人会好奇为什么要这样,但是要注意的是我们是在学习别人的语法,在用别人规定好的东西,我们当然可以吐槽什么的,但是如果不想用这种语法,完全可以去开发一种语言比如**X语言**?
2. 💦半缺省参数
* 半缺省参数必须`从右往左依次`来给出,**不能间隔**着给,看下面的例子
//半缺省
void TestFunc(int a, int b = 10, int c = 20) //必须从右往左连续缺省,不能间隔
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl <<endl;
}
int main()
{
//要传的放在前边,爱传不传的放在后边
TestFunc(1);//这第一个参数必须传
TestFunc(1, 2);
TestFunc(1, 2, 3);
//不能这样TestFun(,1) 原因很简单,因为这不叫C++
return 0;
}

3.💦 缺省参数**不能**在函数声明和定义中**同时出现**,推荐放在声明里🔥 声明是大哥(好比不知道是妈妈当家说话还是爸爸当家说话一样哈哈哈)🔥
🍭举例:
#include<stdio.h>
#include<stdlib.h>
struct Stack
{
int* a;
int top;
int capacity;
};
//部分缺省
void StackInit(struct Stack* ps,int capacity = 4)
{
ps->a = (int*)malloc(sizeof(int)*capacity);
ps->top = 0;
ps->capacity = capacity;
}
int main()
{
struct Stack st;
StackInit(&st);//不知道栈最多存多少数据,就用缺省值初始化
StackInit(&st, 100);//知道我一定会插入100个数据,就可以显示传参数100,提前开好空间,插入数据避免扩容,这样可以减少增容次数,提高效率
return 0;
}
### 🌍 5.函数重载
>
> 自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。
> 比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前
> 者是“谁也赢不了!”,后者是“谁也赢不了!”
>
>
>
#### 🌈5.1 函数重载概念
**函数重载:**是函数的一种特殊情况,C++允许在**同一作用域中**声明几个功能类似的**同名函数**,这些同名函数的**形参列表(参数个数 或 类型 或 类型顺序)不同**,常用来处理实现功能类似数据类型不同的问题。
#include
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{
cout << “int Add(int left, int right)” << endl;
return left + right;
}
