







AI基础扫盲
参考:
AI基础概念扫盲
AI安全扫盲
Matplot
人工智能最早可以追溯至 1956 年 8 月的达特茅斯会议
美国汉诺斯小镇的达特茅斯学院,以约翰 · 麦卡锡(John McCarthy)、马文 · 明斯基(Marvin Minsky)、克劳德 · 香农(Claude Shannon)、艾伦 · 纽厄尔(Allen Newell)、赫伯特 · 西蒙(Herbert Simon)等为首的科学家们相聚在一起,讨论如何让机器模拟人类的学习能力,并在此次会议中正式提出了“人工智能”这个概念。
简化概念:
智能的本质是针对不同情景给出针对性输出反应,人工智能便是通过人工搭建的方式实现这一功能
总结为一句话就是:让机器明白人类的世界,或者让思想可以被数学描述
实现一个ai需要一个黑箱和大量的数据进行机器学习
机器学习的特征工程步骤要手工完成且需要大量领域专业知识
深度学习可以通过大量数据训练自动得到模型,适用于提取特征图像(物体识别,场景识别,车型识别,人脸识别),语音(语音识别),自然语言领域(机器翻译,文本识别,聊天对话)
感知机
感知机由美国学者 FrankRosenblatt 在 1957 年提出来的。感知机是作为神经网络(深度学习)的起源的算法。因此,学习感知机的构造也就是学习通向神经网络和深度学习的一种重要思想。 感知机接收多个输入信号,输出一个信号。这里所说的“信号”可以想象成电流或河流那样具备“流动性”的东西。像电流流过导线,向前方输送电子一样,感知机的信号也会形成流,向前方输送信息。但是,和实际的电流不同的是,感知机的信号只有“流 / 不流”(1/0)两种取值。这里我们认为 0 对应“不传递信号”, 1 对应“传递信号”。
最早的模式识别算法模型:
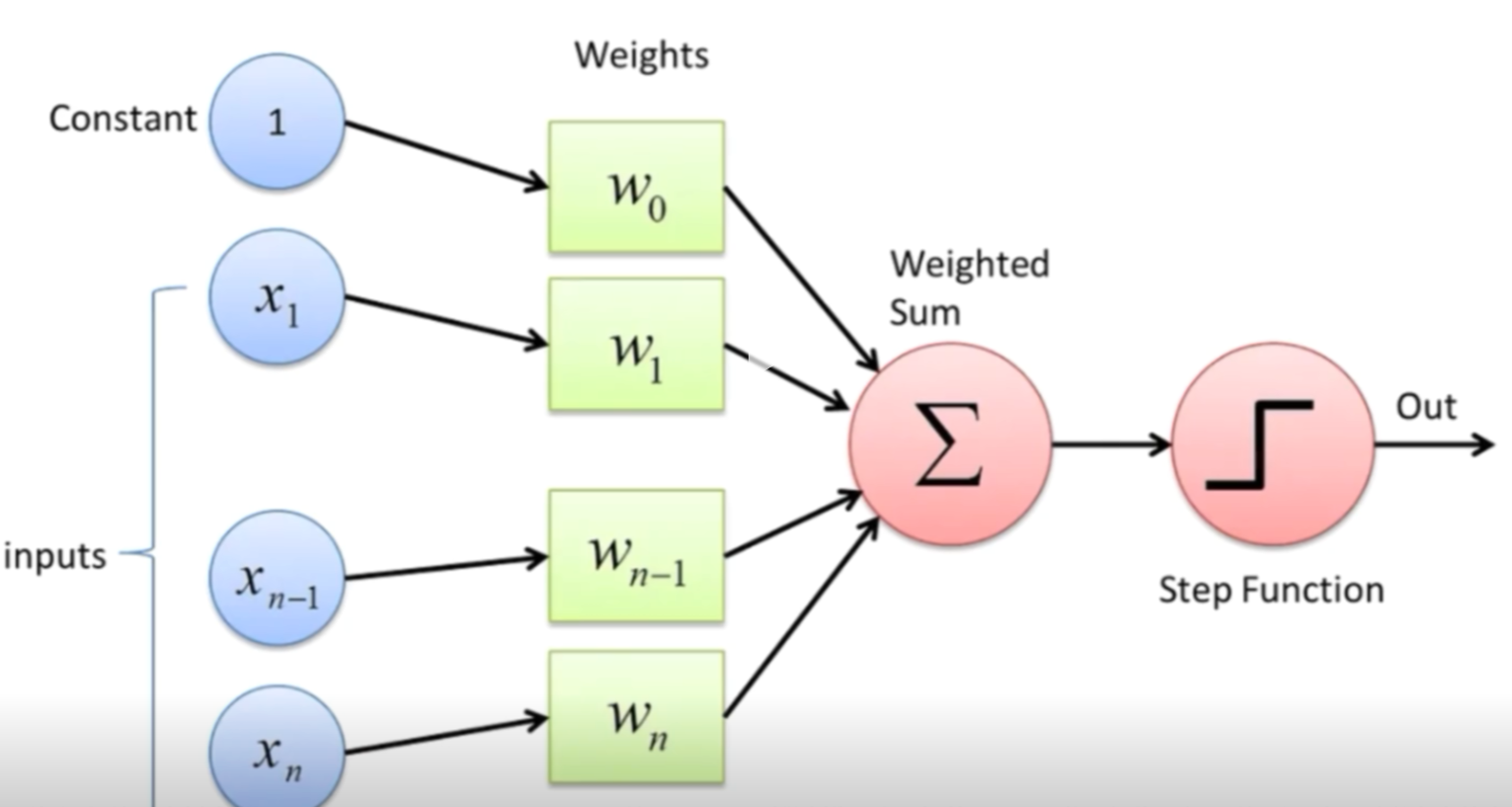
根据得到的信号经过运算后的结果,判断它与抽象函数的关系,这个过程可以抽象为一个感知机,也可以将整个感知机抽象化为一个数学模型
神经网络
这一概念来自于生物中的神经元细胞:
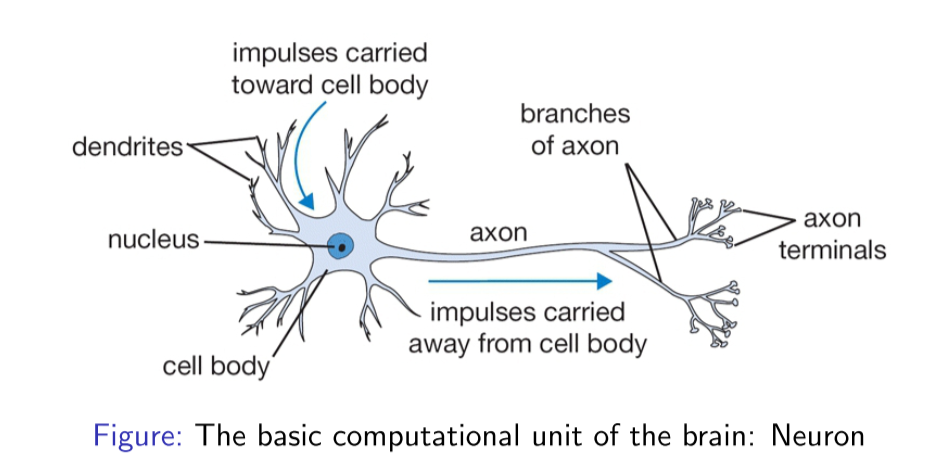 这是人体神经元的基本构成,其中树突主要用于接收其他神经元的信号,轴突用于输出该神经元的信号,数以万计的神经元相互合作,使得我们人类能够进行高级的思考,能够不断地对新事物进行学习。因此,我们就希望仿照人类神经网络的结构,搭建一种人为的神经网络结构,从而使其能够完成一些计算任务,这也是神经网络名字的由来。
这是人体神经元的基本构成,其中树突主要用于接收其他神经元的信号,轴突用于输出该神经元的信号,数以万计的神经元相互合作,使得我们人类能够进行高级的思考,能够不断地对新事物进行学习。因此,我们就希望仿照人类神经网络的结构,搭建一种人为的神经网络结构,从而使其能够完成一些计算任务,这也是神经网络名字的由来。
神经网络中计算的基本单元是 神经元 ,一般称作「节点」(node)或者「单元」(unit)。每个节点可以从其他节点接收输入,或者从外部源接收输入,然后计算输出。每个输入都各自的「权重」(weight,即 w),用于调节该输入对输出影响的大小,节点的结构如图所示:
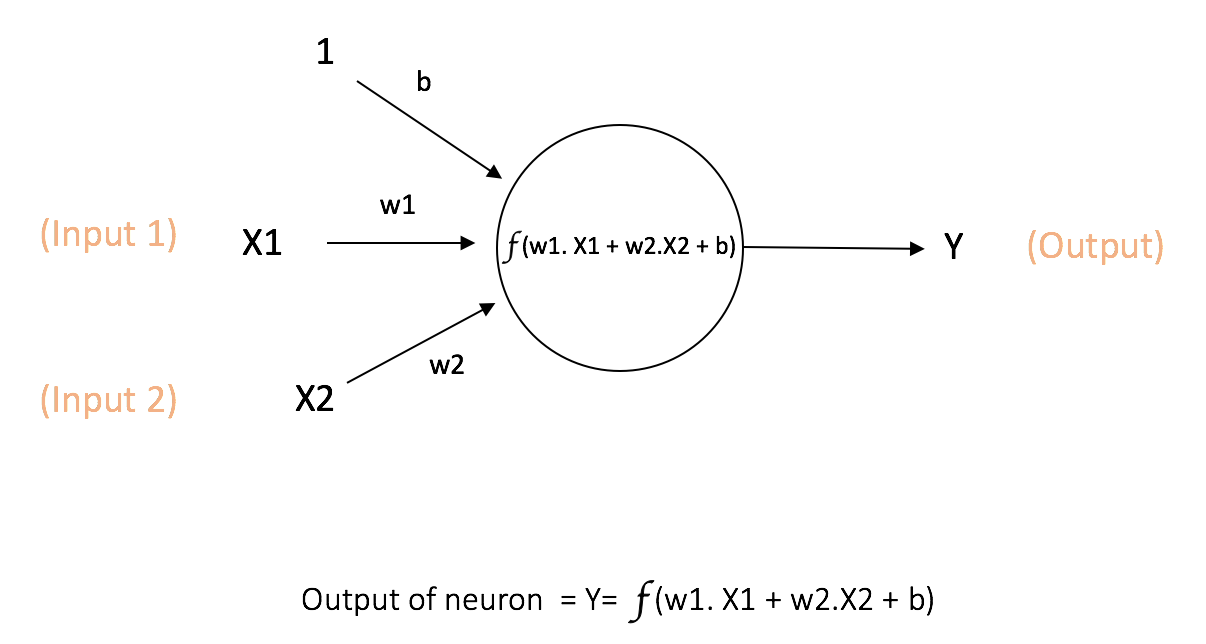 其中 x1, x2 作为该节点的输入,其权重分别为 w1 和 w2。同时,还有配有「偏置 b」(bias)的输入 ,偏置的主要功能是为每一个节点提供可训练的常量值(在节点接收的正常输入以外)。
其中 x1, x2 作为该节点的输入,其权重分别为 w1 和 w2。同时,还有配有「偏置 b」(bias)的输入 ,偏置的主要功能是为每一个节点提供可训练的常量值(在节点接收的正常输入以外)。
多层感知机MLP
《感知机》指出感知机是一个连异或都处理不好的废物,事实正是这样,我们可以用一个线性函数划分是与非的边界,但是对于异或这种关系,没有办法用一个清晰的线性函数表示,于是AI被打入冷宫。
守得云开见月明,我们貌似没必要非得用一个就得到想要的结果,思考是一个漫长的过程,多来几次未尝不可,神经网络获得了新的突破——Multilayer Perceptron就此诞生
《从简单的数字识别到全面了解MLP》:
对于人类来说识别一个数字是非常简单的,但对于机器那就相当复杂,图片转换为密密麻麻数字组成的矩阵(现在对于你来说是不是就复杂多了),运用MLP的思想,我们没必要让它一下就能够看出来这是数字几,逐步进行:首先识别简单的笔画和边缘,后面的神经元负责将这些基础特征组合,从而识别更复杂的概念(比如:折线,曲线等),更深的是神经元组合复杂图像进行识别。当然这里只是方便理解这样说的,真实情况要比这个复杂,更趋向于数学化
最典型的 MLP包括三层: 输入层、隐层(全连接层)和输出层 (全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)
由中学的最小二乘法引发对梯度下降的学习:
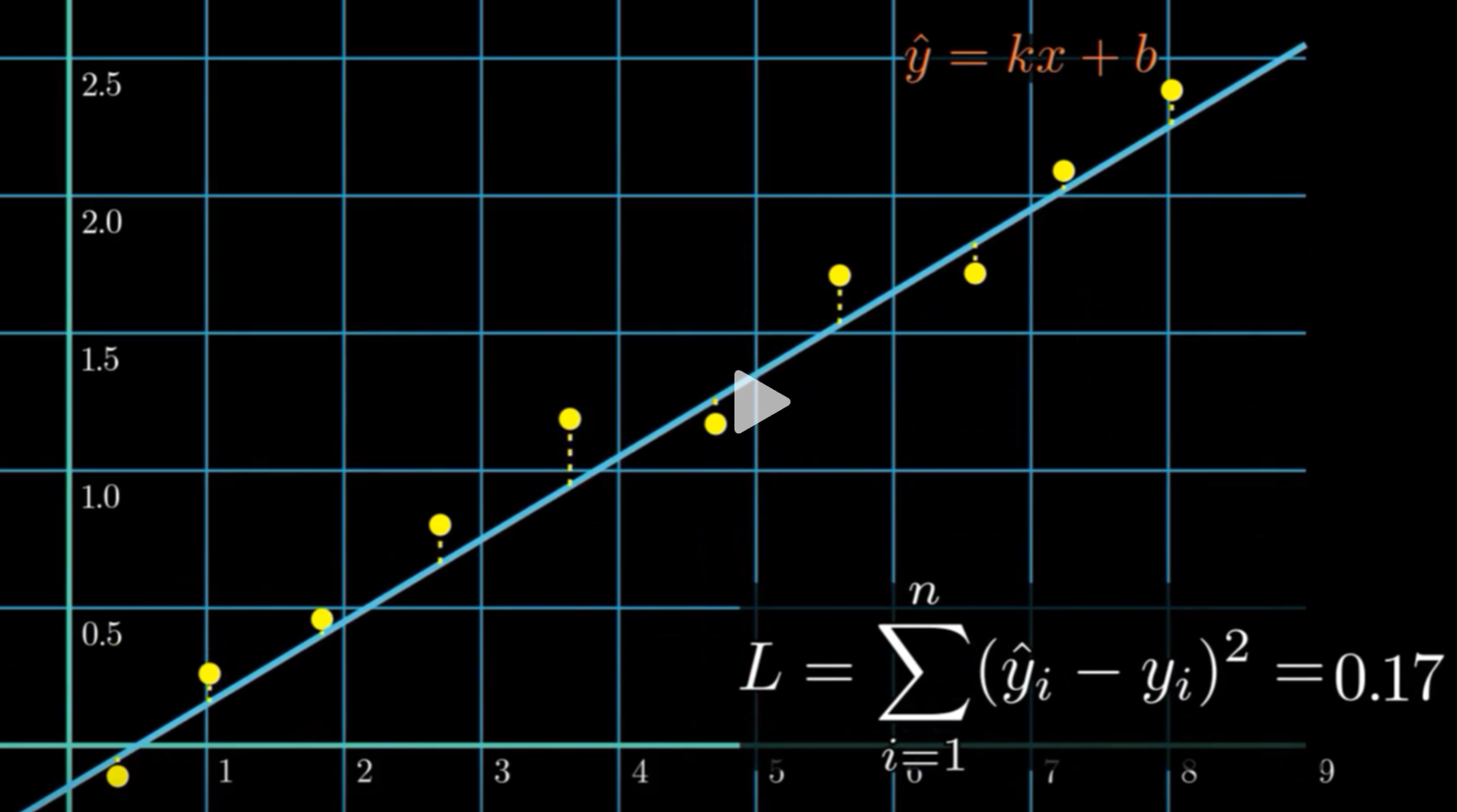
拟合函数和数值偏差平方和得到损失函数,复杂的非线性里也是一样的道理。损失函数的目的是衡量一个模型和真实结果之间的偏差程度,获取损失函数最低的参数,从而得到出色的拟合函数
新的问题又来了,想要一个几乎完美的拟合函数可能就需要多个参数,同时改变多个想想都头疼!(在数学当中被称作非突优化,可谓是臭名昭著)
