






Datawhale官方链接:https://www.datawhale.cn/home
首先先感谢Datawhale提供的AI春训营让我能在枯燥的本科大学生活中也能接触先进的AI知识,感谢你们的开源精神(开源精神永不落幕),也无比感谢鱼佬的代码帮助以及各位助教和各大民间高手的热心帮助,让我这个门外汉也能接触到AI+生命科学的独特。
基于官方文档的学习笔记
一、IDRs 的生物学意义与挑战
-
定义与功能
- IDRs 是指蛋白质中缺乏固定三维结构的区域,具有高度动态性和柔性。
- 在生物体系中,IDRs 参与液-液相分离(LLPS)、DNA 调控、细胞信号传导等关键过程[[3][4]]。
- 研究表明,IDRs 与神经退行性疾病、癌症等疾病密切相关。
-
研究挑战
- 实验表征困难:传统生化方法(如 X 射线晶体衍射)难以捕捉动态结构,需大量实验且耗时。
- 计算预测需求:开发高效准确的计算方法成为生物信息学的重要方向。
二、赛题任务与数据特点
- 任务目标:基于氨基酸序列预测每个位置是否属于 IDR(二分类问题)。
- 数据示例:
{'id': 'disordered_protein_0', 'sequence': 'MKQFGLAAFDELKDGKYNDVNKTILEKQSVELRDQLMVFQERLVEFAKKHNSELQASPEFRSKFMHMCSSIGIDPLSLFDRDKHLFTVNDFYYEVCLKVIEICRQTKDMNGGVISFQELEKVHFRKLNVGLDDLEKSIDMLKSLECFEIFQIRGKKFLRSVPNELTSDQTKILEICSILGYSSISLLKANLGWEAVRSKSALDEMVANGLLWIDYQGGAEALYWDPSWITRQL', 'label': array([1, 1, ..., 0, 0])} # 前22位为IDR - 数据特点:
- 序列长度不一,标注分布不均衡(如
disordered_protein_35中间段为IDR)。 - 需处理局部特征(如氨基酸组成)与全局依赖(如二级结构)。
- 序列长度不一,标注分布不均衡(如
三、解题方法详解
方法1:词向量 + 机器学习
-
步骤
- 词向量训练:使用 Word2Vec 将氨基酸序列转换为固定维度的向量(如 vector_size=100)。
