






7.27
自学第一天,学了为什么要用编译器 编程语言和机器语言的区别 下载devc++ 打印hello world 模仿制作计算器 模仿制作找钱程序 尝试下载tdmgcc失败 下载visual stadio code
7.28
我忏悔,今天啥也没学。我忏悔。
下好了tdmgcc 普天同庆。尝试学习gcc是个什么东西。 用cdm查不出gcc—version 是我的问题吗?
7.29
Vs code 运行的不是很好,很多地方都和老师做的不一样…到底是为什么?搞不懂了开始…不管了先学学看吧,反正是菜狗,不知道怎么就能运行起来了,明明那么多bug
主要用devc++来编程。
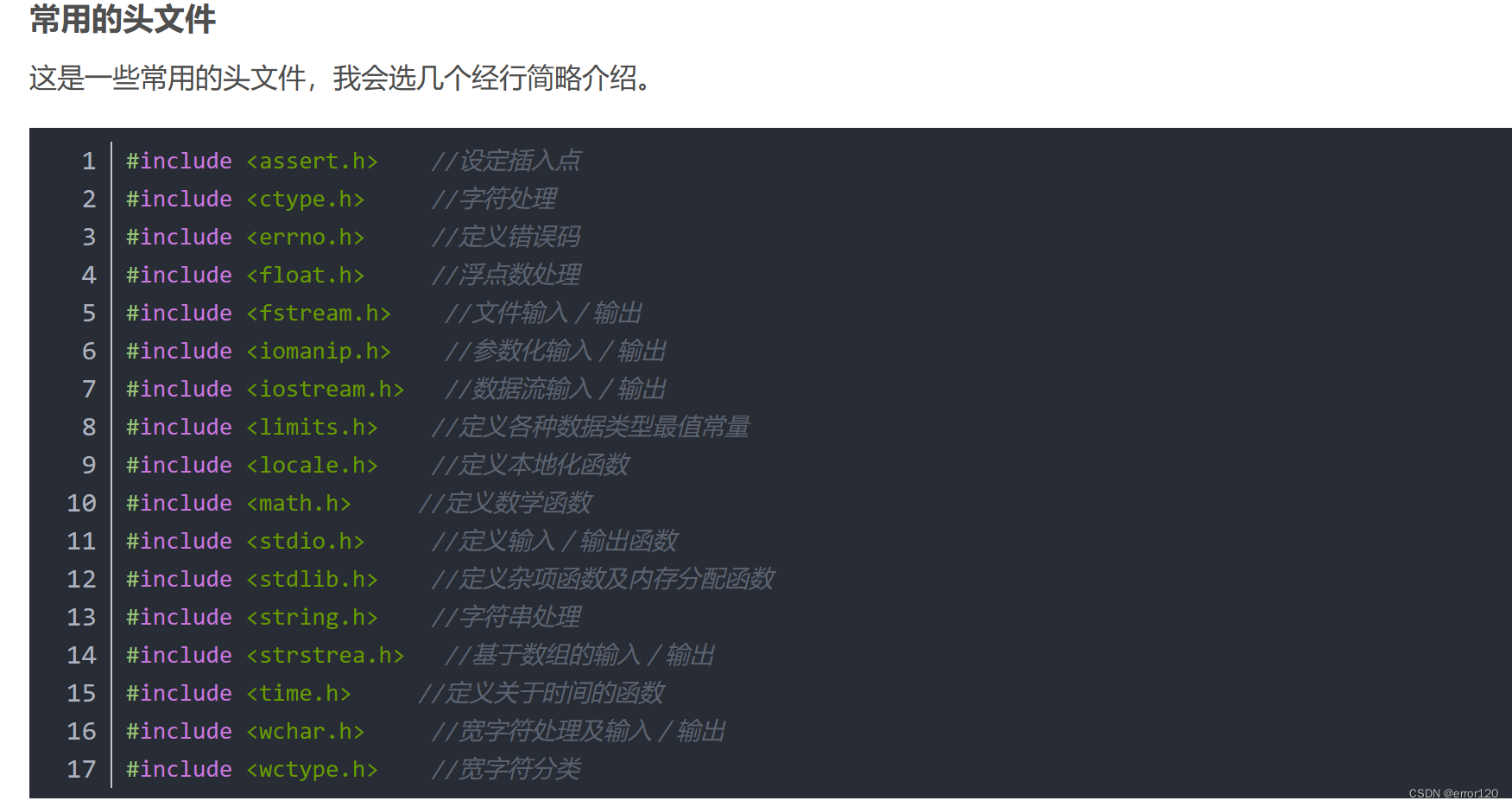
现在学的代码抬头都有 #include <stdio.h> int main() { }
基本知识:
Q:不知道 int main是什么意思
A:#include <stdio.h>是预处理命令头文件,里面包含了一些基本的代码,以便于我们在后面直接引用。类似的还有#include<math.h>等
变量:如:int price=0 这一行定义了一个变量,变量的名字是price,类型是int,初始值是0。
变量是一个保存数据的地方,当我们需要在程序里保存数据时,比如上面的例子中要记录用户输入的价格,就需要一个变量来保存它,用一个变量保存了数据,它才能参与到后面的计算中去。
变量的定义方法:<类型名称><变量名称>
E.g.int price \int amount \int price,amount
变量的名字就叫标识符,基本的构成是数字字母和下划线,数字不能出现在第一个位置上面,c语言的关键字(又名保留字)不可以用作标识符。
A=b意味着把b的值赋给a.