于是在1976年,Seppo Linnainmaa提出的梯度下降算法并于1986年由David Rumelhart,Geoffrey Hinton和Ronald Williams提出反向传播算法共同解决这个令人头大的问题
梯度下降
最小二乘法解决了数据中数的问题,那么在一个曲线函数中如何找到最低点?哈哈哈,Δx趋近于无线小的时候,Δy/Δx趋向于定值,也就是我们平时所说的导数,这不我们成功找到了想要的点。再加点难度,我们现在在二元函数图形上找最低点该如何做?相信大一下学期的高数知识应该牢记于心了吧,那就是偏导数(忘记的快去学习),我们来将抽象知识具象化一下,在二元曲面当中用平面切割得到曲线再在曲线上求导得到点,这便是梯度。再用之前的方法做类似处理便得到同时调节两个参数的拟合函数。更多的参数也不过如此
简述梯度下降:每次减小一点观察要向那个方向走,向这个方向走一点点,不断重复上述流程,缩小损失函数,直到得到结果
反向传播BP
大部分人深度学习劝退的第一步,从链式法则推导BP精简版了解神经网络思想:
中学学习过求导的基本法则,和导等导和,前导后不导之类的,对于复合函数求导在大学一开始,我们又进行了学习,就此链式法则变很好推到的BP的学习当中。
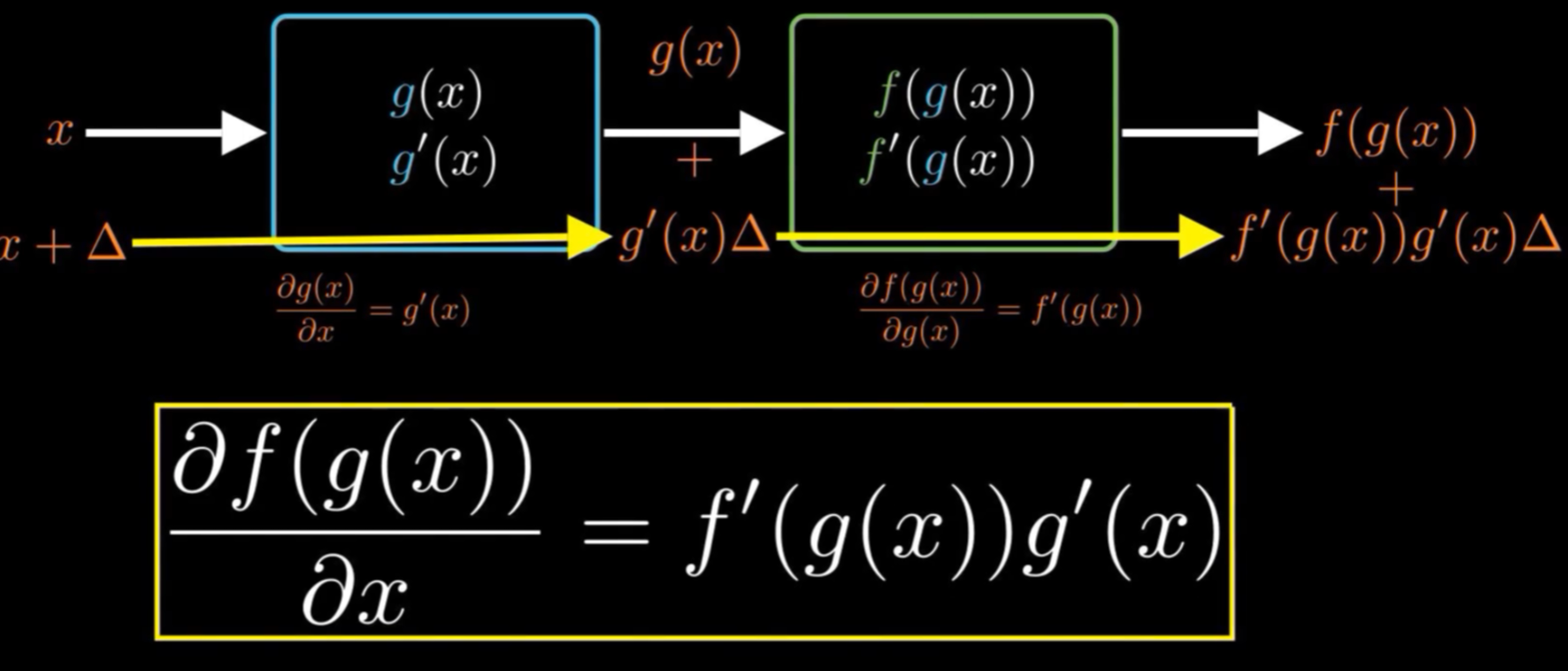
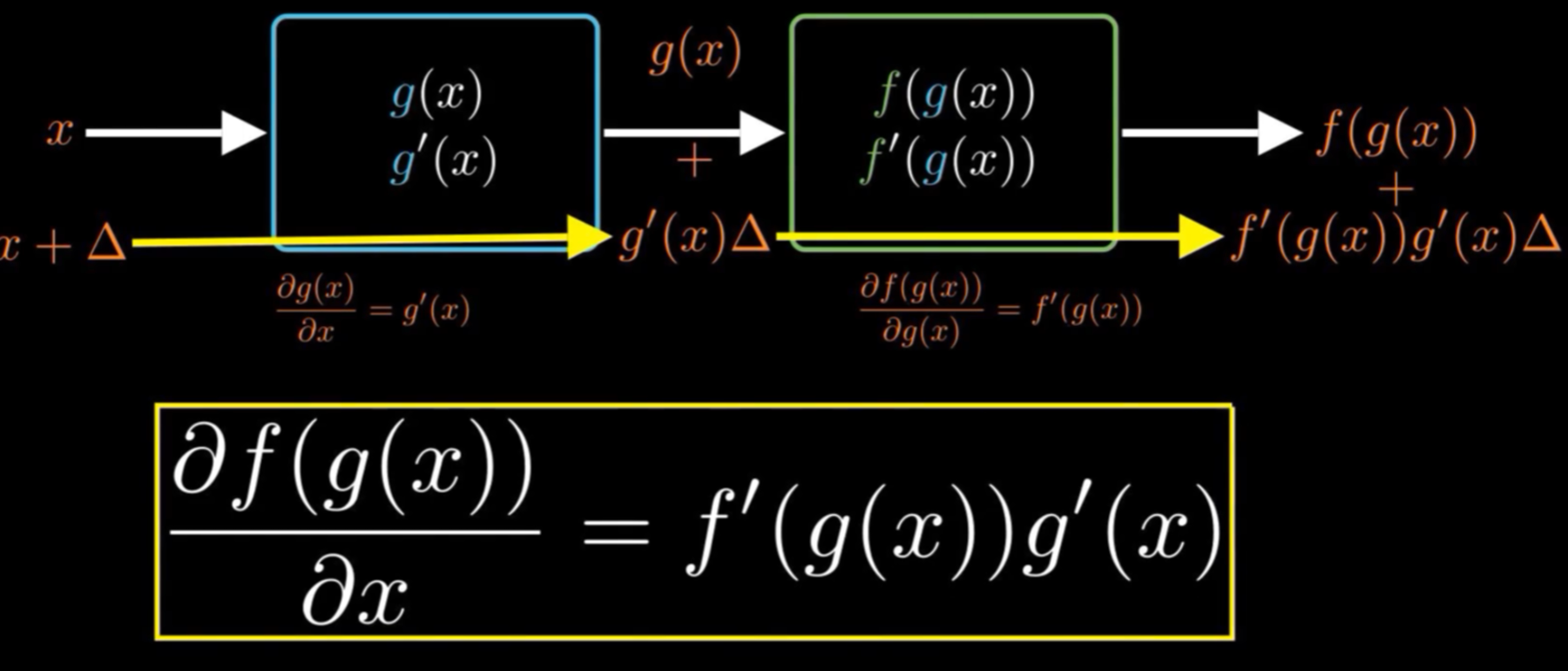
从后向前将每一层嵌套这个传导的导函数一步一步乘在一起,回到最开始的位置时,就得到了开始位置相对于整个损失函数的梯度
泛化
运用前面的知识就可以实现一个几乎完美的感知机,但是,如果给的图片不是训练范围内的该如何是好?这也即使我们通常说的举一反三,官方语言是泛化(Generalization)
对于平面中给定的一堆点,我们用前面的方法拟合出一个函数,那么对于没给出的点就可以用这个函数预测出来。可事实上,我们在现实生活中无法抽象的完美拟合出这样的函数,这是一种更抽象的趋势·。俗话说,量变引起质变,当我们给它投喂足够多的数据,那么机器就可以得到我们意料之外的结果,我们可以戏称它为黑盒中的黑盒。
由于是黑盒中的黑盒因此我们无法理解更深层的运作规律,谁也不知道它从数据集中悟出了什么,就好像你和另一半整天呆在一起,猜不出他在怎样想你是一个道理。(这也让我认识了AI的可怕之处,越来越接近人类,甚至超越人类,是否真的会出现人类与AI大战的一天或是人类就是某种更高维度生物创造的AI)
典型的例子就是对抗样本,最简单的CTF题目分析:【2020年西湖论剑】中的指鹿为马
MNIST数据集
Mixed National Institute of Standards and Technology database来自美国国家标准与技术研究所,训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集 (test set) 也是同样比例的手写数字数据。是一个用来训练各种图像处理系统的二进制图像数据集,广泛应用于机器学习中的训练和测试。作为一个入门级的计算机视觉数据集,发布 20 多年来,它已经被无数机器学习入门者“咀嚼”千万遍,是最受欢迎的深度学习数据集之一

整个数据集包含两部分,训练集 和 测试集。
训练集 60000 张图像,其中 30000 张来自 NIST 的 Special Database 3,30000 张来自 NIST 的 Special Database 1;测试集 10000 张图像,其中 5000 张来自 NIST 的 Special Database 3,5000 张来自 NIST 的 Special Database 1。
MNIST 原始的 Special Database 3 数据集和 Special Database 1 数据集均是二值图像,MNIST 从这两个数据集中取出图像后,通过图像处理方法使得每张图像都变成 28 × 28 大小的灰度图像,且手写数字在图像中居中显示
demo:
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
# 依据API-datasets创建MBIST数据集
train_dataset = datasets.MNIST(root='data', # 文件存储位置
train=True, # 是否是训练集
transform=transforms.ToTensor(), # 数据集数据如何处理
download=True) # 是否运行下载
# 使用API-DataLoader载入数据集
train_loader = DataLoader(dataset=train_dataset, # 数据集
batch_size=BATCH_SIZE, # 大小
shuffle=True) # 是否打乱
编写第一个AI
搭建完整的AI编程
首先确保安装了GPU环境,即Anaconda、CUDA和CUDNN
CUDA和CUDNN安装
确保电脑显卡驱动支持的CUDA版本,鼠标右键桌面空白处:选中“NIVIDIA 控制面板”,"帮助-系统信息“在显示和组件中发现我的电脑是4060Ti 驱动程序版本561.03 支持12.6及以下的CUDA版本
CUDA下载这里选择12.3.0版本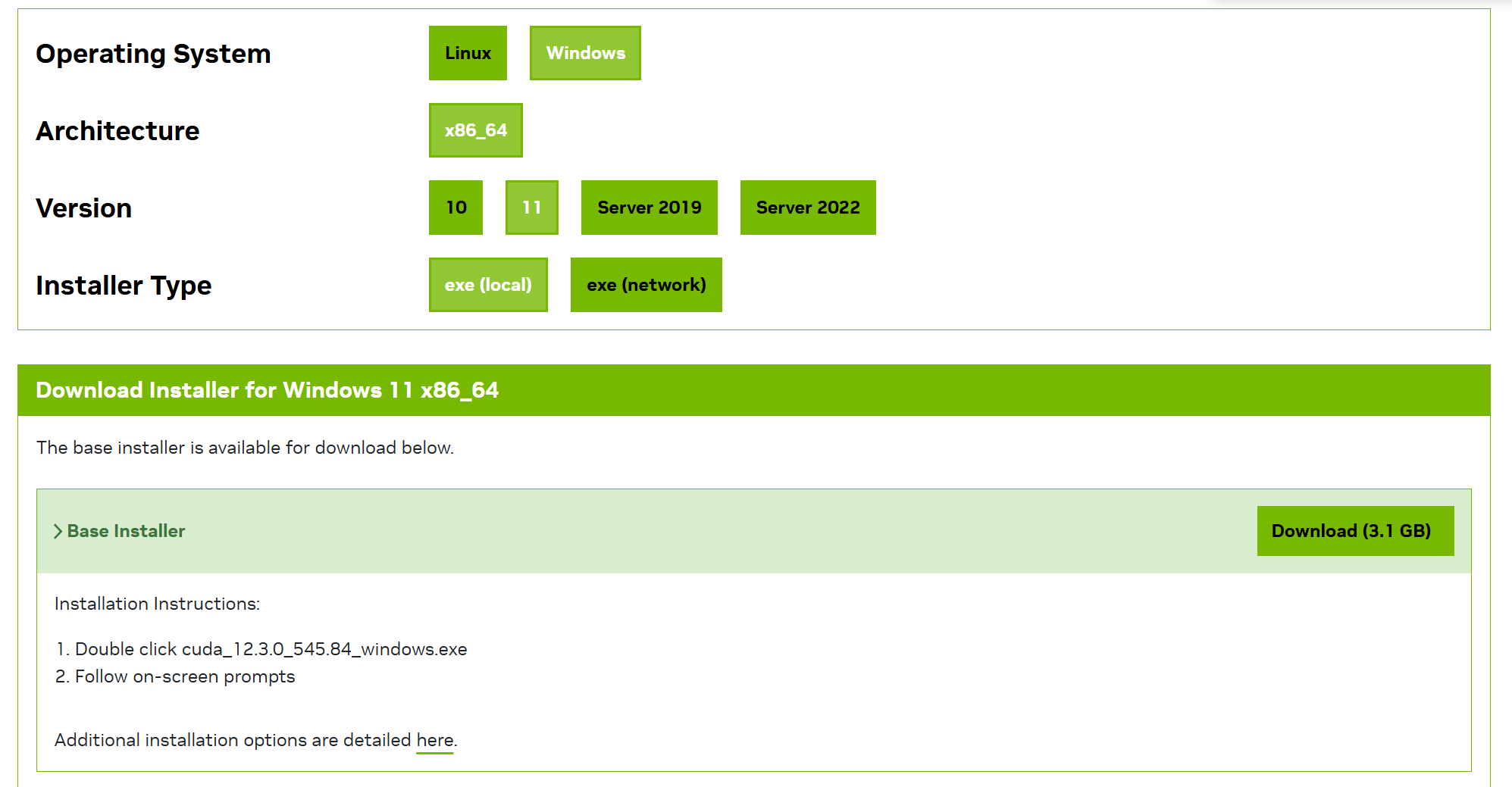
