






文章目录
告别动态规划,连刷40道动规算法题,我总结了动规的套路
hdu 2602 - Bone Collector(01背包)
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 39532 Accepted Submission(s): 16385
Problem Description
Many years ago , in Teddy’s hometown there was a man who was called “Bone Collector”. This man like to collect varies of bones , such as dog’s , cow’s , also he went to the grave …
The bone collector had a big bag with a volume of V ,and along his trip of collecting there are a lot of bones , obviously , different bone has different value and different volume, now given the each bone’s value along his trip , can you calculate out the maximum of the total value the bone collector can get ?
许多年前,在泰迪的家乡,有一个人被称为“骨收集者”。这个人喜欢收集各种骨头,例如狗,牛的骨头,他也去了坟墓……
骨头收集者有一个大袋子,里面装有V,而且在收集骨头的过程中,很明显,不同的骨骼具有不同的值和不同的体积,现在给定沿途的每个骨骼的值,您能否计算出骨骼收集器可以获得的总值的最大值?
Input
The first line contain a integer T , the number of cases.
Followed by T cases , each case three lines , the first line contain two integer N , V, (N <= 1000 , V <= 1000 )representing the number of bones and the volume of his bag. And the second line contain N integers representing the value of each bone. The third line contain N integers representing the volume of each bone.
第一行包含整数T,即案例数。紧随其后的是T个案例,每个案例三行,第一行包含两个整数N,V(N <= 1000,V <=1000),它们表示骨头的数量和包的体积。第二行包含代表每个骨骼值的N个整数。第三行包含N个整数,代表每个骨骼的体积。
Output
One integer per line representing the maximum of the total value (this number will be less than 2 31).
每行一个整数,代表合计的最大值(该数字将小于2 [sup] 31 [/ sup])。
Sample Input
1 5 10 1 2 3 4 5 5 4 3 2 1
Sample Output
14
分析
裸的01背包,经典例题。
代码
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long ll;
const ll N=1e3+5;
int main()
{
int t,n,m;
cin>>t;
ll va[N],v[N],dp[N];
while(t--){
memset(dp,0,sizeof dp);
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>va[i];
}
for(int i=1;i<=n;i++){
cin>>v[i];
}
for(int i=1;i<=n;i++){
for(int j=m;j>=v[i];j--){
dp[j]=max(dp[j] , dp[j-v[i]] + va[i]);
}
}
cout<<dp[m]<<endl;
}
return 0;
}
HDU - 2069 Coin Change
(http://acm.hdu.edu.cn/showproblem.php?pid=2069)
题目描述

题目翻译
假设有5种货币,它们分别是1分,5分,10分,25分,50分,我们要用它们来凑出指定数目的钱币( n n n分)
举个例子,如果我们要凑出11分,我们可以有1个10分+1个1分;2个5分+1个1分;1个5分+6个1分;11个1分四种方案
注意:0分钱的答案是1
请写一个程序来找出凑出指定数目钱币的方案总数, n ≤ 7489 n\leq7489 n≤7489
输入输出格式
输入格式:
输入包含若干行,每一行都包含1个 n n n
输出格式:
每一行输出对应的 n n n的方案总数
输入格式

输出格式

样例 #1
样例输入 #1
11
26
样例输出 #1
4
13
题意
有五种硬币不限数量,面值分别是1,5,10,25,50。问你用这些硬币组成n元有多少种方式,硬币的总数要不超过100个。
分析
dp背包,设dp[i][j]表示用j个硬币组成i元的方法数,则dp[i][j]=dp[i][j]+dp[i-v][j-1],v表示当前的硬币面值。
代码
#include<iostream>
#include<cstring>
