







1、缓存穿透
1.1、问题描叙
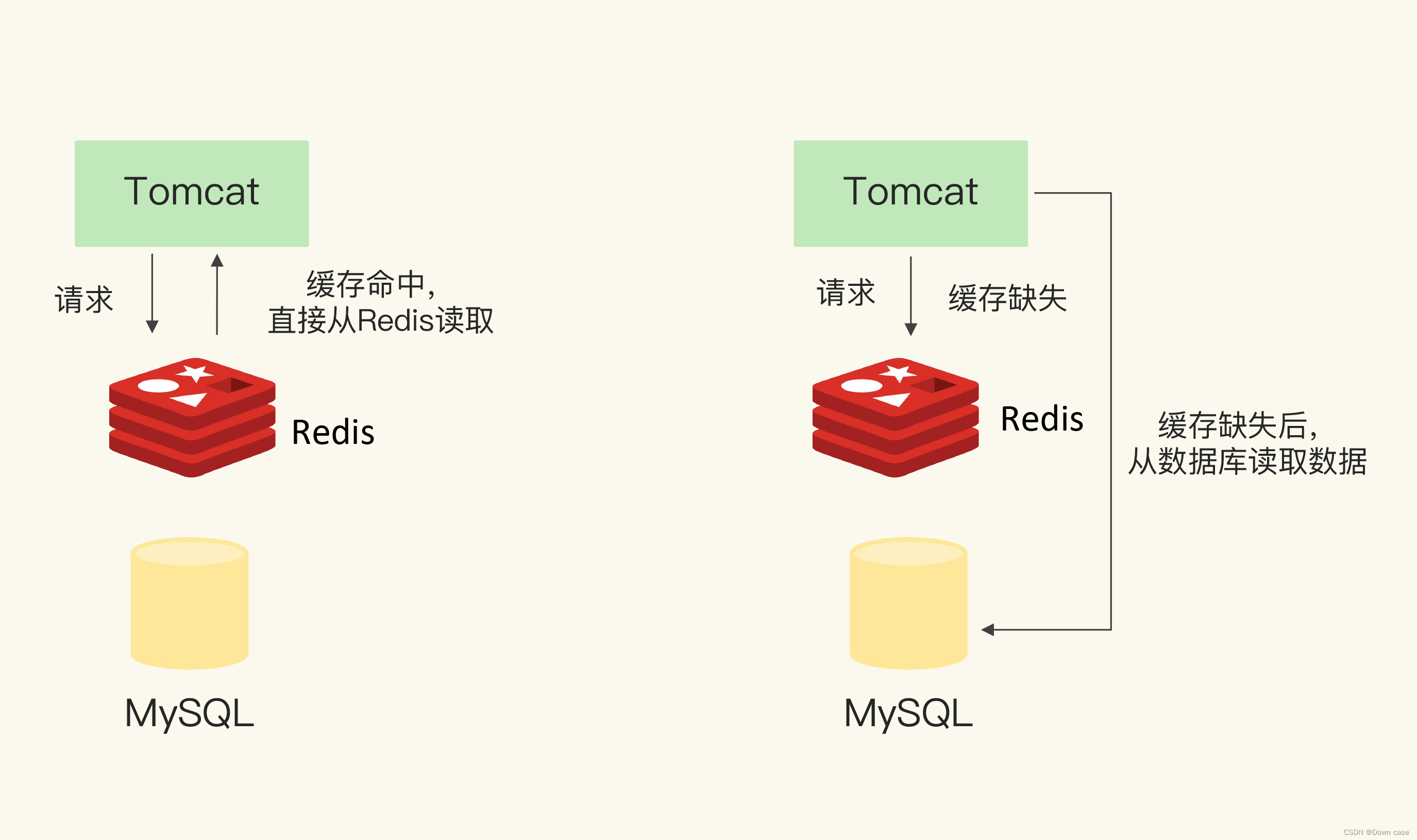
当系统中引入redis
缓存后,一个请求进来后,会先从
redis
缓存中查询,缓存有就直接返回,缓存中没 有就去db
中查询,
db
中如果有就会将其丢到缓存中,但是有些
key
对应更多数据在
db
中并不存在,
每次针对此次key的请求从缓存中取不到,请求都会压到
db
,从而可能压垮
db
。
比如用一个不存在的用户
id
获取用户信息,不论缓存还是数据库都没有,若黑客利用大量此类攻击可能压垮数据库
1.2、解决方案
(1)对空值缓存
如果一个查询返回的数据为空(不管数据库是否存在),我们仍然把这个结果(null
)进行缓存,给其设置一个很短的过期时间,最长不超过五分钟
(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









