






基本概念和数据查询代码:
Elastic Search (ES)Java 入门实操(1)下载安装、概念-CSDN博客
Elastic Search(ES)Java 入门实操(2)搜索代码-CSDN博客
想要使用 ES 来查询数据,首先得要 ES 里有数据,但是如果是后来引入的 ES,数据库上万条的数据肯定不能通过手动进行同步,需要使用其他方法进行同步。
数据同步分为全量同步和增量同步。
所谓全量同步,就是引入 ES 时将 MySQL 里的数据全部同步到 ES 里。增量同步就是当数据库的数据发生变化时,将变化的数据同步到 ES 里。
同步方法
定时任务
通过定时任务的方式,每隔一段时间进行同步。比如每一分钟同步一次。
优点:简单,占用资源少,不用引入第三方中间件
缺点:有时间差,数据一致性要求高的场景不适用
全量同步通过实现 CommandLineRunner 接口,在程序启动时执行。
/**
* CommandLineRunner 接口,当spring启动时就执行方法
*/
@Component
public class FullSycnToEs implements CommandLineRunner {
@Resource
private ArticleService articleService;
@Resource
private ArticleEsDao articleEsDao;
@Override
public void run(String... args) throws Exception {
//spring 启动就执行方法进行全量同步
//1.从MySQL获取数据
List<Article> articleList = articleService.list();
if(CollectionUtils.isEmpty(articleList)){
return;
}
//2.将数据转换为DTO
List<ArticleEsDto> articleDtoList = articleList.stream().map(ArticleEsDto::toDto).collect(Collectors.toList());
//3.将数据同步到ES
articleEsDao.saveAll(articleDtoList);
System.out.println("全量同步完成");
}
}增量同步使用 @ Scheduled 定时任务监控更新时间
注意启动类要加上注解 @EnableScheduling
/**
* 定时任务执行数据同步
*/
@Component
public class InSyncToEs {
@Resource
private ArticleMapper articleMapper;
@Resource
private ArticleEsDao articleEsDao;
@Scheduled(fixedRate = 100)
public void run(){
// 定时任务,将数据同步到es,根据更新时间来判断
//假定3分钟内,如果更新时间大于3分钟之前的时间,就是更新了,获取这个数据存入到ES 中
Date minUpdateTime = new Date(new Date().getTime() - 5* 60*1000L);
List<Article> newArticles = articleMapper.getNewArticles(minUpdateTime);
//判断是否有数据更新
if(CollectionUtils.isEmpty(newArticles)){
//没有数据更新
System.out.println("没有数据更新");
return;
}
//有数据更新,将数据转换成dto格式
List<ArticleEsDto> articleEsDtoList = newArticles.stream().map(ArticleEsDto::toDto).collect(Collectors.toList());
//将数据存入到ES中
articleEsDao.saveAll(articleEsDtoList);
System.out.println("数据同步完成");
}
}双写
写入数据库时同时同步到 ES 中,需要考虑 ES 同步失败了怎么办。
使用事务来保证一致性,如果 ES 同步失败了,可以通过定时任务 + 日志 + 告警进行检测和修复(补偿)
Logstash 数据同步管道
传输和处理数据的管道
下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-7.17.21-windows-x86_64.zip
官方文档:Jdbc input plugin | Logstash Reference [7.17] | Elastic
同样的,需要注意版本,下载解压之后在 config 文件夹创建新的同步文件,建议不同的同步脚本创建不同的文件,不要在同一个文件下配置。

文件配置根据官方文档修改,MySQL jar包使用绝对路径即可,否则可能找不到 jar 包,jar 包可以自行准备,也可以从项目的 maven 仓库获取。

# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
jdbc {
// MySQL jar包路径
jdbc_driver_library => "D:\software\logstash-7.17.21\config\mysql-connector-java-8.0.29.jar"
// MySQL 驱动
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
// MySQL 连接地址
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
//账号密码
jdbc_user => "root"
jdbc_password => "1234"
//动态 SQL
statement => "SELECT * from article where 1=1"
parameters => { "favorite_artist" => "Beethoven" }
//定时执行,core 表达式
schedule => "*/5 * * * * *"
}
}
output {
stdout { codec => rubydebug }
}配置好之后在 logstash 目录下执行下面的命令,完成初步从数据库获取数据
.\bin\logstash.bat -f .\config\my-task.conf成功获取数据