model_w2v = gensim.models.Word2Vec( sentences=[list(x["sequence"]) for x in datas], # 修正:按字符分割 vector_size=100, min_count=1 ) - 特征提取:通过滑动窗口(如 ±2 个氨基酸)平均词向量,构建局部上下文特征。
- 分类模型:使用高斯朴素贝叶斯(GaussianNB)进行二分类。
- 词向量训练:使用 Word2Vec 将氨基酸序列转换为固定维度的向量(如 vector_size=100)。
-
优势与局限
- 优势:轻量级,易于实现。
- 局限:无法捕捉长程依赖关系,特征工程依赖人工设计。
方法2:BERT 实体识别
-
步骤
- 数据预处理:将氨基酸序列视为“句子”,每个氨基酸为“词”。
- 模型架构:
- 使用预训练 BERT 模型编码序列。
- 添加全连接层(Dense Layer)+ Sigmoid 输出概率。
- 训练策略:
- 损失函数:二元交叉熵(Binary Cross-Entropy)。
- 优化器:Adam。
-
优势与局限
- 优势:自动学习上下文表示,适合序列标注任务。
- 局限:计算资源需求高,需大量数据避免过拟合。
方法3:微调 Qwen 大模型
-
步骤
- 数据格式:将任务转化为指令微调(Instruction Tuning)形式,例如:
{ "instruction": "预测蛋白质序列中的IDR区域", "input": "MKQFGLA...", "output": "[1,1,...,0]" } - 模型加载:使用 Qwen 2.5-7B-Instruct,半精度加载(torch.bfloat16)。
- LoRA 微调:
- 冻结基座模型权重,仅训练低秩矩阵(A/B)。
- 参数配置:
config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", ...], r=8, lora_alpha=32, lora_dropout=0.1 )
- 数据格式:将任务转化为指令微调(Instruction Tuning)形式,例如:
-
优势与局限
- 优势:利用大模型泛化能力,LoRA 减少计算开销。
- 局限:需大量高质量指令数据,微调参数敏感。
四、模型结构解析
-
BERT 输入嵌入层
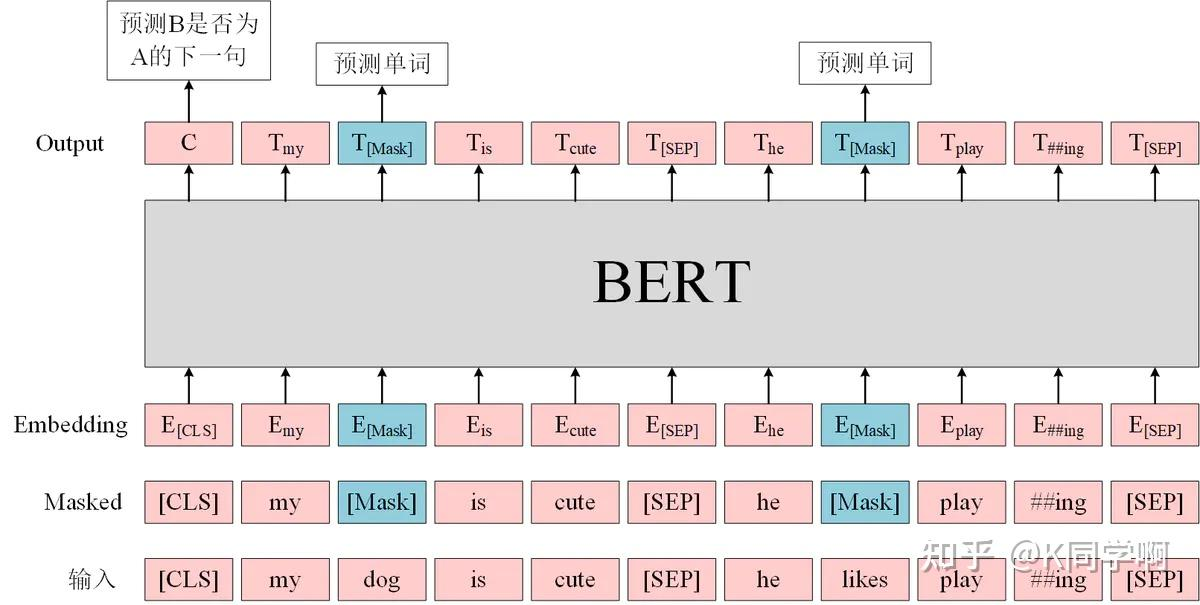
- 每个氨基酸对应 Token Embedding,叠加 Position/Segment Embedding 输入模型。
-
LoRA 机制
