






一、前置知识
1.常见的三种算法
- UUID:基于时间戳、MAC地址、随机数等生成128位唯一值,通常以32位十六进制字符串表示
- Snowflake(雪花算法):生成64位二进制数,最终转为十进制展示
- 自增id:单机或分布式环境下单调递增的数值,如MySQL的
AUTO_INCREMENT或Redis的INCR命令。
2.JWT技术
JWT 由三部分组成:
- Header:记录所使用的算法。
- Payload:记录用户相关信息。
- Verify Signature:用于验签,以验证整个 token 的有效性。
JWT 的 Header 和 Payload 采用 Base64 算法,与 Base32 类似,近乎明文传输,那么如何防止他人伪造、篡改 token 呢?为解决这一问题,JWT 引入了第三部分—— 验证签名。该签名借助一个密钥,结合 Header 和 Payload,利用 MD5 或 RSA 算法生成。因此:
- 只要密钥不泄露,他人就无法伪造签名,进而无法伪造 token。
- 若有人篡改了 token,验签时会依据 header 和 payload 重新计算签名。由于数据被篡改,计算得到的签名必然不一致,此时 token 即为无效。
3.BitMap(位图)
底层实现
-
原理:每个bit位映射一个状态(如0/1),1字节可存储8个状态。
-
Redis实现:
- 最大支持512MB,即约42.9亿bit位(2^32)。
- 指令:
SETBIT、GETBIT、BITCOUNT等。
应用场景
- 用户签到统计。
- 布隆过滤器(判断元素是否存在)。
- 兑换码状态管理:每个bit位对应一个自增ID的兑换状态。
二、兑换码生成算法
问题引入: 优惠劵领取方式可以有两种(手动发放、指定发放),指定发放模式下指的是利用生成的兑换码兑换优惠劵,因此我们需要在优惠劵发放的同时生成兑换码。兑换码应该如何生成?是否是一个简单的字符串就可以?
兑换码格式如图:

1.兑换码的需求
- 良好的可读性: 长度不超过十个字符;只能是24个大写字母和8个数字(排出了系混淆的字母(I、O)和数字(0、1))
- 数据量大: 需满足10亿以上兑换码的需求
- 唯一性: 10亿兑换码都必须具备唯一性,不可出现重复的兑换码,否则会出现兑换混乱的情况
- 不重兑性: 可以通过兑换码判断是否兑换过,避免重复兑换
- 防爆刷: 兑换码的规律性不能很明显,不能轻易被人猜测到其它兑换码
- 高效性: 生成的效率和验证效率高,避免对数据库带来较大的压力
2.算法分析
2.1.Base32转码
若将24个字母和8个数字放到数组中,如下:
| 角标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F | G | H | J | K | L | M | N | P | Q | R |
| 角标 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 字符 | S | T | U | V | W | X | Y | Z | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
0 ~ 31的角标刚好对应32个字符,而2^5刚好为32,因此5位二进制数的范围就是0 ~ 31。
因此,只要我们让数字转为二进制的形式,然后每5个二进制位为一组,转10进制的结果是不是刚好对应一个角标,就能找到一个对应的字符。这样就将一个数字转为我们想要的字符个数了。
这种把二进制数经过加密得到字符的算法就是Base32法,类似的还有Base64法。
举例说明:若我们经过自增id计算出一个复杂数字,转为二进制,并每5位一组,结果如下:
01001 00010 01100 10010 01101 11000 01101 00010 11110 11010
此时,我们看看每一组的结果:
- 01001转10进制是9,查数组得字符为:K
- 00010转10进制是2,查数组得字符为:C
- 01100转10进制是12,查数组得字符为:N
- 10010转10进制是18,查数组得字符为:B
- 01101转10进制是13,查数组得字符为:P
- 11000转10进制是24,查数组得字符为:2
- ...
依此类推,最终那一串二进制数得到的结果就是KCNBP2PC84,刚好符合我们的需求。
但是最终要求字符不能超过10位,而每个字符对应5个bit位,因此二进制数不能超过50个bit位。UUID和Snowflake算法得到的结果,一个是128位,一个是64位,都远远超出了我们的要求,因此排除。
那自增id算法是否符合需求?
