






简介
进程(Process)是正在运行的程序,是操作系统进行资源分配和调度的基本单位。程序是存储在硬盘或内存的一段二进制序列,是静态的,而进程是动态的。进程包括代码、数据以及分配给它的其他系统资源(如文件描述符、网络连接等)。例如在windos系统下打开一个浏览器或者其余任何一个应用程序,都属于一个进程,而程序本身并不是进程,只有当他在运行时才被称为进程。
system创建子进程
system是C标准库函数 int system(const char *command) ;
作用是把 command 指定的命令名称或程序名称传给要被命令处理器执行的主机环境,并在命令完成后返回。也就是根据传入的命令启动一个进程来执行这个命令。他可以自适应对应的操作系统,在windos和linux系统下都可以直接调用。
参数是传入的shell命令,以字符串形式传入,执行成功返回0,失败返回非0
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int result = 0;
result = system("ping -c 10 www.baidu.com");
handle_error("system",result);
return 0;
}
本段代码使用system创建一个子进程来执行ping -c 10 www.baidu.com这个命令。在程序运行后在终端中使用ps -ef 来查看所有进程。

如图第一个进程是执行makefile,第二个是运行system这个可执行文件(因为我把上述代码的.c文件命名为了system),他启动了子进程3723,子进程3723又启动了子进程3724来执行ping -c 10 www.baidu.com
进程处理
进程处理主要涉及创建子进程,跳转到其他进程,等待进程结束等,包括fork,execve,waitpid函数。
在进程处理中,程序的main函数主要采取有参数格式,int main(int argc, char *argv[]);
argc是传递给程序的命令行参数的数量。
argv指向字符串数组的指针,存储了命令行参数,是在命令行运行此程序时传入的参数。
argv[0]通常是程序的名称。
argv[1]到argv[argc-1]是实际的命令行参数。
每个进程都有一个独立的编号,称为pid(process id),即进程ID,用于区分不同的进程,pid的数据格式为__pid_t或者pid_t,层层定义下来最终也就是int类型。
fork函数
fork()函数的作用是创建一个子进程,并继承父进程的资源,即将父进程的资源复制了一遍,但是子进程也是一个进程,拥有独立的进程ID,创建这个子进程的进程叫做父进程,在调用fork之前,程序内只有父进程在运行,fork之后,程序就被复制了一遍,fork之后的程序在父子进程内都会执行一遍。
fork函数在成功创建子进程之后会返回一个值,在父进程中会返回子进程的PID,在子进程中就会返回0,这就可以帮助我们区分父子进程,用于设置父子进程分别执行不同的功能。
pid_t getpid(void);
getpid函数会返回调用该函数的进程的进程ID。
pid_t getppid(void);
getppid函数会返回调用该函数的进程的父进程的进程ID
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
pid_t pid = 0;
printf("现在是父进程\n");
pid = fork();
handle_error("fork",pid);
if(pid == 0)//子进程
{
printf("现在是fork之后创建的子进程,进程ID为%d,我的父进程的进程ID为%d\n",getpid(),getppid());
}
else if(pid > 0)//父进程
{
printf("现在是fork之后的父进程,进程ID为%d\n",getpid());
}
printf("此段代码,父子进程都会执行\n");
return 0;
}
程序运行结果如下

可以看到在fork之前的程序只执行了一次,在fork之后如果不区分pid的值,程序就会在父子进程中都执行,且子进程可以正确返回父进程的ID。
文件描述符的引用计数
#include <sys/stat.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int fd = 0;
fd = open("io.txt",O_RDWR | O_CREAT,0666);
handle_error("open",fd);
pid_t pid = 0;
char write_buf[60] = "父进程在fork之前写入的\n";
write(fd,write_buf,strlen(write_buf));
pid = fork();
handle_error("fork",pid);
if(pid == 0)//子进程
{
strcpy(write_buf,"子进程在fork之后写入的\n");
write(fd,write_buf,strlen(write_buf));
}
else if(pid > 0)
{
strcpy(write_buf,"父进程在fork之后写入的\n");
write(fd,write_buf,strlen(write_buf));
}
close(fd);
return 0;
}
程序运行结果如下,查看io.txt文件
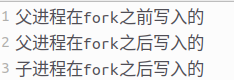
在这个程序中,经过fork创建子进程之后,子进程并没有再单独打开io.txt文件,而是可以直接使用父进程打开的文件描述符fd从而向文件中写入数据。这是因为子进程复制了父进程的文件描述符fd,二者指向的应是同一个底层文件描述(struct file结构体)。
