







本文已收录至《全国计算机等级考试——信息 安全技术》专栏
哈希函数,也称为散列函数
或杂凑函数,指将哈希表中元素的关键键值映射为元素存储位置的函数。是一种将任意长度的数据映射到固定长度输出的函数。哈希函数的特点包括压缩性,即输入数据的空间通常远大于输出哈希值的空间;单向性,即从哈希值难以反向推导出原始输入数据;碰撞抵抗性,即难以找到两个不同的输入产生相同的哈希值。
一般的线性表记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数。 理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。
哈希函数在计算机科学中有多种应用,包括但不限于数据完整性验证、单项数据加密、数字签名等。例如,在数据完整性验证中,通过哈希函数生成的数据或文件的哈希值,可以在后续验证时与原始哈希值进行比较,以检测数据是否被篡改;在单向数据加密中,哈希函数用于存储用户密码的哈希值,并在验证时比较用户输入的密码哈希值与存储的哈希值;在数字签名中,哈希函数用于生成只有发送者知道的信息的唯一标识,接收者可以通过这个标识来验证信息的完整性和来源。
在实际应用中,人们经常使用各种密码学安全的哈希函数,如SHA-256、MD5和SHA-1
等。这些哈希函数不仅具有上述通用特性,还经过了特殊设计以提供额外的安全性。例如,SHA-256可以生成256比特的哈希值,其安全性基于目前计算能力下的碰撞抵抗性。然而,需要注意的是,某些哈希函数(如MD5和SHA-1)已经因为安全性问题而被建议不再使用。
哈希表的概念及作用
哈希表中元素是由哈希函数确定的。将数据元素的关键字K作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址。表示为:
Addr = H(key)
为此在建立一个哈希表之前需要解决两个主要问题:
⑴构造一个合适的哈希函数
均匀性 H(key)的值均匀分布在哈希表中;
简单 以提高地址计算的速度
⑵冲突的处理
冲突:在哈希表中,不同的关键字值对应到同一个存储位置的现象。即关键字K1≠K2,但H(K1)= H(K2)。均匀的哈希函数可以减少冲突,但不能避免冲突。发生冲突后,必须解决;也即必须寻找下一个可用地址。
解决冲突的方法
⑴链接法(拉链法)。将具有同一散列地址的记录存储在一条线性链表中。例,除留余数法中,设关键字为 (18,14,01,68,27,55,79),除数为13。散列地址为 (5,1,1,3,1,3,1),哈希散列表如图。
⑵开放定址法。如果h(k)已经被占用,按如下序列探查:(h(k)+p⑴)%TSize,(h(k)+p⑵)%TSize,…,(h(k)+p(i))%TSize,…
其中,h(k)为哈希函数,TSize为哈希表长,p(i)为探查函数。在 h(k)+p(i-1))%TSize的基础上,若发现冲突,则使用增量 p(i) 进行新的探测,直至无冲突出现为止。其中,根据探查函数p(i)的不同,开放定址法又分为线性探查法(p(i) = i : 1,2,3,…),二次探查法(p(i)=(-1)^(i-1)*((i+1)/2)^2,探查序列依次为:1, -1,4, -4, 9 …),随机探查法(p(i): 随机数),双散列函数法(双散列函数h(key) ,hp (key)若h(key)出现冲突,则再使用hp (key)求取散列地址。探查序列为:h(k),h(k)+ hp(k),…,h(k)+ i*hp(k))。
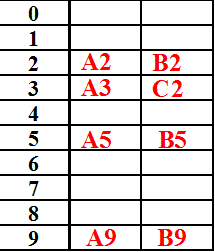
⑶桶定址法。桶:一片足够大的存储空间。桶定址:为表中的每个地址关联一个桶。如果桶已经满了,可以使用开放定址法来处理。例如,插入A5,A2,A3,B5,A9,B2,B9,C2,采用线性探查法解决冲突。
哈希表的构造方法
直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
数字分析法
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
平方取中法
取关键字平方后的中间几位为哈希地址。
折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。
除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key),其中random为随机函数。通常用于关键字长度不等时采用此法。
若已知哈希函数及冲突处理方法,哈希表的建立步骤如下:
步骤1:取出一个数据元素的关键字key,计算其在哈希表中的存储地址D=H(key)。若存储地址为D的存储空间还没有被占用,则将该数据元素存入;否则发生冲突,执行步骤2。
步骤2:根据规定的冲突处理方法,计算关键字为key的数据元素之下一个存储地址。若该存储地址的存储空间没有被占用,则存入;否则继续执行步骤2直到找出一个存储空间没有被占用的存储地址为止。
冲突
无论哈希函数设计有多么精细,都会产生冲突现象,也就是2个关键字处理函数的结果映射在了同一位置上,因此,有一些方法可以避免冲突。
拉链法
拉出一个动态链表代替静态顺序存储结构,可以避免哈希函数的冲突,不过缺点就是链表的设计过于麻烦,增加了编程复杂度。此法可以完全避免哈希函数的冲突。
多哈希法
设计二种甚至多种哈希函数,可以避免冲突,但是冲突几率还是有的,函数设计的越好或越多都可以将几率降到最低(除非人品太差,否则几乎不可能冲突)。
开放地址法
开放地址法有一个公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。
建域法
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。















 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