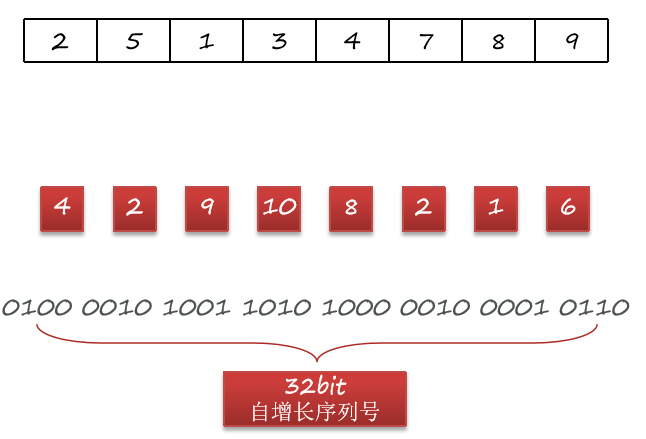
自增id从1增加到Integer的最大值,可以达到40亿以上个数字,而占用的字节仅仅4个字节,也就是32个bit位,距离50个bit位的限制还有很大的剩余,符合要求!Redis是单线程的,因此利用Redis生成自增id不会产生重复,满足唯一性。
综上,利用自增id作为兑换码,但是要利用Base32加密,转为我们要求的格式。此时满足:
- 良好的可读性:可以转为要求的字母和数字的格式,长度还不超过10个字符
- 数据量大:可以应对40亿以上的数据规模
- 唯一性:自增id,绝对唯一
2.2.重兑校验算法
兑换码的状态(已兑换和未兑换)可以用0和1表示,因此使用1bit进行标识状态,当n个兑换码时则需要nbit进行标识其状态,因此可以根据自增id的顺序进行排列,比如自增id为1则状态标识在第1个比特位,自增id为2则状态标识在第2个比特位,以此类直到最大值2^32,由此可以满足其不可重兑性。
-
基于数据库:在设计数据库时有一个字段就是标示兑换码状态,每次兑换时可以到数据库查询状态,避免重兑。
- 优点:简单
- 缺点:对数据库压力大
-
基于BitMap:兑换或没兑换就是两个状态,对应0和1,而兑换码使用的是自增id.我们如果每一个自增id对应一个bit位,用每一个bit位的状态表示兑换状态,可以完美解决问题。而这种算法恰好就是BitMap的底层实现,而且Redis中的BitMap刚好能支持2^32个bit位。
- 优点:简答、高效、性能好
- 缺点:依赖于Redis
综上,BitMap。此时满足重兑和高效。
2.3.防暴刷校验算法
50位,自增id占32位,使用密钥对自增id进行加密=签名,签名+自增id=50位的bit。
我们也可以模拟JWT的思路:
- 首先准备一个秘钥
- 然后利用秘钥对自增id做加密,生成签名
- 将签名、自增id利用Base32转码后生成兑换码
只要秘钥不泄露,就没有人能伪造兑换码。只要兑换码被篡改,就会导致验签不通过。
由于我们的兑换码核心是自增id,也就是数字,因此这里采用按位加权的签名算法:
- 将自增id(32位)每4位分为一组,共8组,都转为10进制
- 每一组给不同权重
- 把每一组数加权求和,得到的结果就是签名
举例:
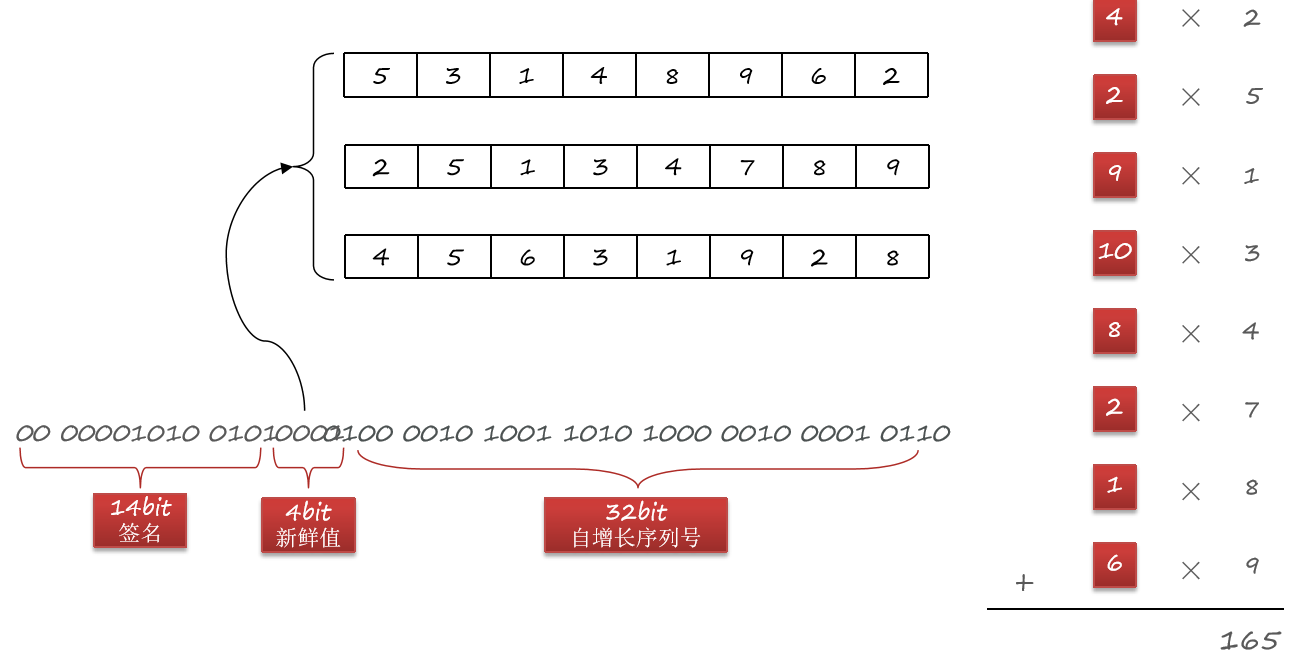
最终的加权和就是:42 + 25 + 91 + 103 + 84 + 27 + 18 + 69 = 165 ,这里的权重数组就可以理解为加密的秘钥。
为了避免秘钥被人猜测出规律,我们可以准备16组秘钥。在兑换码自增id前拼接一个4位的新鲜值,可以是随机的。这个值是多少,就取第几组秘钥。这样就进一步增加了兑换码的复杂度。最后再把加权的和也就是签名转为二进制14bit位拼在前面。
3.小结
兑换码生成算法:
- 利用Redis自增来生成序列号s,作为兑换码的唯一标示
- 利用优惠券id的后4位做新鲜值f,从密钥列表得到密钥
- 将f拼接s,利用密钥加密,取后14位得到签名c
- 将c、f、s拼接,利用Base32编码,得到最终兑换码
如何校验兑换码:
- 从要校验的兑换码中分别获取f、c、s
- 再次利用生成算法,得到签名c2
- 将c2与c1比较,一致则认为是有效兑换码
- 兑换码使用过后,利用BitMap标记序列号s对应位为1,用于下次校验兑换码是否已经使用过
生成兑换码的数量可能较多,比较耗时,因此推荐使用异步线程池生成兑换码来优化性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









