






多刷题,有的时候比较考验脑洞。
多练习python。(python真要命)
misc中的任何文件都可以分离出点东西。(首先它得有点东西)
关于解压,工具最好多几个,有的时候winrar,不好使可以试试7z打开压缩包。
给一个空白的txt文档,可不是没东西,Ctrl+A 试试。
得到一个未知的的文件,就要搞清楚到底是什么文件
常用文件文件头:
JPEG (jpg) 文件头:FF D8 FF 文件尾:FF D9
PNG (png),文件头:89504E47
Windows Bitmap (bmp), 文件头:424D 文件尾:
GIF (gif),文件头:47494638
XML (xml),文件头:3C3F786D6C
HTML (html),文件头:68746D6C3E
MS Word/Excel (xls.or.doc),文件头:D0CF11E0
MS Access (mdb),文件头:5374616E64617264204A
Adobe Acrobat (pdf),文件头:255044462D312E
Windows Password (pwl),文件头:E3828596
ZIP Archive (zip),文件头:504B0304
RAR Archive (rar),文件头:52617221
Wave (wav),文件头:57415645
AVI (avi),文件头:41564920
TIFF (tif), 文件头:49492A00 文件尾:
TTL隐写:
题目中给的数据都是63,255,127,这样的数,就是TTL隐写,详情可以看这篇文章
直接上脚本:时间可能会有点长
import binascii
f = open('./attachment.txt', "r")
str = ''
Binary = ''
number = ''
while 1:
num = f.readline()
if not num:
break
if num.rstrip() == '63': # 去掉每行后面的空格
Binary = '00'
elif num.rstrip() == '127':
Binary = '01'
elif num.rstrip() == '191':
Binary = '10'
elif num.rstrip() == '255':
Binary = '11'
str += Binary
for i in range(0, len(str), 8):
number += chr(int(str[i:i + 8], 2))
data = binascii.unhexlify(number)
f2=open('1.txt','wb')
f2.write(data)
f2.close()snow隐写:
看这篇文章
outguess隐写:
图片详细信息等地方会有个字符串(密码)猜测是outguess隐写
outguess -k "密码" -r 图片名 out.txt
F5隐写:
下载工具看这篇文章
java Extract 文件路径 -p 密码
没有密码后面的就不用了
图片隐写:
最简单的隐写就是,把flag直接写入数据中。
还有的比较离谱就是对图片进行搜索字符串 strings 文件名 | grep 关键字
在图片属性中详细信息,会有提示。或者用winRAR打开压缩包,右侧栏中会有提示。
kali里的俩个工具binwalk(查看文件中有没有隐藏文件) ,
foremost(把隐藏文件分离出来)没思路的时候就试试呗 ,当他不好用时,还是得用binwalk
前提是进入root用户 指令 binwalk -e 文件名 --run-as=root
得到一堆图片,明显可以合并,有在线网站工具
有时候图片需要镜像翻转,这里就放一个工具。
杂项的图片题有的很逆天 比如,这你能看出啥

其实里面藏了张二维码。
有的二维码在某些图片上,就需要我们ps曝光
最简单的隐写就是宽高的修改。有俩种方法。1.在数据里改。2.在010中
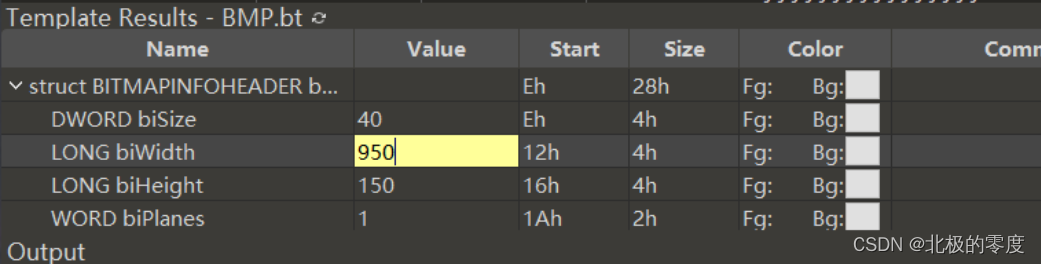
有时是gif格式的文件就需要我们把每张图片都改高度。
但是我们有时候不知道正确的宽高,并且会出想crc错误。
这里直接附上脚本。 高度不对
import os
import binascii
import struct
