







目录
<1>回顾动静态库
我们一般使用ldd命令查看文件所依赖的库,动态库和静态库的后缀是不同的。动态库就是被多个使用者共享使用,一旦缺失所有的用户都无法使用(使用静态链接),静态库就是把自己需要的文件拷到可执行文件中。
优缺点:
| 动态库 | 静态库 | |
| 优点 | 比较节省资源,不会有很多的重复代码 -- 这里的资源包括磁盘资源,内存,网络等等 | 不依赖库,同类型平台中可以直接运行使用 |
| 缺点 | 对库的依赖性比较强,一但库丢失,所有使用这个库的文件都将无法运行 | 可执行程序的体积较大,比较费资源 |
一般情况下,我们使用的都是动态库,云服务器中默认是不装静态库的,需要自行安装。
<2>动静态库的制作和使用
在进行动静态库的制作之前,我们先要了解为什么要有库?第一个方面是因为库能够提高开发效率,我们能够直接使用别人写的一些接口;第二个是因为能够隐藏源代码,当我们不想让别人看到我们的源代码,但又要给别人使用一些接口时,就需要使用库。
而库的本质就是把一些.o文件用特殊的方式,进打包,形成一个文件.
1.静态库的制作
下面演示一下静态库的制作过程
我们先创建对应的.c和.h文件,然后让mymath1.c和mymath2.c 形成对应的同名.o文件


我们可以创建一个目录来验证一下,上述的.o文件是否有效。其中mymath1.c中是加号的计算函数,mymath2.c是减号的计算函数,它们的头文件是对应的函数声明。我们可以把对应的.o文件和.h文件发送到该目录下,再创建一个test.c进行测试。
#include<stdio.h>
#include"mymath1.h"
#include"mymath2.h"
int main()
{
int a = 10;
int b = 20;
int c = Add(a,b);
int d = Del(a,b);
printf("%d + %d = %d\n",a,b,c);
printf("%d - %d = %d\n",a,b,d);
return 0;
}
上述的代码就是test.c的内容,我们把test.c用编译器形成一个.o文件,然后把所有的.o文件编译形成一个可执行的文件。
运行结果
说明即便我们没有源代码,也可以执行程序。但是每次都要将程序中需要的.o文件一个一个的包含,未免太过麻烦,所以我们就可以打包一下所需的.o文件。
我们可以使用ar -rc命令对.o文件进行打包,具体用法:ar -rc lib库文件名称.a/.so + 需要打包的.o文件。如果原来有同名的库文件,该命令生成的库文件会替代原有的库,如果没有就会生成新的库。下面我们先把上述例子中的.o文件打包一下,生成libmymath.a文件。

再将test.c编译形成可执行程序时,系统就会报错
这是因为我们使用gcc编译器时,编译器只认识C语言的标准库,并不认识我们自定义的库。所以我们在编译时,必需要加几个选项。我们可以使用" -l+库文件的文件名称"(是连在一起的,这个需要注意),这就相当于告诉编译器除了C语言的库,还要链接别的库。当然只加一个选项还不够,我们必需要让编译器知道这个库在哪里,一般编译器是在默认路径下寻找库,但是如果库不在该路径下,我们就需要指明库在哪里。我们就可以使用"-L +库所处的路径"选项。如果不想那么麻烦,可以直接将库文件和头文件直接加到系统的默认路径下(C头文件默认在/usr/include路径下,库文件默认在/lib64),这个过程叫做安装库。
2.动态库的制作
动态库的制作稍微要比静态库简单一点,流程都差不多,只不过中间一些细节上有所差异。首先我们还是要把.c文件变成同名的.o文件,只不过此时我们需要增加一个选项,那就是-fPIC。fPIC的意思是产生位置无关码(具体是啥,稍后解释)。然后就是在打包.o文件时,我们需要注意的是,中间要加入一个 "-shared" 选项,以保证生成的是共享库。下面演示一下