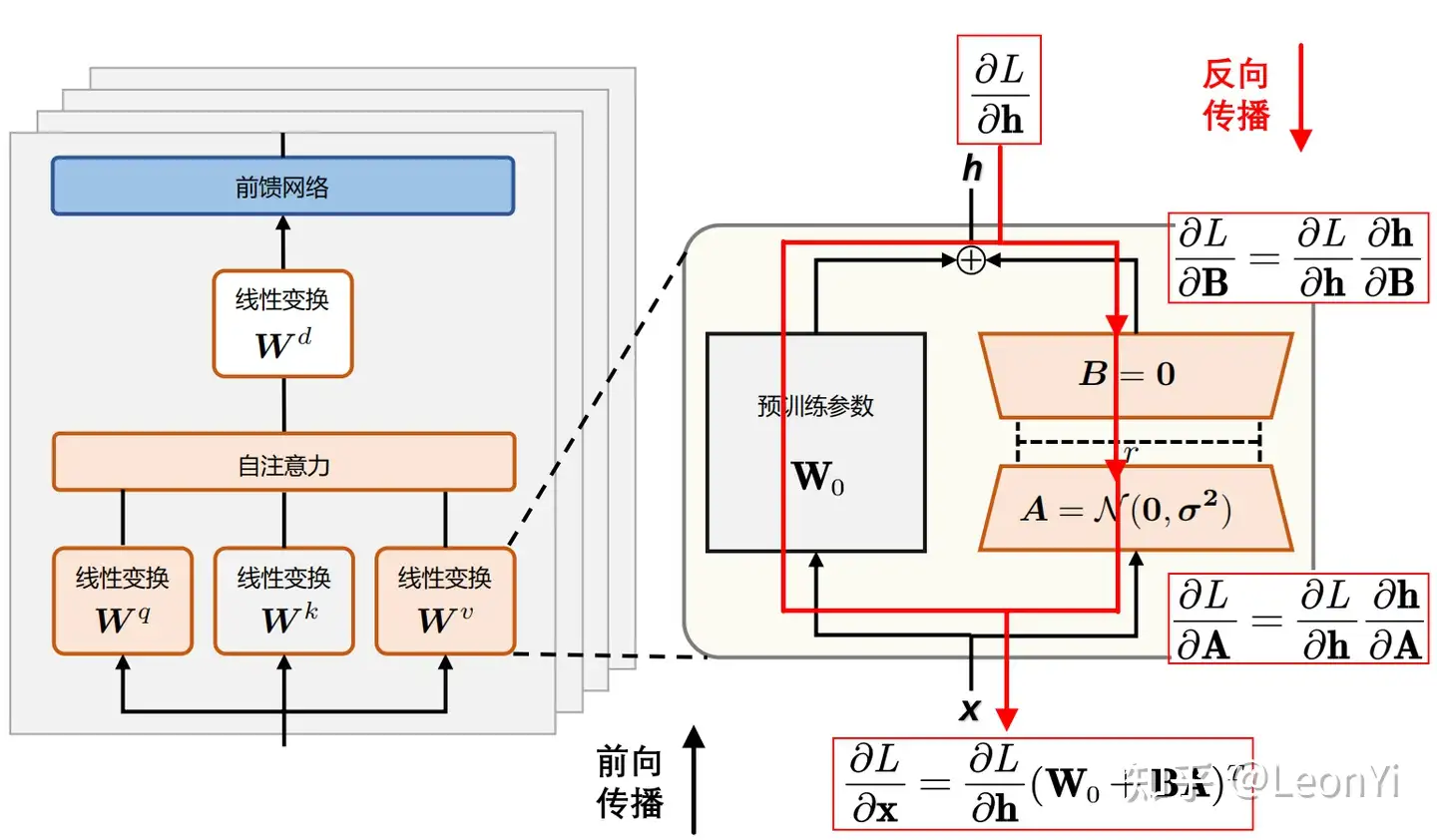
- 原线性层 ( W ) 分解为 ( W_0 + A \cdot B ),仅训练低秩矩阵 ( A ) 和 ( B )。
五、改进方向
- 数据增强:生成合成序列或利用同源序列扩展数据集。
- 多模态融合:结合物理化学特征(如疏水性、电荷)提升预测准确性。
- 模型集成:联合词向量方法与深度学习模型,互补捕捉局部与全局特征。
基于交流会的学习笔记
嘉宾分享内容的摘要
数据处理与模型选择
-
模型类型
- 推荐基于 Transformer、GPT 或 BERT 的架构,适合处理序列标注任务。
- 如果硬件支持,可以使用主流量化模型(如 QLoRA)进行训练。
-
数据处理
- 数据清洗:对原始数据进行基本预处理,例如去除噪声或异常值。
- 概率分布调整:如果数据符合某种统计分布(如正态分布),可通过公式更新数据集以增强质量。
- 数据质量优先:强调“进去的是垃圾,出来的也是垃圾”,建议将大部分时间用于数据处理。
-
特征工程
- 特征缩放:对数值型特征进行标准化或归一化。
- 特征选择:删除冗余或低价值特征,保留关键信息。
-
比赛流程建议
- 数据处理 > 模型选择 > 训练 > 部署
- 数据处理应占据 50% 以上的时间。
赛题分析与初步方案
-
赛题特点
- 输入:氨基酸序列(字符串形式)。
- 输出:每个氨基酸是否属于 IDR(二分类标签)。
- 挑战:
- 序列长度不均匀。
- 类别分布不平衡(无序/有序区域比例差异大)。
- 实验数据存在噪声。
-
解决方案
- 数据预处理:
- 使用 One-Hot 编码表示氨基酸。
- 添加理化性质特征(如疏水性、电荷等)。
- 插入蛋白质语言模型(如 ESM、ProteinBERT)编码序列上下文信息。
- 模型搭建:
- 基于 Transformer 架构设计序列标注模型。
- 输出层采用 Sigmoid 激活函数实现二分类。
- 数据预处理:
迁移学习与创新点
-
迁移学习
- 推荐 ProteinBERT,针对本次数据进行迁移学习。
- 迁移学习需要较大的语料库,但可显著提升模型表现。
-
原创性要求
- 需结合迁移学习结果,增加创新点(如新特征、模型改进等)。
Binary Classification 的思路
- 强调 IDRs 预测是一个典型的二分类问题。
- 提出从 ESM 等预训练模型入手,考虑模型压缩后的效果筛选策略。
使用 ESM 和云计算
-
预期目标
- 使用 ESM 预训练模型提取蛋白质序列特征,并结合云计算加速训练过程。