crcbp = open("misc26.png", "rb").read() #打开图片
for i in range(1024):
for j in range(1024):
data = crcbp[12:16] + struct.pack('>i', i)+struct.pack('>i', j)+crcbp[24:29]#从IHDR开始17个字节,其中宽和高用i和j代替,并以4个字节存放i和j。
crc32 = binascii.crc32(data) & 0xffffffff
if(crc32 == 0xec9ccbc6): #010Editor第二行倒数3字节,加第三行第一字节。按顺序写就行,不用改。
print(i, j)
print('hex:', hex(i), hex(j))
宽度不对
import struct
filename = "misc34.png"
with open(filename, 'rb') as f:
data = f.read()
for i in range(901,1200):
name = str(i) + ".png"
f1 = open(name,"wb")
new = data[:16]+struct.pack('>i',i)+data[20:]
f1.write(new)
f1.close()查看图片文件数据后,发现数据逆序了,跑脚本。这是一个每四位hex反转。
f1=open('task_flag.jpg','rb').read()
f1_len=len(f1)
f2=open('tt.jpg','ab')
i=0
while i<f1_len:
f2.write(f1[i:i+4][::-1])
i=i+4
f2.close()有时候做题时会得到俩张一模一样的图片,这时就需要我们合并,然后使用stegsolvs打开,Analyse→Image Combiner。
从文件中获取的压缩包,简单的暴力破解无果后,密钥就藏在文件中。
多尝试放入010Editor,你觉得不可能恰恰是答案。
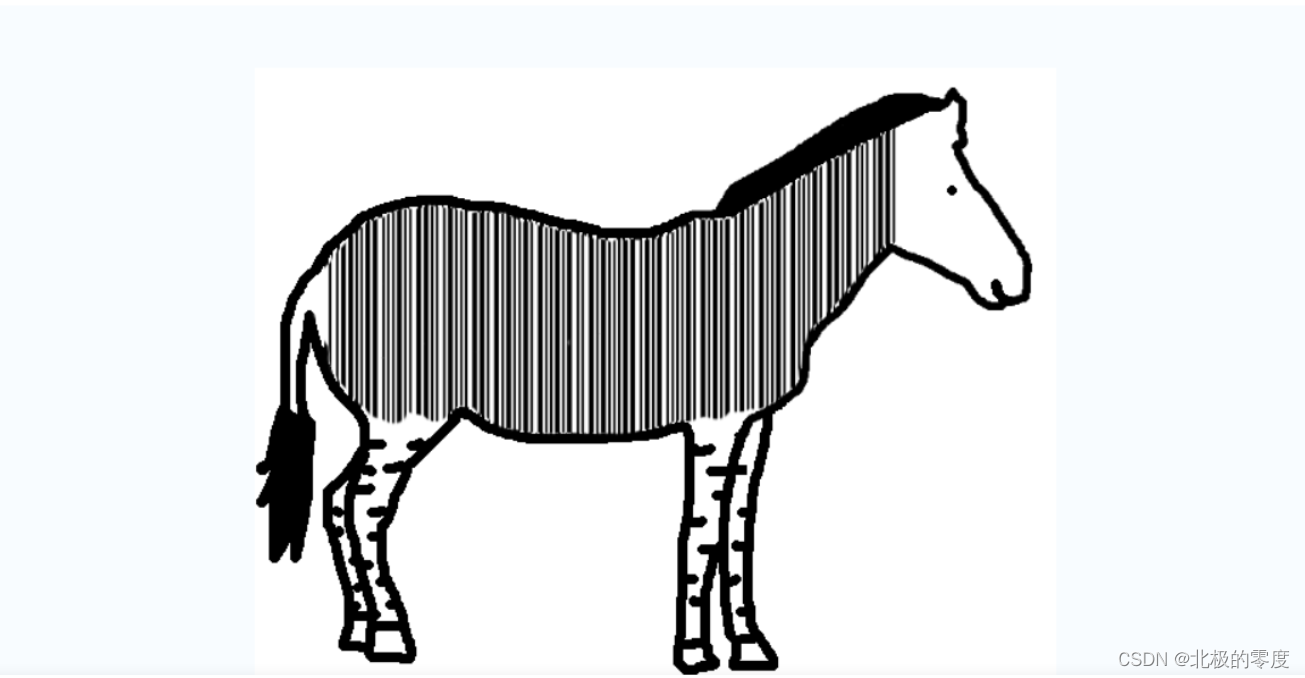
这谁能想的到条形码解析
当我们需要将十六进制的字符串写入文件时
这时我们就需要winhex, 当然010也可以,我不会 ->_->
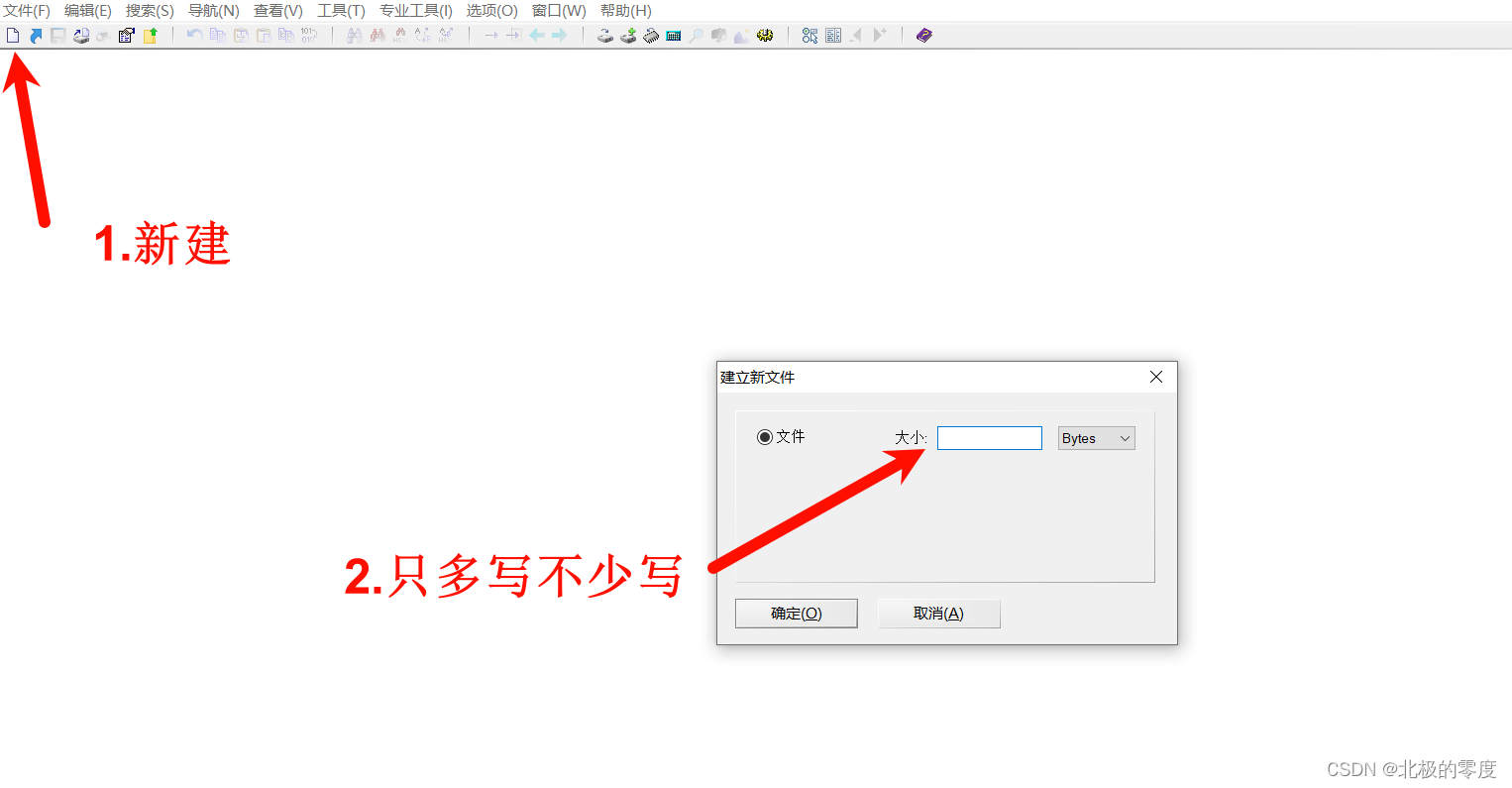

全选粘贴,剪贴板格式选择ASCII Hex。
保存自己想要的文件即可。
stegpy隐写:
安装就看这个
具体什么时候用,看题目提示吧
PNG Debugger:
有时用tweakpng打开 发现报错,用pngdebugger打开进行分析,发现很多错误的crc值,
那我们可以根据题目提示去做下一步。
IDAT隐写:
图像数据块 IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。
1、储存图像像数数据
2、在数据流中可包含多个连续顺序的图像数据块
3、采用 LZ77 算法的派生算法进行压缩
4、可以用 zlib 解压缩
值得注意的是,IDAT 块只有当上一个块充满时,才会继续一个新的块。
意味着异常的数据是人为输入进去的,这里附上数据处理脚本。
import zlib
import binascii
IDAT = "这里输入数据".decode('hex')
#print IDAT
result = binascii.hexlify(zlib.decompress(IDAT))
print (result.decode('hex'))
print (len(result.decode('hex')))在我们查看数据时,发现IDAT异常(有多个),用tweakpng打开,
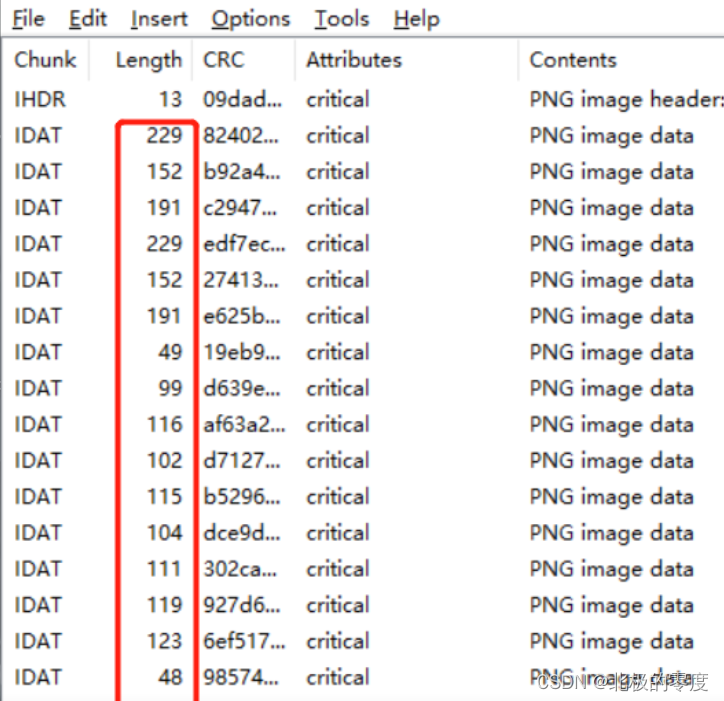
将长度进行chr转换
exif隐写:
在我们拍摄图片时,exif可以记录数码照片的属性信息和拍摄数据
kali exiftool 工具。
在kali中使用时:在结尾附近可以看到 ThumbnailImage (缩略图)
exiftool -ThumbnailImage -b 文件名 > flag.jpg 提取
tif格式文件:
1、一般会有隐藏图层,就需要借助ps。
gif格式:
1、一般直接用工具看一下 Honeyview