CUDNN作为CUDA的补丁,专为深度学习运算进行优化
[CUDNN下载](cuDNN 9.7.1 Downloads | NVIDIA Developer)将下载的文件解压到CUDA\v12.3.0目录下,添加系统变量中的Path,包含bin,include,lib,libnvvp
Anaconda安装
清华源镜像下载Anaconda下载,依次执行安装即可,红色提示:不推荐你打第一个勾,可能会影响你卸载和重新安装Anaconda。如果担心的话,就别打第一个勾,自己手动配置环境变量(在系统path中添加),在终端使用conda --version检验是否安装完成,目前使用的是conda 4.8.3
使用方法:
查看虚拟环境列表:conda env list或者conda info --envs
删除环境:conda remove -n xxx(名字) --all(加上删除虚拟环境,不加删除包)
创建新虚拟环境:conda creat -n xxx(名字) python=3.8
进入虚拟环境:activate xxx(名字)
查看虚拟环境库:pip list
退出虚拟环境:deactivate
pytorch安装

我们将选用PyTorch作为入门神经网络/大模型/ai的第一个框架,TensorFlow不是更好吗?为什么不用它?好问题,为啥编程语言要先学C而不是Rust,它不是更安全吗?(真是个爱问问题的麻瓜啊)
- 主要维护方: Facebook
- 支持的语言: C/C++/Python
- GitHub 源码地址: https://github.com/pytorch/pytorch
PyTorch 是 Facebook 团队于 2017 年 1 月发布的一个深度学习框架,虽然晚于 TensorFlow、Keras 等框架,但自发布之日起,其受到的关注度就在不断上升,目前在 GitHub 上的热度已经超过 Theano、Caffe、MXNet 等框架。
Pytorch 是基于用 Lua 编写的 Torch 库的 Python 实现的深度学习库,目前被广泛应用于学术界和工业界,随着 Caffe2 项目并入 Pytorch,也稳固了 Pytorch 紧追并迫近 TensorFlow 在深度学习应用框架领域的地位。
Pytorch 库足够简单,跟 NumPy,SciPy 等可以无缝连接,而且基于 tensor 的 GPU 加速非常给力
Pytorch 是基于训练网络迭代的核心-梯度的计算,Autograd 架构(借鉴于 Chainer),在 Pytorch,我们可以动态的设计网络,而无需笨拙的定义静态网络图,基于简单,灵活的设计,Pytorch 快速成为了学术界的主流深度学习框架。
不过现在,如果稍微深入的了解 TensorFlow 和 Pytorch,就会发现他们越来越像:TF 加入了动态图架构,Pytorch 致力于其在 工业界更加易用 。打开各自的官网,你也会发现文档风格也越发的相似。
打开Anaconda Prompt,输入conda create -n pytorch python=3.12
检测创建虚拟环境:conda env list
PyTorch下载,根据coda版本进行选择复制命令在对应虚拟环境中选择执行
相关库学习
Numpy
几乎所有的数据科学、机器学习和科学计算库都深深地依赖于NumPy
NumPy的核心是 ndarray 对象,是一种高效的N为数组,更具体的名字时张量
NumPy对象最强大的特性之一就是可以进行高效的算术运算,主要分为两种: 元素级运算(element-wise)和与单一数值的运算(scalar)
创建
import numpy as np
#从列表创建ndarray
list = [1, 2, 3, 4]
np_list = np.array(list)
print(f"数据:{np_list},\n类型转化:{type(list)}--->{type(np_list)}")
print(f"ndim查看ndarray维度:{np_list.ndim}")
#从元组创建ndarray
tuple = (1, 1, 1, 1)
np_tuple = np.array(list)
print(f"数据:{np_tuple},\n类型转化:{type(tuple)}--->{type(np_tuple)}")
print(f"全零ndarray:\n{ np.zeros((3, 4))}")
print(f"全一ndarray:\n{ np.ones((3, 3),dtype=int)}") #dtype控制数据类型
#指定数据填充的ndarray
np_full = np.full((3, 3), 7)
print(f"指定数据填充的ndarray:\n{np_full}")
#创建等差数列ndarray
np_arange = np.arange(0, 10, 5, dtype=int)
np_linspace = np.linspace(0, 1, 5, endpoint=False, dtype=float)
print(f"arange创建等差数列ndarray: {np_arange}\nlinspace创建等差数列ndarray: {np_linspace}")
#创建随机ndarray
np_random_randn = np.random.randn(3, 4)
np.random.seed(0)