变量在使用时必须要做一次初始化,即赋值一次,不然会被机器按照它的逻辑赋值(房间和垃圾),在组合变量定义的时候,也可以在定义中单独给单个变量赋值。如:int price=10;int price=1,amount=199;
C语言是一种有类型的语言,所有的变量在使用之前必须定义或者声明,所有的变量都必须具有确定的数据类型。数据类型表示在变量中可以存放什么样的数据,而且在程序运行过程中不能改变。
Printf(输入) 和 scanf(输出)都是函数 f是格式化的意思 %d读整数 scanf("%d",&price)输入""里面是你要输入的东西,必须格式一致。
常量:const int amount=100;后面改为int change=amount-price;前面加了const(不变)的变量不能再定义,不然会出现error。一旦初始化,就不能被修改。
Plus c
一个scanf函数想输入两个变量,就打两个%d 形如scanf("%d %d",&a,&b);而且中间不能乱打。
浮点数 整数和整数的运算结果只能是整数。在c中10和10.0是完全不同的两个数。在c里带小数点的数叫浮点数,是在计算机内部表达非整数(包含分数和无理数)的一种方式。
%d(十进制整数);%f(十进制浮点数)
Int(整数);double(双精度浮点数)/float(单精度浮点数)。
数据类型 整数 int printf("%d",…) scanf("%d",…) 带小数点的数 double printf("%f",…) scanf("%lf",…)
运算里有一个是浮点数就能输出浮点数。但是必须注意这个规则只在一个运算符号以内的运算里算数。比如在计算机里计算10/3.0*3=10.0,而10/3*3.0=9.0。第二种就是因为10/3取整为3所以结果是9。

**说明:这是一些数据类型的字节数和格式控制符表

**打印一些不同进制的数,特别说明的是,十六进制若表示为%x,则为小写字母,如1e;反之若表示为%X,则为大写字母,如1E。
字符:打印字符和字符串
字符char只能打印一个字符;字符串string可以打印一串字符。
打印字符char 格式控制码:%c ;打印字符串 string 格式控制码:%s
字符在机内都是按照数字的形式储存的,所以想知道字符的ascii码就直接把字符转换成数字,如直接打印%d(十进制),%X(十六进制)。
运算符和算子。运算符是动作,算子是数字。
运算符有优先级 初级运算符()、【】、- >单目运算符》算数运算符(和普通加减乘除一样)》关系运算符》逻辑运算符》条件运算符》赋值运算符》逗号运算符
除了赋值运算符、条件运算符、单目运算符三类的平级运算符之间的结合顺序是从右边到左,其他的都是从左到右。
第三周:判断与循环
判断:
如果:一个基本的if语句由一个关键字if开头,跟上在括号里的一个表示条件的逻辑表达式,然后是一对大括号“{}”之间的若干条语句。如果表示条件的逻辑表达式的结果为true,那么就执行后面跟着的这对大括号中的语句,否则就跳过这些语句不执行,而继续下面的其他语句。
关系运算:
计算机的智能是建筑在规则的基础上的,在遇到情况的时候,根据事先制定的规则做出判断,是计算机最基本的能力。
能做判断的基础,是能对数据做比较,比较就是关于两个数据是否相等、谁大谁小的结论,这需要用到关系运算:对两个数据之间的关系的计算。
C语言提供了六个关系运算符:
-
== 相等
-
!= 不相等
-
> 大于
-
>= 大于或等于
-
< 小于
-
<= 小于或等于
注意其中有两个字符的运算符:==、>=和<=的两个字符必须紧紧连在一起,中间不能插入空格。
关系运算的结果是一个逻辑值,逻辑值只有两种可能的值:true(真,表示成立)或false(假,表示不成立)。当两个值的关系符合关系运算符的预期时,关系运算的结果为true,否则为false。
比较运算只有两个结果:0或者1;
判断是否相等的==和>= <=优先级低于其他关系运算符,有平级的运算符时,运算顺序从左向右;
注释:插入在程序代码中后面书写的内容计算机不会阅读,方便人类读者理解程序,对计算机的工作和理解无影响。
//单行注释(c99独有);/**/多行注释 如:/*这两个符号之间的内容为注释,也可以用于单行注释。
否则的话:else 比较数的大小用if else语句
if (score>grade){printf("你的成绩及格了");}else{printf("很遗憾你的成绩没有及格");}
为了确定if和else语句后面的作用域,保证程序的完整性。如果没有{ },if和else只能执行它们后面的单个语句,若是有多条语句的话,这些多条语句不会受条件限制约束,仍然会执行。而有了{ },可以确定逻辑判断会执行的范围。
存在 else if(条件){};语句
Q: /* */会被替换为什么?