2、进行分离的分离成一张一张的,kali命令:convert 文件名 flag.png
合并:montage flag*.png -tile x1 -geometry +0+0 flag.png
3、看到图片有点卡的感觉就是时间隐写,原理呢就是每张图片切换的时间间隔不一样,我们可以使用kali中identify工具来提取时间间隔,指令呢 identify -format "%T" 文件名
二维码解密 :
工具QR(图片中的二维码足够清晰)
这里是将文本,内容是十六进制的数据导入
盲水印:
主要用来实现版权的防护与追踪。特点就是不破坏源文件,原来的文件可以正常使用。
工具就是:BlindWaterMark 可以看一下这篇文章前面的部分
这里简单说明一下使用命令(python2)
# 合成水印
python bwm.py encode hui.png wm.png hui_with_wm.png
无水印原图 水印图 有盲水印的图
#提取盲水印
python bwm.py decode hui.png hui_with_wm.png wm_from_hui.png
反解出来的水印图 所以我们一般会得到俩个一模一样的文件,人无法感知到水印的存在
不过可以通过比较文件的md5值或者图片大小都可以发现是俩个不同的文件
流量分析:
学习流量分析就要有一定的网络基础(计算机网络),
流量分析的范围很广,只要俩个设备或者是软件产生通信,那么就会产生流量
我们不可能把所有协议都讲一遍,只能就是我们遇到一个不认识协议的就去搜
意思就是我不会这道题,也不知道这协议是什么意思,我还能找到flag
下面讲一下,我们拿到一个题目怎么入手:
1、观察文件的内容,找规律,必要时写脚本(Python)进行提取数据。
2、关键信息的提取,有哪些数据在变,哪些不在变,还有奇怪格式的数据,这个就需要一些脑洞。
3、对某些关键的东西去搜,这里就需要你对搜索引擎的使用能力,有些东西你放百度里可能搜不到,但是你放到谷歌里就可以,有时候你搜“HTTP协议”相关的东西搜不到,但是你搜“HTTP protocol”就可以搜的到,所以这里就需要我们的一些英语能力,当然,也不只是英语,还有日语,韩语等。
4、查到线索后就可以写脚本等手段获取flag。

展示一个小技巧,找到我们的可疑数据,可以看到这是base64加密,在左边可以直接解密base64
如果是图片的话,在显示中选择,图像,可以直接转换为图片
在分析流量中我们可以多关注一下每条流量的长度,
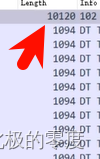
像这样明显长于其他流量的数据我们就可以仔细的看看
rip协议:
电话通信协议
选择电话 -> VoIP通话 就可以直接播放语音播放传输的内容
getshell流量分析:
这个一般题目会提示(getshell),那么我们就可以先选择tcp的过滤,分析流量,
这时就看看他的端口可能出现 4444 等,去着重分析
在最先开始入手可以先看 统计 - > 协议分级 或者 http请求等等
红色的字是请求数据,蓝色的是返回数据。
我们在分析http的数据时可以先 统计 -> http -> 请求
1、有一种简单的方法可以先试试:
strings 文件名 | grep {
意思是查找文件中带有 “ { ” 的ASCII字符串
2、可以尝试查找字节,再分析对应协议,有时可以看到,有文件信息,那就是有隐藏文件,去kali
分离。
3、分析http的数据我们是可以导出对象
4、直接写入的数据可以找一下

当然这里不光是flag,还有可能是flag转换成十六进制(或者是其他编码,如Unicode等)后数据
5、数据中写入压缩包的,导出,选择原始数据。

保存为 .zip
在应用层,我们看到一串十六进制的字符串,可以通过导出分组字节流的方式进行提取。
远程连接协议telnet:

可以选择只看发送或者请求包,查看数据时,发现有英文点号,就是不可打印字符,
这里选择 Hex 转储
查看对应的ASCII
USB协议:
Leftover Capture Data域中,八字节 为键盘流量
Leftover Capture Data域中,四字节 为鼠标流量
在kali里tshark工具下将数据提取为文本文件
tshark -r 文件名 -T fields -e usb.capdata>1.txt
再在脚本里跑,这里附上脚本(键盘流量)
import os