using namespace std;
typedef long long ll;
ll dp[300][110];//dp[i][j]表示用j个硬币拼出i元的方法数
int a[5]={1,5,10,25,50};//五种硬币的面值
int main()
{
int n,i,j,k;
while(cin>>n)
{
memset(dp,0,sizeof(dp));
dp[0][0]=1;
for(i=0;i<5;i++)
{
for(j=1;j<=100;j++)//硬币总数小于100
{
for(k=a[i];k<=n;k++)
dp[k][j]+=dp[k-a[i]][j-1];
}
}
int res=0;
for(i=0;i<=100;i++)
res+=dp[n][i];
cout<<res<<endl;
}
return 0;
}
一只小蜜蜂…
题目描述
有一只经过训练的蜜蜂只能爬向右侧相邻的蜂房,不能反向爬行。请编程计算蜜蜂从蜂房a爬到蜂房b的可能路线数。
其中,蜂房的结构如下所示。

Input
输入数据的第一行是一个整数N,表示测试实例的个数,然后是N 行数据,每行包含两个整数a和b(0<a<b<50)。
Output
对于每个测试实例,请输出蜜蜂从蜂房a爬到蜂房b的可能路线数,每个实例的输出占一行。
Sample Input
2
1 2
3 6
Sample Output
1
3
分析
简单的动态规划问题,唯一需要注意的起点有可能不是1,所以输出的格式要稍加改变。
代码
#include<iostream>
#include<cstring>
using namespace std;
typedef long long ll;
int main()
{
ll n,a,b;
ll dp[100];
dp[1]=1,dp[2]=1;
cin>>n;
for(int i=3;i<=50;i++){
dp[i]=dp[i-1]+dp[i-2];
}
while(n--){
cin>>a>>b;
cout<<dp[b-a+1]<<endl;//求区间内有几个数
}
return 0;
}
折线分割平面
题目描述
我们看到过很多直线分割平面的题目,今天的这个题目稍微有些变化,我们要求的是n条折线分割平面的最大数目。比如,一条折线可以将平面分成两部分,两条折线最多可以将平面分成7部分,具体如下所示。

Input
输入数据的第一行是一个整数C,表示测试实例的个数,然后是C 行数据,每行包含一个整数n(0<n<=10000),表示折线的数量。
Output
对于每个测试实例,请输出平面的最大分割数,每个实例的输出占一行。
Sample Input
2
1
2
Sample Output
2
7
分析
具体图解见 -> 折线分割平面(图文解析)
一条折线可以看成两条直线相交,减去形成的多余空间
代码
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long ll;
const ll N=1e3+5;
ll line(int x){//x条直线切割的区域
int ans,sum=0;
if(x==2) sum=0;
for(int i=1;i<=x-2;i++){
sum +=i;
}
ans = sum+2*x;
return ans;
}
int main()
{
int t,n,m;
cin>>t;
ll dp1[N],dp2[N];
while(t--){
int n;
cin>>n;
cout<<line(2*n/*n条折线相当于2n条直线*/)-2*n<<endl;
}
return 0;
}
LCS和LIS
A - Common Subsequence
A subsequence of a given sequence is the given sequence with some elements (possible none) left out. Given a sequence X = <x1, x2, …, xm> another sequence Z = <z1, z2, …, zk> is a subsequence of X if there exists a strictly increasing sequence <i1, i2, …, ik> of indices of X such that for all j = 1,2,…,k, xij = zj. For example, Z = <a, b, f, c> is a subsequence of X = <a, b, c, f, b, c> with index sequence <1, 2, 4, 6>. Given two sequences X and Y the problem is to find the length of the maximum-length common subsequence of X and Y.
The program input is from a text file. Each data set in the file contains two strings representing the given sequences. The sequences are separated by any number of white spaces. The input data are correct. For each set of data the program prints on the standard output the length of the maximum-length common subsequence from the beginning of a separate line.
