






目录
Kafka消息队列
Kafka消息队列是一种高性能、分布式、可扩展的流处理平台,专为处理大规模实时数据而设计
核心特性
- 高吞吐量与低延迟
- 每秒可处理数百万条消息,延迟控制在毫秒级,适合实时数据流处理。
- 采用批量发送和零拷贝技术,减少网络和磁盘I/O开销。
- 持久化与容错性
- 消息持久化存储在磁盘,支持配置保留时间(如7天或永久),避免数据丢失。
- 通过多副本机制(默认副本因子为3)实现高可用,允许部分节点故障而不影响服务。
- 可扩展性
- 支持水平扩展,通过增加Broker节点和分区(Partition)提升吞吐量。
- 分区设计允许并行处理,每个分区可独立分配给不同消费者。
- 消费者组与负载均衡
- 消费者组(Consumer Group)内的消费者共享分区,实现负载均衡。
- 一个分区只能被一个消费者组内的消费者消费,避免重复处理。
- 顺序保证
- 单个分区内的消息严格按顺序存储和消费,适合需要有序处理的场景(如订单处理)。
技术架构
- 核心组件
- Broker:Kafka集群中的节点,负责消息存储和转发。
- Topic:消息分类的逻辑单元,可划分为多个分区。
- Partition:分区的物理存储单元,每个分区是一个有序的日志文件。
- Producer:消息生产者,将消息发送到指定Topic的分区。
- Consumer:消息消费者,从Topic的分区拉取消息。
- 消息存储机制
- 消息以追加方式写入分区日志文件,支持压缩(如Snappy、LZ4)减少存储开销。
- 通过索引文件快速定位消息,支持高效随机读取。
- 副本与同步机制
- 每个分区有Leader和Follower副本,Leader处理读写请求,Follower同步数据。
- 使用ISR(In-Sync Replica)机制确保数据一致性,避免脑裂问题。
优劣势分析
- 优势
- 高性能:支持高吞吐量和低延迟,适合大规模实时数据处理。
- 可扩展性:水平扩展简单,分区设计支持并行处理。
- 持久化与容错:消息持久化存储,多副本机制保证高可用。
- 灵活性:支持多种消费模式(如拉取、推送)和流处理框架集成。
- 劣势
- 复杂性:配置和管理较复杂,需处理分区分配、副本同步等问题。
- 顺序保证限制:仅保证单个分区内的顺序,跨分区无序。
- 资源消耗:多副本和持久化存储占用较多磁盘和内存资源。
zookeeper概述
核心特性
- 高可用性
- 以集群方式部署,采用Leader-Follower模式,通过自动Leader选举机制,在节点故障时仍能维持服务,确保系统的高可用性。
- 数据一致性
- 使用ZAB协议(ZooKeeper Atomic Broadcast)保证数据一致性,所有写操作由Leader处理并复制到Followers,确保集群数据一致性。
- 可靠性
- 采用持久化日志记录所有写操作,即使Leader宕机,新Leader也可从日志中恢复数据,保证数据的可靠性和可恢复性。
- 高性能
- 使用内存数据库存储数据,快速响应读操作,并通过并行处理提高写操作吞吐量。
- 简单易用
- 提供简单的API和数据模型,易于理解和使用,适用于各种分布式应用场景。
- 灵活性
- 允许在集群运行时动态添加或删除节点,灵活适应不同规模和需求的系统。
工作原理
- 集群模式
- 由多个ZooKeeper服务器组成集群,通过选举机制选择Leader,其他服务器作为Followers。
- 数据模型
- 提供树形结构的命名空间,每个节点称为ZNode,可存储少量数据,支持持久节点和临时节点。
- 原子更新
- 对ZNode的更新操作具有原子性,要么完全成功,要么完全失败,保证数据一致性。
- 通知机制
- 客户端可在ZNode上注册Watcher,当节点状态变化时,ZooKeeper会通知客户端,支持实时响应。
- 事务日志
- 记录所有写操作,确保服务器崩溃或重启后可恢复到之前的状态,保证数据可靠性。
优劣势
- 优势
- 高可用性:通过Leader选举和集群部署,确保系统在节点故障时仍能正常运行。
- 强一致性:使用ZAB协议保证数据一致性,支持线性一致性读操作。
- 高性能:内存数据库和并行处理机制,提高读写操作效率。
- 灵活性:支持动态添加或删除节点,适应不同规模和需求的系统。
- 劣势
- 单点故障风险:Leader节点是单点,宕机时虽会选举新Leader,但存在短暂不可用性。
- 写入性能受限:所有写操作由Leader处理并复制,高负载下写入性能可能受影响。
- 数据大小限制:每个ZNode的数据大小有限制(默认1MB),不适合存储大量数据。
- 系统复杂性:功能强大但复杂,简单应用场景下可能增加系统复杂度。
zookeeper集群架构
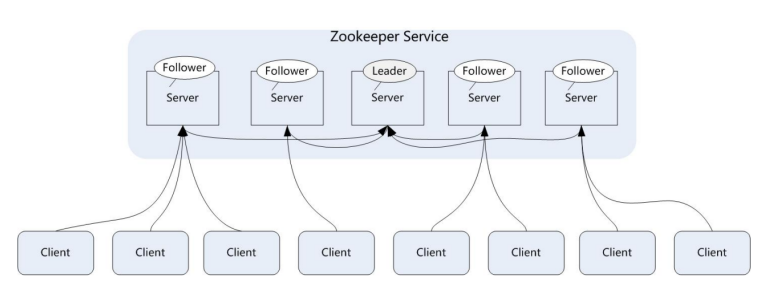
- Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态
- follower:跟随着角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
- observer:观察者角色,用户接收客户端的请求,并将写请求转发给1eader,同时同步 leader 状态,但是不参与投票。0bserver 目的是扩展系统,提高伸缩性。
- client:客户端角色,用于向zookeeper 发起请求
ZooKeeper在Kafka中的核心作用
- Broker元数据管理
- Broker注册与发现:Kafka的Broker启动时会向ZooKeeper注册自身信息(如IP、端口),消费者和生产者通过ZooKeeper获取集群Broker列表,实现动态发现。
- Broker状态监控:ZooKeeper维护Broker的在线/离线状态,若Broker宕机,ZooKeeper会通知其他组件,触发重新平衡(Rebalance)。
- Topic与Partition管理
- Topic元数据存储:ZooKeeper存储Topic的分区(Partition)数量、副本(Replica)分配等元数据,确保所有Broker对Topic结构有一致认知。