os.system("tshark -r test.pcapng -T fields -e usb.capdata > usbdata.txt")
normalKeys = {"04":"a", "05":"b", "06":"c", "07":"d", "08":"e", "09":"f", "0a":"g", "0b":"h", "0c":"i", "0d":"j", "0e":"k", "0f":"l", "10":"m", "11":"n", "12":"o", "13":"p", "14":"q", "15":"r", "16":"s", "17":"t", "18":"u", "19":"v", "1a":"w", "1b":"x", "1c":"y", "1d":"z","1e":"1", "1f":"2", "20":"3", "21":"4", "22":"5", "23":"6","24":"7","25":"8","26":"9","27":"0","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"-","2e":"=","2f":"[","30":"]","31":"\\","32":"<NON>","33":";","34":"'","35":"<GA>","36":",","37":".","38":"/","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"}
shiftKeys = {"04":"A", "05":"B", "06":"C", "07":"D", "08":"E", "09":"F", "0a":"G", "0b":"H", "0c":"I", "0d":"J", "0e":"K", "0f":"L", "10":"M", "11":"N", "12":"O", "13":"P", "14":"Q", "15":"R", "16":"S", "17":"T", "18":"U", "19":"V", "1a":"W", "1b":"X", "1c":"Y", "1d":"Z","1e":"!", "1f":"@", "20":"#", "21":"$", "22":"%", "23":"^","24":"&","25":"*","26":"(","27":")","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"_","2e":"+","2f":"{","30":"}","31":"|","32":"<NON>","33":"\"","34":":","35":"<GA>","36":"<","37":">","38":"?","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"}
nums = []
keys = open('1.txt')#你导出的数据文档
for line in keys:
#print(line)
if len(line)!=17: #首先过滤掉鼠标等其他设备的USB流量
continue
nums.append(line[0:2]+line[4:6]) #取一、三字节
#print(nums)
keys.close()
output = ""
for n in nums:
if n[2:4] == "00" :
continue
if n[2:4] in normalKeys:
if n[0:2]=="02": #表示按下了shift
output += shiftKeys [n[2:4]]
else :
output += normalKeys [n[2:4]]
else:
output += '[unknown]'
print('output :' + output)鼠标流量 在windows中可能提取不出来东西,就需要在kali里面跑
#鼠标流量
import os
os.system("tshark -r test2.pcapng -T fields -e usb.capdata > usbdata.txt")
nums = []
keys = open('usbdata.txt','r')
result = open('result.txt','W')