np_random_seed = np.random.rand(2, 2, 2)
print(f"randn创建随机ndarray:\n{np_random_randn}\nseed创建随机ndarray:\n{np_random_seed}")
运算
import numpy as np
#元素级运算:两个形状相同的数组之间,对应位置的元素进行运算
narray1 = np.array([[1, 2, 3], [4, 5, 6]])
narray2 = np.array([[7, 8, 9], [10, 11, 12]])
print(f"""元素级加法:\n{narray1 + narray2}\n
元素级减法:\n{narray1 - narray2}\n
元素级乘法:\n{narray1 * narray2}\n
元素级除法:\n{narray1 / narray2}\n
元素级指数:\n{narray1 ** 2}""")
#单一数值运算:数组中的每个元素都与同一个数值进行运算
narray3 = np.array([[1, 2, 3], [4, 5, 6]])
scalar = 2
print(f"""单一数值加法:\n{narray3 + scalar}\n
单一数值减法:\n{narray3 - scalar}\n
单一数值乘法:\n{narray3 * scalar}\n
单一数值除法:\n{narray3 / scalar}\n
单一数值指数运算:\n{narray3 ** scalar}""")
#广播:实现不同形状的数组运算
"""
Numpy自动扩展维度较小的数组,使其与高维数组形状兼容,然后进行元素级运算
数组的维度不同,但维度较小的数组的形状在前面补1,直到维度数量与维度较大的数组相同
两个数组在各个维度上的长度相等,或者其中一个数组在该维度上的长度为1
如果这两个条件都不满足,NumPy 会抛出 ValueError: operands could not be broadcast together with shapes ... 错误,表示无法进行广播
"""
narray_2d = np.array([[1, 2, 3], [4, 5, 6]])
scalar = 10
broadcast_narray_scalar = narray_2d + scalar # 标量 10 被广播成 [[10, 10, 10], [10, 10, 10]],然后与 array_2d 相加
print(f"标量广播:\n{broadcast_narray_scalar}")
类型转化
nd_narray = np.arange(12)
print(f"n维数组:\n{nd_narray}\n形状(shape): {nd_narray.shape}")
print(f"维度是: {nd_narray.ndim}")
#使用reshape修改形状,但是总元素必须保持一致,一个维度设置为-1,numpy自动计算该维度
nd_re_narray = nd_narray.reshape((3, -1))
print(nd_re_narray)
#flatten():浅拷贝
flatten_nd_narray = nd_narray.flatten()
print(flatten_nd_narray)
#ravel():深拷贝
ravel_nd_narray = nd_narray.ravel()
print(ravel_nd_narray)
#修改数据后的flatten和ravel区别
flatten_nd_narray[0] = 100
print(f"修改flatten:{flatten_nd_narray}\n修改后原数组:{nd_narray}")
ravel_nd_narray[0] = 200
print(f"修改ravel:{ravel_nd_narray}\n修改后原数组:{nd_narray}")
#astype():改变数组的数据类型
astype_nd_narray = nd_narray.astype(np.float64)
print(f"""修改前数据类型:{nd_narray.dtype},
修改后数据:{astype_nd_narray},
修改后数据类型:{astype_nd_narray.dtype}""")
定位数据
nd_narray = np.arange(24).reshape((2,3,4))
print(f"3维数组:\n{nd_narray}")
#索引:用于定位单个数据
print(f"索引:第二个深度,第二行,第三列元素: {nd_narray[1, 1, 2]}")
#切片:获取一部分元素,可以连续也可以不连续
print(f"切片:第一个深度,前两行,前两列: \n{nd_narray[0, 0:2, 0:2]}")
print(f"切片:所有深度,第二行到最后一行,所有列: \n{nd_narray[:, 1:, :]}")
#布尔索引:选中为True否则False
bool_narray = nd_narray[nd_narray > 15]
print(f"布尔数据:{bool_narray}")
#花式索引:允许使用整数数组作为索引
array_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print(f"2维数组:\n{array_2d}")