如果子进程通过close()释放文件描述符之后,父进程对于相同的文件描述符执行write()操作仍然可以成功。这是因为struct file结构体中有一个属性为引用计数,记录的是与当前struct file绑定的文件描述符数量。close()系统调用的作用是将当前进程中的文件描述符和对应的struct file结构体解绑,使得引用计数减一。如果close()执行之后,引用计数变为0,则会释放struct file相关的所有资源。通过fork创建子进程,子进程复制父进程的文件描述符,在这一过程中,会使对应文件的引用计数+1,所以在关闭时,父子进程都需要调用close关闭文件描述符,才能使其引用计数降为0。否则struct file相关的所有资源将不会释放。
execve
exec是一个系列函数,可以在一个进程中跳转到另外一个函数并开始执行,如果跳转成功,那么该函数之后的内容都不会再执行,而是跳转到新程序开始执行新程序的内容,跳转之后的进程ID保持不变。本文以execve为例。
函数原型为int execve (const char *__path, char *const __argv[], char *const __envp[]);
char *__path: 需要执行程序的完整路径名
char *const __argv[]: 指向字符串数组的指针 需要传入多个参数
(1) 需要执行的程序命令(和*__path相同)
(2) 执行程序需要传入的参数
(3) 最后一个参数必须是NULL
char *const __envp[]: 指向字符串数组的指针 需要传入多个环境变量参数,环境变量也可以不传,直接赋值为NULL
(1) 环境变量参数 固定格式 key=value
(2) 最后一个参数必须是NULL
return: 成功就回不来了 下面的代码都没有意义 失败返回-1
先写一个跳转到的目标程序,编译为可执行文件,命名为execve_dst
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
if(argc < 2)
{
printf("参数小于两个\n");
}
else if(argc >= 2)
{
printf("参数正常,跳转到的进程ID为%d\n",getpid());
}
return 0;
}
再写一个跳转的程序,跳转到execve_dst,该程序命名为execve_src
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
char *argvs[] = {"./execve_dst","跳转的源头",NULL};
char *envp[] = {NULL};
printf("我是跳转源头,我的进程ID是%d\n",getpid());
execve("./execve_dst",argvs,envp);
printf("我已经跳转了\n");
return 0;
}
编译运行execve_src,结果如下
![]()
可以看到两次调用getpid查询到的进程ID相同,且execve之后的printf没有执行。
waitpid
Linux中父进程除了可以启动子进程,还要负责回收子进程的状态。如果子进程结束后父进程没有正常回收,那么子进程就会变成一个僵尸进程——即程序执行完成,但是进程没有完全结束,其内核中的相关资源没有释放。如果父进程在子进程结束前就结束了,那么其子进程的回收工作就交给了父进程的父进程的父进程。本次使用waitpid使父进程等待子进程结束后回收资源后再结束,防止子进程变为僵尸进程。
wait函数
原型为pid_t wait(int *wstatus);
作用是等待子进程停止并获取退出状态。
waitpid函数
原型为pid_t waitpid(pid_t pid, int *wstatus, int options);
pid: 等待的模式
* (1) 小于-1 例如 -1 * pgid,则等待进程组ID等于pgid的所有进程终止
* (2) 等于-1 会等待任何子进程终止,并返回最先终止的那个子进程的进程ID -> 儿孙都算
* (3) 等于0 等待同一进程组中任何子进程终止(但不包括组领导进程) -> 只算儿子
* (4) 大于0 仅等待指定进程ID的子进程终止
wstatus: 整数指针,子进程返回的状态码会保存到该int
options: 选项的值是以下常量之一或多个的按位或(OR)运算的结果;二进制对应选项,可多选:
* (1) WNOHANG 如果没有子进程终止,也立即返回;用于查看子进程状态而非等待
* (2) WUNTRACED 收到子进程处于收到信号停止的状态,也返回。
* (3) WCONTINUED(自Linux 2.6.10起)如果通过发送SIGCONT信号恢复了一个已停止的子进程,则也返回。
若填0则为waitpid最初的功能,等待子进程关闭。
return: (1) 成功等到子进程停止 返回pid
* (2) 没等到并且没有设置WNOHANG 一直等
* (3) 没等到设置WNOHANG 返回0
* (4) 出错返回-1
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
pid_t pid = 0;
pid = fork();
handle_error("fork",pid);
if(pid == 0)
{
sleep(10);
printf("子进程马上结束\n");
}
else
{
printf("父进程正在等待子进程结束\n");
waitpid(pid,NULL,0);
printf("父进程等待子进程结束,即将结束\n");
}
return 0;
}