posx =0
posy = 0
for line in keys :
if len(line) != 13 :
continue
x = int(line[4:6],16)
y = int(line[6:8],16)
if x > 127 :
x -= 256
if y > 120 :
y -= 264
posx += x
posy += y
btn_flag = int(line[2:4],16)# 1 for left,2 for right,0 for nothing
if btn_flag == 1:
result.write(str(posx)+' '+str(-posy)+'\n')
print(result)
keys.close ()
result.close()
#os.system("gnuplot.exe -e\"plot\'result.txt\'\"-p")一般提取后的东西就需要绘图
用kali中的gnuplot
蓝牙协议:
首先就是去过滤,蓝牙的传输协议是OBEX,查看传输的数据,有压缩包就直接提取。
无线流量协议:
该流量的协议为 802.11 。
先爆破出无线连接的密码, aircrack-ng 文件名.pacp -w 文件名.txt
下面俩个方法任选一个
1、airdecap-ng 文件名.pcap -e SSID -p 无线密码
2、编辑 -> 首选项 -> protocols -> IEEE 802.11 -> Decryption keys -> 添加(wpa-pwd)
-> 密钥格式是 无线密码:SSID
SSL\TLS协议:
主要就是加载密钥,再分析流量,那怎么加载嘞。
打开流量包发现协议是TLS(经过加密的流量)
编辑 -> 首选项 -> protocols -> TLS(在3.0以下版本中是SSL) ->

更换我们的密钥路径 完事
在这里要注意,TLS协议的内容是加密的,大概率是RSA加密,关于密码的知识这里就不做过多赘述,只讲过程:
在分析流量时,就会发现模和e,把他们提取出来,用工具yafu提取出p,q。
通过脚本计算出私钥
#用来生成私钥
import libnum
from Crypto.PublicKey import RSA
n = "这里是十六进制"
e = ""
p = ""
q = ""
phi_n=(p-1)*(q-1)
d=libnum.invmod(e,phi_n)
rsa_components=(n,e,d,p,q)
keypair = RSA.construct(rsa_components)
with open('key.pem','wb') as f:
f.write(keypair.exportKey())之后编辑 -> 首选项
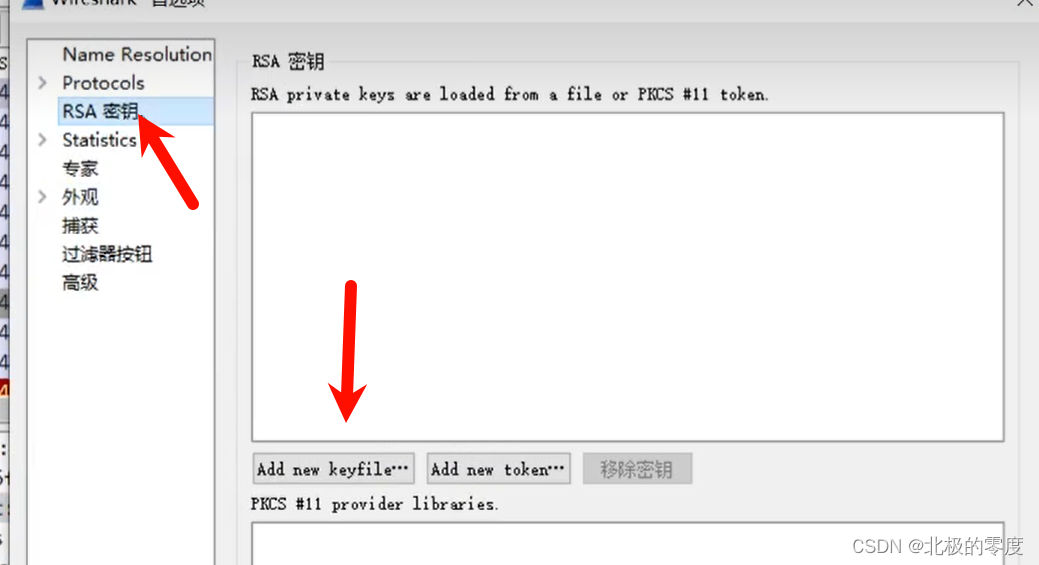
把我们生成的私钥加载进去
再分析流量,发现可疑数据,跟踪TLS流
工控管理协议:
这个没什么好说的也就是传输一些文件,然后提取出来。easy~~
RTP协议:
数据传输协议RTP,用于实时传输数据。RTP全名是Real-time Transport Protocol(实时传输协议)。它是IETF提出的一个标准,对应的RFC文档为RFC3550。RFC3550不仅定义了RTP,而且定义了配套的相关协议RTCP(Real-time Transport Control Protocol,即实时传输控制协议)。RTP用来为IP网上的语音、图像、传真等多种需要实时传输的多媒体数据提供端到端的实时传输服务。RTP为Internet上端到端的实时传输提供时间信息和流同步,但并不保证服务质量,服务质量由RTCP来提供。详细内容看这篇文章
这个看具体的题目是隐藏了什么条件,比如voip,就可以直接选择电话 -> Voip通话,可以直接听到flag
LSB隐写:
一般在png和bmp格式的图片才会用。
对于图片没有思路就可以试试LSB隐写。
windows有Stegsolve工具。
kali有zsteg。
奇怪的编码和密码:
1、<<>>>>>>>>>>>>>+.-<<<<<<<<<<<<<>>>>>>>>>>>>>>>----.++++<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>---.+++<<<<<<<<<<<<<<<<.
