






 一、OpenCompass 大模型评测
一、OpenCompass 大模型评测
1.OpenCompass 简介
- 目的:全面了解大型语言模型的优势和限制,指导改进人机交互,规划模型发展,预防风险。
- 重要性:尽管成本高昂,但大型语言模型的应用广泛,了解其性能对研究人员和产品开发者至关重要。
2.OpenCompass2.0 特点
- 开源可复现:公平、公开、可复现的评测方案。
- 全面的能力维度:五大维度,70+ 数据集,约40万题。
- 丰富的模型支持:支持20+ HuggingFace 及 API 模型。
- 分布式高效评测:快速完成评测。
- 多样化评测范式:支持多种评测方式。
- 灵活化拓展:易于增加新模型或数据集,自定义任务分割策略。
3.评测对象
- 基座模型:自监督学习训练,具有文字续写能力。
- 对话模型:基于基座模型,具有对话能力。
4.工具架构
- 模型层:评测主要模型种类。
- 能力层:评测通用能力和特色能力。
- 方法层:结合客观和主观评测。
- 工具层:自动化评测功能。
5.设计思路
- 通用人工智能:面向实际应用的评价体系。
- 能力维度体系:通用能力和特色能力。
6.评测方法
- 客观评测:定量指标比较,提示词工程,语境学习。
- 主观评测:基于受试者判断,真实人类专家与模型打分结合。
二、大模型评测实战
1.快速开始
- 配置:选择模型和数据集,定义评估策略。
- 推理与评估:并行推理和评估。
- 可视化:结果整理,保存为 CSV 和 TXT 文件。
2.实战环境配置
- 开发机和环境:选择合适镜像和 GPU。
- 安装:克隆仓库,安装依赖。
3.数据准备
- 数据集:解压到指定目录。
4.启动评测
- 命令:使用特定命令进行评测。
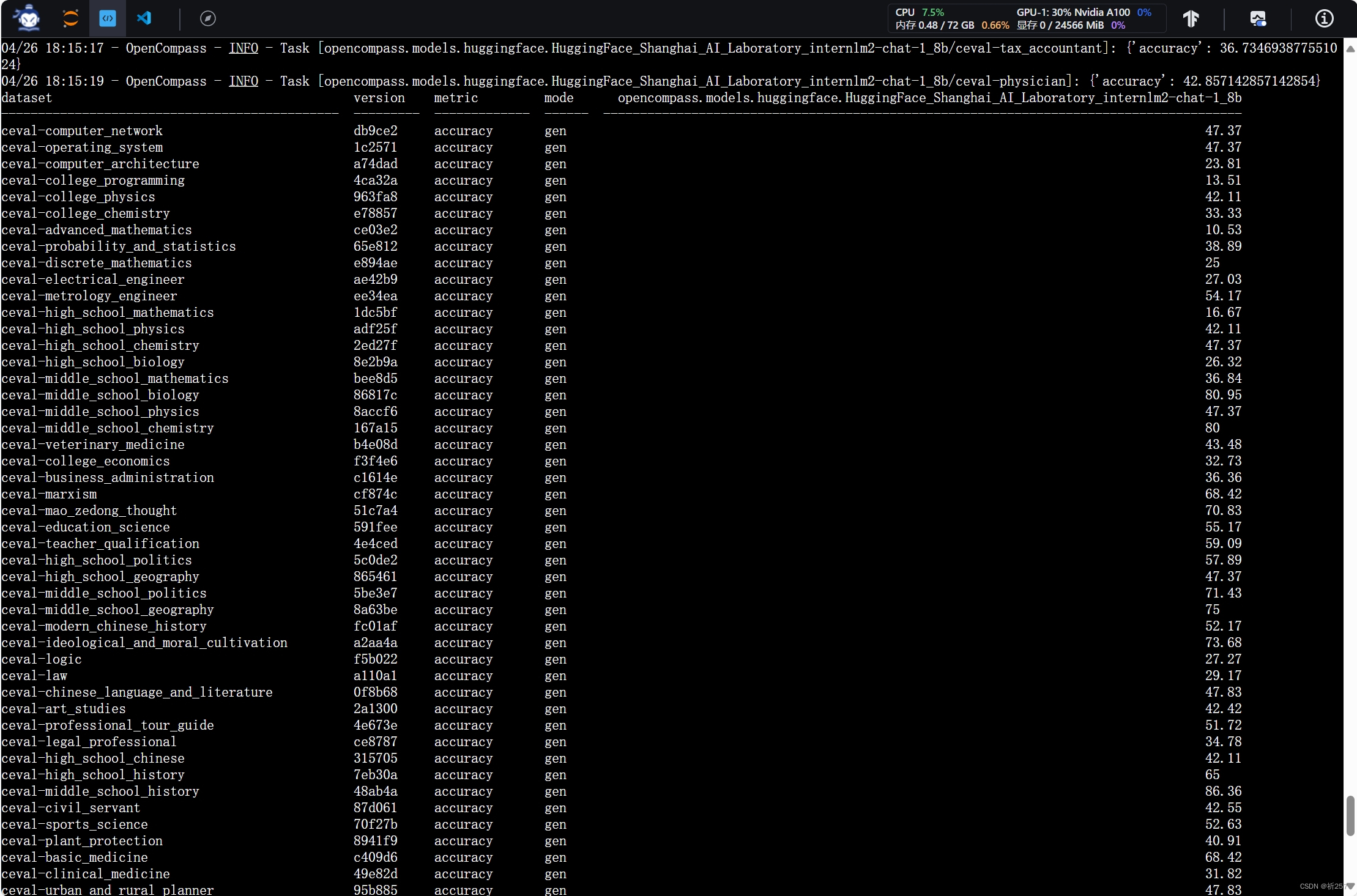
- 使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能,如图:
5.自定义数据集评测
- 客观数据集:自建步骤。
- 主观评测:真实对话场景下评估。
- 尝试构建自定义数据集,并提交至OpenCompass官网。
支持新数据集 — OpenCompass 0.2.4 文档![]() https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_dataset.html
https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_dataset.html
主观评测指引 — OpenCompass 0.2.4 文档![]() https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/subjective_evaluation.html
https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/subjective_evaluation.html
CompassHub![]() https://hub.opencompass.org.cn/dataset-submit?lang=%5Bobject%20Object%5D自定义数据集: CompassHub (opencompass.org.cn)
https://hub.opencompass.org.cn/dataset-submit?lang=%5Bobject%20Object%5D自定义数据集: CompassHub (opencompass.org.cn)

6.数据污染评估
- 数据污染:检测训练数据中的问题。
7.大海捞针测试
- 测试:测试模型的长文本信息提取能力。
8.数据集介绍
- Skywork/ChineseDomainModelingEval:高质量中文文章,涵盖多个领域。














 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









