










目录
5.ok,又有人发现,为什么有些人写项目使用std::cout或者第二种表示方式呢
一.一些废话
首先欢迎大家边听歌边看本博客▶ 未必 (163.com)
嗨!大家好呀,凌乱的我又双叒叕来了,少年振衣,岂不可作千里风帆看?作为新时代的打代码专员,当然是对万事万物充满好奇,但千里之行者,必始于足下,死于逐假~!
相信大家学了一个学期的C语言肯定滚瓜烂熟了吧,融汇贯通,还不会的其实也没关系(这里插拨广告),ok。
在学习C语言后我们其实已经掌握了基础的编程能力,在新的学期我们即将迎来C++的领域,C++嘛就是在C的基础上去增加了一点东西的,现在我们就来浅浅了解一下吧,让我们一起学习C++吧,欢迎各位大佬在看完我的蒟蒻见解后能给我宝贵的意见,当然欢迎各位大佬指错!!
二.C++的相关知识
1.关键字
其实C++就在C的基础上去发展的,我们可以观察一下C++的关键字
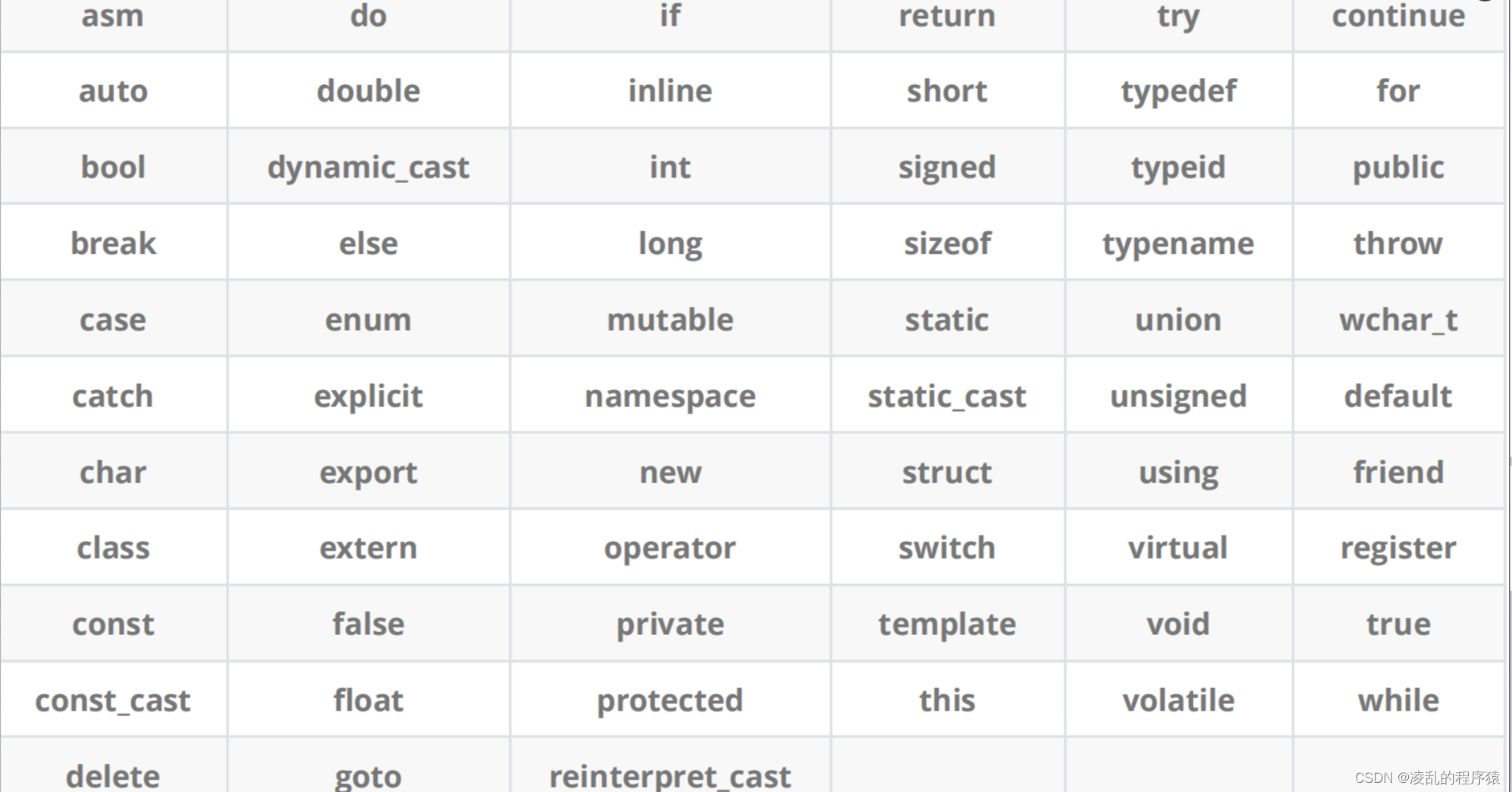
不难发现大多数都是C里面的,C++是C语言基础上不断叠加的一门语言,所以C++兼容90%作用的C语言语法。
2.头文件
上期我们了解了C++的头文件,其实不难发现其头文件和C的最大区别就是一个是math.h一个是cmath。
其实在C语言我们说(早期)标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来C++将其实现在std命名空间(下面会讲)下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;
但旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用<iostream>+std的方式。
3.命名空间
3.1这里就是补上期的坑
using namespace std;我讲的比较含糊,现在补充一下:
首先
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存
在于全局作用域中,可能会导致很多冲突。(就是同一个项目,不同的模块用了同一个变量)
使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。