如果我们要形成可执行文件时,也要和静态库一样,标明自定的库(-l选项,这个是必需的)和库的路径。
如果我们需要把我们写的库和头文件发送给别的用户,我们最好把头文件和库文件打包成一个压缩包,防止遗漏某些文件。但是我们在解压完压缩包后,使用库中的一些接口编写代码,然后我们会发现系统会报错,系统提示无法找到头文件。这是因为系统一般在/usr/include路径和当前路径下寻找头文件。如果我们打包的头文件在一个目录中,会导致系统无法找到头文件。所以在形成可执行文件时我们可以再加一个 "-I+所需头文件路径",改选项就相当于告诉系统,除了去上述两个路径寻找头文件,还要去 -I 后面跟的路径找一下头文件。当然,上述的操作也可通过把库安装(拷贝)到系统默认路径简化。这样我们再形成可执行程序文件,只需要指明所需的库即可。(不推荐)
当然,完成上述步骤后,我们会发现运行可执行文件时,我们会发现,系统依旧会报错,是找不到文件的错误。我们在执行形成可执行文件时,不是已经告诉了系统库文件的路径吗?这是因为对于动态库来说,编译时我们需要告诉编译器搜索路径,在运行时我们也要告诉系统库的搜索路径,这两条路径可以一样。这和静态库略微有点不同,静态库在编译成功后,就不需要管了(静态库会把库文件中的代码直接拷到我们的可执行文件中)。
解决上述问题的办法有许多种,下面简单介绍几种:
<1>直接把动态库拷贝到系统的默认搜索路径下(一般是在/lib64目录下),既可以支持编译,有支持运行。
<2>使用 LD_LIBRARY_PATH环境变量,该环境变量用于系统运行程序时,动态库查找的辅助路径,如果系统中没有该环境变量,可自行添加;如果有,使用export命令把不在系统默认库搜索路径下的库路径添加进去即可。如果系统中原来并没有该环境变量,我们使用export时,只是在内存中增加了环境变量,下次启动系统时,该环境变量依旧会消失。为了避免这种情况,我们可以直接在家目录下找到.bashrc 或 .bash_profile文件,直接在该文件中使用export命令添加环境变量,下次系统启动时,会自动读取该文件内容并导入环境变量。
<3> 在当前目录下,建立所依赖的动态库的软链接。
<4> 在系统中创建配置文件,在/etc目录下,存在许多的系统配置文件。我们可以在/etc/ld.so.conf.d/下创建一个配置文件,文件后缀为.conf,文件名无要求。文件中只要添加所需要搜索的库文件路径即可。然后我们执行“ ldconf”命令,让配置文件生效。(上述的操作都要root权限)
3.动静态库链接问题
<1>如果我们同时提供动静态库,系统默认使用动态库。如果非要使用静态库,在命令行后加上-static选项。
<2>如果我们只提供静态库,那我们的可执行程序也没有办法,只能对该库进行静态链接,但程序不一定整体是静态链接的。
<3>如果我们只提供动态库,默认只能动态链接,非得静态链接,就会发生链接报错。
<3>动态库的加载
1.站在系统的角度理解
当cpu在执行程序时,会把可执行程序加载到内存当中,当cpu执行的代码需要动态库文件代码和数据时,动态库会从磁盘上加载到内存上(动态库是磁盘文件)。为了让进程也能看到库的数据与代码,这里就需要将动态库的代码和数据通过页表映射到进程地址空间的共享区。但cpu执行代码段数据遇到库函数的调用时,就直接跳到共享区中,根据共享区的映射关系,执行物理内存中库函数。结束后,再回到代码段。

如果我们新起了一个进程,并且这个进程也需要动态库的数据。如果物理内存上没有共享库的代码和数据,那就把磁盘上的库加载到物理内存上,然后再映射到共享区上;如果原来在物理内存上存在共享库的代码和数据,那就直接映射到进程地址空间中的共享区。OS会决定哪些库加载,哪些库没有别加载。由此,在系统进程中,公共的代码和数据,都只要存在一份即可。虽然再物理内存中一个共享库只会有一份,但是物理内存中是存在非常多库的。OS要对这些库进行管理,就要使用struct 结构体对其进行管理。
2.简单谈谈编址
<1>可执行程序
可执行程序本身是有自己的格式信息的。在没有加载到内存之前,可执行程序其实就存在地址。可执行在没有加载前,也基本被按照类别(比如权限、访问属性等等) 已经将可执行程序划分为各个区域了。
我们可以使用size命令,查看每一个可执行程序中各个区域的大小。
这几个区域的代表含义:
.text(代码段):包含可执行指令的部分。.data(数据段):包含初始化的全局变量和静态变量。.bss(未初始化数据段):包含未初始化的全局变量和静态变量(这些变量在程序启动时会自动初始化为0或空指针)-
dec:表示文件大小的十进制数值。这是最常见的表示方式,易于人们阅读和理解。 -
hex:表示文件大小的十六进制数值。十六进制在某些情况下对于程序员来说更加方便,因为它可以直接与计算机的内存地址和大小对应。 -
filename:文件名称、
我们假设目前可执行程序只有代码段和数据段,为了让cpu寻找到代码和数据,在编译形成可执行程序时,就要对代码和数据进行编址。(下图仅是粗略展示,实际并不是这样编址)

