






Shapefile(.shp):
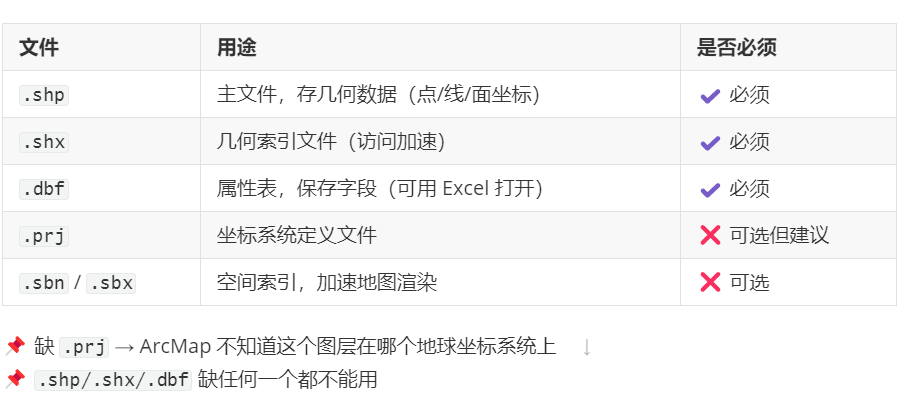
根本错误原因:
Shapefile 的属性数据 .dbf 是老旧格式,默认不含编码信息
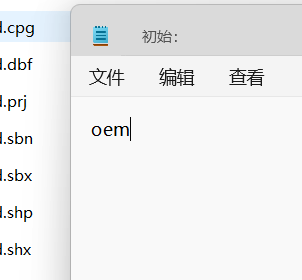
解决方法:
在shapefile文件夹目录上,创建一个同名的.cpg文件,内容"oem"
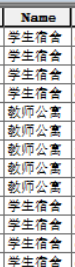
使用ArcGIS再右键打开属性表,正确编码✅

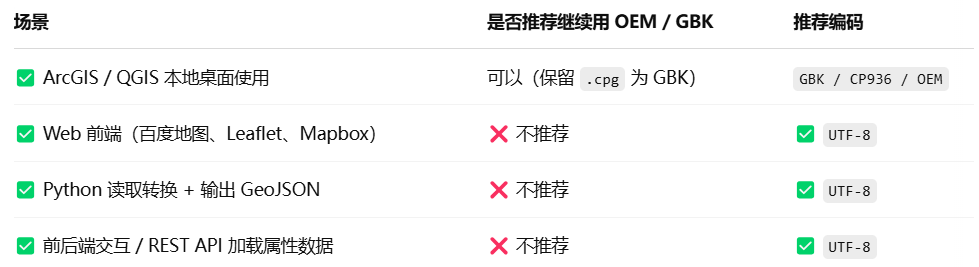
用于解决中文编码错误的shapefile_2_geojson脚本:
ps 代码不是通用模板,根据你的需求进行调整
import geopandas as gpd
import os
import json
from pyproj import CRS
import warnings
import codecs
warnings.filterwarnings('ignore')
def convert_shp_to_geojson(shp_path, output_path):
"""
将 Shapefile 转换为 WGS84 坐标系的 GeoJSON
参数:
shp_path: Shapefile 文件路径
output_path: 输出 GeoJSON 文件路径
"""
print(f"正在处理: {shp_path}")
try:
# 检查是否存在CPG文件,如果不存在则创建
cpg_path = shp_path.replace('.shp', '.cpg')
if not os.path.exists(cpg_path):
print("未找到CPG文件,创建CPG文件指定编码为GBK")
with open(cpg_path, 'w') as f:
f.write("GBK")
else:
# 读取现有CPG文件内容
with open(cpg_path, 'r') as f:
encoding = f.read().strip()
print(f"检测到CPG文件,编码为: {encoding}")
# 读取CPG文件获取编码
with open(cpg_path, 'r') as f:
encoding = f.read().strip()
print(f"使用编码 {encoding} 读取Shapefile")
# 使用CPG中指定的编码读取Shapefile
gdf = gpd.read_file(shp_path, encoding=encoding)
# 检查坐标系
if gdf.crs is None:
print("警告: 未检测到坐标系,尝试从 .prj 文件解析")
# 尝试从 .prj 文件读取坐标系
prj_path = shp_path.replace('.shp', '.prj')
if os.path.exists(prj_path):
with open(prj_path, 'r') as f:
prj_text = f.read()
try:
crs = CRS.from_wkt(prj_text)
gdf.set_crs(crs, inplace=True)
print(f"从 .prj 文件解析坐标系: {crs.name}")
except Exception as e:
print(f"解析 .prj 文件失败: {str(e)}")
# 假设为北京54投影坐标系
gdf.set_crs("+proj=tmerc +lat_0=0 +lon_0=117 +k=1 +x_0=500000 +y_0=0 +ellps=krass +units=m +no_defs", inplace=True)
print("已设置为默认北京54投影坐标系(3度带,中央经线117°)")
else:
# 假设为北京54投影坐标系
gdf.set_crs("+proj=tmerc +lat_0=0 +lon_0=117 +k=1 +x_0=500000 +y_0=0 +ellps=krass +units=m +no_defs", inplace=True)
print("未找到 .prj 文件,已设置为默认北京54投影坐标系(3度带,中央经线117°)")
# 输出原始坐标系信息
print(f"原始坐标系: {gdf.crs}")
# 转换为 WGS84 坐标系 (EPSG:4326)
if gdf.crs.to_epsg() != 4326:
print("转换坐标系为 WGS84 (EPSG:4326)")
gdf = gdf.to_crs(epsg=4326)
# 处理二进制数据
for col in gdf.columns:
if col == 'geometry':
continue
# 处理bytes类型数据
gdf[col] = gdf[col].apply(
lambda x: x.decode(encoding, errors='replace') if isinstance(x, bytes) else str(x) if x is not None else None
)
# 转换为 GeoJSON - 移除不支持的force_ascii参数
geojson_str = gdf.to_json()
geojson_data = json.loads(geojson_str)
# 保存 GeoJSON 文件,添加 BOM 标记
with codecs.open(output_path, 'w', encoding='utf-8-sig') as f:
json.dump(geojson_data, f, ensure_ascii=False, indent=2)
print(f"成功转换并保存到: {output_path}")
print(f"使用 UTF-8 with BOM 编码保存,确保中文正确显示")
return True
except Exception as e:
print(f"转换失败: {str(e)}")
import traceback
traceback.print_exc()
return False
if __name__ == "__main__":
# 设置 Shapefile 文件夹路径
shp_folder = r"你的路径"
output_folder = r"你的路径"
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 获取所有 .shp 文件
shp_files = [f for f in os.listdir(shp_folder) if f.endswith('.shp')]
print(f"找到 {len(shp_files)} 个 Shapefile 文件")
# 转换每个文件
for shp_file in shp_files:
shp_path = os.path.join(shp_folder, shp_file)
output_path = os.path.join(output_folder, shp_file.replace('.shp', '.geojson'))
convert_shp_to_geojson(shp_path, output_path)
















 3399
3399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









