






网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成,传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。
爬取一个网页首先要导入所需python包
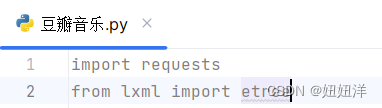
输入网页地址和请求头
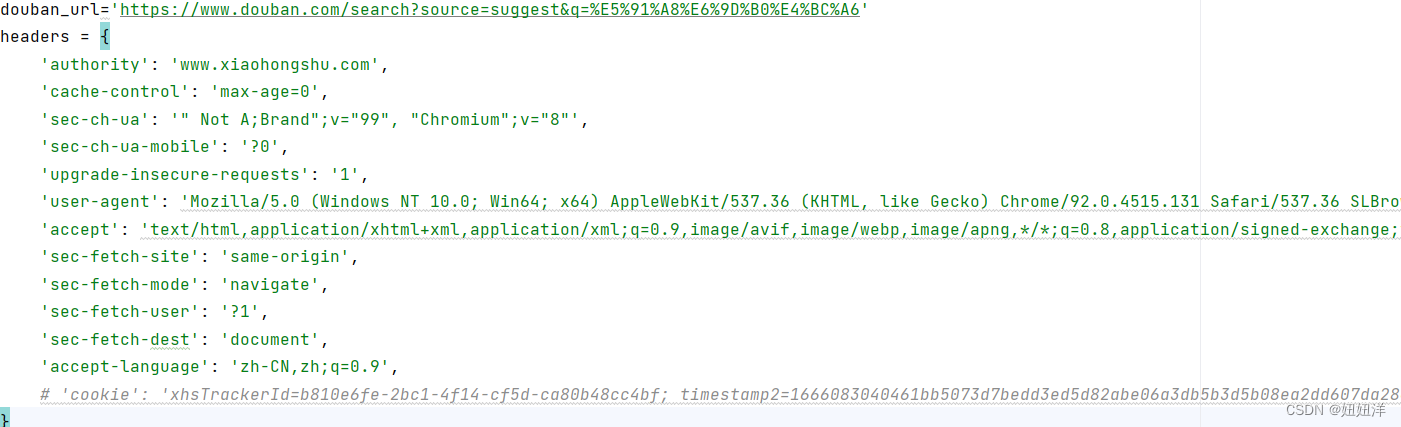
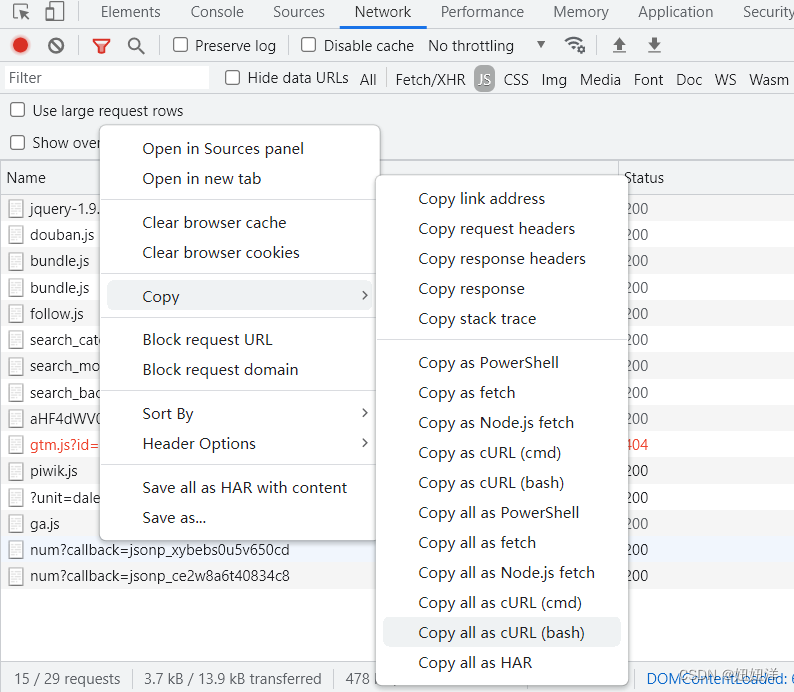
请求头:复制js文件的请求cUrl 命令代码( copy all as cURL(bash)) 到网址https://curlconverter.com/进行翻译(不要复制状态为404的js文件)
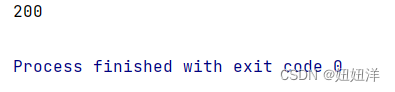
使用requests的get方法请求网址并打印状态码,判断是否年正常访问网页(200为可以访问)

获取网页的xpath
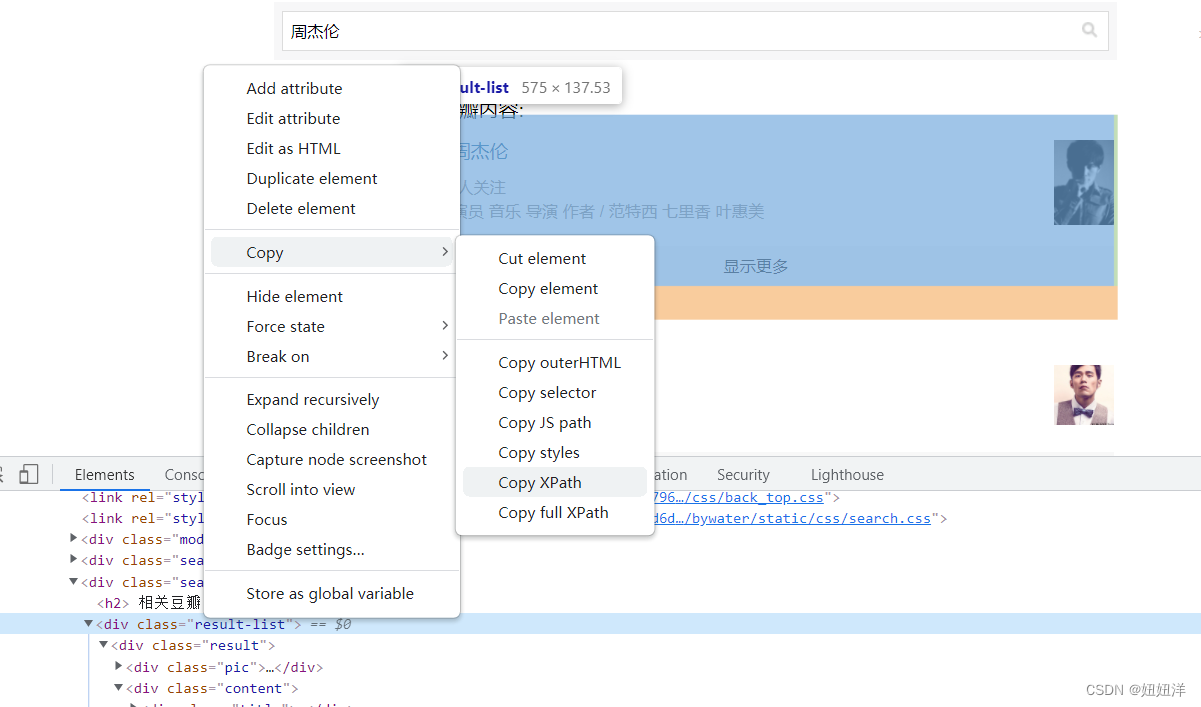
使用for循坏得到其中的详细内容



















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