翻译
这个题意挺清晰的,就是输入两个字符串a 和 b,输入最长顺序公共子序列。
Input
abcfbc abfcab
programming contest
abcd mnp
Output
4
2
0
分析:
就是建立一个长为[0,lena],宽为[0,lenb]的表格,然后第(i,j)个就代表搜完a的前i-1个字符和b的前j-1个字符的最长公共子序列的长度,那么第(lena,lenb)个格子里的数就是这两个字符串的最长公共子序列了咯。接下来就是如何去构建这张表格:
首先,表格储存在二维数组dp里。
然后填表肯定是从第一行和第一列开始的,用两组循环的方式,一列一列去填表,即以字符串a为基准,不断去计算前n个字符(也就是填前n列)和字符串b的最长公共子序列。
对于每次比较,肯定是先比较a的第i-1个字符和b的第j-1个字符,
如果相等,就加一。
如果不等,就不断的从前面挑选最大的公共子序列,然后继续比较。
————————————————
版权声明:本文为CSDN博主「-Avril-」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_52433146/article/details/113356783
代码
#include<iostream>
#include<stdio.h>
#include<string.h>
using namespace std;
int dp[1050][1050] = {0};
int main()
{
string a,b;
while(cin>>a>>b){
memset(dp,0,sizeof dp);
a = '.' + a;//让a的下标从1开始,防止dp数组越界
b = '.' + b;
int n=a.size();
int m=b.size();
for(int i=1;i<n;i++){
for(int j=1;j<m;j++){
if(a[i] == b[j]){
dp[i][j] = dp[i-1][j-1] + 1;
}
else dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}
}
cout<<dp[n-1][m-1]<<endl;
}
return 0;
}
小技巧——字符串从下标为1开始出入
POJ1080-Human Gene Functions(LCS)
题目描述
It is well known that a human gene can be considered as a sequence, consisting of four nucleotides, which are simply denoted by four letters, A, C, G, and T. Biologists have been interested in identifying human genes and determining their functions, because these can be used to diagnose human diseases and to design new drugs for them.
A human gene can be identified through a series of time-consuming biological experiments, often with the help of computer programs. Once a sequence of a gene is obtained, the next job is to determine its function.
One of the methods for biologists to use in determining the function of a new gene sequence that they have just identified is to search a database with the new gene as a query. The database to be searched stores many gene sequences and their functions – many researchers have been submitting their genes and functions to the database and the database is freely accessible through the Internet.
A database search will return a list of gene sequences from the database that are similar to the query gene.
Biologists assume that sequence similarity often implies functional similarity. So, the function of the new gene might be one of the functions that the genes from the list have. To exactly determine which one is the right one another series of biological experiments will be needed.
Your job is to make a program that compares two genes and determines their similarity as explained below. Your program may be used as a part of the database search if you can provide an efficient one.
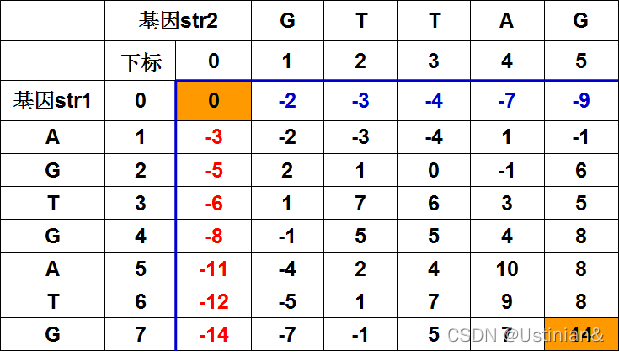
Given two genes AGTGATG and GTTAG, how similar are they? One of the methods to measure the similarity
of two genes is called alignment. In an alignment, spaces are inserted, if necessary, in appropriate positions of
the genes to make them equally long and score the resulting genes according to a scoring matrix.
For example, one space is inserted into AGTGATG to result in AGTGAT-G, and three spaces are inserted into GTTAG to result in –GT–TAG. A space is denoted by a minus sign (-). The two genes are now of equal
length. These two strings are aligned:
AGTGAT-G
-GT–TAG
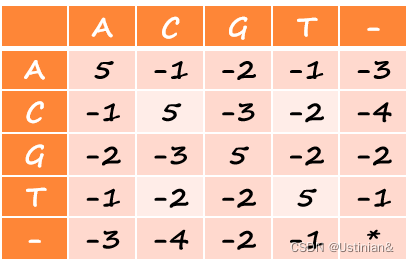
In this alignment, there are four matches, namely, G in the second position, T in the third, T in the sixth, and G in the eighth. Each pair of aligned characters is assigned a score according to the following scoring matrix.
denotes that a space-space match is not allowed. The score of the alignment above is (-3)+5+5+(-2)+(-3)+5+(-3)+5=9.