这个讨论是深入的讨论,第一次学习C语言的同学可以围观一下,看不懂也没关系。
/* */是注释,编译器不管其中的内容。但是有没有想过编译器会把它替换成什么呢?是一个空格?还是不留痕迹?可以写代码来测试你用的编译器吗?
A: 把代码翻译成汇编代码前的步骤预处理当中会把注释代码删掉;
一条语句前的注释 替换成等长的空格;
一条语句中的注释 替换成一个空格;
一条语句后的注释 直接删除。
循环
if语句可以判断条件是否满足,满足时才做相应的动作,而循环语句可以在满足条件时,不断地重复执行一些动作。
重复执行的语句(循环语句)可以多次执行其他语句,它检查一个逻辑条件是否满足,只在满足的时候执行它的循环体。
while语句是一个循环语句,它会首先判断一个条件是否满足,如果条件满足,则执行后面紧跟着的语句或语句括号,然后再次判断条件是否满足,如果条件满足则再次执行,直到条件不满足为止。后面紧跟的语句或语句括号,就是循环体。
do-while循环和while循环很像,唯一的区别是我们在循环体执行结束的时候才来判断条件。也就是说,无论如何,循环都会执行至少一遍,然后再来判断条件。与while循环相同的是,条件满足时执行循环,条件不满足时结束循环。
do-while循环写法:do{n++,x/=10}while(x>0);
for循环是编程语言中一种循环语句,而循环语句由循环体及循环的判定条件两部分组成,其表达式为:for(单次表达式;条件表达式;末尾循环体){中间循环体;}
如for(count=10;count>0;count--){中间循环体} 可以读成:对于一开始的count=10,当count>0时,重复做循环体,每一轮循环在做完循环体内语句后,使得count--。
for循环的条件判断和while一样是在循环开始之前进行。对于for 循环来说,三个表达式每一个表达式都是可以省略的。
for 和while循环是可以互换的。
for循环逗号表达式的值:
按自左向右顺序求解,逗号表达式作为一个整体,它的值为最后一个表达式的值,逗号运算符的优先级别在所有运算符里面最低。
像这种代码 z=x++,y++,++y;实际上我们写成(z=x++),y++,++y;就很明显了。
tips1:在求和的程序里,记录结果的变量的初始值为0,在求积的程序里,记录结果的变量的初始值为1。
tips2:选择用哪种循环是有固定规则的,如果有固定次数用for,必须执行一次用do-while,其他用while。
循环控制变量即使只在循环里面使用,也不能在循环表达式里面定义,这种写法只在c99里面可用,在大部分编译器里无法直接使用。
验证:测试程序常使用边界数据,如有效范围两端的数据以及特殊的倍数等,还有个位数、10、0、负数;(验证方向两种:一种是计算机运算 一种是人脑模拟计算机纸笔运算)
8.23
进一步的判断与循环
逻辑类型和运算 (运算类型五种:加减乘除,关系运算【大于小于等】,赋值运算【a=b等】,逻辑运算,条件运算)
bool 类型使用要在代码前面加上头文件 #include <stdbool.h>,之后就可以使用bool ture和false。
逻辑运算
逻辑运算是对逻辑量的运算,结果只有0和1。逻辑量是关系运算或逻辑运算的结果。
运算符:!逻辑非 示例:!a 如果a是ture,结果就是false.反之则是ture.意为not,即a命题不对。
运算符:&& 逻辑与 示例:a&&b 如果ab都是ture,结果就是ture.否则就是false.