在代码和数据之上,还存在一个头部的管理信息(e_entry),里面存放了main函数的起始地址(方便cpu执行程序),分了多少区 ,使用了哪些库等等。
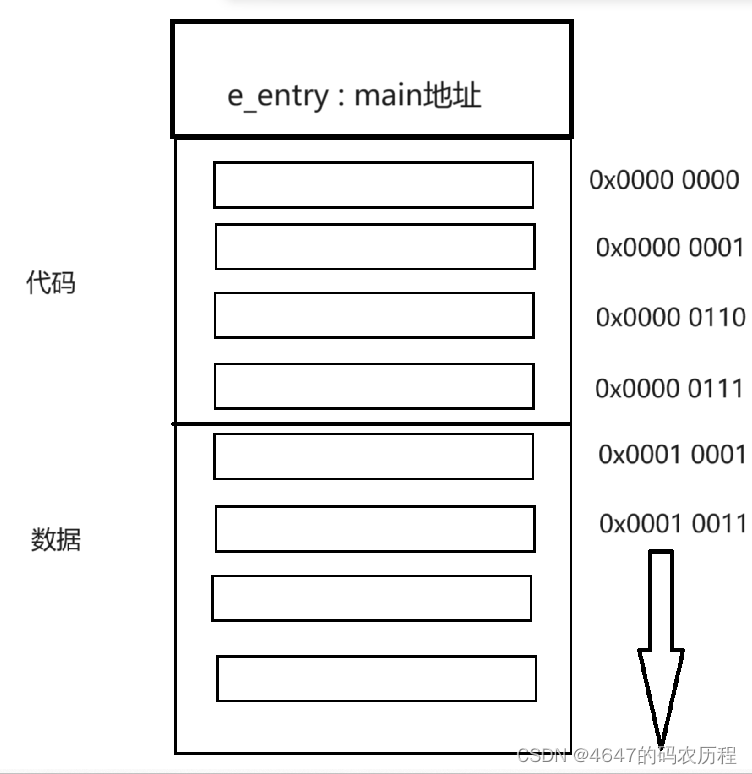
前面我们了解到,进程地址空间是分为很多区域的,包括像代码区,初始化区,未初始化区等等。但是不同的可执行程序的各个区域大小是不同的,OS是怎么初始化不同进程地址空间的各个区域的?其实OS就是根据可执行程序来对进程地址空间中的地址数据进行初始化。
<2>编址的方式
1.绝对编址:绝对编址是指使用固定的内存地址来访问数据。每个数据项都有一个唯一的地址,无论程序运行在内存的哪个位置,这个地址都是固定的。(平坦模式)
2.相对编址:它使用相对于当前指令或数据指针的偏移量来访问数据。这种方式不直接使用数据的绝对地址,而是使用相对于某个基准地址的偏移量。
编址的范围,如果是32位机器,那就是[0,4GB]。
而相对编址等于起始地址+偏移量,不就是我们的虚拟地址吗?所以在加载时,OS就能根据这些地址初始化进程地址空间(准确地说是可执行程序的表头,也就是整个可执行文件的头部信息)。所以,虚拟地址空间本身不仅是OS要遵守,编译器在编译形成可执行程序时,也要遵守。
<3>理解动态库的动态链接和加载问题
1.一般的程序加载过程