Of course, many other alignments are possible. One is shown below (a different number of spaces are inserted into different positions):
AGTGATG
-GTTA-G
This alignment gives a score of (-3)+5+5+(-2)+5+(-1) +5=14. So, this one is better than the previous one. As a matter of fact, this one is optimal since no other alignment can have a higher score. So, it is said that the
similarity of the two genes is 14.
翻译
众所周知,人类基因可以认为是一个基因序列,包含四种核苷酸,分别用A,C,T和G四个字母简单地表示。生物学家对鉴别人类基因并确定他们的功能很感兴趣,因为这对诊断人类疾病和开发新药很有用。……
你的任务是编写一个程序,按以下规则比较两个基因并确定它们的相似程度。
给出两个基因AGTGATG和GTTAG,他们有多相似呢?测量两个基因相似度的一种方法称为对齐。使用对齐方法,可以在基因的适当位置插进空格,让两个基因的长度相等,然后根据基因分值矩阵计算分数。
例如,给AGTGATG插入一个空格,就得到AGTGAT-G;给GTTAG插入三个空格,就得到-GT–TAG。空格用减号(-)表示。现在两个基因一样长了,把这两个字符串对齐:
AGTGAT-G
-GT–TAG
对齐以后,有四个基因是相配的:第二位的G,第三位的T,第六位的T和第八位的G。根据下列基因分值矩阵,每对匹配的字符都有相应的分值。
表示空格对空格是不允许的。上面对齐的字符串分值是:
(-3)+5+5+(-2)+(-3)+5+(-3)+5=9。
数据结构
Input
The input consists of T test cases. The number of test cases ) (T is given in the first line of the input file. Each test case consists of two lines: each line contains an integer, the length of a gene, followed by a gene sequence. The length of each gene sequence is at least one and does not exceed 100.
Output
The output should print the similarity of each test case, one per line.
Sample Input
2
7 AGTGATG
5 GTTAG
7 AGCTATT
9 AGCTTTAAA
Sample Output
14
21
分析
int list[5][5] =
{{5, -1, -2, -1, -3},
{-1, 5, -3, -2, -4},
{-2, -3, 5, -2, -2},
{-1, -2, -2, 5, -1},
{-3, -4, -2, -1, 0}};
原矩阵的下标是’A’,‘C’,‘G’,‘T’和’-’,有很多程序采用switch语句转换,这里采用map数组转换:
只使用其中5个单元:mp[‘A’] = 0; mp[‘C’] = 1; mp[‘G’] = 2; mp[‘T’] = 3; mp[’-’] = 4;
图解
我们可以模仿dp里面经典的求最长公共子序列的方法。
字符串a中的字符和字符串b中的字符相比无非就三种情况
1.上面加‘-’
2.下面加‘-’
3.直接两个字符相比
dp[i][j]用来表示字符串a和字符串序列b的最大相似度
dp[i][j] 为dp[i-1][j] + list[mp[a[i]]][mp['-']] , dp[i][j-1]+list[mp['-']][mp[b[j]]]中的最大值
当然重要还有注意下dp的边界值 这也是经常可能会出错的地方
dp[0][j] = dp[0][j-1] + list[4][mp[b[j]]];
dp[i][0] = dp[i-1][0] + list[mp[a[i]]][4];
代码
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<map>
using namespace std;
int list[5][5]={{5,-1,-2,-1,-3},{-1,5,-3,-2,-4},{-2,-3,5,-2,-2},{-1,-2,-2,5,-1},{-3,-4,-2,-1,0}};
map<char,int>mp;
int dp[105][105];//这里dp[i][j]表示a的前i个字符组成的字符串与b的前j个字符组成的字符串的最长公共子列的长度,
//mp[a[i]][b[j]]表示字符a[i]和b[j]的匹配值
int main()
{
int t,n,m;
mp['A']=0;//在表格中的位置
mp['C']=1;
mp['G']=2;
mp['T']=3;
mp['-']=4;
cin>>t;
while(t--){
string a,b;
dp[0][0] = 0;
cin>>n;//数组1的长度
cin>>a;//数组1
a='.'+a;//让数组1的下标从1开始
cin>>m;//2
cin>>b;//2
b='.'+b;// 2的下标从1开始
for(int i=1;i<=n;i++){//边界值
dp[i][0] = dp[i-1][0] + list[mp[a[i]]][4];
}
for(int i=1;i<=m;i++){
dp[0][i] = dp[0][i-1] + list[4][mp[b[i]]];
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
dp[i][j] = dp[i-1][j-1] + list[mp[a[i]]][mp[b[j]]];
dp[i][j] = max(dp[i-1][j] + list[mp[a[i]]][mp['-']] , dp[i][j]);
dp[i][j] = max(dp[i][j-1]+list[mp['-']][mp[b[j]]],dp[i][j]);
}
}
cout<<dp[n][m]<<endl;
}
return 0;
}
E - Advanced Fruits(LCS两字符串最短母串模板)
题目描述
The company “21st Century Fruits” has specialized in creating new sorts of fruits by transferring genes from one fruit into the genome of another one. Most times this method doesn’t work, but sometimes, in very rare cases, a new fruit emerges that tastes like a mixture between both of them.