运算符:|| 逻辑或 示例:a||b 如果ab有一个是ture,结果就是ture.两个为false,结果就是false。
优先级:!>&&>||(!属于单目运算符,优先度较高,属于第二档)
**附表:逻辑运算符

附表:优先级表

短路:逻辑运算是自左向右进行的,如果左边的结果足够决定结果了,就不会做右边的计算。这件事情叫做短路。==所以不要把赋值和复合赋值写入表达式。这样短路就不会起作用。
**区别:y++和++y
y++:表达式的值为原来的y值,然后再将y值加1;
++y:先将y的值加一,表达式的值为加一后的y的值。
赋值和++:z=x++和z=++x运算后输出的x值是不一样的。 z=x++会先把x的值赋给z然后再对z进行++操作,这样的话x还是原来的值而z是x+1,但是z=++x运算是这样的,会先将x加一然后再对z赋值,这样x和z都是+1后的。
条件运算符
格式:形如 count=(count>20)?count-10:count+10;意为:判断count是否大于20,如果大于20,那么最终count输出count=count-10;否则count=count+10。
(条件?条件满足时的值:条件不满足时的值。)
条件运算符的优先级高于赋值运算,低于其他运算符。条件运算符是自右向左计算的。
所以,尽量不要使用嵌套的条件表达式。因为这样别人会难以理解你的代码。
逗号运算(逗号的优先级是最低的,低于赋值运算。主要在for中使用。)
8.28
级阶和嵌套的判断
嵌套的if-else 嵌套的if语句:当if的条件被满足或者不满足时要执行的语句也可以是一条if或者if-else语句。
*1 else的匹配:else总是与最近的else进行匹配,但是大括号可以改变else的所属,大括号外面的else属于外面的if。同时,缩进格式不能暗示else的匹配。
*2 ifif嵌套语句或者就是if语句,它的意思就是要求判断是否成立,如果条件成立再执行下面的语句*3 作为一个好的编程习惯,在if和else后面总是用{},即使是在只有一条语句的时候。
级联的if-else if
编排ifelse的方式:把大括号取消然后使所有的else对齐。
单一出口:比较好,把变量用一个确切的符号定义,能够比较灵活的使用。
多路分支 switch-case
格式:switch(控制表达式){
case 常量:语句......;break;
case 常量:语句......;break;
default:语句......}
*1 default 顾名思义是缺省,即输入的控制变量不属于任何事先规定的case,所以执行default后面的语句。并且,default应该放在最后,可以不在后面加break也能停止。如果后面还有case就必须加break,但是default后面一般不加case。
*2 控制表达式里面只能是整数型的结果。常量可以是常数,也可以是常数计算的表达式。
*3 const int 只有c99可以使用。ascin c 不可以使用。
*4 switch语句可以看作是一种基于计算的跳转,计算控制表达式的值后,程序会跳转到相匹配的case(分支标号)处,分支标号只是说明switch内部位置的路标,在执行完分支中的最后一条语句后,如果后面没有break,就会按顺序执行到下面的case里面去,直到遇到一个break,或者switch结束为止。
*5 case并不能阻止程序往下执行,它只标志着程序进入。只有break标志着结束。一般来说我们会为每一个case配一个break,只有在需要多个常量执行同一个语句时才会多个case共用一个break。
8.30
补充复习遗漏 *printf("%d",12+24) 里面%d是指我需要计算机给我输出一个结果,12+24是它要执行的内容。
第四周循环:4 循环的例子
1 循环计算
小套路:tips1 在计算最开始的数据可能需要保留,这个时候可以设置一个新变量来对旧数据进行保存。即
int x=148;
int ret=0;
int y=x;
while(x>1){x/=2;ret++;}
printf("log2 of %d is %d",t,ret);
这样就可以保存原来的数据进行相关计算,并且反馈出清晰的结果。
tips2 计数循环 但做循环时自己检验时,在面对较大循环次数时,可以先用较小的次数做判断,然后再推断较大的次数,类似数学题目里面的找规律。
补充内容2 对于while循环来说,在最后边界数值判断时,如果这是最后一次满足执行条件而下一次不满足,那么输出的结果就是上一次的最后结果。
e.g.int x=100;
while(x>=0){printf("%d",x); x--;}
那么这段代码最后循环101次,输出x=0,最后循环结束的时候x的值为-1。
调换printf(......)和x--的顺序时,即改为while(x>=0){ x--;printf("%d",x);},这段代码的循环次数不变,但是输出的第一个和最后一个值不同。后者最终输出-1。
2 算平均数
解决问题的流程:找到解决问题需要的变量--找到算法--构造流程图--写出程序
数据需要变量来储存。 不同的算法过程的繁琐程度不同,选择较简洁的程序。
3 猜数
在实际写出程序之前,我们可以先用文字描述程序的思路,核心重点是循环的条件,人们往往会考虑循环终止的条件。
