






打卡开始
昇(shēng)思一个有意思的机器学习在线平台,可以让苦于无资金但是有学习机器学习的小伙伴圆梦人工智能前沿技术学习的这一平台,今天开始学习操作

使用须知
- 目前
jupyter运行时长限制只能运行2个小时。2个小时之后将会自动释放所有资源,请提前将所需资源下载到本地或git push到平台中。- 本平台是开放的学习平台,禁止使用本平台进行商业用途和非法用途或者恶意攻击,一旦发现将依法追究。
此开发环境是使用的是Jupyter Lab 3.x,并集成了实用的插件。您可以在Jupyter Lab上灵活运行调试代码和编写文档,Jupyter Lab集成了很多编辑器,例如 Jupyter 笔记本、文本编辑器、终端和自定义组件。更多的详细介绍你可以查看 JupyterLab官网文档介绍。
接下来跟我来一起沉浸式地探索Jupyter Lab吧❗
若您不熟悉Jupyter Lab, 您可以先阅读Jupyter-Document.ipynb文件熟悉Jupyter的基本操作
背景介绍
机器学习的概念诞生于20世纪50年代,起源于图灵的一个问题:计算机是否能够学习和创新?图灵的问题引出了一个与经典程序设计不同的编程范式:
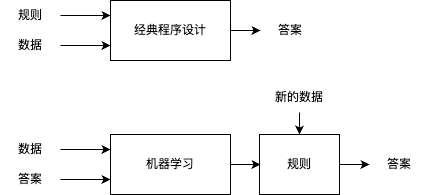
这便是最初机器学习的概念,到现在已经发展为一套完整的流程:

深度学习是一种特殊的机器学习,主要是利用了多层神经网络模拟人脑,自动提取特征并进行预测。
昇思MindSpore介绍
昇思MindSpore是 一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
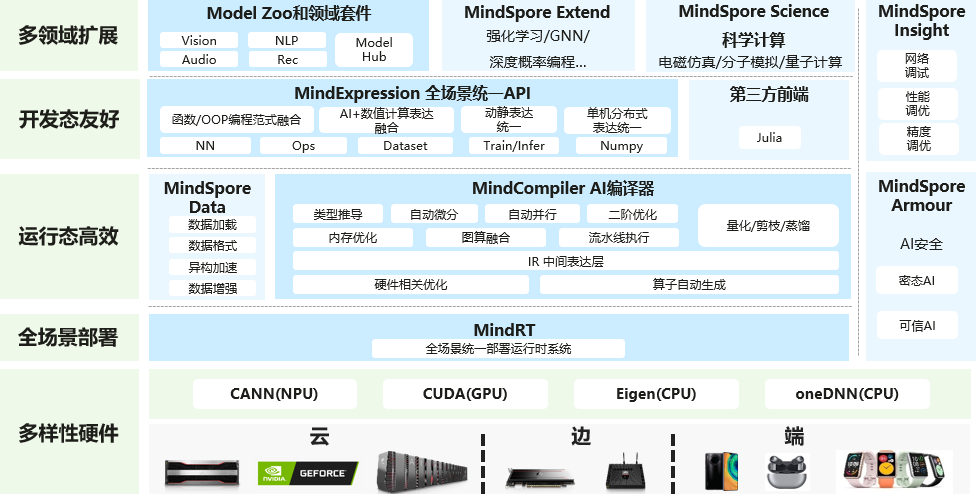
昇思MindSpore总体架构如下图所示:
各个模块之间的配合,如下图所示:
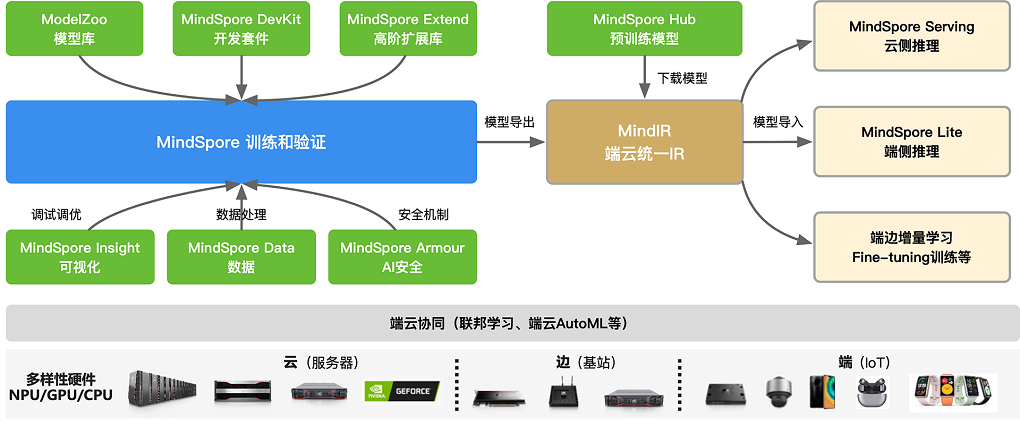
MindSpore是主体框架,主要提供神经网络在训练、验证过程中相关的基础API功能,另外还会默认提供自动微分、自动并行等功能。
MindSpore Data模块,可以利用该模块进行数据预处理,包括数据采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调优的问题,因此有MindSpore Insight模块对loss曲线、算子执行情况、权重参数变量等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。
ModelZoo存放大量的AI算法模型库,提供面向不同领域(NLP、CV等)的开发工具套件,具体可查看MindSpore-Lab仓
快速体验平台操作
快速体验推理
大模型套件MindSpore MindFormers,MindSpore Transformers套件的目标是构建一个大模型训练、微调、评估、推理、部署的全流程开发套件,提供业内主流的Transformer类预训练模型和SOTA下游任务应用,涵盖丰富的并行特性。期望帮助用户轻松的实现大模型训练和创新研发。
MindSpore Transformers套件基于MindSpore内置的并行技术和组件化设计,具备如下特点:
- 一行代码实现从单卡到大规模集群训练的无缝切换;
- 提供灵活易用的个性化并行配置;
- 能够自动进行拓扑感知,高效地融合数据并行和模型并行策略;
- 一键启动任意任务的单卡/多卡训练、微调、评估、推理流程;
- 支持用户进行组件化配置任意模块,如优化器、学习策略、网络组装等;
- 提供Trainer、pipeline、AutoClass等高阶易用性接口;
- 提供预置SOTA权重自动下载及加载功能;
- 支持人工智能计算中心无缝迁移部署;
如果感兴趣可以进入下面代码仓或查看官方文档,一键三连哦
MindFormers 目前支持的模型列表如下:
| 模型 | 任务(task name) | 模型(model name) |
|---|---|---|
| LLama2 | text_generation | llama2_7b llama2_13b llama2_7b_lora llama2_13b_lora llama2_70b |
| GLM2 | text_generation | glm2_6b glm2_6b_lora |
| CodeGeex2 | text_generation | codegeex2_6b |
| LLama | text_generation | llama_7b llama_13b llama_7b_lora |
| GLM | text_generation | glm_6b glm_6b_lora |
| Bloom | text_generation | bloom_560m bloom_7.1b |
| GPT2 | text_generation | gpt2_small gpt2_13b |
| PanGuAlpha | text_generation | pangualpha_2_6_b pangualpha_13b |