double Add(double left, double right)
{
cout << “double Add(double left, double right)” << endl;
return left + right;
}
// 2、参数个数不同
void f()
{
cout << “f()” << endl;
}
void f(int a)
{
cout << “f(int a)” << endl;
}
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << “f(int a,char b)” << endl;
}
void f(char b, int a)
{
cout << “f(char b, int a)” << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, ‘a’);
f(‘a’, 10);
return 0;
}
结果如下:👇🏻
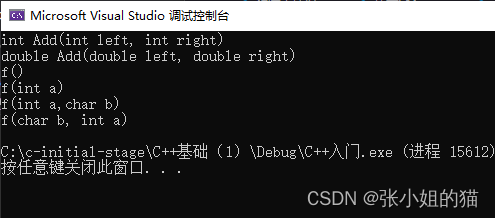
下面思考一下这两个函数支持冲载吗?👇🏻
short Add(short left, short right)
{
return left + right;
}
int Add(short left, short right)
{
return left + right;
}
答案:❌不能,函数重载和返回值不同没有关系❗ 是与参数的不同有关,这里不要搞混了哈
>
> 函数重载的意义就是让用的很方便,就像在用同一个函数一样
>
>
>
#### 🌈5.2 C++支持函数重载的原理–名字修饰(name Mangling)和extern “C”
这部分要单独写一篇文章,8月中更新,不鸽👻
### 🌍 6.引用
#### 🌈6.1 引用的概念
引用不是新定义一个变量,而是**给已存在变量**`取了一个别名`,编译器不会为引用变量开辟内存空间,它和它引用的变量**共用同一块内存空间**。
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。

**类型**`&` **引用变量名(对象名)** = 引用实体
void TestRef()
{
int a = 10;
int& ra = a;//<====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}
通过监视窗口我们可以看到—— **a和b的地址相同**
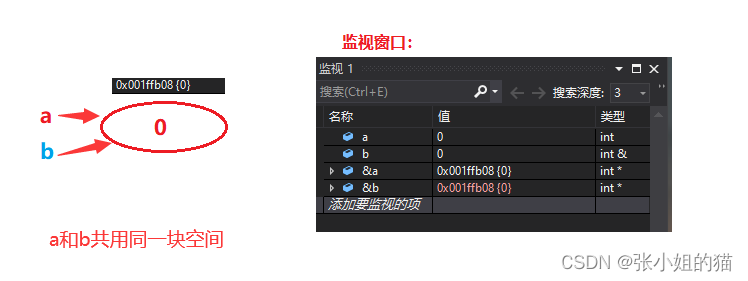所以我们知道原来引用只是`对原来的空间起了个“花名”`
>
> 注意:引用类型必须和引用实体是**同种类型的**
>
>
>
#### 🌈6.2 引用特性
1. 💦引用在定义时`必须初始化`
好比🍭:**你要给谁起别名,这个谁要先说戳来**
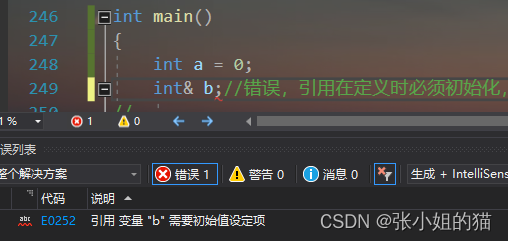
2. 💦 一个变量可以有`多个引用`
好比🍭:**一个人有多个外号**