# 使用整数数组作为行索引和列索引
row_indices = np.array([0, 2]) # 行索引
col_indices = np.array([1, 3]) # 列索引
fancy_indexed_array = array_2d[row_indices, col_indices] # 选取 (0, 1) 和 (2, 3) 位置的元素
print(f"花式索引结果: {fancy_indexed_array}") # 输出: [ 2 12] (选取了 array_2d[0, 1] 和 array_2d[2, 3])
# 选取多行,所有列
row_indices_multi = np.array([0, 0, 1, 2, 2]) # 重复选取行
fancy_indexed_array_multi_row = array_2d[row_indices_multi, :] # 选取指定行,所有列
print(f"花式索引 (多行): \n{fancy_indexed_array_multi_row}")
MatPoltlib
学习这个主要是为了将模型数据进行可视化,当然我是CTF狗,用来做Musc真香
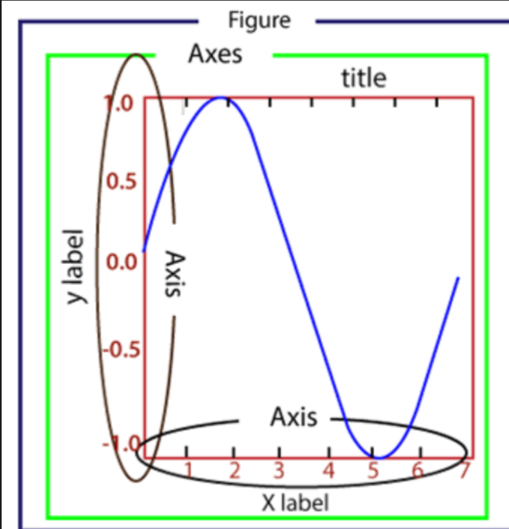
Canvas:位于最底层的系统层,在绘制过程充当画板
Figure:Canves上方第一层也是用户来操作应用层的第一层,在绘制过程充当画板
Axes:应用层的第二层,在绘制过程充当画布上绘制区
Axis:指坐标系中的垂直轴与水平轴,包含轴的长度大小(图中轴长为 7)、轴标签(指 x 轴,y轴)和刻度标签
Artist:您在画布上看到的所有元素都属于 Artist 对象,比如文本对象(title、xlabel、ylabel)、Line2D 对象(用于绘制2D图像)等
许多第三方工具包都对 Matplotlib 进行了功能扩展,其中有些安装包需要单独安装,也有一些允许与 Matplotlib 一起安装
常见的工具包如下:
Basemap:这是一个地图绘制工具包,其中包含多个地图投影,海岸线和国界线
Cartopy:这是一个映射库,包含面向对象的映射投影定义,以及任意点、线、面的图像转换能力
Excel tools: 这是 Matplotlib 为了实现与 Microsoft Excel 交换数据而提供的工具
Mplot3d:它用于 3D 绘图
Natgrid:这是 Natgrid 库的接口,用于对间隔数据进行不规则的网格化处理
Matplotlib.pyplot接口
绘图类型
| fucation | describe |
|---|---|
| Bar | 绘制条形图 |
| Barh | 绘制水平条形图 |
| Boxplot | 绘制箱型图 |
| Hist | 绘制直方图 |
| his2d | 绘制2D直方图 |
| Pie | 绘制饼状图 |
| Plot | 在坐标轴上画线或者标记 |
| Polar | 绘制极坐标图 |
| Scatter | 绘制x与y的散点图 |
| Stackplot | 绘制堆叠图 |
| Stem | 用来绘制二维离散数据绘制(又称为“火柴图”) |
| Step | 绘制阶梯图 |
| Quiver | 绘制一个二维按箭头 |
Iamge函数
| fucation | describe |
|---|---|
| Imread | 从文件中读取图像的数据并形成数组 |
| Imsave | 将数组另存为图像文件 |
| Imshow | 在数轴区域内显示图像 |
Axis函数
| fucation | describe |
|---|---|
| Axes | 在画布(Figure)中添加轴 |
| Text | 向轴添加文本 |
| Title | 设置当前轴的标题 |
| Xlabel | 设置x轴标签 |
| Xlim | 获取或者设置x轴区间大小 |
| Xscale | 设置x轴缩放比例 |
| Xticks | 获取或设置x轴刻标和相应标签 |
Figure函数
| fucation | describe |
|---|---|
| Figtext | 在画布上添加文本 |
| Figure | 创建一个新画布 |
| Show | 显示数字 |
| Savefig | 保存当前画布 |
| Close | 关闭画布窗口 |
#绘制2pi范围内的余弦函数
import matplotlib.pyplot as PLT
import numpy as np
import math
x = np.arange(0, math.pi * 2, 0.05)
y = np.sin(x)
PLT.plot(x,y)
PLT.xlabel("x")
PLT.ylabel("y")
PLT.title('sin-function(0-2*pi)')
PLT.show()
#PyLab绘制曲线图
#语法类似于MATLAB,可是当时学《线性代数》时没有好好学,只得重学了,我是废物啊!!!
from pylab import *
x = linspace(-3, 3, 30)
y = x ** 2
plot(x, y, 'm-')
plot(x, -sin(x), 'g.')
plot(x, cos(x), 'c-.')
