







 本文介绍了如何使用Python的requests库和PyQuery模块爬取小说网站Qidian的热榜书籍,包括书名、序号和月票等数据,并提供了代码示例。
本文介绍了如何使用Python的requests库和PyQuery模块爬取小说网站Qidian的热榜书籍,包括书名、序号和月票等数据,并提供了代码示例。
import requests
from pyquery import PyQuery
起点网址:
-
电脑版:www.qidian.com
-
手机版:m.qidian.com
这里使用的是电脑版。
url = ‘https://www.qidian.com/’
请求头
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52’
}
html = requests.get(url=url, headers=headers)
html.encoding = ‘utf-8’ # utf-8 编码,否则会出现乱码
html = PyQuery(html.text)
找到热榜节点
ranks = html.find(‘div#rank-list-row.rank-list-row.cf.mb20 div.rank-list’).items()
books = dict()
遍历每一个热榜
for rank in ranks:
title = rank.find(‘h3 a.more’).siblings().text()
books[title] = list()
遍历热榜的书
lis = rank.find(‘div.book-list ul li’).items()
for li in lis:
排名第一的书是展开的,结构会稍有不同,我们找到我们需要的信息
if li.attr(‘class’) == ‘unfold’:
books[title].append([
li.attr(‘data-rid’), # 序号
li.find(‘h4’).text(), # 书名
li.find(‘p em’).text() # 月票
])
else:
books[title].append([
li.attr(‘data-rid’), # 序号
li.find(‘div.name-box a.name’).text(), # 书名
li.find(‘div.name-box i.total’).text() # 月票
])
遍历
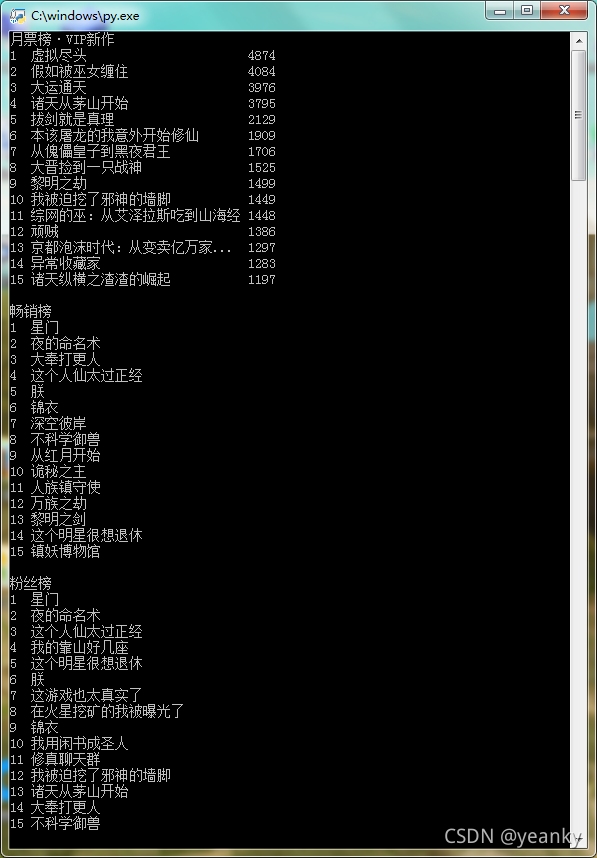
for key, values in books.items():
print(key) # 输出榜名
for rank, name, total in values:
如果长度超出,则省略13位以后的
if len(name.encode(‘GBK’)) > 30:
name = name[:13] + ‘…’
补全
name += ’ ’ * (30 - len(name.encode(‘GBK’)))
print(rank.ljust(2), name, total)
print() # 空一行
import requests
from pyquery import PyQuery
url = ‘https://www.qidian.com/’
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52’
}
主函数
def main():
html = requests.get(url=url, headers=headers)
html.encoding = ‘utf-8’
html = PyQuery(html.text)
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