| BLIP2 | contrastive_language_image_pretrain zero_shot_image_classification | blip2_stage1_vit_g |
| CLIP | contrastive_language_image_pretrain zero_shot_image_classification | clip_vit_b_32 clip_vit_b_16 clip_vit_l_14 clip_vit_l_14@336 |
| BERT | masked_language_modeling text_classification token_classification question_answering | bert_base_uncased txtcls_bert_base_uncased txtcls_bert_base_uncased_mnli tokcls_bert_base_chinese tokcls_bert_base_chinese_cluener qa_bert_base_uncased qa_bert_base_chinese_uncased |
| T5 | translation | t5_small |
| sam | segment_anything | sam_vit_b sam_vit_l sam_vit_h |
| MAE | masked_image_modeling | mae_vit_base_p16 |
| VIT | image_classification | vit_base_p16 |
| Swin | image_classification | swin_base_p4w7 |
任务描述:
- text_generation:文本生成,生成新文本的任务,模型基于输入的不完整的文本或解释进行填充,或对输入的源语言翻译成目标语言。
- text_classification:文本分类,模型在基于文本对的微调后,可以在给定任意文本对与候选标签列表的情况下,完成对文本对关系的分类,文本对的两个文本之间以-分割。
- image_classification:图像分类,模型基于图像数据集进行训练后,可以在给定任意图片的情况下,完成对图像的分类,分类结果仅限于数据集中所包含的类别。
- token_classification:命名实体识别,模型在基于命名实体识别数据集的微调后,可以在给定任意文本与候选标签列表的情况下,完成对文本中命名实体的识别。
- contrastive_language_image_pretrain:语言图像对比预训练,对模型进行图文对比学习,增强模型对文本图片的匹配度认识能力,预训练完的模型可用于零样本图像分类等下游任务
- zero_shot_image_classification:零样本图像分类,模型在基于图文对的预训练后,可以在给定任意图片与候选标签列表的情况下,完成对图像的分类,而无需任何微调。
快速入门
通过MindSpore的API来快速实现一个简单的深度学习模型。若想要深入了解MindSpore的使用方法。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理,使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
本章节中的示例代码依赖download,可使用命令pip install download安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)
file_sizes: 100%|██████████████████████████| 10.8M/10.8M [00:01<00:00, 6.73MB/s]
Extracting zip file…
Successfully downloaded / unzipped to ./
MNIST数据集目录结构如下:
MNIST_Data
└── train
├── train-images-idx3-ubyte (60000个训练图片)
├── train-labels-idx1-ubyte (60000个训练标签)
└── test
├── t10k-images-idx3-ubyte (10000个测试图片)
├── t10k-labels-idx1-ubyte (10000个测试标签)
数据下载完成后,获得数据集对象。
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
打印数据集中包含的数据列名,用于dataset的预处理。
print(train_dataset.get_col_names())
[‘image’, ‘label’]
MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,将输入的图像缩放为1/255,根据均值0.1307和标准差值0.3081进行归一化处理,然后将处理好的数据集打包为大小为64的batch。
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