A big topic of discussion inside the company is “How should the new creations be called?” A mixture between an apple and a pear could be called an apple-pear, of course, but this doesn’t sound very interesting. The boss finally decides to use the shortest string that contains both names of the original fruits as sub-strings as the new name. For instance, “applear” contains “apple” and “pear” (APPLEar and apPlEAR), and there is no shorter string that has the same property.
A combination of a cranberry and a boysenberry would therefore be called a “boysecranberry” or a “craboysenberry”, for example.
Your job is to write a program that computes such a shortest name for a combination of two given fruits. Your algorithm should be efficient, otherwise it is unlikely that it will execute in the alloted time for long fruit names.
翻译
LCS最长公共子序列的一个升级版,将两个序列不是最长公共子序列的部分都输出,是最长公共子序列的部分只输出一次。
Input
Each line of the input contains two strings that represent the names of the fruits that should be combined. All names have a maximum length of 100 and only consist of alphabetic characters.
Input is terminated by end of file.
Output
For each test case, output the shortest name of the resulting fruit on one line. If more than one shortest name is possible, any one is acceptable.
Sample Input
apple peach
ananas banana
pear peach
Sample Output
appleach
bananas
pearch
分析:
lcm路径还原,还原路径的时候不仅要得到lcm,还要把两个字符串中各自有的顺便记录下来
回顾我们在求LCS的时候的算法。
if(s1[i-1] == s2[j-1])
f[i][j] = f[i-1][j-1] + 1;
else f[i][j] = max(f[i-1][j],f[i][j-1]);
我们发现当s1[i-1]和s2[j-1]相等的时候(这里序列下标从0开始),f[i][j] = f[i-1][j-1] + 1。只是在原来的长度上增加1。而不等的时候取一个最大值便可。
通过观察我们发现f[i][j]只能有三种状态转移而来f[i-1][j-1],f[i-1][j] , f[i][j-1]。而f[i][j]每次更新的路径其实就是我们要求的那个合并后的序列,所以我们再用一个数组记录路径,最后用一个递归输出即可。
代码
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int main() {
string a,b;
while(cin >> a >> b){
//求lcm
int dp[105][105] = {0};
a = '.' + a;//让a的下标从1开始
b = '.' + b;//同理a
for(int i = 1;i < a.size();i++){
for(int j = 1;j < b.size();j++){
//状态转移方程
if(a[i] == b[j]){
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else{
dp[i][j] = max(dp[i - 1][j],dp[i][j - 1]);
}
}
}
//根据dp表还原答案
string ans;
int i = a.size() - 1, j = b.size() - 1; //从终点推
while (i >= 1 && j >= 1){
if (a[i] == b[j]){
ans = b[j] + ans;
i--;
j--;
}
//由上面的求LCS可以知道dp【i】【j】是由这两个中的一个得来的,
//所以可以知道上面的一个字符来自于哪个字符串;
else if (dp[i - 1][j] > dp[i][j - 1]){//从上面传来的
ans = a[i--] + ans;
}
else{
ans = b[j--] + ans;
}
}
//把剩下的字符加入字符串中;
while (i){
ans = a[i--] + ans;
}
while (j){
ans = b[j--] + ans;
}
cout << ans << endl;
}
return 0;
}
D - Super Jumping! Jumping! Jumping!(最长非连续子序列之和)
题目描述
Nowadays, a kind of chess game called “Super Jumping! Jumping! Jumping!” is very popular in HDU. Maybe you are a good boy, and know little about this game, so I introduce it to you now.