新符号:1、rand() 随机数 每次召唤rand()就得到一个随机的整数。 使用前需要在头文件里多包含一个库--#include <stdlib.h>
2.%100 例如 x%n的结果是【0,n-1】的一个整数
4 整数逆序
主要要做的是整数的分解,然后通过计算的方式进行题目要求的变换。
思路:1 对一个整数做%10的操作,就得到它的个位数;
2 对一个整数做/10的操作,就去掉了它的个位数;
3 然后再对2的结果做%10,就得到原来数的十位数。
4 依此类推。
5 循环和判断常见的错误
1、if语句常见的错误
*忘了大括号;
解决方法:永远在if和else后面加上大括号,即使当时后面只有一条语句。
*if后面的分号:
例如: if();=if() ;相当于它默认后面已经有一条语句即 ,但是这个语句的意思是什么都不做。而且这个时候即使你在后面加上大括号也没有用,这个时候本该属于if语句的句子成为了普通的语句。
(可以在代码里面加上一些大括号,编译器不会觉得你的语句有问题,这是我们有的时候做调试的小技巧。)
*错误使用==和=;
if只要求()里的值是零或者非零,所以用==(比较)和=(赋值)都会输出结果,但是意义不一样,导致代码出现问题。
(要尊重warning,这样的程序就算暂时能运行也可能后面出现问题)
*使人困惑的else;
补充:代码风格:在if和else之后必须加上大括号形成语句块;
大括号内的语句缩进一个tab的位置。
(如果以后进大公司工作,不同的公司一般有不同的格式要求,按照它们要求的去做就行。)
第五周:循环控制
1、循环控制:break和continue
1.1、一旦遇到break就会跳出循环,即不再做接下来的语句,也不再判断条件之间跳出循环。与switch里面的用法一样。
1.2。continue就是不再把这一轮的语句继续完成,但是会继续判断条件,进入下一轮循环,即它并不离开循环。

**例图如上;
2、多重循环
2.1、嵌套的循环:在循环里面还是循环
没什么特别需要理解的,就是正常嵌套使用。但是必须注意的是外部循环的变量和我们内部循环变量必须是不一样的,比如说可以一个是i一个是x,但是不能两个都是x,因为如果内外变量一致会混淆。
p.ps 在我们while循环和for循环互换的时候,使用while循环可能会比for循环多出一个中间变量随之递增或者递减,这样来替代for循环里面变量本身的递增或者递减所进行的判断。
2.2、从嵌套的循环中跳出:break只能跳出其所在的循环
这句话的意思就是当我们有很多层嵌套的循环时,我们在某一层使用break和continue的时候,只能跳出一层循环。但是接下来外层的循环依然回进行。
如果我们想一次性全部跳出,就在每一层都加break,但是也不能直接加break,否则在每一次出循环判断条件的时候都会break。
所以我们采取接力break的方式。
即我们采取:当我们获得了需要的结果时,我们让我们某一个定义的变量满足我们break的条件,然后我们判断一次然后一路break出循环。
goto语句:goto语句后面要有一个标号,指明我们要跳去的地方。
执行goto语句就是会跳转到那个标号所代表的地方,所以goto语句特别适合用来在多重循环里面做跳转。==所以其实goto语句是用来代替接力break语句的高替,用来跳出多重循环。
**其实goto语句哪里都可以用,但是会破坏代码的结构性,难查错,让程序逻辑混乱并且降低程序的可读性,所以建议是尽量不要随便的使用,在做多重循环的跳出时候做就行。而且对cache和虚存储器的性能都有不良的影响。
注意:goto语句在使用时是这样的:
for(i=1;i<min;i++){
if(a%i==0&&b%i==0){
ret=1;
goto out;
}
}
out:
return 0;标明的跳转地点标记词out后面是加一个 : 而不是 ; 。
而且goto语句可以用多个起点跳到同一个终点,但是不能一个goto语句到多个终点。
还有,在标识符后面应该跟一条语句才行,可以是赋值可以是声明,但是如果实在没有办法在它后面加语句我们也可以加上一个分号;作为空语句,来让这个标识符运行起来。
2.3、循环应用
**little tips:当一个循环的起始数字和终止数字都确定的时候我们优先考虑for循环。
2.3.1.前n项求和。
2.3.2 求最大公约数
法一:枚举法
- 设t为2;
- 如果u和v都能被t整除,则记下这个t。
- t加1后重复第二步,直到t等于u或v。
- 、那么,曾经记下最大的可以同时整除u和v的t就是gcd ( 最大公约数)。
法二:辗转相除法(欧几里得算法)
- 如果b等于0,计算结束,a就是最大公约数;
- 否则,计算a除以b的余数,让a等于b,而b等于那个余数;
- 回到第一步。
原理:两个数的最大公约数等于其中较小的数字和两者间(大数除以小数后)余数的最大公约数。
所以是辗转相除,如果有几次除不尽的话。
**下图证明了为什么这个原理成立。这里只截出一部分证明但是已经足够,剩下的你自己去想。实在不行去知乎搜证明过程。

2.3.3 整数的分解
正序分解整数。
1、先逆序整数再逆序分解。但是这种方法只适用于末尾不含0的数字。所以我们要再想一种方法。
**little tips: 解决末尾空格的问题
当你要输出空格来隔开输出语句时,如果你不想要让末尾有空格输出你就加一个判断条件,只有当条件成立时输出。
2、所以我们把之前学的逆序乘法改变顺序,先拿x\t得到最高位然后再拿x%t得到剩下的几位,然后再拿t\10得到下一位。这个时候要拿一个变量来储存结果,然后输出。