int main()
{
// 一个变量可以有多个引用 —— 好比一个人可以有很多个外号一样
int a = 0;
int& b = a; //引用, 在类型和变量之间
int& c = a;
int& d = b;
}
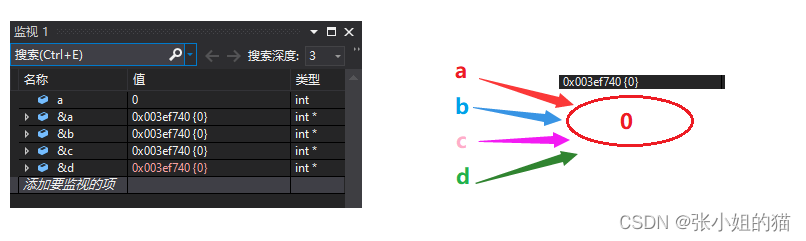
3. 💦引用一旦**引用一个实体**,**再不能引用其他实体**
好比🍭:引用是一个老实人,一旦和一个人结婚就一定终身了,但是指针可以解引用(可理解成离婚)所以指针就是一个渣男❗
思考👇🏻 b是x的别名呢? 还是x赋值给b呢?
int main()
{
int a = 10;
int& b = a;
int x = 20;
b = x;
return 0;
}
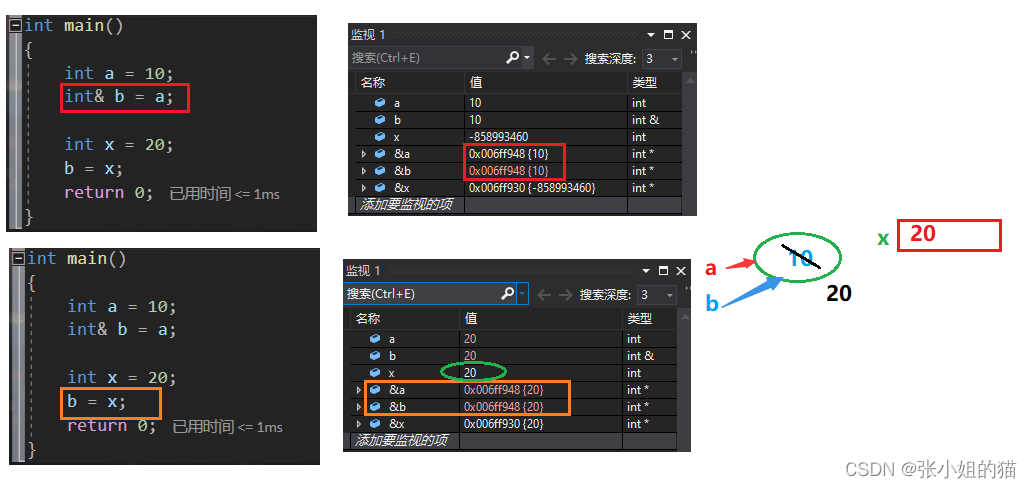
>
> 通过调试后看到,很明显是赋值了,地址都没改动
>
>
>
#### 🌈6.3 常引用
我们知道,const修饰**只读**,引用修饰**读和写**
const引用🌏
1. **权限扩大**❌
const int a = 10;//只读
int& b = a;//编译器报错 - 权限扩大 - int可读可写
2. **权限缩小** ✅
int c = 10;//可读可写
const int& d = c;//d是c的别名,缩小成只读 —— 权限缩小
3. **权限平移**✅
const int a = 10;
const int& b = a;//权限不变
接下来再看看这个例子⚡
int main()
{
int ii = 1;
double dd = ii;
//int& rdd = ii; //编译出错
const double& rdd = ii; //编译通过
return 0;
}
隐式类型转换会产生临时变量(**有常属性**相当于`const`)因为不能发生权限变大,引用要加上const
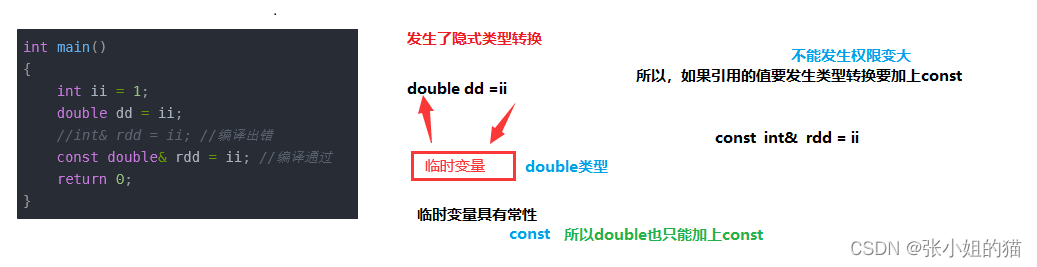
小小的总结:`const`有很强的接收度(**const type&**)——通吃,可以接收任意类型的对象
>
> ✨const的权限放大和缩小只在**指针和引用**奏效
>
>
>
因此,如果使用若函数中不改变参数n,那么建议使用`const &传参` 涉及到**权限不能放大的问题**
void fun2(const int& n)
#### 🌈6.4 使用场景
##### 💦1.做参数
void Swap(int& r1, int& r2)
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
int main()
{
int x = 10;
int y = 20;
//这里相当于把本身传了过去
Swap(x, y);//传引用
printf("a = %d,b = %d\n", x, y);
return 0;
}
上述的调用方法就是在**传引用**做输出型参数, **r1,r2就是x,y的别名**
这样不就是指针的用法吗?