程序的运行结果应该是先打印出父进程正在等待子进程结束,等待十秒打印出子进程马上结束,之后子进程结束,父进程等待子进程结束后打印父进程等待子进程结束,即将结束。
进程树
Linux的进程是通过父子关系组织起来的,所有进程之间的父子关系共同构成了进程树(Process Tree)。进程树中每个节点都是其上级节点的子进程,同时又是子结点的父进程。一个进程的父进程只能有一个,而一个进程的子进程可以不止一个。
ps -ef可以查看当前系统中的所有进程,我们在程序中调用命令行输入来阻塞程序内容,然后在终端中使用ps -ef命令查看进程的ID号和父进程的ID号,最终会查到ID为1的进程,实质上,1号进程就是systemd,它由内核创建,是第一个进程,负责初始化系统,启动其他所有用户空间的服务和进程。它是所有进程的祖先。
查看进程树的命令是pstree,会以树状图展示所有用户线程的依赖关系,就像一张族谱图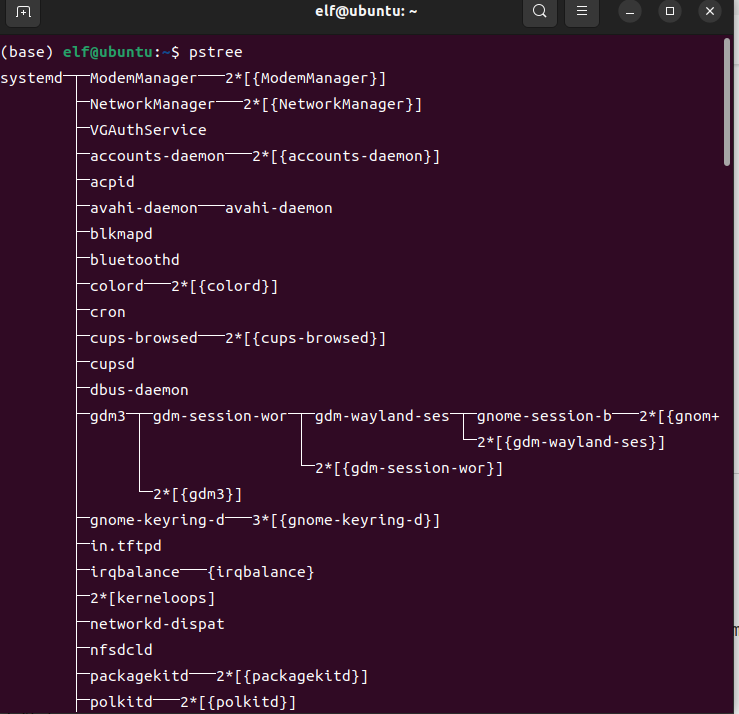
调用pstree -p可以显示每个进程的ID号
孤儿进程
孤儿进程(Orphan Process)是指父进程已结束或终止,而它仍在运行的进程。
当父进程结束之前没有等待子进程结束,且父进程先于子进程结束时,那么子进程就会变成孤儿进程。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
pid_t pid = 0;
pid = fork();
handle_error("fork",pid);
if(pid == 0)
{
printf("子进程刚刚创建,进程ID为%d,我现在的父进程ID为%d\n",getpid(),getppid());
sleep(5);
printf("子进程已经休眠了5s,我现在的父进程ID为%d\n",getppid());
}
else if(pid > 0)
{
printf("父进程的ID号为%d\n",getpid());
sleep(2);
printf("父进程已经结束\n");
}
return 0;
}

根据结果可以看到,父进程结束之后,程序已经是退出状态,运行结束,子进程仍未结束,又重新占用了终端输出,而且其父进程变为了祖先的ID,所以孤儿进程会被其祖先自动领养。此时的子进程因为和终端切断了联系,所以很难再进行标准输入使其停止了,所以写代码的时候一定要注意避免出现孤儿进程。
进程间通信
进程之间的内存是隔离的,如果多个进程之间需要进行数据交换,通常可以通过匿名管道(pipe),有名管道(fifo),共享内存,消息队列和套接字编程,本文先不介绍套接字编程,后续放到网络编程中讲解。
匿名管道(PIPE)
匿名管道是位于内核的一块缓冲区,用于进程间通信。创建匿名管道的系统调用为pipe。
pipe的函数原型是int pipe(int pipefd[2]);
pipe的功能是在内核空间创建管道,用于父子进程或者其他相关联的进程之间通过管道进行双向的数据传输。
管道的数组中的两个参数就是两个文件描述符,可以用write,read,open,close,实现读写开关,在一个进程写的时候,要把读功能关掉。
pipefd: 用于返回指向管道两端的两个文件描述符。pipefd[0]指向管道的读端。pipefd[1]指向管道的写端。
return: 成功 0,不成功 -1,并且pipefd不会改变
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
if(argc < 2)//如果运行该程序时没有传入命令则退出程序
{
printf("信息不足\n");
exit(EXIT_FAILURE);
}
printf("%s\n",argv[1]);//打印传入的命令
int pipefd[2],tmp;
char read_buf;
tmp = pipe(pipefd);
handle_error("pipe",tmp);
pid_t pid;
pid = fork();
handle_error("fork",pid);
if(pid == 0)//子进程
{
close(pipefd[1]);//子进程是接收端,读取数据,需要关闭写端
while (read(pipefd[0],&read_buf,1) > 0)//每次读取一个数据,方便读取结束符
{
write(STDOUT_FILENO,&read_buf,1);
}
write(STDOUT_FILENO,"\n",1);
close(pipefd[0]);//读取完成之后关闭读端
exit(EXIT_SUCCESS);
}
else if(pid > 0)
{
close(pipefd[0]);//父进程是发送端,写入数据,需要关闭读端
write(pipefd[1],argv[1],strlen(argv[1]));//往管道的写端写入数据
close(pipefd[1]);//写入完毕,关闭写端
waitpid(pid,NULL,0);
exit(EXIT_SUCCESS);
}
return 0;
}
使用gcc编译之后,在终端中执行
./pipe hellocsdn
hellocsdn
hellocsdn第一个hellocsdn是printf输出的,用于检查输入的命令,第二个是父进程将命令写入匿名管道,子进程通过匿名管道读取到的内容,注意输入的命令是以空格为间隔的,如果输入的命令有空格,就会以空格为间隔,将空格之后的数据算到下一个命令,比如argv[2]。
两个进程通过一个管道只能实现单向通信,比如上面的例子,父进程写子进程读,如果有时候也需要子进程写父进程读,就必须另开一个管道。
管道返回的两个文件描述符分别表示读写,各自指向一个struct file结构体,然而,它们并不对应真正的文件。