如何根据我们所输入的数字x求t的大小?拿x除以10一直进入循环,直到x<=9,然后设置t一开始=1,一路和x一起进入循环,一直乘以10。
第六周:数组与函数
* 数组:数据可以存放在变量里,每一个变量有一个名字,有一个类型,还有它的生存空间。如果我们需要保存一些相同类型、相似含义、相同生存空间的数据,我们可以用数组来保存这些数据,而不是用很多个独立的变量。(静态)数组是长度固定的数据结构,用来存放指定的类型的数据。一个数组里可以有很多个数据,所有的数据的类型都是相同的。
静态数组在编译时分配内存,大小固定,而动态数组在运行时手动分配内存,大小可变。
1.1 初试数组
e.g.int number [100] ;
我们在这里就定义了一个变量number,这个number是一个数组。后面中括号中的数字表明这个数组可以容纳100个数据,而这一组数据它们的数据类型都是int。
代码的模式示例如下:
int x;
double sum=0;
int cnt=0;
int number[100];
scanf("%d",&x);
while(x!=-1){
number[cnt]=x;
sum+=x;
scanf("%d",&x);
}其中cnt就相当于一个编号,后面引用数组中的数据时就输入相应的编号就可以。
比如:number[6];就是引用编号为6的数据。
但是现在的程序还是存在安全隐患,因为我们并没有去判断在我们输入数据的过程中,cnt会不会出现大于100,也就是我们定义的数组大小的情况。
1.2 定义数组
<类型>变量名称[元素数量];
*这个方括号确定了它是一个数组,如果没有方括号那它的性质就变了,它就成为一个普通的变量。
元素数量必须是整数;
在c99之前:元素数量必须是编译时刻确定是字面量,也就是静态数组。
c99开始,我们就可以用变量来定义数组的大小。
数组就是一个容器,容器是现代程序设计当中非常重要的一个基本概念,或者说,现代的编程语言都应该提供某种形式的容器,一种语言提供容器的能力的大小可以看作是语言能力的大小的一种非常重要的评判标准。
数组的特点是:
- 其中所有的元素具有相同的数据类型;
- 一旦创建,不能改变大小;【可以在每一次循环的时候输入的数组大小不一样,但是一旦确定,就不能再改变】
- 数组中的元素在内存中是连续依次排列的。
数组中的单元可以出现在赋值的左边或右边;
在赋值左边的叫做左值,右边叫右值。在赋值号右边的时候我们就读取它的值,在赋值号左 边我们就赋予它右边的值。
e.g. a[2]=a[1]+6;
数组的单元
- 数组的每个单元就是数组类型的一个变量
- 使用数组时放在[ ]中的数字叫做下标或者索引,下标从0开始计数,最大的下标是数组大小-1;
**1:有效的下标范围 编译器和运行环境都不会检查数组下标是否越界,无论是对数组单元做读还是写;一旦程序运行,越界的数组访问可能造成问题,导致程序崩溃。即segmentation fault。
但是也可能运气好没有造成严重的后果,所以这是程序员的责任来保证程序只使用有效的下标值:【0,数组的大小-1】。
动态数组:
就是之前我们所构思的那样,
int number[cnt];
int cnt;
scanf("%d",&cnt);这样每输入一个数字就能获得一个不同容量的数组,实现动态变化。
但是这样的操作只在c99系统里面可用。
p.ps 长度为0的数组可以存在但是没有任何用处。
Q1:字符可以做下标吗?
可以,因为在ascii码中,字符在计算机中的储存就是数字。但是这种在实际应用中不常见,虽说在语法上面合法。
1.3 用数组做散列运算
**在使用数组之前应该初始化数组,不只是数组,在使用任何变量之前,都应该对变量进行初始化,这是一个编程的好习惯,可以有效避免许多由于垃圾值导致的bug。
c99 用数组的程序 示例
const int number=10; //数组的大小
int x;
int count[number];
int i; //定义数组
for(i=0;i<number;i++){
count[i]=0;
} //初始化数组,数组和本地变量一样都是没有默认赋值的,所以为了安全性我们给它们做一个初始化赋值,正如上文所说,记得初始化赋值是一个好习惯。
scanf("%d",&x);
while(x!=-1){
if(x>=0&&x<=9){
count[x]++; //数组参与运算
}
scanf("%d",&x);
}
for(i=0;i<number;i++){
printf("%d:%d",i,count[i]); //遍历这个数组做输出
**在这个例子里面,我们可以看到我们给数组初始化赋值所用的方法是for循环,这个方法的缺点是速度较慢,需要给每一个单元都赋一次值。但是它的优点是移植性较好,几乎适用于所有类型数组的初始化(可以考虑和初始化参数列表int a[10]={0}配合使用,并且release版本的for循环初始化经优化后速度并不慢。)
除此之外还有另外三种数组初始化的方法:初始化参数列表,使用memset函数进行初始化,指定初始化器。这三种各有优缺点。
2、函数的定义和使用
2、1 初见函数
思考:分块 实现某一功能 输入输出 直接引用
