







之前的博客已经对Redis的大致内容做了一个总结,但依然有很多没有提及的部分。在这里将做面试题总结,将那些没有提到的内容做一个补充,对已有内容总结成一个面试时可用的腹稿。
1.关于项目中,哪些场景使用了redis呢?
-
缓存:缓存三兄弟(穿透、击穿、雪崩)、双写一致、持久化、数据过期策略,数据淘汰策略
-
分布式锁setnx、redisson
-
消息队列、延迟队列何种数据类型
缓存三剑客
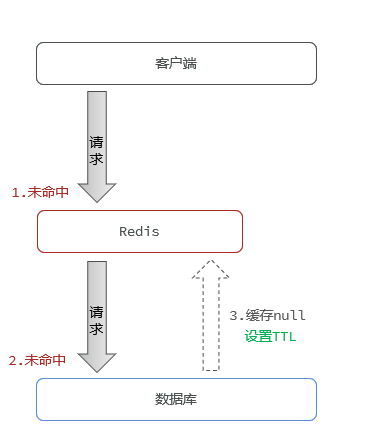
2.什么是缓存穿透?怎么解决?
-
缓存穿透是指查询一个一定不存在的数据,由于DB查不到数据因此不写入缓存,这将导致每次都查到DB。
-
解决方案的话:
-
缓存空值(如
null)并设置短期 过期时间(TTL) -
布隆过滤器拦截
-
在 API 入口处判断求请求参数是否合理
-
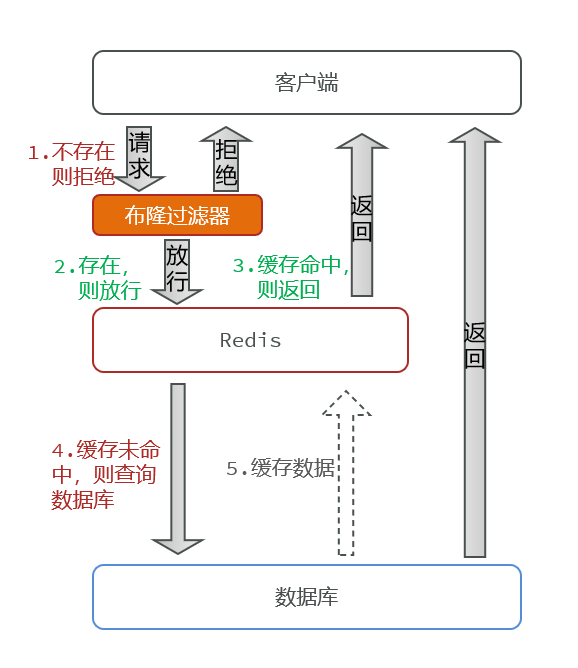
3.展开讲一下布隆过滤器
使用过程:使用Redisson实现,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在:将数据源中所有有效 Key(如用户 ID、商品 ID)提前存入布隆过滤器,请求先过过滤器,无效 Key 直接拦截(注意:布隆过滤器有小概率误判,需配合空值缓存兜底)。我用的是Redisson实现
原理:先初始化一个比较大的数组,里面存放的是二进制0或1表示存在与否。用多个哈希函数计算把元素映射到位数组上,通过位置是否全为1来判断存在性,以空间换取查询速度。
布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%。其实这个误判是必然存在的,要不就得增加数组的长度。5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
4.什么是缓存击穿?怎么解决?