在执行一个进程之前,OS要先把磁盘上的可执行程序加载到物理内存之上。期间,OS会根据可执行程序的表头星系初始化进程的地址空间。在加载到物理内存后,可执行程序的代码和数据会马上获得物理地址,页表紧跟着填充物理和虚拟地址之间的映射关系。CPU开始执行时,通过pc指针(程序计数器,保存正在执行指令的下一条指令的地址)找到可执行程序的虚拟地址入口,然后通过MMU模块与页表将虚拟地址转换成物理地址,将物理地址中存放的指令读到指令寄存器中,然后让CPU的其他模块执行该指令。
小结:所谓的地址空间,本质是由操作系统 + 编译器 + 计算机体系结构(CPU)三者配合完成。
3.动态库程序的加载过程
含动态库的程序加载过程起始和普通程序的加载过程类似,下面大体介绍一下过程
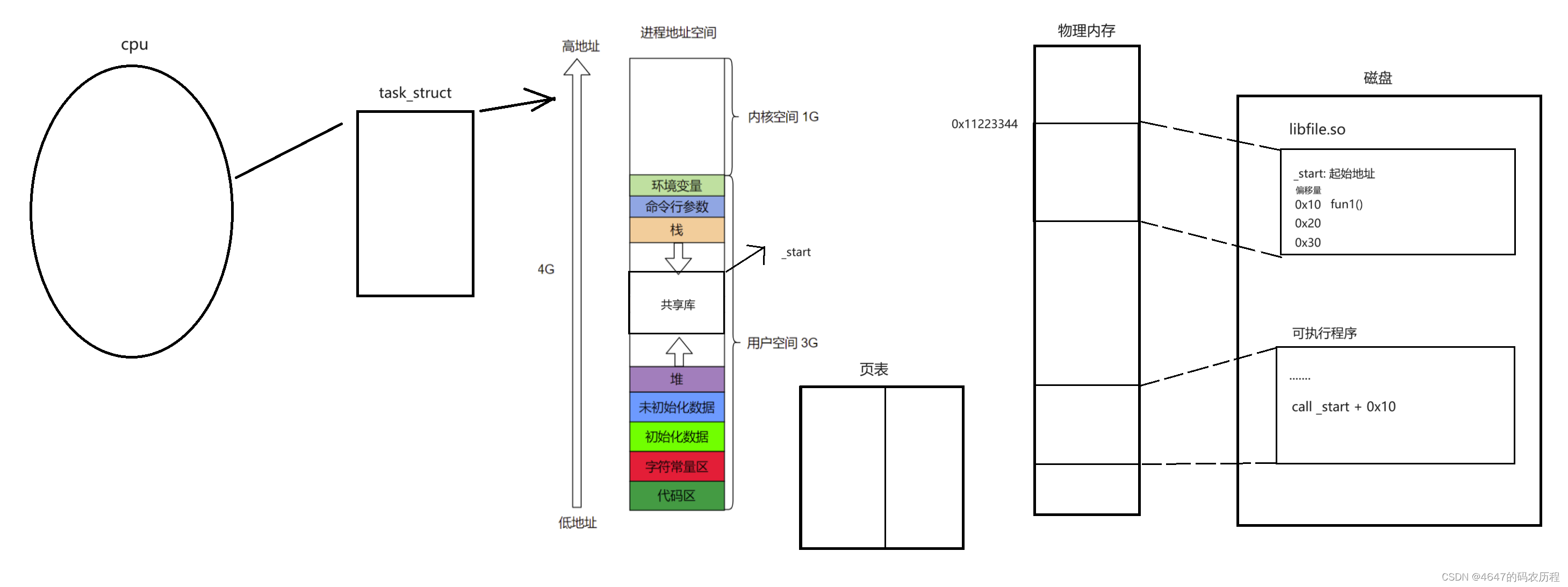
首先,我们还是要把可执行程序加载到物理内存当中,并形成对应的页表与进程地址空间。当程序进行到需要共享库的方法时,OS会把共享库从磁盘加载到物理内存中,同时OS还会建立对应的页表。上述操作结束后,CPU会继续往下执行与共享库相关的指令。CPU在物理内存中获取与调用共享库有关方法的指令后,根据指令上的地址"_start + 偏移量",跳转到共享区执行代码,然后CPU依次执行共享区的代码,执行完成后返回代码区继续执行代码。
库的数据和方法的访问,都可以通过库在地址空间的起始偏移量+程序内部偏移量即可。
以上就是所有内容,文中如有不对之处,还望各位大佬指正,谢谢!!!















 3574
3574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