好好好,有点难懂,举个例子吧
现在有一个游戏项目分好几个组做,我们组负责写游戏代码定义了应该变量名称叫Handsome(一般应该是record,这里博主在发疯罢了),然而负责网络的小组也定义里一个Handsome(record)变量,当我们合并的时候发现代码报错了,不能运行。
那么这时候如果用得是C语言的话,这两组人可能就得有一组得把有关这个变量的代码全写一遍,首先在这个多写一天代码就多掉几根头发的时代,你觉得谁想当这个冤种,其次我傻呀,我干嘛要改,又不给我加班费!噢当然肯定有些人会说

这种另当别论,因为C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决。
代码举例
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}运行

翻译
编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
rand以前是函数,不能在定义为变量
3.2 命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}
中即为命名空间的成员。
ll(凌乱)是命名空间的名字,一般开发中是用项目名字做命名空间名。
我自己用的是ll,大家可以也用自己名字缩写,娜彪 如:nb
namespace ll
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
int Add(int l, int r)
{
return l + r;
}
struct Node
{
struct Node* next;
int val;
};
}
//当然也可以嵌套
//我们创建一个源代码
//t.cpp
namespace N1
{
int a;
int b;
int Add(int l, int r)
{
return l + r;
}
namespace N2
{
int c;
int d;
int Sub(int l, int r)
{
return l - r;
}
}
}同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
如一个工程中的t.h和上面t.cpp中两个N1会被合并成一个
// t.h
namespace N1
{
int Mul(int left, int right)
{
return left * right;
}
}注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中 ,这个吧就有点类似局部变量了(哈哈类似)
3.3使用
比如
namespace bit
{
// 命名空间中可以定义变量/函数/类型
int a = 0;
int b = 1;
}
int main()
{
// 编译报错:error C2065: “a”: 未声明的标识符
printf("%d\n", a);
return 0;
}// 编译报错:error C2065: “a”: 未声明的标识符
其实命名空间的使用有三种方式:
1.加命名空间名称及作用域限定符:
代码示例:
int main()
{
printf("%d\n", N::a);
return 0;
}
2.使用using将命名空间中某个成员引入:
代码示例:
using N::b;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
return 0;
}
3.使用using namespace 命名空间名称引入:
代码示例:
using namespce N;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
Add(10, 20);
return 0;
}我们在写的时候一般采用第三种
4.学C++需要改变的习惯
我们学一种语言第一件事肯定就是向世界打招呼咯,所以学C++也不能少呀
#include<iostream>
using namespace std;
int main()
{
cout<<"Hello world!!!"<<endl;
return 0;
}std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
所以这就是我们为什么经常使用using namespace std;的本质
可以看到我们的printf不见了,变成了cout,还有那个<<,什么鬼嘛
首先呢C++的输入输出有自己的函数,就是cin和cout
1. 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件
以及按命名空间使用方法使用std。
2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<
iostream >头文件中。
3. <<是流插入运算符,>>是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。
5.ok,又有人发现,为什么有些人写项目使用std::cout或者第二种表示方式呢
这个std是C++标准库的命名空间:
1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对
象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模
大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 +
using std::cout展开常用的库对象/类型等方式。
那么都学到这里了,我们是不是得来讲讲 缺省参数
6.缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实
参则采用该形参的缺省值,否则使用指定的实参。
说实际一点,比如
void Func(int a = 0)
{
cout<<a<<endl;
}
int main()
{
Func(); // 没有传参时,使用参数的默认值
Func(10); // 传参时,使用指定的实参
return 0;
}当Func()里面没东西的时候,以上的定义int a=0;就把0给Func,如果有,比如10,则传10
如果把int a=0;比作现实的添狗的话,那么Func就是他们的女神,如果女神的男朋友(Func(10)中的10)给了女神10快钱,那女神就不需要添狗(int a=0)的钱钱了,如果女神的男朋友没给钱,自然女神就得接受这条添狗的钱钱啦(int a=0)
所以我们从中明白了什么道理?

好好好
先收,再写博主要...了..............................















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