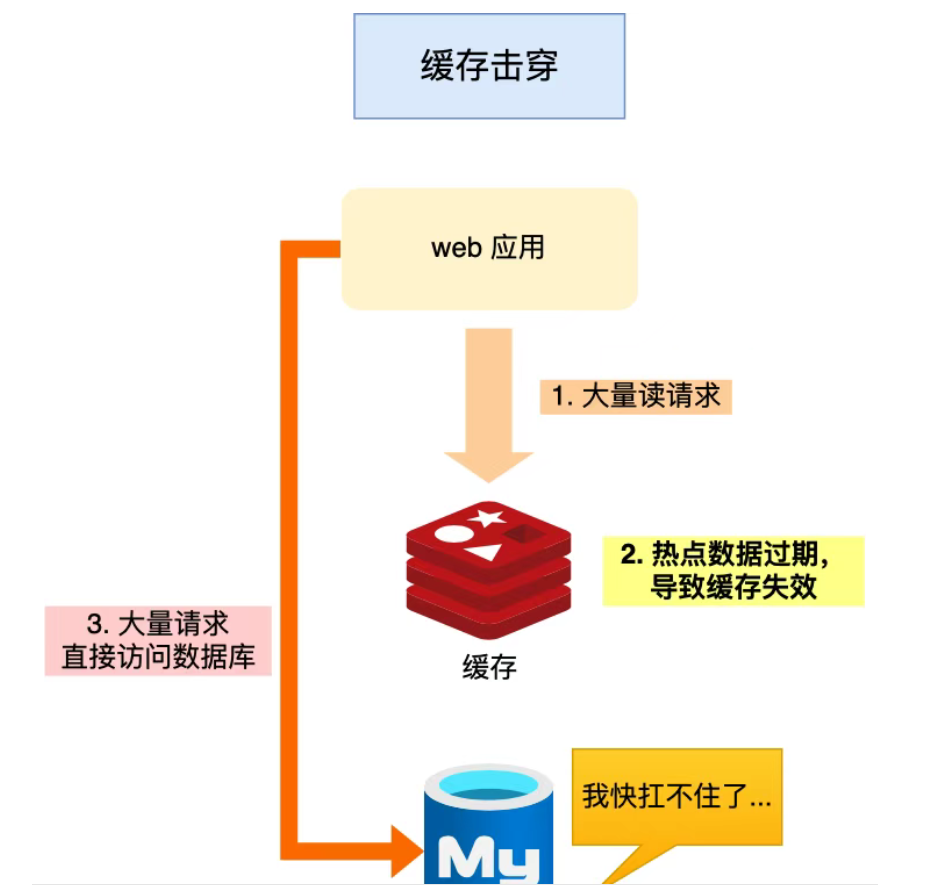
-
某个热点数据刚好过期,此时大量请求同时访问该 key,导致大量请求穿透缓存,打爆数据库
-
解决办法:
-
互斥锁(分布式锁):当缓存未命中,先尝试加锁,只有一个线程能去数据库加载,其它线程等待。锁释放后再从缓存中读取。(如用 Redis 的
SET NX实现锁); -
逻辑过期 + 异步更新: 存缓存时存一个TTL,查缓存时判断过期时间,如果未过期直接返回;如果已过期,先尝试加锁,成功则异步刷新缓存并返回旧数据,失败则直接返回旧数据等待后台线程更新。这样避免了缓存击穿,同时相比Redis TTL更灵活可控。
-
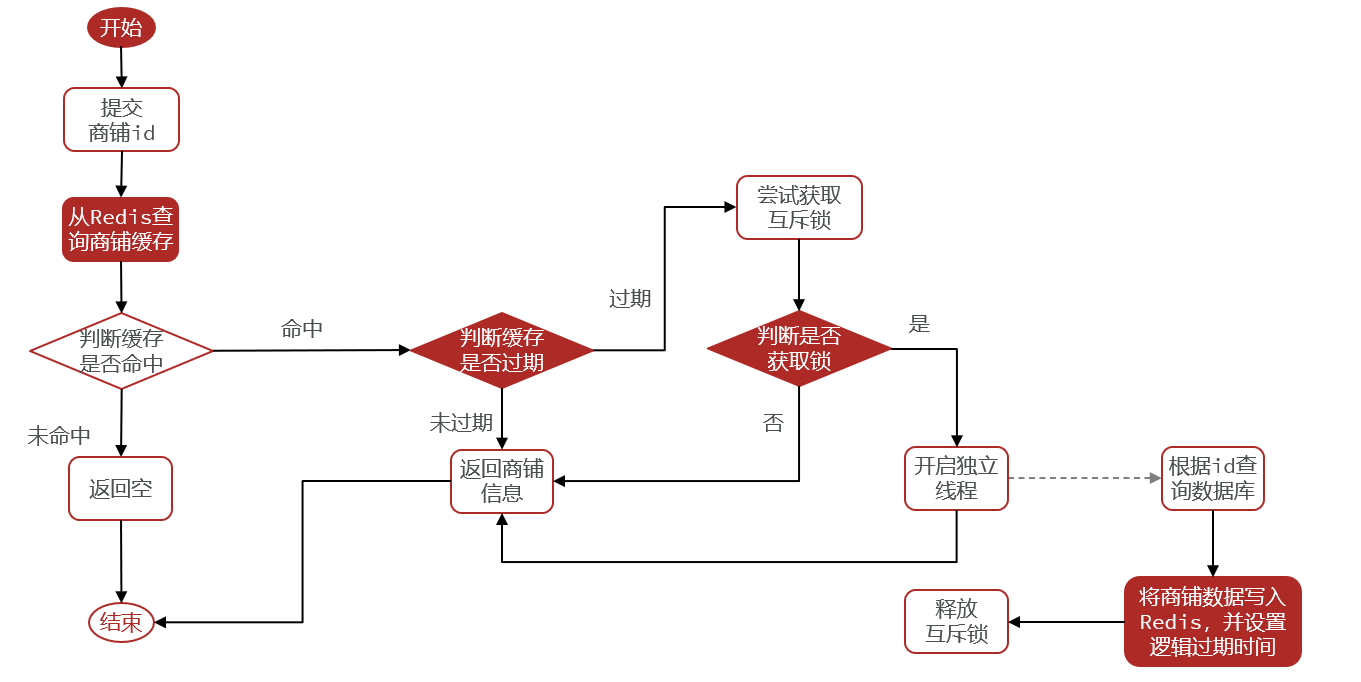
5.什么是缓存雪崩?怎么解决?
在同一时间大量缓存key同时失效或者Redis服务宕机,导致所有请求都打到数据库,引起数据库压力剧增,甚至崩溃,系统整体不可用。
解决方案:
-
将缓存失效时间随机打散: 在失效时间基础上增加一个随机值或者让过期时间错开分布,逐步过期,不集中失效
-
使用逻辑过期 + 异步缓存重建:手动控制过期时间, 不让热点 key 自行过期,如果判断逻辑时间已过期,先返回旧数据,再异步重建缓存(防止请求打爆数据库),从而避免因为缓存失效造成的缓存雪崩
-
👉 这是黑马点评中解决热点缓存一致性的关键方案。
-
双写一致性——互斥锁
6.redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
需要让数据库与redis高度保持一致,因为要求时效性比较高。
我采用的读写锁保证的强一致性。我使用的是Redisson实现的读写锁。在读的时候添加共享锁,可以保证读读不互斥、读写互斥。当我们更新数据的时候,添加排他锁。它是读写、读读都互斥,这样就能保证在写数据的同时,是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是,读方法和写方法上需要使用同一把锁才行。
7.那这个排他锁是如何保证读写、读读互斥的呢?
其实排他锁底层使用的也是SETNX,SETNX(SET if Not eXists) 原子操作,加锁时要带NX参数(0或1),保证同一时间只有一个线程能获取锁;。
8.你听说过延时双删吗?为什么不用它呢?