我们举个例子🍭:
以SListPushBack这个函数为例`传引用`来改造一下,其中phead是plist的别名,改变phead就是在改变plist,这样就没有指针那样“**复杂**”

##### 💦2.做返回值
>
> 传值返回:**生成一个返回对象的copy作为函数调用的返回值**
>
>
>
我们平时见的最多的就是`传值返回`
特点:返回值是在函数栈桢销毁之前,`copy`一份放在临时变量中,所以**Count里的是n的拷贝**
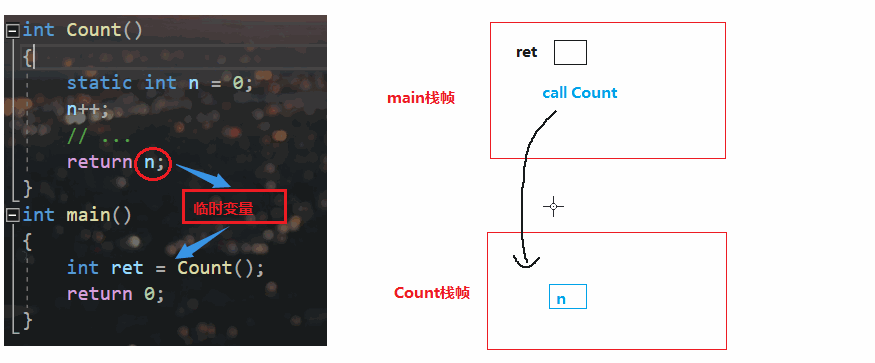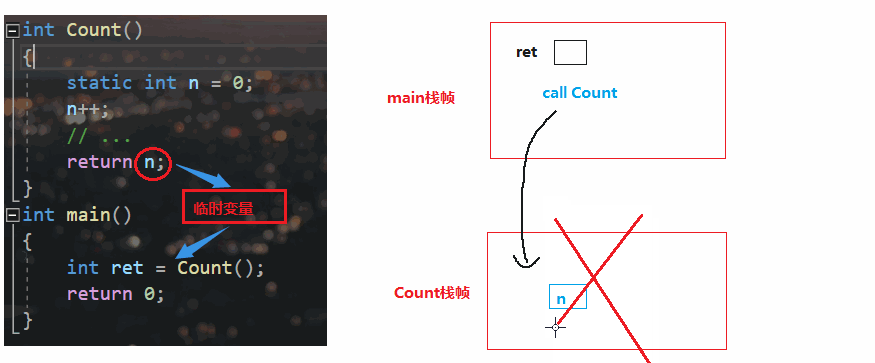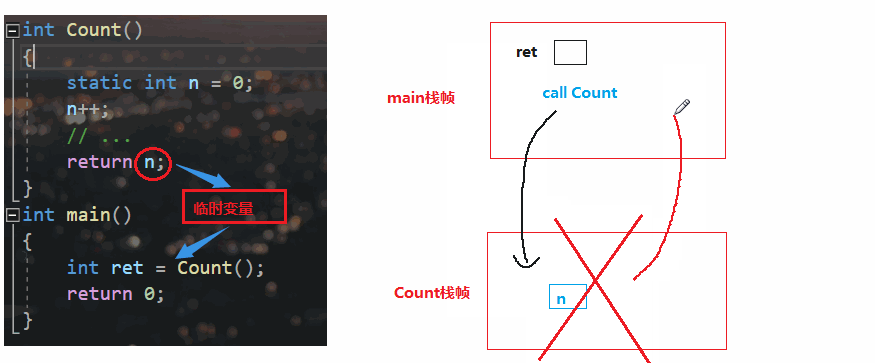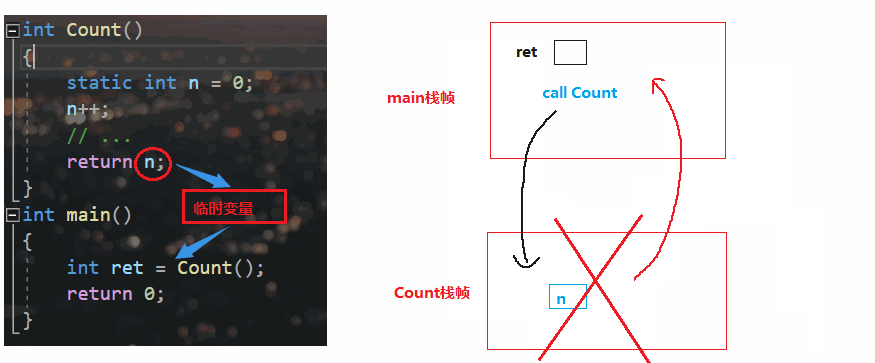
🔥如果是static ,变量就会被放在静态区、栈帧都在堆区,但是编译器没有这么聪明,他还是会copy一份
按照上面的动画演示来看,Count栈帧都已经销毁了,仍然取n的返回值,那如果n被清成随机值?很明显有问题
* 若n比较**小(4/8byte)**,一般是**寄存器**充当临时变量
* 若n比较大,临时变量存放在调用层函数(main)的栈桢中
>
> 传引用返回:**返回n(返回对象)的别名**
>
>
>
int& Count()
{
int n = 0;
n++;
// …
return n;
}
int main()
{
int ret = Count();
return 0;
}
**传引用返回**,return c; 即是返回c的引用,ret就是c的别名(引用)。
❌你看出来这段代码是有问题的了吗?因为引用返回的这种返回方式,并没有生成c的拷贝(引用这样减少拷贝[大对象 + 深拷贝对象],可以很好的提高性能),而是**直接返回c的引用**,作为ret的别名。然而**Add函数栈桢已经销毁**了,还回去访问c的空间,就发生了`非法访问(越界)`
但我们发现还是能正常打印,**越界就一定报错吗,犯罪一定会被抓吗?**
* 这种情况下,如果c空间没被覆盖,ret还能**侥幸**拿到所谓"正确"的值;如果清理了空间,ret拿到的就是`随机值`(取决于编译器)
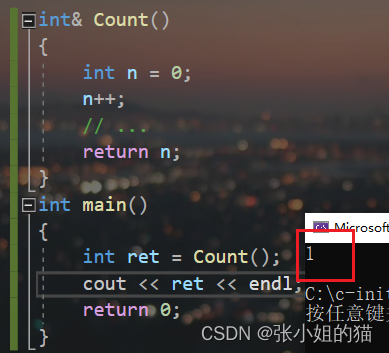
所以我们总结出一个结论❗:
* 🥗 如果函数返回值,出了作用域,如果**返回对象未还给系统**(全局变量),则可以`引用返回`;如果已经**还给系统了**(局部变量),则必须使`用传值返回`,不能返回局部变量的引用(随机值)
所以在日常中很少使用传引用返回,但是在类和对象中有大用途,后面慢慢讲