plot(x, arctan(x), 'b-')
# 符号:-,--,-.,.,:,,,o,<,>,^,v,s,+,x,D,d,1,2,3,4,h,H,p,_
# 颜色:b(蓝色),g(绿色),r(红色),c(青色),m(品红),y(黄色),k(黑色),w(白色)
import matplotlib.pyplot as plt
y = [1, 4, 9, 16, 25, 36, 49, 64]
x1 = [1, 16, 30, 42, 55, 68, 77, 88]
x2 = [1, 6, 12, 18, 28, 40, 52, 65]
fig = plt.figure()
ax = fig.add_axes([0, 0, 1, 1])
l1 = ax.plot(x1, y, 'ys-')
l2 = ax.plot(x2, y, 'go--')
"""
legend函数:
handles参数作为一个序列包含所有线型实例
labels是一个字符串序列,用来指定标签的名称
loc指定图例位置的参数,其参数值可以用字符串或整数来表示,例如
位置 字符串表示 整数数字表示
自适应 Best 0
右上方 upper right 1
左上方 upper left 2
左下 lower left 3
右下 lower right 4
右侧 right 5
居中靠左 center left 6
居中靠右 center right 7
底部居中 lower center 8
上部居中 upper center 9
中部 center 10
"""
ax.legend(labels = ('tv', 'Smartphone'), loc = 0)
ax.set_title("Advertisement effect on sales")
ax.set_xlabel('medium')
ax.set_ylabel('sales')
plt.show()
import matplotlib.pyplot as plt
plt.subplot(211)
plt.plot(range(6))
plt.subplot(212, facecolor='y')
plt.plot(range(12))
import matplotlib.pyplot as plt
import numpy as np
import math
x = np.arange(0, math.pi*2, 0.05)
fig=plt.figure()
axes1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # main axes
axes2 = fig.add_axes([0.55, 0.55, 0.3, 0.3]) # inset axes
y = np.sin(x)
axes1.plot(x, y, 'b')
axes2.plot(x,np.cos(x),'r')
axes1.set_title('sine')
axes2.set_title("cosine")
plt.show()
import matplotlib.pyplot as plt
fig,a = plt.subplots(2,2) # 一张画板创建四张图
import numpy as np
import math
x = np.arange(0, math.pi*2, 0.05)
#绘制sin_fucation图像
a[0][0].grid(True) #绘制网格
a[0][0].plot(x, sin(x))
a[0][0].set_title('sin_fucation')
#绘制cos_fucation图像
a[0][1].grid(color='b', ls = '-.', lw = 0.25) #控制绘制网格的样式颜色粗细
a[0][1].plot(x, cos(x))
a[0][1].set_title('cos_fucation')
#绘制tan_fucation图像
a[1][0].plot(x, tan(x))
a[1][0].set_title('tan_fucation')
a[1][0].set_ylim(-50, 50)
#绘制对数函数
a[1][1].plot(x,np.log10(x))
a[1][1].set_title('log')
a[1][1].set_xlim(0, 10)
plt.show()
#自由分区
import matplotlib.pyplot as plt
#使用colspan指定列,使用rowspan指定行
a1 = plt.subplot2grid((3,3), (0,0), colspan = 2)
a2 = plt.subplot2grid((3,3), (0,2), rowspan = 2)
a3 = plt.subplot2grid((3,3), (1,0), rowspan = 2, colspan = 2)
import numpy as np
x = np.arange(1,10)
a1.plot(x, np.exp(x))
a1.set_title('exp')
a2.plot(x, x*x)
a2.set_title('square')
a3.plot(x, np.log(x))
a3.set_title('log')
a3.set_xticks([0, 2, 4, 6, 8])
a3.set_xticklabels(['zero', 'two', 'four', 'six', 'eight'])
plt.tight_layout()
plt.show()
"""
网格区域为3*3大小
a1位置为第一行第一列,跨越两列大小
a2位置为第一行第三列,占三行大小
a3位置为第二行第一列,占两行、两列大小
"""
#Matplotlib中文乱码处理方案,默认支持ASCII,讲解在 Windows 环境下让 Matplotlib 显示中文
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
year = [2017, 2018, 2019, 2020]
people = [20, 40, 60, 70]
plt.plot(year, people)
plt.xlabel('年份')
plt.ylabel('人口')
plt.title('人口增长')
plt.yticks([0, 20, 40, 60, 80])
plt.fill_between(year, people, 20, color = 'green')
plt.show()
#另一种方案则是在目录下修改ttf
双轴图
#双轴图
import matplotlib.pyplot as plt
import numpy as np
#创建图形对象
fig = plt.figure()
#添加子图区域
a1 = fig.add_axes([0,0,1,1])
#准备数据
x = np.arange(1,11)
#绘制指数函数
a1.plot(x,np.exp(x))
a1.set_ylabel('exp')
#添加双轴
a2 = a1.twinx()
#‘ro’表示红色圆点
a2.plot(x, np.log(x),'ro-')
#绘制对数函数
a2.set_ylabel('log')
#绘制图例
fig.legend(labels = ('exp','log'),loc='upper left')
plt.show()
柱状图
#双轴图
import matplotlib.pyplot as plt
import numpy as np
#创建图形对象
fig = plt.figure()
#添加子图区域
a1 = fig.add_axes([0,0,1,1])
#准备数据
x = np.arange(1,11)
#绘制指数函数
a1.plot(x,np.exp(x))
a1.set_ylabel('exp')
#添加双轴
a2 = a1.twinx()
#‘ro’表示红色圆点
a2.plot(x, np.log(x),'ro-')
#绘制对数函数
a2.set_ylabel('log')
#绘制图例
fig.legend(labels = ('exp','log'),loc='upper left')
plt.show()
```#### 柱状图
```python
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1, 2)
# 准备数据
Categories = ['Web', 'Misc', 'Pwn', 'Reverse', 'Crypto']
students = [[30, 16, 36, 50, 15], [23, 17, 35, 29, 12]]
ind = np.array([x for x, _ in enumerate(Categories)])
# 分组柱状图
ax[0].grid(True, linestyle='-.', alpha=1)
ax[0].bar(ind + 0.00, students[0], 0.25, align="center", color='yellow', edgecolor='blue')
ax[0].bar(ind + 0.25, students[1], 0.25, align="center", color='red', edgecolor='blue')
ax[0].set_xticks(ind)
ax[0].set_xticklabels(Categories)
ax[0].set_title('CTF_Study', fontsize=16)
ax[0].set_xlabel('Categories', fontsize=12)
ax[0].set_ylabel('Number of Students', fontsize=12)
# 堆叠柱状图
ax[1].bar(ind, students[0], width=0.5, label='now', color='gold')
ax[1].bar(ind, students[1], width=0.5, label='old', color='silver')
ax[1].set_xticks(ind)
ax[1].set_xticklabels(Categories)
ax[1].set_title('CTF_Study', fontsize=16)
ax[1].set_ylabel("Number of Students")
ax[1].set_xlabel("Countries")
ax[1].legend(loc="upper right")
plt.show()
直方图
又称质量分布图,是条形图的一种,由一系列高度不等的纵向线段来表示数据分布的情况。
区别在于:
直方图用于概率分布,它显示了一组数值序列在给定的数值范围内出现的概率
柱状图则用于展示各个类别的频数
"""
例如:
我们对某工厂的员工年龄做直方图统计
首先我们要统计出每一位员工的年龄,然后设定一个 20 至 65 的数值范围
并将该数值范围细分为 4 个区间段 (20,35),(35,45),(45,55),(55,65)
最后通过直方图的形式,展示该工厂员工在相应年龄区间的分布情况
"""
from matplotlib import pyplot as plt
import numpy as np
#创建图形对象和轴域对象
fig,ax = plt.subplots(1,1)
x = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27])
#绘制直方图
#range:指定全局间隔的下限与上限值 (min,max),元组类型,默认值为 None
#density:如果为 True,返回概率密度直方图;默认为 False,返回相应区间元素的个数的直方图
#histtype:要绘制的直方图类型,默认值为“bar”,可选值有 barstacked(堆叠条形图)、step(未填充的阶梯图)、stepfilled(已填充的阶梯图)
#bins不设置,默认10个
ax.hist(x, bins = [0,25,50,75,100])
#设置坐标轴
ax.set_title("Histogram Of Result")
ax.set_xticks([0,25,50,75,100])
ax.set_xlabel('marks')
ax.set_ylabel('no.of students')
plt.show()
饼状图
from matplotlib import pyplot as plt
import numpy as np
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
#准备数据
langs = ['C', 'C++', 'Java', 'Python', 'PHP']
students = [23, 17, 35, 29, 12]
colors = ['blue', 'orange', 'green', 'red', 'purple']
#绘制饼状图
ax.pie(students, labels = langs, colors=colors, autopct='%1.3f%%')
plt.show()
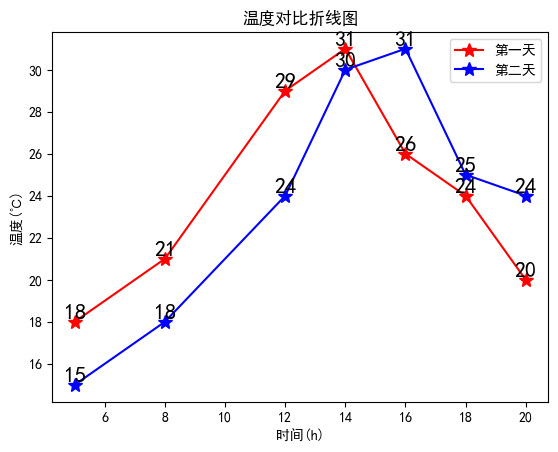
折线图
#对比两天内同一时刻温度的变化情况
import matplotlib.pyplot as plt
x = [5, 8, 12, 14, 16, 18, 20]
y1 = [18, 21, 29, 31, 26, 24, 20]
y2 = [15, 18, 24, 30, 31, 25, 24]