这样的就是Brainfuck/OoK加密工具
2、看到一个字符串只有数字和大写字母,且大写字母不超过F可以猜测是十六进制转字符
3、AES编码是我们这里最常见的,首先你会得到一个密钥(当然是凭我们自己猜想),再是得到密文,我们可以最先尝试。
4、
高速流密码——Rabbit
Rabbit使用一个128位密钥和一个64位初始化向量。该加密算法的核心组件是一个位流生成器,该生成器每次迭代都会加密128个消息位。加密后的数据以U2FsdGVkX1开头,可以设定密钥。
流密码是一种对称加密算法,它的基本思想是使用密钥生成一个伪随机密钥流,再通过该密钥流进行加/解密。
5、到单独的一串字符和一个网站地址,推测是希尔加密
6、怎么来快速区分base16、base32、base64:
首先看有没有符号,base64和base32都以’=‘作为空白补足符符号,如果结尾没有’='有可能是base16。如果出现了+和/,那么一定是base64。base64是最容易区分也是最常见的。
再看大小写字母,如果有大写有小写就一定是base64。
如果全是大写,再看字母有没有在F之后的,因为base16就16进制,字母部分只到F,若出现了F之后的大写字母则可以排除是base16。
7、Unicode编码的字符串
Unicode 是国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
Unicode 字符集的编码范围是 0x0000 - 0x10FFFF , 可以容纳一百多万个字符, 每个字符都有一个独一无二的编码,也即每个字符都有一个二进制数值和它对应,这里的二进制数值也叫 码点 , 比如:汉字 "中" 的 码点是 0x4E2D, 大写字母 A 的码点是 0x41, 具体字符对应的 Unicode 编码可以查询Unicode字符编码表。
Unicode 有多种存储方式,常见的有 UTF-8、UTF-16、UTF-32,它们分别用不同的二进制格式来表示 Unicode 字符。

8、与佛论禅工具
9、你得到一串数字,发现只有01248,只几个数字。 脚本跑一下
def de_code(c):
dic = [chr(i) for i in range(ord("A"), ord("Z") + 1)]
flag = []
c2 = [i for i in c.split("0")]
for i in c2:
c3 = 0
for j in i:
c3 += int(j)
flag.append(dic[c3 - 1])
return flag
def encode(plaintext):
dic = [chr(i) for i in range(ord("A"), ord("Z") + 1)]
m = [i for i in plaintext]
tmp = [];flag = []
for i in range(len(m)):
for j in range(len(dic)):
if m[i] == dic[j]:
tmp.append(j + 1)
for i in tmp:
res = ""
if i >= 8:
res += int(i/8)*"8"
if i%8 >=4:
res += int(i%8/4)*"4"
if i%4 >=2:
res += int(i%4/2)*"2"
if i%2 >= 1:
res += int(i%2/1)*"1"
flag.append(res + "0")
print ("".join(flag)[:-1])
c = input("输入要解密的数字串:")
print (de_code(c))
m_code = input("请输入要加密的数字串:")
encode(m_code)10、HTML编码:特征就是&#x开头。
11、Affine密码:看这里
12、看到只有俩种的形式的排列方式,就可以试试转换成0或1
13、rabbit加密:看这个 通常还有密钥
14、base100 是一种对称加密,加密后全是emoji表情。
15、“~呜喵喵喵喵呜啊喵啊呜呜喵呜呜~喵喵~啊喵啊呜喵喵~喵~喵~呜呜”这样的是兽言兽语编码