为此我们还可以把 n 置为全局变量 :`+static`
int& Count()
{
static int n = 0;//static
n++;
// …
return n;
}
int main()
{
int ret = Count();
cout << ret << endl;
return 0;
}
🍤例:我们改一个函数加深一下对传引用返回的好处
int& SLAt(SL& s, int pos)
{
assert(pos >= 0 && <= s.size);
return s.a[pos];
}
我们调用这个函数,销毁函数之后,`sl`的空间不会被销毁,因为**sl是malloc出来的**,所以是在`堆`上的

🍂总结:
1. 🍳前提:出了作用域,返回对象还在的
2. 使用场景
1️⃣做参数————🌏输出型参数 、✨大对象传参,提高效率
2️⃣做返回值————🌏输出型返回对象,调用者可以修改返回对象 ✨减少拷贝,提高效率
#### 🌈6.5 传值、传引用效率比较
以**值**作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份**临时的拷贝**,因此效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低,对比来看,**引用**可以提高能效
💦话不多说下面我们来测试一下:
#include <time.h>
//全局变量
struct A { int a[10000]; };
void TestFunc1(A a) {} //传值 ~ 生成拷贝
void TestFunc2(A& a) {}//引用别名
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << “TestFunc1(A)-time:” << end1 - begin1 << endl;
cout << “TestFunc2(A&)-time:” << end2 - begin2 << endl;
}
调用10000次的结果⚡
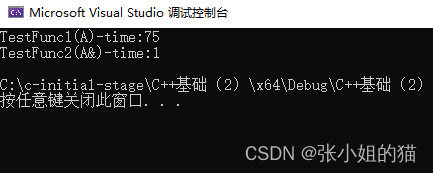
引用做参数如此,做返回值就不用我多说了吧
#### 🌈6.6 引用和指针的区别
以下的建议不要背,要去理解,理解透了看一眼就好⚡
1. 引用概念上定义一个变量的**别名**(**引用没开空间**)、指针存储一个变量地址。
2. 引用在**定义时必须初始化**,指针没有要求
3. 引用在初始化时引用一个实体后,就不**能再引用其他实体**,而指针可以在任何时候指向任何一个同类型实体
4. **没有NULL引用**,但有NULL指针