管道的读写端通过打开的文件描述符来传递,因此要通信的两个进程必须从它们的公共祖先那里继承管道文件描述符。上面的例子是父进程把文件描述符传给子进程之后父子进程之间通信,也可以父进程fork两次,把文件描述符传给两个子进程,然后两个子进程之间通信,总之需要通过fork传递文件描述符使两个进程都能访问同一管道,它们才能通信。
有名管道(FIFO)
上面介绍的Pipe是匿名管道,只能在有父子关系的进程间使用,某些场景下并不能满足需求。与匿名管道相对的是有名管道,在Linux中称为FIFO,即First In First Out,先进先出队列。
FIFO和Pipe一样,提供了双向进程间通信渠道。但要注意的是,无论是有名管道还是匿名管道,同一条管道只应用于单向通信,否则可能出现通信混乱(进程读到自己发的数据)。
有名管道可以用于任何进程之间的通信。
mkfifo函数
函数原型:int mkfifo(const char *pathname, mode_t mode);
用于创建有名管道。该函数可以创建一个路径为pathname的FIFO专用文件,mode指定了FIFO的权限,FIFO的权限和它绑定的文件是一致的。FIFO和pipe唯一的区别在于创建方式的差异。一旦创建了FIFO专用文件,任何进程都可以像操作文件一样打开FIFO,执行读写操作。
pathname 有名管道绑定的文件路径
mode 有名管道绑定文件的权限 通过三位八进制数据分别表示所有者,同组内,使用者的权限,与创建文件时设置文件的权限相同。
创建两个c文件分别为fifo_write.c和fifo_read.c作为发送端和接收端
发送端如下
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int fd,tmp;
char fifopath[] = "/tmp/fifo";
//和匿名管道不同的是,有名管道需要文件路径,以便不同进程都可以访问,比匿名管道更加通用
tmp = mkfifo(fifopath,0666);
handle_error("mkfifo",tmp);
fd = open(fifopath,O_WRONLY);
handle_error("open",fd);
char read_buf[30];
while (read(STDIN_FILENO,read_buf,30))
{
write(fd,read_buf,strlen(read_buf));
}
printf("fifo发送端退出\n");
close(fd);
return 0;
}
接收端如下
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
//其他任何进程都可以通过唯一路径和管道建立联系
char fifopath[] = "/tmp/fifo";
int fd,tmp;
fd = open(fifopath,O_RDONLY);
handle_error("openfifo",fd);
char read_buf[30];
while (read(fd,read_buf,30))
{
write(STDOUT_FILENO,read_buf,strlen(read_buf));
}
printf("fifo接收端退出\n");
close(fd);
return 0;
}
分别在两个终端下分别运行发送端和接收端程序,发送端运行结果如下
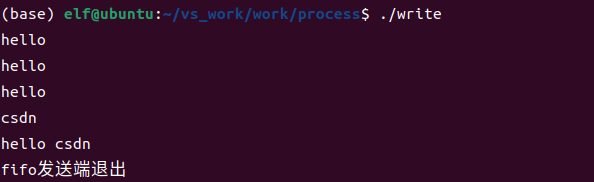
接收端运行结果如下
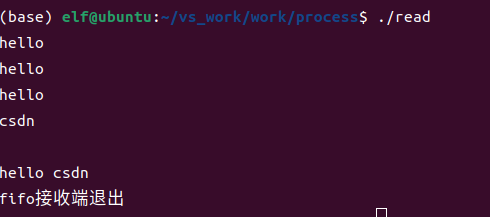
在按下ctrl+D,会使read接收到0个字符,返回值为0,就会跳出循环。
但是如果再次运行该程序就会提示该fifo已经存在,这是因为创建有名管道时,我们同时创建了一个fifo专用文件,在上述案例中是/tmp/myfifo,这实际上就是fifo专用文件在文件系统的路径。程序执行完之后并没有清除掉该文件。所以有名管道使用完成之后,应该调用unlink清除相关资源,这个函数只用调用一次,因为文件可以打开很多次,关闭很多次,但是清除(删除)只需要一次。
unlink函数原型为int unlink(const char *pathname);
作用是从文件系统中清除一个名称及其链接的文件。
只有有名管道需要调用unlink清除,匿名管道不需要,因为匿名管道虽然依靠文件描述符通信但是并没有生成真正的文件。
更改后的fifo_write.c内容如下
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int fd,tmp;
char fifopath[] = "/tmp/fifo";
tmp = mkfifo(fifopath,0666);
handle_error("mkfifo",tmp);
fd = open(fifopath,O_WRONLY);
handle_error("open",fd);
char read_buf[30];
while (read(STDIN_FILENO,read_buf,30))
{
write(fd,read_buf,strlen(read_buf));
}
printf("fifo发送端退出\n");
close(fd);
tmp = unlink(fifopath);
handle_error("unlink",tmp);
return 0;
}
调用open()打开有名管道时,flags设置为O_WRONLY则当前进程用于向有名管道写入数据,设置为O_RDONLY则当前进程用于从有名管道读取数据。也就是匿名管道中提到的写入端要关闭读功能,读端要关闭写入功能,避免数据错乱。设置为O_RDWR从技术上是可行的,但正如上文提到的,此时管道既读又写很可能导致一个进程读取到自己发送的数据,通信出现混乱。因此,打开有名管道时,flags只应为O_WRONLY或O_RDONLY。