比如printf("")这个就是一种函数,来自我们头文件的函数库,我们在后面写它就可以直接调用。所以我们现在要做的是创建一个属于我们自己的函数,然后后面我们就可以引用了。方便我们实现功能多次引用,减少代码工程量。并且提高代码的可读性。防止出现程序复制(代码质量不良的表现)。而且能够方便我们在后面进行调试,纠错。
函数的形式:
我们现在接触到的是主函数int main(){ 主体 };
类似的我们也可以自己定义一个函数形如 int isprime(int i){ 主体 };(中间这个int i是我们预先定义的变量)。
函数的基本定义方式就是一个函数头和一个函数主体:
函数头 函数主体
return_type function_name( parameter list){ body }
返回类型 函数名称 参数表
返回类型:一个函数可以返回一个值。return_type是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type是关键字void。
函数名称:这是函数的实际名称。函数名和参数列表一起构成了函数签名。
参数:参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。参数和参数之间用,分隔。参数和它的圆括号对于确定这是一个函数很重要,某种意味上标志这它是一个函数。
函数主体:函数主体包含一组定义函数执行任务的语句。
这个也被称为函数声明,在函数声明中,参数的名称并不重要,只有参数的类型是必需的。因此下面的也是有效的声明: int max( int , int );
当您在一个源文件中定义函数且在另一个文件中调用函数时,函数声明是必需的。在这种情况下,您应该在调用函数的文件顶部声明函数。
然后在后面我们引用时,输入 isprime(i) 程序就会跑一遍我们定义的函数isprime(i)。
2.2 函数的定义和使用
函数是一块代码,接收0个或者多个参数,做一件事情,并返回0个或者多个值。
可以先想象成数学中的函数。但是不完全一样,编程中的函数有它自己的独特性质。
函数的定义方法我们在上面可以看到,这里就不再重复。
调用函数:
- 函数名(参数值) 这个函数参数表里有什么参数,我们就需要传递什么参数,而且要传递正确的参数类型。这个圆括号是很重要的,如果没有圆括号就不算是调用了一个函数。哪怕没有参数也需要有圆括号。
- 如果有参数,则需要给出正确的数量和顺序
- 这些值会被按照顺序依次用来初始化函数中的参数。
函数返回:函数知道每一次是哪里调用它,会返回到正确的地方
2.3从函数中返回
return停止函数的执行,并送回一个值。
所以return可以表现为 return 或者return 表达式。
- return 表达式 语句结束函数执行,返回调用函数,而且把表达式的值作为函数的结果。return 表示从被调函数返回到主调函数继续执行,返回时可附带一个返回值, 由return后面的参数指定。return通常是必要的,因为函数调用的时候计算结果通常是通过返回值带出的。return语句只能出现在函数体内,出现在代码中的其他任何地方都会造成语法错误!当执行return语句时,即使函数主体中还有其他语句,函数执行也会停止!
- return 通常情况下return后面跟有表达式,但是并不是绝对的。此情况就是单纯的将控制权转交给主调函数继续执行。
一个函数里面可以出现多个return语句,但是依照我们的单一出口原则(因为出口太多了不方便我们后面进调试和修改)。
return的值可以赋值给变量,可以再传递给函数(返回值的赋值),甚至可以丢弃(我们已经见过了,就是常见的return 0,它的作用就是结束这个函数,而不是返回值)。
没有返回值的函数
- void 函数名(参数表)
- 不能使用带值的return
- 可以没有return
- 调用的时候不能做返回值的赋值,所以,如果函数有返回值,则必须使用带值的return。
3.函数的参数和变量
3.1 函数原型
- 一般是把自己的函数写在上面,把主函数写在下面,这是因为:
- c的编译器自上而下顺序分析你的代码
- 在看到sum(1,10)的时候,它需要知道sum()的样子
- 也就是sum要几个参数,每个参数的类型如何,返回什么类型
- 这样它才能检查你对sum的调用是否正确
但是,我们会希望把主函数放到比较显眼的前面位置,所以我们会采取这样的措施:原型声明。
- 当我们把调用的函数放在后面时,我们可以把函数的函数头取出,加上分号 “ ; ",就构成了函数的原型。我们把函数原型放在主函数的前面,把实际的函数头放在主函数的后面,这样就看起来美观便捷。
- 函数原型的目的是告诉编译器这个函数长什么样子,包括名称,参数(数量和类型),以及返回类型。
- 旧标准习惯把函数原型写在调用它的函数里面,现在一般写在调用它的函数前面;
- 原型里可以不写参数的名字,但是一般仍然写上。
编译器会有一次检查,检查参数的类型,声明和实际的是否一致。
3.2 参数传递
调用函数
- 如果函数有参数,调用函数时必须传递给它数量、类型正确的值
- 可以传递给函数的值是表达式的结果,这包括:
- 字面量
- 变量
- 函数的返回值
- 计算的结果
类型不匹配?
- 调用函数给的值与参数得到类型不匹配是c语言传统上最大的漏洞
- 编译器总是悄悄帮你把类型转换好,但是这很可能不是你所期望的,所以编译器不一定会指出你的错误,这就不方便你debug
- 后续的语言如cpp和java在这方面很严格
传过去的是什么?