增量同步配置,使用 updateTime 来进行同步更新的数据。
完整 input 配置如下。
input {
jdbc {
jdbc_driver_library => "D:\software\logstash-7.17.21\config\mysql-connector-java-8.0.29.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "root"
jdbc_password => "1234"
// 动态查询语句,保证最后一条是最大的
statement => "SELECT * from article where updateTime > :sql_last_value and updateTime < now() order by updateTime asc"
// 查询参数的 hash,不用更改
parameters => { "favorite_artist" => "Beethoven" }
// 查询参数的类型,updatetime 是 timestamp 类型的
tracking_column_type => "timestamp"
// 查询参数
tracking_column => "updatetime"
// 设置为 true 时,将定义的查询参数值用作动态 SQL 中sql_last_value,false 时:sql_last_value 是上次查询时间
use_column_value => true
// 时区设置为上海,否则存在 8小时时差
jdbc_default_timezone => "Asia/Shanghai"
// core 表达式
schedule => "*/5 * * * * *"
}
}配置好从 MySQL 获取的数据之后,就可以同步到 ES 中了。同样需要书写配置。
官方文档:Elasticsearch output plugin | Logstash Reference [7.17] | Elastic
output {
stdout { codec => rubydebug }
elasticsearch {
//访问地址,就是本地 ES 端口
hosts => "127.0.0.1:9200"
// ES 索引
index =>"article_1"
// 数据 id,从数据库获取
document_id => "%{id}"
}最终配置
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
jdbc {
jdbc_driver_library => "D:\software\logstash-7.17.21\config\mysql-connector-java-8.0.29.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "root"
jdbc_password => "1234"
statement => "SELECT * from article where updateTime > :sql_last_value and updateTime < now() order by updateTime asc "
parameters => { "favorite_artist" => "Beethoven" }
tracking_column_type => "timestamp"
tracking_column => "updatetime"
use_column_value => true
jdbc_default_timezone => "Asia/Shanghai"
schedule => "*/5 * * * * *"
}
}
// 筛选
filter{
mutate{
//重命名
rename => {
"updatetime" =>"updateTime"
"createtime" => "createTime"
"isdetele" => "isDetele"
}
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => "127.0.0.1:9200"
index =>"article_1"
document_id => "%{id}"
}
}
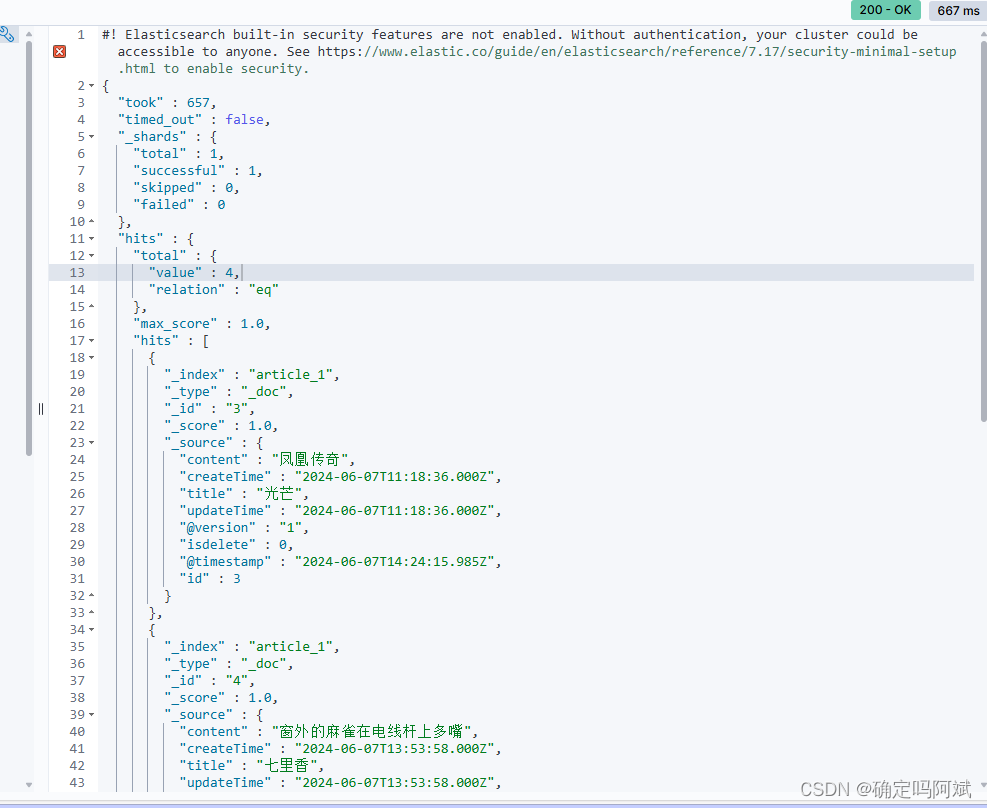
同步成功!
logstash 的优点:配置完成后使用比较方便,插件多
缺点:要多维护组件,一般需要配合其他中间件,比如(kafka)
Canal
下载地址:Releases · alibaba/canal (github.com)
文档:QuickStart · alibaba/canal Wiki (github.com)
实时同步数据,通过监控 MySQL 的 binlog,当数据库发生修改时,会修改 binlog 文件,然后 canal 监听到就可以同步到 ES 中。
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,在 MySQL 目录下新建一个my.ini,配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant,直接在查询控制台执行如下命令
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;bin 目录下 startup 启动即可。
然后 Java 需要一个客户端,首先引入依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>客户端代码
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}正在监听,修改数据之后可以把修改前和修改后的数据查询出来,之后只需要将修改后的数据同步到 ES 即可,比如通过 ES 的 save 方法。