内核为每个被进程打开的FIFO专用文件维护一个管道对象。当进程通过FIFO交换数据时,内核会在内部传递所有数据,不会将其写入文件系统。因此,/tmp/myfifo文件大小始终为0,但是在程序运行过程中,可以在该路径下看见该文件。
共享内存
共享内存就是一个内存共享对象,可以像使用文件描述符操控文件那样使用他,对其进行读取/写入操作,由此也就可以进行进程之间的通信。
涉及到的函数如下
shm_open函数
原型为int shm_open(const char *name, int oflag, mode_t mode);
const char *name: 这是共享内存对象的名称,直接写一个文件名称,本身会保存在 /dev/shm。名称必须是唯一的,以便不同进程可以定位同一个共享内存段。命名规则:必须是以正斜杠/开头,以\0结尾的字符串,中间可以包含若干字符,但不能有正斜杠
int oflag: 打开模式 二进制可拼接
(1) O_CREAT:如果不存在则创建新的共享内存对象
(2) O_EXCL:当与 O_CREAT 一起使用时,如果共享内存对象已经存在,则返回错误(避免覆盖现有对象)
(3) O_RDONLY:以只读方式打开
(4) O_RDWR:以读写方式打开
(5) O_TRUNC 用于截断现有对象至0长度(只有在打开模式中包含 O_RDWR 时才有效)。
mode_t mode: 当创建新共享内存对象时使用的权限位,和创建文件时设置权限一样,一般0644即可,如果没有设置O_CREAT,此处填0即可
return: 成功执行,它将返回一个新的描述符;发生错误,返回值为 -1
shm_unlink函数
函数原型为int shm_unlink(const char *name);
删除一个先前由 shm_open() 创建的命名共享内存对象。尽管这个函数被称为“unlink”,但它并没有真正删除共享内存段本身,而是移除了与共享内存对象关联的名称,使得通过该名称无法再打开共享内存。当所有已打开该共享内存段的进程关闭它们的描述符后,系统才会真正释放共享内存资源,类似于fifo中提到的unlink
char *name: 要删除的共享内存对象名称
return: 成功返回0 失败返回-1
truncate()和ftruncate()
truncate和ftruncate都可以将文件缩放到指定大小,二者的行为类似:如果文件被缩小,截断部分的数据丢失,如果文件空间被放大,扩展的部分均为\0字符。缩放前后文件的偏移量不会更改。缩放成功返回0,失败返回-1。
不同的是,前者需要指定路径,而后者需要提供文件描述符;ftruncate缩放的文件描述符可以是通过shm_open()开启的内存对象,而truncate缩放的文件必须是文件系统已存在文件,若文件不存在或没有权限则会失败。
truncate的函数原型为int truncate(const char *path, off_t length);
作用是将指定文件扩展或截取到指定大小
char *path: 文件名 指定存在的文件即可 不需要打开
off_t length: 指定长度 单位字节
return: int 成功 0,失败 -1
ftruncate的函数原型为int ftruncate(int fd, off_t length);
作用是将指定文件描述符扩展或截取到指定大小
int fd: 文件描述符 需要打开并且有写权限
off_t length: 指定长度 单位字节
return: int 成功 0,失败 -1
mmap()函数
mmap系统调用可以将一组设备或者文件映射到内存地址,我们在内存中寻址就相当于在读取这个文件指定地址的数据。父进程在创建一个内存共享对象并将其映射到内存区后,子进程可以正常读写该内存区,并且父进程也能看到更改。
mmap函数的函数原型为
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
作用是将文件映射到内存区域,进程可以直接对内存区域进行读写操作,就像操作普通指针一样,但实际上是对文件或设备进行读写,从而实现高效的 I/O 操作
void *addr: 指向期望映射的内存起始地址的指针,通常设为 NULL,让系统选择合适的地址
size_t length: 要映射的内存区域的长度,以字节为单位
int prot: 内存映射区域的保护标志,可以是以下标志的组合
(1) PROT_READ: 允许读取映射区域
(2) PROT_WRITE: 允许写入映射区域
(3) PROT_EXEC: 允许执行映射区域
(4) PROT_NONE: 页面不可访问
int flags:映射选项标志
(1) MAP_SHARED: 映射区域是共享的,对映射区域的修改会影响文件和其他映射到同一区域的进程(一般使用共享)
(2) MAP_PRIVATE: 映射区域是私有的,对映射区域的修改不会影响原始文件,对文件的修改会被暂时保存在一个私有副本中
(3) MAP_ANONYMOUS: 创建一个匿名映射,不与任何文件关联
(4) MAP_FIXED: 强制映射到指定的地址,如果不允许映射,将返回错误
int fd: 文件描述符,用于指定要映射的文件或设备,如果是匿名映射,则传入无效的文件描述符(例如-1)
off_t offset: 从文件开头的偏移量,映射开始的位置
return void*: (1) 成功时,返回映射区域的起始地址,可以像操作普通内存那样使用这个地址进行读写
(2) 如果出错,返回 (void *) -1,并且设置 errno 变量来表示错误原因
munmap()函数
函数原型为int munmap(void *addr, size_t length);