The game can be played by two or more than two players. It consists of a chessboard(棋盘)and some chessmen(棋子), and all chessmen are marked by a positive integer or “start” or “end”. The player starts from start-point and must jumps into end-point finally. In the course of jumping, the player will visit the chessmen in the path, but everyone must jumps from one chessman to another absolutely bigger (you can assume start-point is a minimum and end-point is a maximum.). And all players cannot go backwards. One jumping can go from a chessman to next, also can go across many chessmen, and even you can straightly get to end-point from start-point. Of course you get zero point in this situation. A player is a winner if and only if he can get a bigger score according to his jumping solution. Note that your score comes from the sum of value on the chessmen in you jumping path.
Your task is to output the maximum value according to the given chessmen list.
翻译
输入首先给出数字n(n<=1000),接下来会给出有n个数字的序列。
求其递增序列(可以不连续)的最大和。
输入n为0时结束输入。
输入
Input contains multiple test cases. Each test case is described in a line as follow:
N value_1 value_2 …value_N
It is guarantied that N is not more than 1000 and all value_i are in the range of 32-int.
A test case starting with 0 terminates the input and this test case is not to be processed.
输出
For each case, print the maximum according to rules, and one line one case.
样例输入
3 1 3 2
4 1 2 3 4
4 3 3 2 1
0
1
2
3
4
样例输出
4
10
3
1
2
3
举例:
样例1中递增序列有:1,13,12,3,2
其中最大和为 1+3=4,所以输出4
分析
求最长上升序列:有 n 个数,每次取的数都必须比前一个取的数大。的和的最大值,需要找到状态转移方程。
设计一个dp数组,数组中表示当前该数字所能处于的最长上升子序列(以当前数字为最大值)的最大和。
dp[i] 为以 i 结尾的最大上升子序列由 max(dp[j] )转移过来,因为 dp[j] 以 a[j] 结尾,所以只要判断 a[i]>a[j] 即可
最后记得初始化
int a[maxn]; //存储序列
int dp[maxn]; //dp[i]:a[i]所处的上升序列的最大和(a[i]处的最优解)
for(int i=1; i<=n; i++)
cin>>a[i],dp[i]=a[i]; //一开始a[i]对应的dp[i]值为a[i]本身
dp部分:
for(int i=1; i<=n; i++) //以a[i]为结尾的子序列
{
for(int j=1; j<i; j++)//遍历a[i]之前的元素
{
if(a[j]<a[i])
dp[i]=max(dp[i],dp[j]+a[i]); //状态转移方程
}
}
代码
#include<bits/stdc++.h>
using namespace std;
const int maxn=1005;
int a[maxn]; //存储序列
int dp[maxn]; //dp[i]:a[i]所处的上升序列的最大和(a[i]处的最优解)
int main()
{
int n;
while(cin>>n&&n)
{
int maxx=-1;
for(int i=1; i<=n; i++)
cin>>a[i],dp[i]=a[i]; //一开始a[i]对应的dp[i]值为a[i]本身
for(int i=1; i<=n; i++) //以a[i]为结尾的子序列
{
for(int j=1; j<i; j++)//遍历a[i]之前的元素
{
if(a[j]<a[i])
dp[i]=max(dp[i],dp[j]+a[i]); //状态转移方程
}
}
//答案表示,所有以自己为结尾当中的最大值
//注意答案不是dp【n】,最大上升子序列的和不一定以最后一个结尾
for(int i=1; i<=n; i++)
maxx=max(ma,dp[i]); //取最大值
cout<<maxx<<endl;
}
}















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}