#绘制折线图,添加数据点,设置点的大小
# * 表示绘制五角星;此处也可以不设置线条颜色,matplotlib会自动为线条添加不同的颜色
plt.plot(x, y1, 'r', marker='*', markersize=10)
plt.plot(x, y2, 'b', marker='*', markersize=10)
plt.title('温度对比折线图')
plt.xlabel('时间(h)')
plt.ylabel('温度(℃)')
#给图像添加注释,并设置样式
for a, b in zip(x, y1):
plt.text(a, b, b, ha='center', va='bottom', fontsize=16)
for a, b in zip(x, y2):
plt.text(a, b, b, ha='center', va='bottom', fontsize=16)
plt.legend(['第一天', '第二天'])
plt.show()
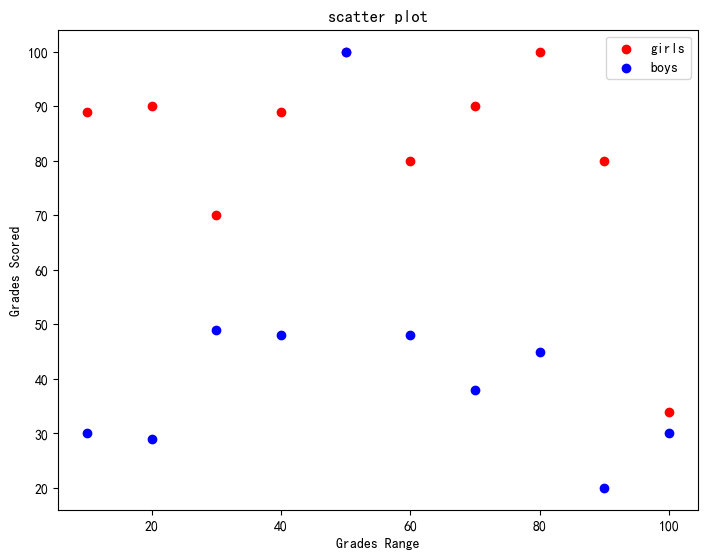
散点图
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_axes([0,0,1,1])
girls_grades = [89, 90, 70, 89, 100, 80, 90, 100, 80, 34]
boys_grades = [30, 29, 49, 48, 100, 48, 38, 45, 20, 30]
grades_range = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
ax.scatter(grades_range, girls_grades, color='r',label="girls")
ax.scatter(grades_range, boys_grades, color='b',label="boys")
ax.set_xlabel('Grades Range')
ax.set_ylabel('Grades Scored')
ax.set_title('scatter plot')
plt.legend()
plt.show()
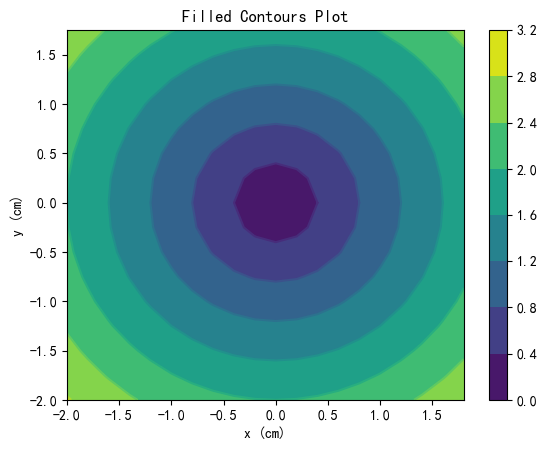
等高线
import numpy as np
import matplotlib.pyplot as plt
X, Y = np.meshgrid(np.arange(-2, 2, 0.2), np.arange(-2, 2, 0.25))
Z = np.sqrt(X**2 + Y**2)
fig, ax = plt.subplots(1,1)
cp = ax.contourf(X, Y, Z)
fig.colorbar(cp)
ax.set_title('Filled Contours Plot')
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
plt.contour(X,Y,Z)
plt.show()
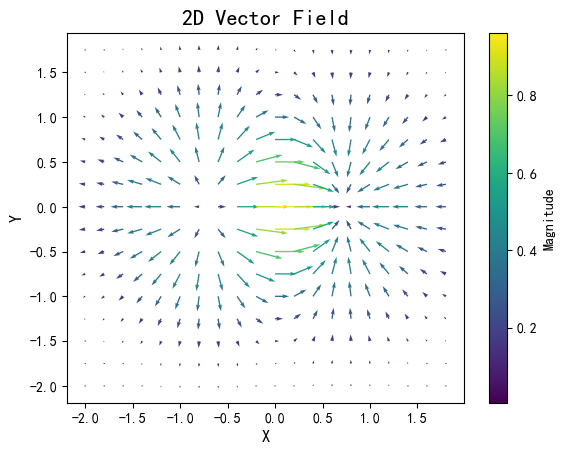
振动图
振动图也叫磁场图,或量场图,其图像的表现形式是一组矢量箭头,其数学含义是在点 (x,y) 处具有分向量 (u,v)。
import matplotlib.pyplot as plt
import numpy as np
x, y = np.meshgrid(np.arange(-2, 2, 0.2), np.arange(-2, 2, 0.25))
z = x * np.exp(-x**2 - y**2)
v, u = np.gradient(z, 0.2, 0.2)
fig, ax = plt.subplots()
magnitude = np.sqrt(u**2 + v**2)
q = ax.quiver(x, y, u, v, magnitude, cmap='viridis', scale=10)
plt.colorbar(q, label='Magnitude')
ax.set_title('2D Vector Field', fontsize=16)
ax.set_xlabel('X', fontsize=12)
ax.set_ylabel('Y', fontsize=12)
plt.show()
箱型图
又叫做盒须图,于1977年由美国著名统计学家约翰·图基(John Tukey)发明
它能显示出一组数据的最大值、最小值、中位数、及上下四分位数
from matplotlib import pyplot as plt
#利用随机数种子使每次生成的随机数相同
np.random.seed(10)
collectn_1 = np.random.normal(100, 10, 200)
collectn_2 = np.random.normal(80, 30, 200)
collectn_3 = np.random.normal(90, 20, 200)
collectn_4 = np.random.normal(70, 25, 200)
data_to_plot=[collectn_1,collectn_2,collectn_3,collectn_4]
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
#创建箱型图
bp = ax.boxplot(data_to_plot)
plt.show()
提琴图
小提琴图跟箱形图类似,不同之处在于小提琴图还显示数据在不同数值下的概率密度。
import matplotlib.pyplot as plt
np.random.seed(10)
collectn_1 = np.random.normal(100, 10, 200)
collectn_2 = np.random.normal(80, 30, 200)
collectn_3 = np.random.normal(90, 20, 200)
collectn_4 = np.random.normal(70, 25, 200)
data_to_plot = [collectn_1, collectn_2, collectn_3, collectn_4]
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
bp = ax.violinplot(data_to_plot)
plt.show()
3D绘图
from mpl_toolkits import mplot3d
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(18, 10))
# 3D Line plot
ax0 = fig.add_subplot(231, projection='3d')
z = np.linspace(0, 1, 100)
x = z * np.sin(20 * z)
y = z * np.cos(20 * z)
ax0.plot3D(x, y, z, 'gray')
ax0.set_title('3D Line Plot')
# 3D Scatter plot
ax1 = fig.add_subplot(232, projection='3d')
c = x + y
ax1.scatter3D(x, y, z, c=c)
ax1.set_title('3D Scatter Plot')
# 3D Contour plot
ax2 = fig.add_subplot(233, projection='3d')
def f(x, y):
return np.sin(np.sqrt(x ** 2 + y ** 2))
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
ax2.contour3D(X, Y, Z, 50, cmap='binary')
ax2.set_xlabel('x')
ax2.set_ylabel('y')
ax2.set_zlabel('z')
ax2.set_title('3D Contour')
# 3D Wireframe plot
ax3 = fig.add_subplot(234, projection='3d')
ax3.plot_wireframe(X, Y, Z, color='black')
ax3.set_title('3D Wireframe Plot')
# 3D Surface plot
ax4 = fig.add_subplot(235, projection='3d')
x = np.outer(np.linspace(-2, 2, 30), np.ones(30))
y = x.copy().T
z = np.cos(x ** 2 + y ** 2)
ax4.plot_surface(x, y, z, cmap='viridis', edgecolor='none')
ax4.set_title('3D Surface Plot')
plt.show()
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
# 3,8 表示x,y的坐标点;style设置字体样式为斜体;bbox用来设置盒子的属性,比如背景色
ax.text(3, 8, '人生苦短,我用python', style='italic',bbox = {'facecolor': 'yellow'},fontsize=15)
#绘制数学表达式,用$符包裹
ax.text(2, 6, r'an equation: $E = mc^2$', fontsize = 15)
#添加文字,并设置样式
ax.text(4, 0.05, '网址:https://www.cnblogs.com/N1ng',verticalalignment = 'bottom', color = 'green', fontsize = 15)
ax.plot([2], [1], 'o')
#xy为点的坐标;xytext为注释内容坐标;arrowprops设置箭头的属性
ax.annotate('python', xy = (2, 1), xytext = (3, 4),arrowprops = dict(facecolor = 'blue', shrink = 0.1))
ax.axis([0, 10, 0, 10])
plt.show()
plt.savefig('sine_wave19.png')
Torch
张量
创建
import torch
print(f"全零张量:\n{torch.zeros(2, 3)}")
print(f"全一张量:\n{torch.ones(2, 3)}")
rand_narray = torch.rand(2, 3, dtype=torch.float64)
print(f"服从正态分布的随机张量:\n{torch.randn(2, 3)}")
print(f"服从均匀分布的随机张量:\n{rand_narray}")
print(f"未初始化张量:\n{torch.empty((2, 3))}")
print(f"对角张量:\n{torch.eye(3)}")
print(f"一维序列张量:\n{torch.arange(0, 10, 2)}")
print(f"指定范围内等间隔序列张量:\n{torch.linspace(0, 1, 5)}")
import numpy as np
numpy_narray = np.array([[0.1594, 1.6637, -0.4465], [0.6389, -2.7789, 0.4863]])
tensor_numpy_narray = torch.from_numpy(numpy_narray)
print(f"从NumPy数组创建张量\n{tensor_numpy_narray}")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device_narray = torch.randn(2, 3, device=device)
print(f"在指定设备(CPU/GPU)上创建张量\n{device_narray}")
属性
import torch
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)
print("Tensor:\n", tensor)
print("获取形状:", tensor.shape, tensor.size())
print("数据类型:", tensor.dtype)
print("设备:", tensor.device)
print("维度数:", tensor.dim())
print("元素总数:", tensor.numel())
print("是否启用梯度:", tensor.requires_grad)
print("是否在 GPU 上:", tensor.is_cuda)
print("是否连续存储:", tensor.is_contiguous())
print("获取单元素值:", tensor[0][1].item())
运算
print(f"张量加法:\n{rand_narray + tensor_numpy_narray}")
print(f"张量乘法:\n{rand_narray * tensor_numpy_narray}")
print(f"张量转置:\n{tensor_numpy_narray.t()}")