作用是用于取消之前通过 mmap() 函数建立的内存映射关系
void *addr: 这是指向之前通过 mmap() 映射的内存区域的起始地址的指针,这个地址必须是有效的,并且必须是 mmap() 返回的有效映射地址
size_t length: 这是要解除映射的内存区域的大小(以字节为单位),它必须与之前通过 mmap() 映射的大小一致
return: int 成功 0, 失败 -1
创建流程
创建一块共享内存一般有以下几个步骤
1 开辟一个共享内存
2 设置共享内存的大小
3 内存映射,将内存映射到指针地址,绑定,
映射区建立完毕,共享内存已经映射到了程序的内存上即指针地址,close掉共享内存对应的文件描述符 注意不是删除
此处关闭的只是文件描述符,并没有删除共享内存文件,后续munmap也用不到文件描述符
也可以将close放到后边,防止共享内存的资源被意外释放。
4 进行进程之间通讯
5 munmap释放映射区,将用户区的指针地址和共享内存解绑,并不是释放共享内存
如果创建了子进程,父子进程都要解除映射,因为子进程会继承父进程的映射,创建子进程之后,父子进程会单独管理内存映射
6 shm_unlink释放共享内存对象
只需要执行一次即可,这个操作会删除共享内存对应的临时文件,只需要一次,在调用之后,当所有已打开该共享内存段的进程解除映射并关闭它们的描述符之后,系统才会真正释放共享内存资源。
例程
创建一个shm_write.c和shm_read.c分别实现发送端和接收端功能,发送端发送数据,接收端每次读取一次数据。
shm_write.c如下
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <string.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int fd,tmp;
char shmpath[] = "/myshm";
//此处需要使用O_RDWR打开,因为mmap中设置PORT_WRITE需要读写权限都打开
fd = shm_open(shmpath,O_RDWR | O_CREAT,0666);
handle_error("shm_open",fd);
tmp = ftruncate(fd,100);
char *shm_write_buf = NULL;
shm_write_buf = mmap(NULL,100,PROT_WRITE,MAP_SHARED,fd,0);
if (shm_write_buf == MAP_FAILED)
{
perror("map_failed");
exit(EXIT_FAILURE);
}
while (read(STDIN_FILENO,shm_write_buf,30))
{
}
printf("共享内存的发送端程序退出\n");
tmp = munmap(shm_write_buf,100);
close(fd);
tmp = shm_unlink(shmpath);
handle_error("unlink",tmp);
return 0;
}
shm_read.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <string.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
int fd,tmp;
char shmpath[] = "/myshm";
fd = shm_open(shmpath,O_RDWR,0);
char *shm_read_buf = NULL;
shm_read_buf = mmap(NULL,100,PROT_READ,MAP_SHARED,fd,0);
printf("%s",shm_read_buf);
tmp = munmap(shm_read_buf,100);
handle_error("munmap",tmp);
close(fd);
return 0;
}
先在一个终端内运行shm_write.c写入数据,在另一个终端内再运行shm_read.c

![]()
消息队列
MQ(全称Message Queue)是一种进程间通信或同一进程的不同线程间的通信方式,队列就是一个消息容器,消息队列本身是一种先进后出的结构,数据从一端进入后从另外一端读取。我们将消息队列称之为中间件,消息队列不存储消息内容的本身,它只是消息的搬运工。在FreeRTOS和linux中都涉及到了消息队列的使用。在linux中我们需要通过文件描述符来使用消息队列,就像操控文件一样,这点和共享内存相似,都是创建一个临时文件。
相关数据类型
mqd_t该数据类型定义在mqueue.h中,是用来记录消息队列描述符的。
typedef int mqd_t;其实也就是int类型
该结构体包含消息队列的属性信息
struct mq_attr {
long mq_flags; //调用mq_open时可以忽略他,因为这个标记是通过mq_open设置的
long mq_maxmsg; //消息的最大容量,最大存储多少条消息
long mq_msgsize; //单条消息的最大容量,单位字节
long mq_curmsgs; // 当前队列中的消息条数
};
该结构体描述了UNIX的时间戳
struct timespec {
time_t tv_sec; //秒
long tv_nsec; //纳秒
};
mq_open()函数
函数原型为mqd_t mq_open(const char *name, int oflag, mode_t mode, struct mq_attr *attr);
作用是创建或打开一个已存在的POSIX消息队列,消息队列是通过名称唯一标识的。
参数一:消息队列的名称。必须是以正斜杠/开头,以\0结尾的字符串,中间可以包含若干字符,但不能有正斜杠