延时双删指的是:
-
先删一次 Redis 缓存;
-
更新 MySQL;
-
延迟一小段时间,再删一次缓存(防止并发下旧数据回写到缓存)。
延时双删本质是用延迟第二次删除来降低并发下脏数据回写的概率,但它不能彻底保证一致性,延迟时间不好选,过短无效、过长影响性能;而且高并发下依然可能出现竞争导致脏数据,延迟删除还会引入额外的复杂度和不确定性。所以生产环境更多用异步消息、订阅binlog或逻辑过期等方案来保证最终一致性。
redis持久化
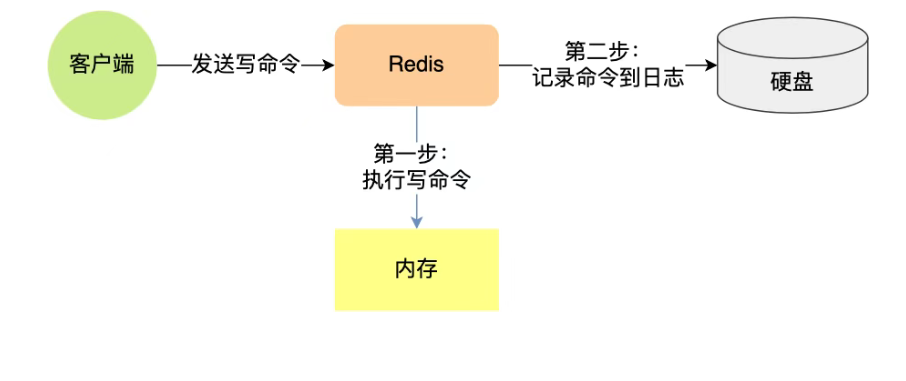
9.redis做为缓存,数据的持久化是怎么做的?
在Redis中提供了两种数据持久化的方式: RDB , AOF。
-
RDB(快照式):Redis 会在某些时机fork 出一个子进程,将当前内存中的数据生成快照,写入
.rdb文件,RDB 快照记录的是实际数据。 -
AOF(追加式) :将数据库操作命令,以追加的方式记录到 AOF 文件中,恢复时重写。
10.这两种方式,哪种恢复的比较快呢?
RDB快
-
RDB因为是二进制文件,保存时体积也比较小,所以它恢复得比较快。但它有可能会丢数据。
-
我们通常在项目中也会使用AOF来恢复数据。虽然AOF恢复的速度慢一些,但它丢数据的风险要小很多。在AOF文件中可以设置刷盘策略。我们当时设置的就是每秒批量写入一次命令。
过期策略
11.Redis的数据过期策略有哪些?
在redis中提供了两种数据过期删除策略。
-
惰性删除:只有当请求查询某个 key 时,才检查它是否过期,过期则删除。
-
优点是节省 CPU,缺点是可能内存中堆积大量过期 key。
-
-
定期删除:Redis 每隔一段时间(默认 100ms)随机抽查部分过期 key 并删除。
-
优点是平衡 CPU 和内存,缺点是可能有少量过期 key 未及时删除。
-
淘汰策略
12.Redis的数据淘汰策略有哪些?
这个在redis中提供了很多种,默认是noeviction,不删除任何数据,内部不足时直接报错。
这个可以在redis的配置文件中进行设置。里面有两个非常重要的概念:
-
一个是LRU,淘汰「最近最少使用」的 key(适合热点数据场景,如商品详情)。
-
另外一个是LFU,淘汰「最近访问频率最低」的 key(适合长期有访问但频率不均的场景,如用户登录记录)。
|
策略名 |
含义 |
说明 |
|---|---|---|
|
noeviction |
不删除,直接报错 |
默认策略,写入失败 |
|
allkeys-lru |
所有键中淘汰最近最少使用 |
智能 |
|
allkeys-lfu |
所有键中淘汰使用频率最低的 |
更先进的推荐策略 |
|
allkeys-random |
所有键中随机淘汰 |
简单快速 |
|
volatile-lru |
仅 TTL 键中 LRU 淘汰 |
有 TTL 控制 |
|
volatile-lfu |
仅 TTL 键中 LFU 淘汰 |
类似上面 |
|
volatile-random |
仅 TTL 键中随机淘汰 |
比较极端 |
|
volatile-ttl |
淘汰 TTL 时间最短的 |
优先过期键 |
13.数据库有1000万数据,Redis只能缓存20w数据。如何保证Redis中的数据都是热点数据?
嗯,我想一下,可以使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略。那留下来的都是经常访问的热点数据。
14.Redis的内存用完了会发生什么?
不同的redis数据淘汰策略情况式不一样的。默认是noeviction,,redis内存用完以后则直接报错。我当时设置的是allkeys-lru策略,把最近最常访问的数据留在缓存中。
分布式锁
15.Redis分布式锁如何实现?