-
具体现象
- 单机训练可能受限于硬件资源,尤其是 GPU 内存不足。
-
解决方案
- 模型压缩:通过知识蒸馏或 LoRA(低秩适应)减少参数量。
- 云计算:利用云平台(如 AWS、阿里云)扩展计算资源,支持大规模训练。
使用其他模型参数
-
预期目标
- 利用现有预训练模型(如 AlphaFold2、AlphaFold3)提升模型性能。
-
具体现象
- 仅靠蛋白质序列 + 自定义模型,效果可能不足(模型无法理解残基倾向无序或常见组合)。
-
解决方案
- 允许使用的模型:
- AlphaFold2 和 AlphaFold3 官方发布的预训练模型。
- 允许使用的模型:
尝试选用其他训练模型
- Disobind:https://github.com/isblab/disobind
- 专注于预测蛋白质中的无序区域,提供多种特征工程方法。
- Sparrow:https://github.com/idptools/sparrow
- 提供快速的序列标注功能,适合处理长序列数据。
交流会的总结
1. 数据处理的核心地位
- 数据质量决定了模型上限。
- 关注以下几点:
- 序列编码:One-Hot 编码 + 理化性质特征。
- 类别平衡:通过过采样或欠采样解决不平衡问题。
- 噪声处理:剔除异常值或平滑数据。
2. 模型选择与迁移学习
- Transformer 架构:ESM、ProteinBERT 是首选,适合捕捉长程依赖关系。
- 迁移学习:利用 AlphaFold2/3 或其他预训练模型提升泛化能力。
- 模型压缩:通过 LoRA 或知识蒸馏降低计算成本。
3. 特征工程与创新点
- 新增特征:如二级结构预测、氢键网络等。
- 模型改进:结合多任务学习(如同时预测 IDR 和功能域)。
- 工具整合:测试 Disobind 和 Sparrow 等工具,汲取灵感。
4. 计算资源与效率
- 借助云计算扩展资源,避免单机训练瓶颈。
- 优化代码实现(如混合精度训练、分布式计算)。
在后续比赛中的重点
- 数据处理:完成序列编码与特征工程。
- 模型实验:对比不同预训练模型(ESM、ProteinBERT、AlphaFold2/3)。
- 工具测试:评估 Disobind 和 Sparrow 的适用性。
- 模型优化:尝试迁移学习与 LoRA 微调,提升预测精度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