音频视频隐写:
1、先听一下,没有什么特别之处,没有的话,放到kali里看看没有没有隐藏文件,有的话分离。
2、可以试试查看频谱图

3、分析无线电的音频用RX-SSTV,转换成图像,但是要选择对应的编码。
4、silenteye隐写:SilentEye是一个跨平台的应用程序设计,可以轻松地使用隐写术,在这种情况下,可以将消息隐藏到图片或声音中。它提供了一个很好的界面,并通过使用插件系统轻松集成了新的隐写算法和加密过程。
5、SSTV:慢扫描电视(SSTV)
慢扫描电视(Slow-scan television)是业余无线电爱好者的一种主要图片传输方法,慢扫描电视通过无线电传输和接收单色或彩色静态图片。
慢扫描电视的一个术语名称是窄带电视。广播电视需要6MHz的带宽,因为帧速为25到30fps。慢扫描电视的带宽只有3kHz,因此慢扫描电视是一种慢得多的静态图像传输方法,通常每帧需要持续8秒或若干分钟。
业余无线电操作员通常在短波(或高频)、甚高频、超高频波段使用慢扫描电视。
在kali中安装qsstv工具,将无线电转换成图像
6、固定码遥控信号
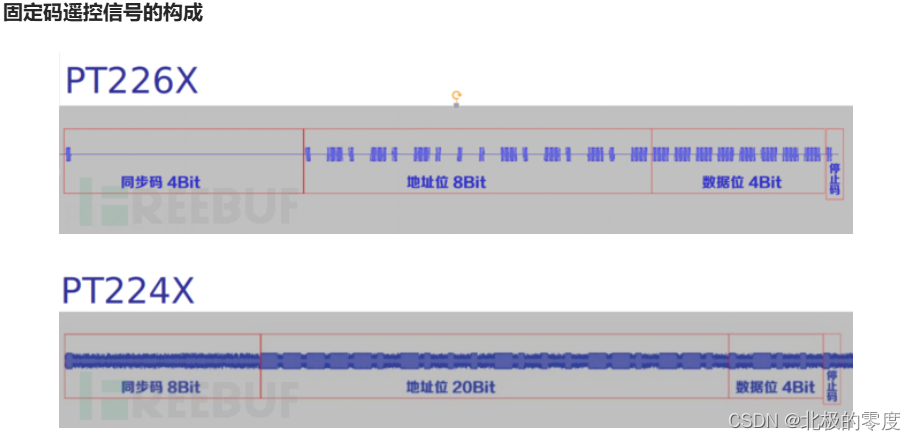
这里是知识点,基本特征波形应该长这样
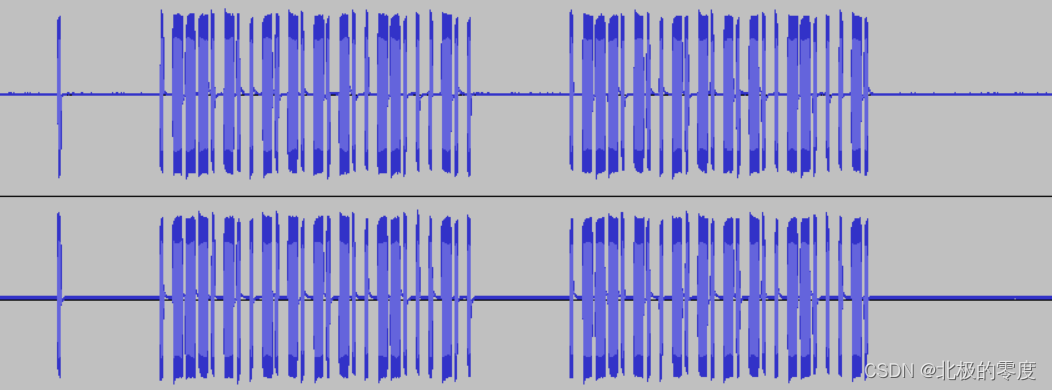
短的为0, 长的为1, 得到一串字符串,分割,只要地址位。
7、这里的题目就是音频隐写,总想着电码来解题呢,wav文件中藏了什么东西,用binwalk 和 foremost 工具就不好使了,此路不通我们就换呗,使用steghide,别怪我没提醒你,在kali里下。
8、MP3音频,MP3stego是专注于解密MP3文件,提供一个官网下载地址,使用可以看这个
9、有些信息藏在了视频里的某一帧里,就通过VideotoPicture工具进行把每一帧分离出来
伪加密:
这一块的我别人发的文章就很不错,推荐看这篇文章。
我觉得改08好使。
将加密的文件拖入软件中,修改frFlags和deFlags的值为0。
WORD文档隐写:
1、显示/隐藏编辑标记
2、 修改字体颜色
3、一个压缩包解压后,出现[Content_Types].xml并且有word为名的文件夹,那么这个zip压缩包十有八九是一个word文档,有时是将doc文件修改成压缩包,有时是反过来的
4、word文档内置了隐藏文字的效果,如果想要查看被隐藏的内容,则需要依次点击“文件=>选项=>视图”,选中隐藏文字,这样就可以查看被隐藏的文字了
PPT隐写:
1、ppt和word文档有一个相同的特性,将一个.ppt的文件,修改后缀, 变成一个zip压缩包,解压缩,出现[Content_Types].xml并且有ppt为名的文件夹。
2、一般也就是文字颜色和背景颜色设置的一样的方式用来隐藏
3、还有就是隐藏了幻灯片,这个右键就可以查看
4、加密的ppt 见过没有,使用这个工具Accent OFFICE Password Recovery
零宽度字符隐写术:
零宽度字符是一些不可见、不可打印的字符,在页面中用于调整字符的显示格式。零宽度字符本质上是unicode编码。
零宽度字符隐写:需要加密的内容转换为二进制,然后将二进制转换成一系列的零宽度字符,这样加密的内容就被隐藏了(普通文本编辑器不显示零宽度字符)。
在linux系统中使用vim就可以查看的到
文件异或隐写:
首先在010中查看时,发现文件不正常,没有头文件等正常格式。
某一 十六进制 字节多次出现,所以猜测是对整个文件进行了异或
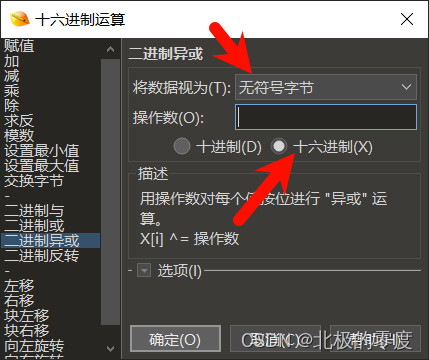
解决方法:
工具 -> 十六进制运算 -> 二进制异或
操作数即为重复的那一十六进制字节
excel隐写:
这里我只能那我写的一道题来解释
打开一个excel 表格,发现没有什么明显的信息,随便点击几个单元格发现了在这里有变化,有的显示1,有的则没有显示,所以我们让所有的1显现出来

选中尽可能多的单元格因为防止遗漏,右键,选择数字,自定义,D/通用格式
看样子像是二维码,把有1的位置涂黑,