用 SET NX PX 实现加锁,NX 保证只有 key 不存在时才能成功(互斥),UUID 标识锁归属,Lua 脚本原子解锁,并控制过期时间防死锁,必要时配合自动续期。
16.那你如何控制Redis实现分布式锁的有效时长呢?
redis的SETNX指令不好控制这个问题。我当时采用的是redis的Redisson框架实现的。
在Redisson中需要手动加锁,并且可以控制锁的失效时间和等待时间。当锁住的一个业务还没有执行完成的时候,Redisson会引入一个看门狗机制。就是说,每隔一段时间就检查当前业务是否还持有锁。如果持有,就增加加锁的持有时间。当业务执行完成之后,需要使用释放锁就可以了。还有一个好处就是,在高并发下,一个业务有可能会执行很快。客户1持有锁的时候,客户2来了以后并不会马上被拒绝。它会自旋不断尝试获取锁。如果客户1释放之后,客户2就可以马上持有锁,性能也得到了提升。
触发看门狗机制非常简单,当你调用 Redisson 的 lock() 方法并不传入过期时间时,会自动触发看门狗机制
触发该机制Redisson 会:
-
默认加锁 30 秒;
-
创建一个后台守护线程(看门狗线程);
-
每隔 10 秒 自动将锁的过期时间 重置为 30 秒;
-
持续续期,直到你
unlock()释放锁。
17.Redisson实现的分布式锁是可重入的吗?
是可以重入的。这样做是为了避免死锁的产生。Redisson 提供的RLock 是 基于 Redis 的 Hash 结构 实现的可重入锁
那么底层实现原理就可以通过判断次数来解决重入问题:
🔁 加锁流程:
-
客户端生成唯一标识(UUID + 线程ID);
-
使用 Lua 脚本判断锁是否存在;
-
如果是同一个线程,则只 自增重入次数,并刷新过期时间;
-
否则尝试抢锁。
🧹 解锁流程:
-
判断锁是否是当前线程加的;
-
如果是,减少重入次数;
-
如果次数为 0,删除 key,释放锁;
-
否则只是更新剩余次数。
18.Redisson实现的分布式锁能解决主从一致性的问题吗?
并没有完全解决,项目中提到的办法是使用Redisson 的 multiLock(多锁)机制,它通过在多个独立 Redis 节点上加锁,绕开主从同步问题,避免因主从延迟造成“锁丢失”或“误释放”。
这个是不能的。比如,当线程1加锁成功后,master节点数据会异步复制到slave节点,此时如果当前持有Redis锁的master节点宕机,slave节点被提升为新的master节点,假如现在来了一个线程2,再次加锁,会在新的master节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用Redisson提供的红锁来解决这个问题,RedLock 使用多个 完全独立的 Redis 实例(推荐 5 个) 来保证分布式锁的一致性。它并非依赖 Redis 的主从架构,而是多个主节点构成的“集群”。
-
客户端使用唯一值尝试依次向多个 Redis 实例发起加锁操作同时客户端获取【当前时间T1】
-
如果客户端从大多数(如 5 个节点中至少 3 个)以上Redis实例加锁成功,则再次获取【当前时间戳T2】, 如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则加锁失败
-
加锁成功,去操作共享资源
-
加锁失败,向【全部节点】发起释放锁请求
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变得非常低,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁。
19.如果业务非要保证数据的强一致性,这个该怎么解决呢?
Redis本身就是支持高可用的,要做到强一致性,就非常影响性能,所以,如果有强一致性要求高的业务,建议使用ZooKeeper实现的分布式锁,它是可以保证强一致性的。
redis集群
20.Redis集群有哪些方案,知道吗?