5. **在sizeof中含义不同**:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(占4个字节/ 8个字节)
6. 引用自加即引用的**实体增加1**,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是**没有多级引用**
8. 访问实体方式不同,指针需要显式解引用,**引用编译器自己处理**
9. **引用比指针使用起来相对更安全**
🥗了解一下即可,用的时候不要想底层实现
在**底层实现上**实际是有空间的,因为`引用是按照指针方式来实现的`
我们来看下引用和指针的汇编代码对比:
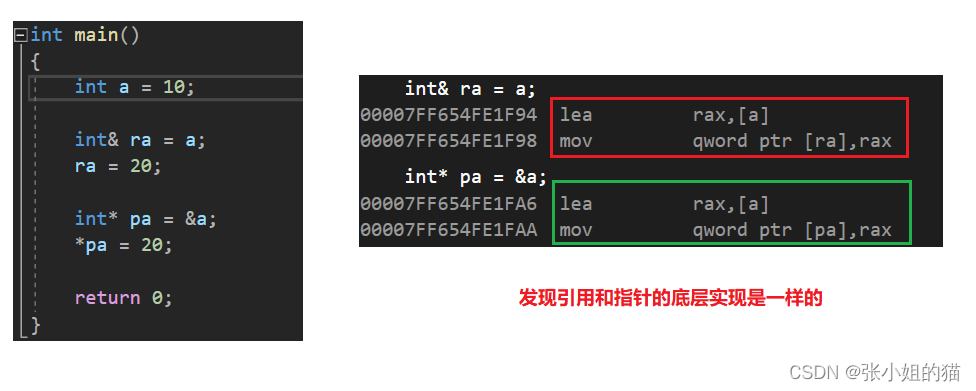
发现是引用和指针在底层实现是一样的,但语法上不一样

好比同一条流水线生产出来的鞋子,一种卖1000块钱,一种卖100块,但解刨来看居然是同一家厂商做出来的哈哈哈生动吧 这样就好理解了
### 🌍 7.内联函数
我们对于**短小的函数**(1~10行) 频繁的调用就要不断开创栈帧,这些都是有消耗的,那么我们怎么样优化呢?
💥C语言:宏 🔥C++:内联函数(inline)
我们知道C++是大佬觉得c语言写的不够好才创出了内联
接下来我们先回顾一下宏:
#define ADD(a,b) ((a)+(b))//要注意每一个括号的含义
int main()
{
cout << ADD(1, 2) << endl;
return 0;
}
//括号用的场景
// ADD(1, 2) * 3;// ((1)+(2))*3 外面的括号
// ADD(x | y, x & y);// ((x | y)+(x & y)) 里面的括号————运算符的优先级
**🎶优点**:增强代码的复用性、 提高性能。
**🎶缺点**:
1. 导致代码可读性差,可维护性差,容易误用。
2. 不方便调试宏。(因为预编译阶段进行了替换)
3. 没有类型安全的检查 。
那么我请来了宏的大哥
#### 🌈7.1 概念
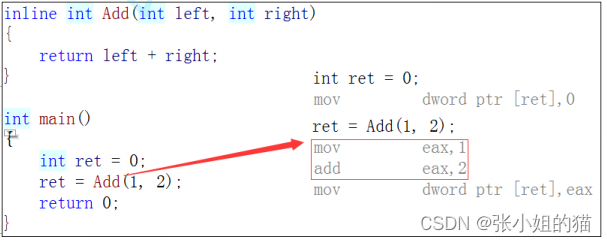
以**inline修饰**的函数叫做内联函数,**编译时**C++编译器会在**调用内联函数的地方展开**,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
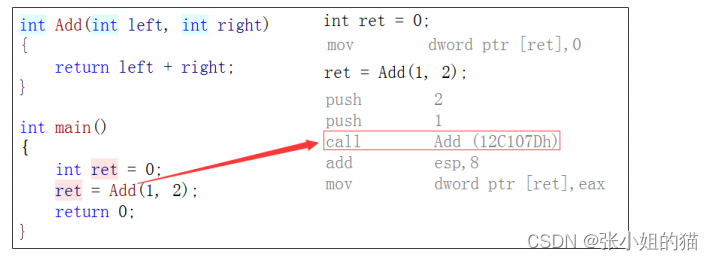
如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用
查看方式:
1. 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2013的设置方式)