- c语言在调用函数时,永远只能传值给函数。每个函数有自己的变量空间,参数也位于这个独立的空间中,和其他函数没有关系。
- 在其他函数里面找不到这个函数里的参数变量。
- 过去,对于函数参数表中的参数,叫做“形式参数”,调用函数时给的值,叫做“实际参数”,由于容易让初学者误会实际参数就是实际在函数中进行计算的参数,误会调用函数的时候把变量而不是值传进去了,所以我们不建议继续用这种古老的方式来称呼它们。
- 参数:在函数参数表中的参数;
- 实际参数:在调用数据时给予的值。
3.3 本地变量
- 函数的每次运运行,就产生了一个独立的变量空间,这个空间中的变量,是函数这次运行独有的,叫做本地变量。所有我们定义在函数内部的变量都是本地变量。
- 定义在函数内部的变量就是本地变量
- 参数也是本地变量
变量的生存期和作用域
- 生存期:什么时候这个变量开始出现了,到什么时候它消亡了
- 作用域:在(代码的)什么范围内可以访问这个变量(这个变量可以起作用)
- 对于本地变量,这两个问题的答案是统一的:大括号内———块。
本地变量的规则
- 本地变量是定义在块内的
- 它可以是定义在函数的块内,也可以是定义在语句的块内
- 甚至可以随便拉一对大括号来定义变量,这个大括号可以不依附于任何语句,大括号里面 定义的变量在大括号外就不存在了
- 程序运行进入这个块之前,其中的变量不存在,离开这个块,其中的变量就消失了
- 块外面定义的变量在里面仍然有效(这个就是块的包含),但是在块里定义的变量在这个块里的局部优先级高于块外的变量。即块里面定义了和外面同名的变量则掩盖了外面的。
- 不能在同一个块内定义同名的变量。
- 本地变量不会被默认初始化
- 参数在进入函数的时候被初始化了,会拥有一个默认值。
3.4 函数的其他细节注意事项
没有参数时:void f(void):明确告诉编译器是我们这个函数不接受任何的参数
void f():在传统c中,它表示f函数的参数表未知,并不表示没有参数。但现在在c99中,它会猜测你是int类型。
逗号运算符:
调用函数时,圆括号里面的逗号,是标点符号不是运算符。但是如果你给它再加一层,那么就变成逗号运算符,这个和之前的区别就是传一个还是两个参数进去。
不能在函数里面定义另外一个函数,c语言里面不允许,只能放声明,不能放函数的主体。
关于main
- int main()也是一个函数
- 可以写成int main(void)
- return 0是有意义的
- main函数是第一个被执行的函数,但不是第一个被执行的代码,它之前还有编程准备
4、二维数组
int a[3][5]通常代表着a是一个三行五列的矩阵。
二维数组的遍历:
for(i=0;i<3;i++){
for(j=0;j<5;j++){
a[i][j]=i*J;
}
}二维数组的初始化
示例: int a[ ][5]={
{0,1,2,3,4},
{2,3,4,5,6},
};
- 列数是必须给出的,行数可以由编译器来数
- 每行一个{ },逗号分隔
- 最后的逗号可以存在,有古老的传统
- 如果省略,表示补零
- 也可以用定位,c99 only
第七周:数组运算
1.数组运算
1.1数组运算
数组的集成初始化 自动填入;不写就自动补零。
c99集成初始化时的定位:用 [ n ] 在初始化数据中给出定位,没有定位的数据接在前面的位置后面,其他位置的值补零,也可以不给出数组的大小,让编译器算,这个时候它自动默认你输入的最大为最大,这种方法特别适合初始数据稀疏的数组。
数组的大小
sizeod给出整个数组所占据内容的大小,单位是字节。
为了得到数组中数据的个数: sizeof(a ) / sizeof(a[0]),这样当我们修改数据时不用修改我们的遍历次数。
在c语言中数组的下标从【0】开始。
数组的赋值
数组变量本身不能直接赋值。所以要把一个数组赋给另外一个数组就要遍历。通常都是使用for循环,让循环变量 i 从0到<数组的长度,这样就刚好是最大有效下标。
数组中的数据类型相同。
离开循环后不能继续用 i 的值来做数组的下标。因为离开时 i 的值就等于数组长度,不是有效下标。
数组的维数:数组元素下标的个数。根据数组的尾数可以将数组分为一维、二维等多维数组。
数组之间的复制:
(1)逐个元素之间复制;
(2)利用memory函数整体复制
例: memcpy(a, b, 10*sizeof(int)); //b到a,复制10*sizeof(int)字节的数据
memcpy(a, b, sizeof(b));
int *p=(int *) memcpy(a,b,sizeof(b)); //返回值p指向a[0]
数组的类型
数组除了基本的数据类型以外还有 : 指针 ( 数组里的每一个元素是一个指针,指向一个整形数据 ),字符型(char) 以及 结构体,共用体
- 我学习参考的是书本和网络。
- 我写博客旨在监督自己学习,与大家分享学习成果,脚踏实地,一步踩死一个bug。















 3122
3122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