参数二:指定消息队列的控制权限,必须也只能包含以下三者之一
O_RDONLY 打开的消息队列只用于接收消息
O_WRONLY 打开的消息队列只用于发送消息
O_RDWR 打开的消息队列可以用于收发消息
可以与以下选项中的0至多个或操作之后作为oflag
O_CLOEXEC 设置close-on-exec标记,这个标记表示执行exec时关闭文件描述符
O_CREAT 当文件描述符不存在时创建它,如果指定了这一标记,需要额外提供mode和attr参数
O_EXCL 创建一个当前进程独占的消息队列,要同时指定O_CREAT,要求创建的消息队列不存在,否则将会失败,并提示错误EEXIST
O_NONBLOCK 以非阻塞模式打开消息队列,如果设置了这个选项,在默认情况下收发消息发生阻塞时,会转而失败,并提示错误EAGAIN
参数三:每个消息队列在mqueue文件系统对应一个文件,mode是用来指定消息队列对应文件的权限的
参数四:属性信息,如果为NULL,则队列以默认属性创建
返回值为mqd_t类型 成功则返回消息队列描述符,失败则返回(mqd_t)-1,同时设置errno以指明错误原因
当flag没有设置O_CREAT时,即打开一个已经存在的消息队列,则后续两个参数可以不填。
mq_timedsend()函数
函数原型为int mq_timedsend(mqd_t mqdes, const char *msg_ptr, size_t msg_len, unsigned int msg_prio, const struct timespec *abs_timeout);
作用是将msg_ptr指向的消息追加到消息队列描述符mqdes指向的消息队列的尾部(写入一条消息)。如果消息队列已满,默认情况下,调用阻塞直至有充足的空间允许新的消息入队,或者达到abs_timeout指定的等待时间节点,或者调用被信号处理函数打断。需要注意的是,正如上文提到的,如果在mq_open时指定了O_NONBLOCK标记,则转而失败,并返回错误EAGAIN。
参数一:消息队列描述符
参数二:指向消息的指针
参数三:指向的消息长度,不能超过队列的mq_msgsize属性指定的单条消息最大容量,长度为0的消息是被允许的
参数四:一个非负整数,指定了消息的优先级,消息队列中的数据是按照优先级降序排列的,如果新旧消息的优先级相同,则新的消息排在后面。
参数五:指向struct timespec类型的对象,指定了阻塞等待的最晚时间。如果消息队列已满,且abs_timeout指定的时间节点已过期,则调用立即返回。
返回值为int类型,成功返回0,失败返回-1,同时设置errno以指明错误原因。
mq_send()则没有超时机制,取决于打开的方式,可为无限阻塞或者非阻塞
mq_timedreceive()函数
函数原型为ssize_t mq_timedreceive(mqd_t mqdes, char *msg_ptr, size_t msg_len, unsigned int *msg_prio, const struct timespec *abs_timeout);
作用是从消息队列中取走最早入队且权限最高的消息(读出一条消息),将其放入msg_ptr指向的缓存中。如果消息队列为空,默认情况下调用阻塞,此时的行为与mq_timedsend同理。
参数一:消息队列描述符
参数二:接收消息的缓存
参数三:指向的缓存区的大小,必须大于等于mq_msgsize属性指定的队列单条消息最大字节数
参数四:如果不为NULL,则用于接收接收到的消息的优先级
参数五:阻塞时等待的最晚时间节点,同mq_timedsend
返回值:成功则返回接收到的消息的字节数,失败返回-1,并设置errno指明错误原因
mq_receive()函数则没有超时机制,取决于打开的方式,要么为无限阻塞要么为非阻塞
mq_unlink()函数
函数原型为int mq_unlink(const char *name);
作用是清除name对应的消息队列,mqueue文件系统中的对应文件被立即清除(在该进程中清除其文件描述符)。消息队列本身的清除必须等待所有指向该消息队列的描述符全部关闭之后才会发生。
参数:消息队列名称
返回值:成功返回0,失败返回-1,并设置errno指明错误原因
clock_gettime()函数
函数原型为int clock_gettime(clockid_t clockid, struct timespec *tp);
作用是获取以struct timespec形式表示的clockid指定的时钟
clockid 特定时钟的标识符,常用的是CLOCK_REALTIME,表示当前真实时间的时钟
tp 用于接收时间信息的缓存
成功返回0,失败返回-1,同时设置errno以指明错误原因
一般用于发送、接收函数之前,获取当前时间,然后对结构体中的时间进行修改,代表发送、接收函数阻塞的最晚时间。例如设置最多阻塞5s,则获取时间结构体后,对其中的tv_sec成员+5即可。
例程
创建一个mq_write.c程序和一个,mq_read.c程序,分别实现发送和接收的功能,约定crtl+d为结束信号。
mq_write.c内容如下
#include <fcntl.h>
#include <sys/stat.h>
#include <mqueue.h>
#include <stdio.h>
#include <time.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
struct mq_attr attr = {0};
attr.mq_flags = 0;
attr.mq_curmsgs = 0;
attr.mq_msgsize = 128;//设置单条消息的大小,单位字节。注意不要超过系统限制,一般最大为8192