print(f"矩阵乘法:\n{torch.matmul(rand_narray, tensor_numpy_narray.t())}")
print(f"张量求和:\n{rand_narray.sum()}")
print(f"张量求均值:\n{rand_narray.mean()}")
print(f"张量中最大值:\n{rand_narray.max()}")
print(f"张量中最小值:\n{rand_narray.min()}")
print(f"张量最大索引(指定维度):\n{rand_narray.argmax()}")
print(f"计算张量softmax:\n{rand_narray.softmax(dim=1)}")
print(f"向量点积(仅适用于 1D 张量):\n{torch.dot(rand_narray[0], tensor_numpy_narray[0])}")
tensor_requires_grad = torch.tensor([1.0], requires_grad=True)
tensor_result = tensor_requires_grad * 2
tensor_result.backward()
print(f"梯度:\n{tensor_requires_grad.grad}") # 输出梯度
"""
自动求导:用于在训练神经网络时计算梯度并且进行反向传播算法的实现
requires_grad=True属性:PyTorch会自动跟踪所有对它的操作,以便在之后计算梯度
.backward():实现反向传播,用来计算梯度
torch.no_grad()或requires_grad=False:停止梯度计算
"""
#形状操作
"""
x.view(shape):改变张量的形状(不改变数据)
x.reshape(shape):类似于 view,但更灵活
x.unsqueeze(dim):在指定维度添加一个维度
x.squeeze(dim):去掉指定维度为 1 的维度
torch.cat((x, y), dim):按指定维度连接多个张量
"""
第一个神经网络——MNIST
神经网络
神经网络是一种模仿人脑神经元连接的计算模型,由多层节点(神经元)组成,用于学习数据之间的复杂模式和关系
神经网络通过调整神经元之间的连接权重来优化预测结果,这一过程涉及前向传播、损失计算、反向传播和参数更新
神经网络的类型包括前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM),它们在图像识别、语音处理、自然语言处理等多个领域都有广泛应用
PyTorch 提供了一个非常方便的接口来构建神经网络模型,即 torch.nn.Module
使用
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
#获取数据:生成100个二维数据点, 点在圆内为1, 圆外为0
data = torch.randn(100, 2)
labels = (data[:, 0]**2 + data[:, 1]**2 < 1).float().unsqueeze(1)
# 可视化数据
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm')
plt.title("Generated Data")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
# 定义前馈神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
# 定义神经网络的层
self.fc1 = nn.Linear(2, 4) # 输入层有 2 个特征,隐藏层有 4 个神经元
self.fc2 = nn.Linear(4, 1) # 隐藏层输出到 1 个神经元(用于二分类)
self.sigmoid = nn.Sigmoid() # 二分类激活函数
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数
x = self.sigmoid(self.fc2(x)) # 输出层使用 Sigmoid 激活函数
return x
model = SimpleNN()
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1) # 使用随机梯度下降优化器
# 训练循环
for epoch in range(100):
# 前向传播
outputs = model(data)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 10 轮打印一次损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{100}], Loss: {loss.item():.4f}')
# 可视化决策边界
def plot_decision_boundary(model, data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
xx, yy = torch.meshgrid(torch.arange(x_min, x_max, 0.1), torch.arange(y_min, y_max, 0.1), indexing='ij')
grid = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1)], dim=1)
predictions = model(grid).detach().numpy().reshape(xx.shape)
plt.contourf(xx, yy, predictions, levels=[0, 0.5, 1], cmap='coolwarm', alpha=0.7)
plt.scatter(data[:, 0], data[:, 1], c=labels.squeeze(), cmap='coolwarm', edgecolors='k')
plt.title("Decision Boundary")
plt.show()
plot_decision_boundary(model, data)
pytorch 构造简单的三层(784 → 128 → 64 → 10)MLP,使用了 ReLU 作为激活函数,最后一层通过 softmax 进行归一化,转化为概率分布,我们将依靠 MNIST 这个著名的数据集对它进行训练,并测试我们的模型效果。
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import numpy as np
import pytest # 测试框架,详情见https://blog.csdn.net/qq_45609369/article/details/140007322
from collections.abc import Callable
BATCH_SIZE = 64 #设置每一批的大小
EPOCHS = 5 #设置训练轮数
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") #确定是否有可用的CUDA设备
#定义一个BPNet类,它继承于nn.Module类,nn.Module是pytorch给出的默认神经网络类
class MLP(nn.Module):
def __init__(self): #定义类对象实例化方法
super().__init__() #初始化神经网络
#定义类的接口函数,使用nn.Sequential将操作合并到一起
self.classifier = nn.Sequential(
nn.Linear(28 * 28, 128), #放入了一个全连接层,从28*28—>128,28*28是图像大小
nn.ReLU(inplace=True), #放入了一个ReLU激活函数,inplace=True节省显存
nn.Linear(128, 64), #放入了一个全连接层,从128—>64,128是上层大小
nn.ReLU(inplace=True), #放入了一个ReLU激活函数
nn.Linear(64, 10) #放入了一个全连接层,从64—>10,64是上层大小
)
#forward函数定义该神经如何处理数据,也就是数据如何在网络中前进
def forward(self, x):
x = torch.flatten(x,1) #首先将x展平为一维数组
x = self.classifier(x) #将x放入上面定义的函数中
x = torch.softmax(x, dim=1) #将x进行归一化处理,转换为概率分布
return x
#定义训练神经网络模型的代码
def train(model):
#使用pytorch框架给出的接口datasets,创建一个MNIST数据集
train_dataset = datasets.MNIST(root=r'data', #root指明文件存储位置
train=True, #train代表是否是训练集
transform=transforms.ToTensor(), #transform表明数据集的数据应该如何处理
download=True) #download表明是否运行下载
#使用pytorch框架给出的接口DataLoader,将数据集载入
train_loader = DataLoader(dataset=train_dataset, #dataset指明数据集
batch_size=BATCH_SIZE, #batch_size指明批大小
shuffle=True) #shuffle指明是否需要打乱
#实例化一个Adam优化器,用来对数据进行优化
optimizer = Adam(model.parameters(), lr=0.0005) #第一个参数指明需要被优化的数据是模型的参数,lr指明了学习率
criterion = nn.CrossEntropyLoss() #指明误差计算方式,这里使用交叉熵损失
model.train() #可以先理解为:训练模式,启动!(启用 Batch Normalization 和 Dropout)
#训练EPOCHS这么多轮(话说是不是es
for epoch in range(EPOCHS):
#使用enumerate对train_loader进行迭代
for index, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE) #将数据和真实标签部署在选定的设备上,加快运算速度
optimizer.zero_grad() #每次训练前要先将梯度归零
pred = model(data) #使用现在的模型得到现实输出
loss = criterion(pred, target) #计算现实输出和期望输出之间的误差
loss.backward() #反向传播计算得到每个参数的梯度值
optimizer.step() #梯度下降执行一步参数更新
#每到一定阶段就打印目前训练进度以及相关信息,下面代码是print(f"")格式化输出
if index % 100 == 0:
print(f'Train Epoch: {epoch} [{index * len(data)}/{len(train_loader)} ({(100. * index / len(train_loader)):.0f}%)]\tLoss: {loss.item():.6f}')
model.eval() #训练结束(不启用 Batch Normalization 和 Dropout)
torch.save(model.state_dict(),"MLP.pth") #保存模型(仅保存参数)
@pytest.fixture
def model():
model = MLP().to(DEVICE)
train(model) # 根据需要是否测试之前训练模型
return model
# 定义校验模型效果的代码
def test(model):
test_dataset = datasets.MNIST(root='data',
train=False,
transform=transforms.ToTensor(),
download=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)
total = 0 #总计
correct = 0 #正确
for index, (data, target) in enumerate(test_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
pred = model(data)
correct += (torch.argmax(pred, dim=1) == target).sum() #检测预测是否正确,因为是批处理,所以求和
total += pred.size(0)
print("Correct : ",correct,'/',total,sep='')
print('Accuracy : ',float(correct)/float(total) * 100. ,"%",sep='')
if __name__ == "__main__":
pytest.main()
model = MLP().to(DEVICE) #在指定的设备(cpu或者gpu)上将模型实例化
train(model)
test(model)
可以通过修改lr提高准确度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