在Redis中提供的集群方案总共有三种:主从复制、哨兵模式、Redis分片集群。
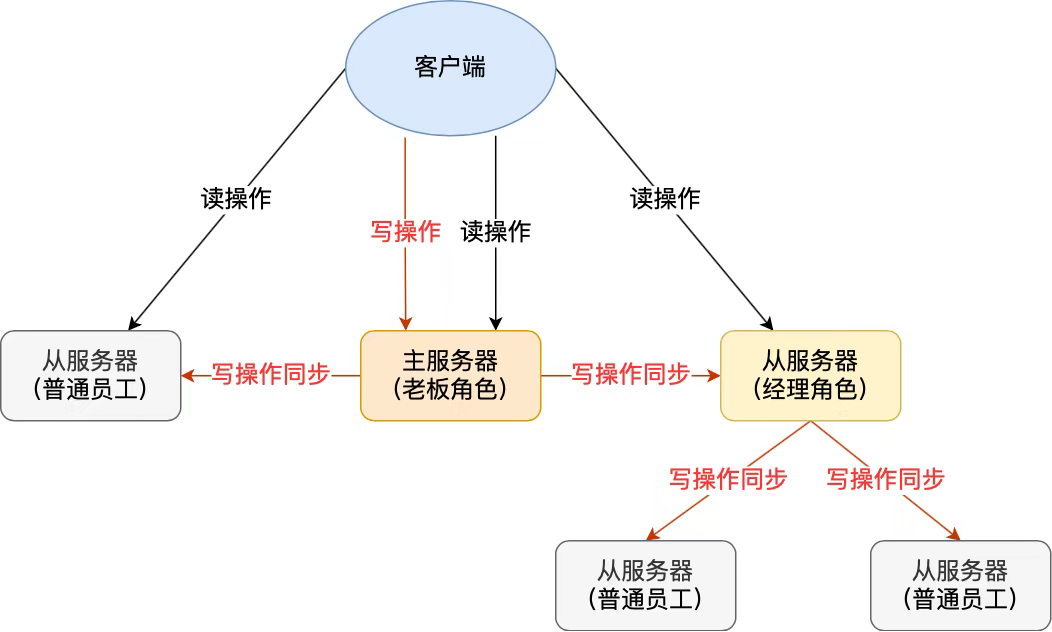
21.那你来介绍一下主从同步
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一个主节点(Master)处理写操作,多个从节点(Slave)通过复制主节点数据承担读操作,数据异步同步。从节点通过复制保持与主节点一致。
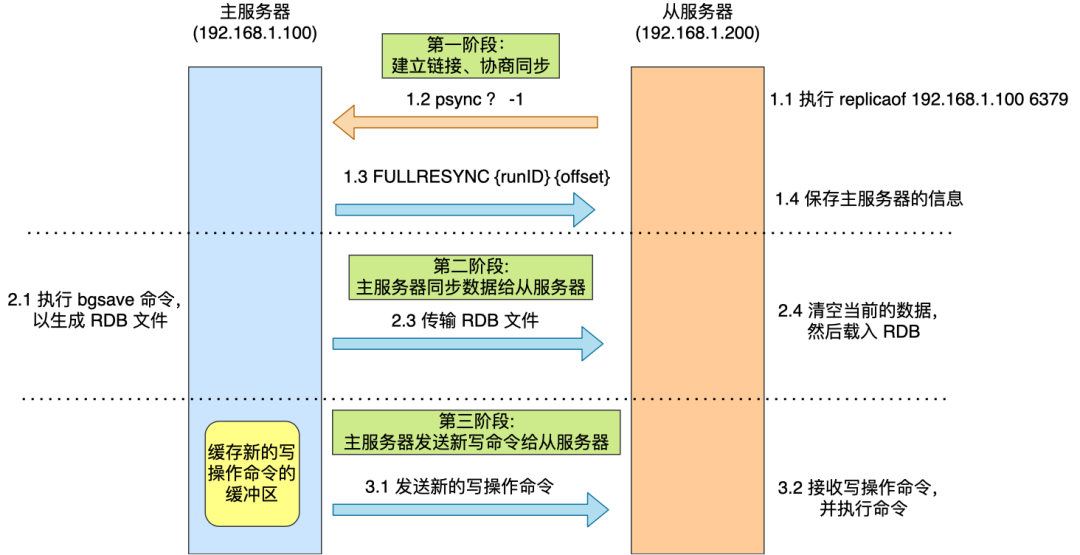
22.能说一下,主从同步数据的流程吗?