attr.mq_maxmsg = 5;//设置消息的最大数量。注意不要超过系统限制,一般最大为10
mqd_t mq_fd;
int tmp;
char *mq_name = "/mymq";
mq_fd = mq_open(mq_name,O_CREAT | O_RDWR,0666,&attr);
handle_error("mq_open",mq_fd);
char mq_write_buf[128];//缓冲区要大于等于设置的单条消息的大小
struct timespec time;
clock_gettime(CLOCK_REALTIME,&time);//获取当前时间戳
time.tv_sec += 5;//代表发送时间为5s,超过5s未发送成功即报错
//从控制台读取ctrl+d后,读取个数为0,跳出循环
while (tmp = read(STDIN_FILENO,mq_write_buf,128))
{
if(tmp > 0)
printf("从控制台接收到数据\n");
tmp = mq_timedsend(mq_fd,mq_write_buf,strlen(mq_write_buf),0,&time);
if(tmp == 0)
printf("发送端发送成功\n");
handle_error("send",tmp);
}
//发送结束信号,发送0个数据
tmp = mq_timedsend(mq_fd,mq_write_buf,0,0,&time);
if(tmp == 0)
printf("发送端发送结束信号成功\n");
printf("消息队列发送端退出\n");
close(mq_fd);
//mq_unlink只需要调用一次,当所有进程都释放了和这个消息队列有关的文件描述符之后才会释放资源
tmp = mq_unlink(mq_name);
handle_error("unlink",tmp);
return 0;
}
mq_read.c程序如下
#include <fcntl.h>
#include <sys/stat.h>
#include <mqueue.h>
#include <stdio.h>
#include <time.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#define handle_error(cmd,result) \
if(result < 0) \
{ \
perror(cmd); \
exit(EXIT_FAILURE); \
} \
int main(int argc, char const *argv[])
{
char mq_name[] = "/mymq";
struct mq_attr attr = {0};
attr.mq_curmsgs = 0;
attr.mq_flags = 0;
attr.mq_msgsize = 128;
attr.mq_maxmsg = 5;
mqd_t mq_fd;
int tmp;
char mq_read_buf[128];//缓冲区要大于等于设置的单条消息的大小
//发送端已经创建了消息队列,这里只需要以只读方式打开即可
mq_fd = mq_open(mq_name,O_RDONLY);
handle_error("mq_open",mq_fd);
struct timespec time;
clock_gettime(CLOCK_REALTIME,&time);//获取当前时间戳
time.tv_sec += 86400;//设置一个很长的时间,表示一直等待发送端发送消息
//当接收到0个数据时即为结束信号,跳出循环
while (tmp = mq_timedreceive(mq_fd,mq_read_buf,128,NULL,&time))
{
handle_error("send",tmp);
printf("%s",mq_read_buf);
}
printf("消息队列接收端退出\n");
close(mq_fd);
return 0;
}
在一个终端内运行mq_write.c,另外一个终端运行mq_read.c
发送端运行结果如下
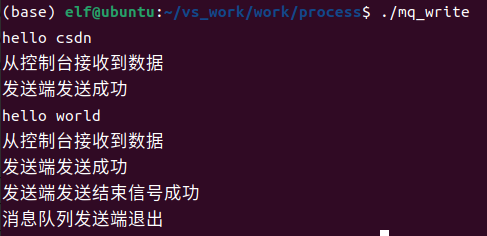
接收端运行结果如下
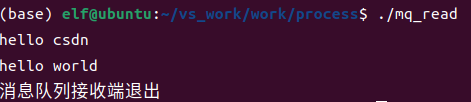
在发送端循环发送数据,接收端可以接收到消息,按下ctrl+d之后,发送端从控制台接收到0个数据,跳出while循环,之后发送一条包含0个数据的消息到接收端,接收端的接收函数会返回接收到的数据个数,接收到0之后跳出while循环,程序结束。
我们可以通过设置POSIX消息队列的模式为O_RDWR,使它可以用于收发数据,从技术上讲,单条消息队列可以用于双向通信,但是这会导致消息混乱,无法确定队列中的数据是本进程写入的还是读取的,因此,不会这么做,通常单条消息队列只用于单向通信。为了实现全双工通信,我们可以使用两条消息队列,分别负责两个方向的通信。类似于管道。
总结进程间通信
上述共介绍了四种进程间的通信方式,分别为匿名管道,有名管道,共享内存和消息队列,其中匿名管道只能用于父子进程间的通信,因为其只能通过创建的文件描述符进行通信,只有父子进程之间可以继承到,其他进程无法获取到相关的资源。其余三种通信方式既可用于父子进程通信,也可以用作任何两个进程间的通信,因为他们都拥有一个唯一标识,会创建一个临时文件用于进程访问。
还有另外一种可以用于进程间的通信方式,套接字,套接字一般用于网络通信,后续演变为进程间的一种通信方式,本文暂时不做介绍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