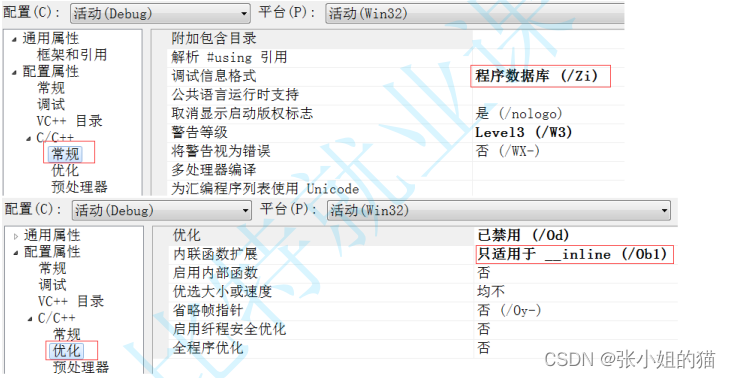
可以看见内联函数,没有调用而是**直接展开**
#### 🌈7.2 内联函数特性
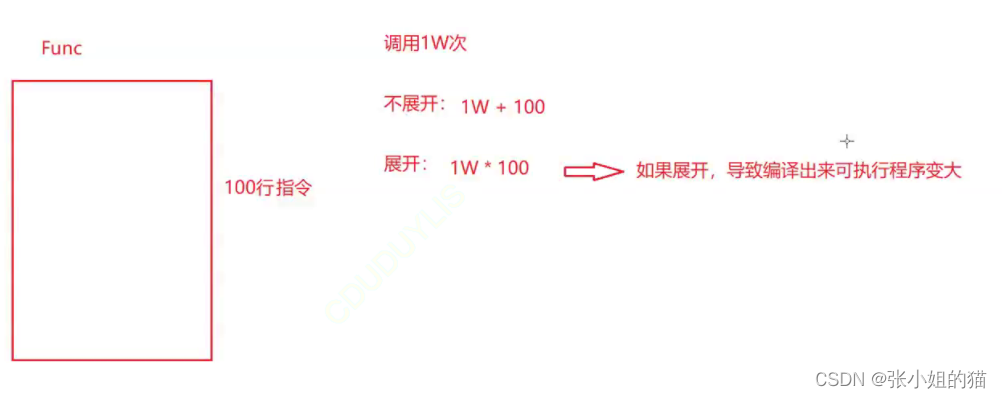
1. inline是一种以**空间换时间**的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率
2. inline对于编译器而言**只是一个建议**,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(**取决于编译器**内部实现)。如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。

3. inline**不建议声明和定义分离**,分离会导致**链接错误**。因为inline被展开,就没有函数地址了,链接就会找不到,一般建议`在定义中放内联`
// F.h
#include
using namespace std;
inline void f(int i);
// F.cpp
#include “F.h”
void f(int i)
{
cout << i << endl;
}
// main.cpp

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率

2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(取决于编译器内部实现)。如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。

3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到,一般建议在定义中放内联
// F.h
#include <iostream>
using namespace std;
inline void f(int i);
// F.cpp
#include "F.h"
void f(int i)
{
cout << i << endl;
}
// main.cpp
[外链图片转存中...(img-fTMnXHbd-1714912971297)]
[外链图片转存中...(img-7lv8E9Mr-1714912971298)]
[外链图片转存中...(img-Fcfi7xiZ-1714912971298)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