实现过程:
1. 初始同步(全量复制)
当从节点第一次连接主节点时,会进行全量复制:
-
从节点发送
PSYNC请求; -
主节点执行
bgsave创建 RDB 快照,同时将写命令缓存在复制缓冲区中; -
主节点将 RDB 发送给从节点;
-
从节点加载 RDB 文件;
-
主节点将缓冲区中的写命令发送给从节点执行,完成增量补偿。
2. 增量同步
-
当从节点已经复制过一次,只是短暂断连时,会尝试继续同步主节点的复制积压缓冲区中的写操作,避免全量复制;
-
使用复制偏移量(replication offset)和主节点的
backlog buffer实现。
23.怎么保证Redis的高并发高可用?
首先可以搭建主从集群,再加上使用Redis中的哨兵模式,哨兵其实是一个运行在特殊模式下的 Redis 进程,所以它也是一个节点。哨兵主要负责三件事情:监控、选主、通知。
-
✅ 监控节点状态(哨兵持续向主节点和从节点发送 PING命令 ,无回应PONG则出事了)
-
✅ 主节点故障自动转移 ,自动将某个从节点提升为主节点(Sentinel 会优先选择 优先级数值最小的从节点(priority 越小,优先级越高))
-
✅ 通知客户端更新连接地址(通过 Redis 的PUB/SUB(发布者/订阅者)机制来实现)
24.你们使用Redis是单点还是集群,哪种集群?
候选人:我们当时使用的是主从(1主1从)加哨兵。一般单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点。
尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用Lua脚本和事务。
25.Redis集群脑裂,该怎么解决呢?
什么是脑裂:
主节点因网络分区与大多数从节点失联,但它仍对外提供写服务;与此同时,集群选出了新的主节点,也对外写数据,导致数据不一致甚至丢失。
这个在项目中很少见,不过脑裂的问题是这样的,我们现在用的是Redis的哨兵模式集群的。
解决思路
-
min-replicas-to-write
-
设置主节点必须有至少 N 个从节点同步确认才能执行写操作,减少孤立主节点写入的可能。
-
-
min-replicas-max-lag
-
限制主从数据延迟时间,超过延迟时间就拒绝写,避免长时间滞后的孤立主节点继续写数据。
-
26.Redis的分片集群有什么作用?
分片集群主要解决的是海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
27.Redis分片集群中数据是怎么存储和读取的?
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围,key通过CRC16校验(循环冗余校验算法)后对16384取模来决定放置哪个槽,通过槽找到对应的节点进行存储。取值的逻辑是一样的。
28.Redis是单线程的,但是为什么还那么快?
嗯,这个有几个原因吧~~~
-
完全基于内存的,避免了磁盘 I/O 瓶颈。。
-
采用单线程,避免不必要的上下文切换和竞争条件。
-
使用多路I/O复用模型,非阻塞IO。
例如:BGSAVE和BGREWRITEAOF都是在后台执行操作,不影响主线程的正常使用,不会产生阻塞。
I/O多路复用
29.能解释一下I/O多路复用模型?
I/O多路复用是指利用单个线程来同时监听多个Socket(文件描述符),并且在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源,单线程就能高效处理成百上千并发连接,常见实现有 select、poll、epoll,Redis 就是基于 epoll 实现的。
📌 工作原理(简化)
-
把多个 socket 注册到内核(如
epoll)。 -
内核监视这些 socket。
-
某个 socket 有事件(可读/可写/异常)时,内核一次性返回所有就绪的 socket 列表。
-
应用程序逐个处理这些就绪的 socket。
30.为什么需要 I/O多路
-
如果用阻塞 I/O:一个连接在等待数据时,线程会被阻塞,浪费 CPU。
-
如果用多线程/多进程:每个连接一个线程/进程,开销大,切换频繁。
-
I/O 多路复用:单线程就能管理成百上千连接,不用开很多线程,也不会阻塞。


















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