再次选中单元格,选择条件格式,突出显示单元格规则,等于,自定义格式为黑色
按照正常扫了之后,无结果,才发现是汉信码
汉信码:2005年12月26日,由2位院士(倪光南、何德全)担任组长的专家组对《二维条码新码制开发与关键技术标准研究》进行了鉴定,专家们一致认为:该课题攻克了二维条码码图设计、汉字编码方案、纠错编译码算法、符号识读与畸变矫正等关键技术,研制的汉信码具有抗畸变、抗污损能力强,信息容量高等特点,达到了国际先进水平。专家们建议相关部门尽快将该课题的研究成果产业化,并积极组织试点及推广,同时建议将汉信码国家标准申报成为国际标准。
这里为我们的祖国强大感到自豪,我们应该有文化自信
ELF文件:
详细信息可以看这篇文章
1、有时在linux系统里运行一下就行
XML文件:
可以使用binwalk ,查看一下
或者拖到010Editor 里,这个需要点耐心
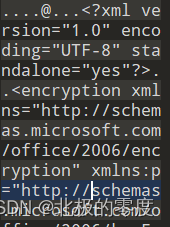
遇到这样的文件,就改后最名为,doc或者ppt
暴力破解:
掩码爆破:
会给一个密码的范围,像这样

注意这几个地方

ARCHPR无法使用问题:
在该软件无法进行使用时,原因就是压缩该压缩包的软件版本(rar5.0) ,所以无法导入
那我们真的毫无办法了吗,不,跑脚本
import subprocess
rar_name="1.rar"
#载入字典
with open('10000.txt'"r") as f:
for p in f.readlines():
cmd ="rar.exe e {0} -y -p{1}".format(rar_name,p.strip())
r = subprocess.getstatusoutput(cmd)
print(r)
#print(r[0])
if r[0] == 0:
print("pass = {}".format(p.strip()))
break明文攻击:
在我们目标压缩包中,和外部还有一个文件是一样的,才可以使用。
外部的文件需要我们制作成压缩包(zip),使用ARCHPR破解(时间不会太长,最多5分钟,暂停),成功后保存(点击确定)。
压缩包CRC报错:
CRC报错,报错信息显示是文件的第三个块,RAR结构有四个块:标记块、归档头部块、文件快、结束块
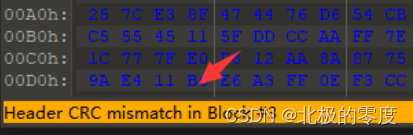
这样的就是第三个块出现了问题
修改正确的数据具体原理看这篇文章
网络迷踪:
这一个新型的信息泄露,面对一张图片来猜出他的地理位置。拍照对于我们来说是再正常不过的了,可这无形之中就泄露了我们的信息。身临其境有一种破案当侦探的快感,一点点的拨开迷雾。但是呢,这个过程有是比较痛苦的,需要我们充足的耐心,去寻找。
1、抓住主要特征,进行筛选,缩小排查范围。
2、罗列可能的潜在对象,根据细节特征进一步缩小范围。
3、除去不可能之外留下的,那就是真相。
LOGO语言:
代码特征如下:
cs pu lt 90 fd 500 rt 90 pd fd 100 rt 90 repeat 18[fd 5 rt 10]
lt 135 fd 50 lt 135 pu bk 100 pd setcolor pick [ red orange yellow green blue violet ]
repeat 18[fd 5 rt 10] rt 90 fd 60 rt 90 bk 30 rt 90 fd 60 pu lt 90 fd 100 pd rt 90 fd 50 bk 50 setcolor pick [ red orange yellow green blue violet ]
lt 90 fd 50 rt 90 fd 50 pu fd 50 pd fd 25 bk 50 fd 25 rt 90 fd 50 pu setcolor pick
[ red orange yellow green blue violet ] 日后会持续跟新....















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