可使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype。
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
Shape of image [N, C, H, W]: (64, 1, 28, 28) Float32
Shape of label: (64,) Int32
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
Shape of image [N, C, H, W]: (64, 1, 28, 28) Float32
Shape of label: (64,) Int32
网络构建
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense<input_channels=784, output_channels=512, has_bias=True>
(1): ReLU<>
(2): Dense<input_channels=512, output_channels=512, has_bias=True>
(3): ReLU<>
(4): Dense<input_channels=512, output_channels=10, has_bias=True>
>
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
- 定义正向计算函数。
- 使用value_and_grad通过函数变换获得梯度计算函数。
- 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 3. Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
除训练外,我们定义测试函数,用来评估模型的性能。
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
print("Done!")
Epoch 1
loss: 2.302088 [ 0/938]
loss: 2.290692 [100/938]
loss: 2.266338 [200/938]
loss: 2.205240 [300/938]
loss: 1.907198 [400/938]
loss: 1.455603 [500/938]
loss: 0.861103 [600/938]
loss: 0.767219 [700/938]
loss: 0.422253 [800/938]
loss: 0.513922 [900/938]
Test:
Accuracy: 83.8%, Avg loss: 0.529534
Epoch 2
loss: 0.580867 [ 0/938]
loss: 0.479347 [100/938]
loss: 0.677991 [200/938]
loss: 0.550141 [300/938]
loss: 0.226565 [400/938]
loss: 0.314738 [500/938]
loss: 0.298739 [600/938]
loss: 0.459540 [700/938]
loss: 0.332978 [800/938]
loss: 0.406709 [900/938]
Test:
Accuracy: 90.2%, Avg loss: 0.334828
Epoch 3
loss: 0.461890 [ 0/938]
loss: 0.242303 [100/938]
loss: 0.281414 [200/938]
loss: 0.207835 [300/938]
loss: 0.206000 [400/938]
loss: 0.409646 [500/938]
loss: 0.193608 [600/938]
loss: 0.217575 [700/938]
loss: 0.212817 [800/938]
loss: 0.202862 [900/938]
Test:
Accuracy: 91.9%, Avg loss: 0.280962
保存模型
模型训练完成后,需要将其参数进行保存。
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
Saved Model to model.ckpt
加载模型
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
[]
param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功,加载后的模型可以直接用于预测推理。
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break
Predicted: "[3 9 6 1 6 7 4 5 2 2]", Actual: "[3 9 6 1 6 7 4 5 2 2]"
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