过程出现的问题
1. 在执行命令.\bin\logstash.bat -f .\config\my-task.conf 时报错
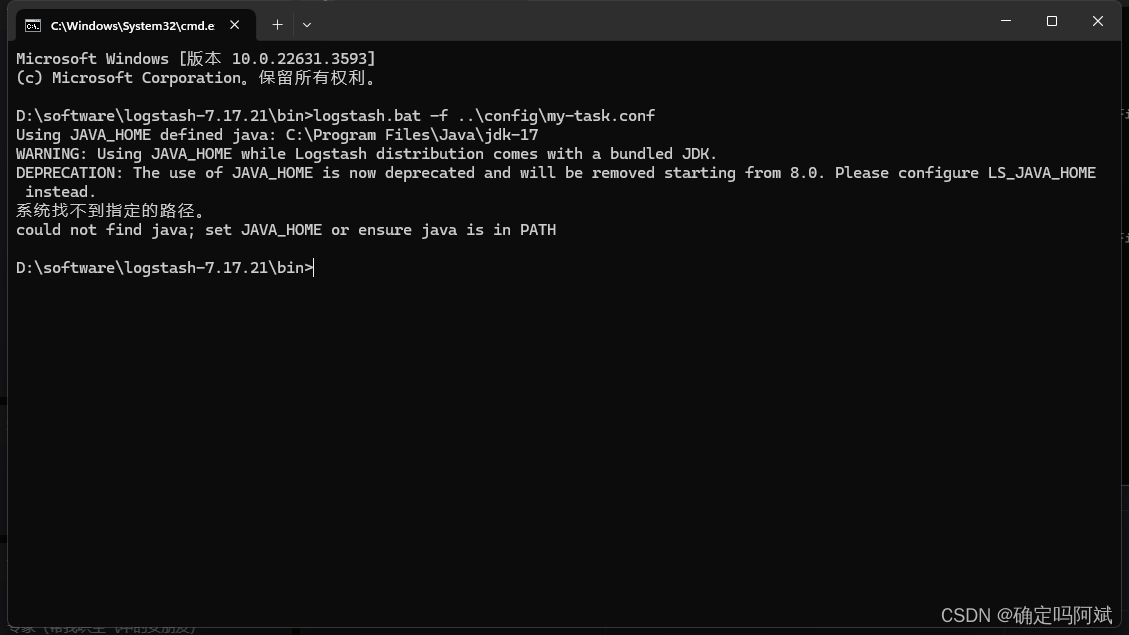
只需要更改 bin 目录下的 setup.bat 文件中的双引号去掉即可。

2. canal 启动 报错 canal 1.1.8版本
不知道什么原因,是和 MySQL 8不兼容还是其他原因,报 druid 错误。
解决方法:简单粗暴,下载 1.1.7 版本,实测有效
3. 找不到 JAVA_HOME
修改变量或者修改启动项
编辑 startup.bat,在文件中添加如下配置:
// 自己的 jdk 路径
set JAVA_HOME=C:\Users\p'b\.jdks\corretto-1.8.0_392
// 覆盖环境变量
set PATH=%JAVA_HOME%\bin;%PATH%














 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