- Partition Leader选举:当Partition的Leader宕机时,ZooKeeper协调Follower选举新Leader,保证分区可用性。
- Consumer Group协调
- Offset存储:早期Kafka版本中,Consumer Group的消费偏移量(Offset)存储在ZooKeeper中(新版本已迁移至Kafka内部Topic)。
- Rebalance触发:Consumer Group成员变化(如新消费者加入或宕机)时,ZooKeeper通知其他成员,触发重新分配Partition。
- 集群配置管理
- 动态配置更新:Kafka集群的配置(如副本因子、分区数)可通过ZooKeeper动态更新,无需重启Broker。
- ACL权限控制:ZooKeeper存储Kafka的ACL(访问控制列表),管理Topic和Broker的权限。
案例:分布部署
三台设备
关闭防火墙及系统内核
[root@kafka1 ~]# systemctl stop firewalld #关闭防火墙
[root@kafka1 ~]# seten/tab 0 #关闭系统内核更改三台设备名称
[root@localhost ~]#101:hostnamectl set-hostname fafka1
[root@localhost ~]#102:hostnamectl set-hostname fafka2
[root@localhost ~]#103:hostnamectl set-hostname fafka3
bash #立即生效修改hosts文件
[root@kafka1 ~]# vim /etc/hosts
101:hostnamectl set-hostname fafka1
102:hostnamectl set-hostname fafka2
103:hostnamectl set-hostname fafka3将zookeeper文件包解压缩,解压即可用
[root@kafka1 ~]# tar zxf apache-zookeeper-3.6.0-bin.tar.gz将解压后的文件移动到指定的目录下
[root@kafka1 ~]# mv apache-zookeeper-3.6.0-bin /etc/zookeeper创建日志文件
[root@kafka1 ~]# mkdir -p /etc/zookeeper/zookeeper-data修改配置文件名称
[root@kafka1 ~]# cd /etc/zookeeper/conf/
[root@kafka1 ~]# cp zoo_samaple.cfg zoo.cfg #将配置文件更换成能用的文件修改配置文件
[root@kafka1 ~]# vim zoo.cfg
#12行
dataDir=/etc/zookeeper/zookeeper-data
clientPort=2181 #下
server.1=192.168.10.101:2888:3888
server.2=192.168.10.102:2888:3888
server.3=192.168.10.103:2888:3888给设备分一个id
[root@kafka1 ~]# 101:echo '1'>/etc/zookeeper/zookeeper-data/myid
[root@kafka1 ~]# 102:echo '2'>/etc/zookeeper/zookeeper-data/myid
[root@kafka1 ~]# 103:echo '3'>/etc/zookeeper/zookeeper-data/myid启动zookeeper
[root@kafka1 ~]# cd /etc/zookeeper/bin/
[root@kafka1 ~]# ./zkServer.sh start #启动查看状态
./zkServer.sh status #查看解压kafka
[root@kafka1 ~]# tar zxf kafka_2.13-2.4.1.tgz 移动到指定目录
[root@kafka1 ~]# mv kafka /etc/kafka修改配置文件
[root@kafka1 ~]# vim /etc/kadka
#21行
101:1
102:2
103:3
#日志60行
log.dirs=/etc/kafka/kafka-logs
#31行
listeners=PLAINTEXT://192.168.10.101:9092 #监听自己的IP地址:102、103同上
#123行
zookeeper.connect=192.168.10.101:2181,192.168.10.102:2181,192.168.10.103:2181创建日志文件
[root@kafka1 ~]# cd /etc/kafka
[root@kafka1 ~]# mkdir kafka-logs启动kafka
[root@kafka1 ~]# cd bin
[root@kafka1 ~]# ./kafka-server-start.sh ../config/server.properties &检测是否启动起来
netstat -anpt |grep 2181验证
101创建主题
[root@kafka1 ~]# ./kafka-topics.sh --create --zookeeper kafka1:2181 --replication-factor 1 --partitions 1 --topic test生成消息
[root@kafka1 ~]# ./kafka-console-producer.sh --broker-list kafka1:9092 -topic test102接收
[root@kafka1 ~]# cd /etc/kafka/bin
[root@kafka1 ~]# ./kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









