






#复旦大学深度学习基础课程期中项目 完成目标检测模型,项目内容为识别宿舍违规电器
引言
在我国的学生宿舍中,违规电器的问题日益严重,这不仅影响了宿舍的安全性,也构成了潜在的火灾隐患。许多电器可能不符合国家安全标准,使用不当甚至可能导致重大事故。为了维护宿舍的安全,通常依赖宿管阿姨定期查寝,以发现并清除这些违规电器。然而,这种传统的查寝方式往往忽视了学生的隐私权,给学生带来了不必要的压力与不适。此外,宿管人员在查寝过程中也可能因为疏忽而忽略某些违规电器,从而未能有效地保障安全。
为了更高效且尊重学生隐私,我们提出了一种基于摄像头监控与神经网络技术的解决方案。通过安装监控摄像头,我们可以实时监测宿舍内的电器使用情况。利用YOLO v5算法的预训练模型进行迁移学习,不仅可以提高检测的准确性,还能降低成本。YOLO v5已经在许多物体检测任务中表现出色,能够快速识别出宿舍内的违规电器,包括电热水壶、电暖器等常见的危险设备。
这种方法的优势在于其高效性与准确性,能够在不干扰学生的情况下,实时监控宿舍的安全隐患。此外,系统的自动化检测将大大减轻宿管的工作压力,让他们有更多的时间与精力关注其他管理事务。通过这种创新的技术手段,我们不仅可以提升宿舍管理的智能化水平,还能有效保障学生的生命财产安全,为创建一个安全、和谐的校园环境贡献力量。
1 数据选取和标注
根据自己在日常生活中搜集的以及网络上宿舍违规电器的图片,使用 labelimg对其中的 100个图像文件进行标注,包括电热水壶、电卷发棒、电锅以及电吹风机,每个图像文件产生一个对应的文字标注文件。
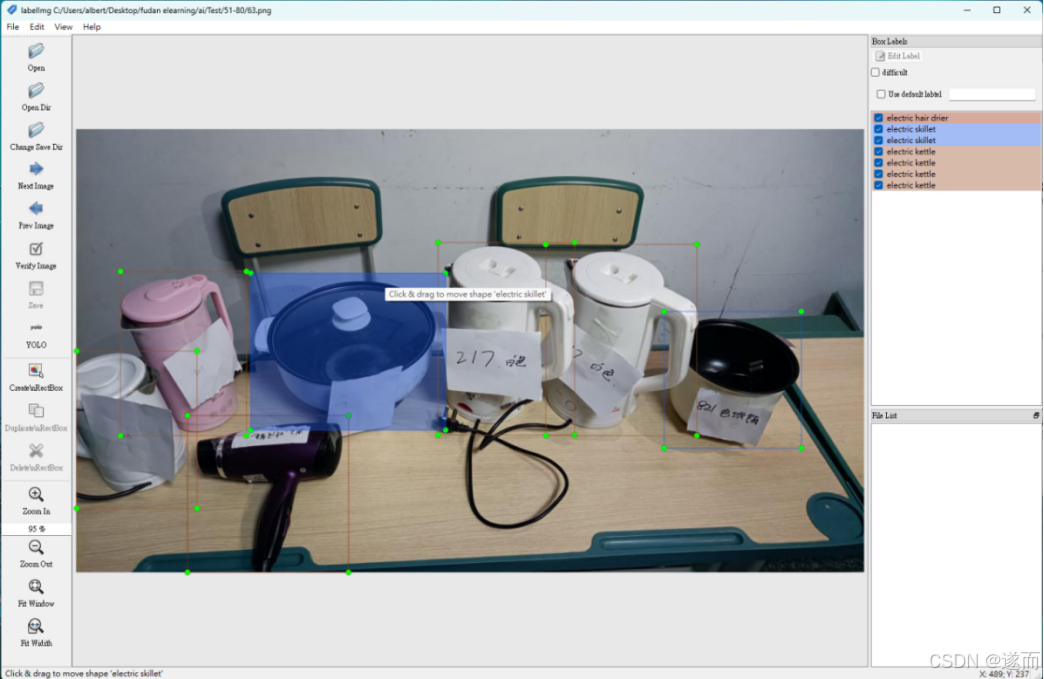
标注后在label文案中存为与图像文件名同名的 txt 文件,如图 2 所示。图像和标注文件分别放在不同的目录。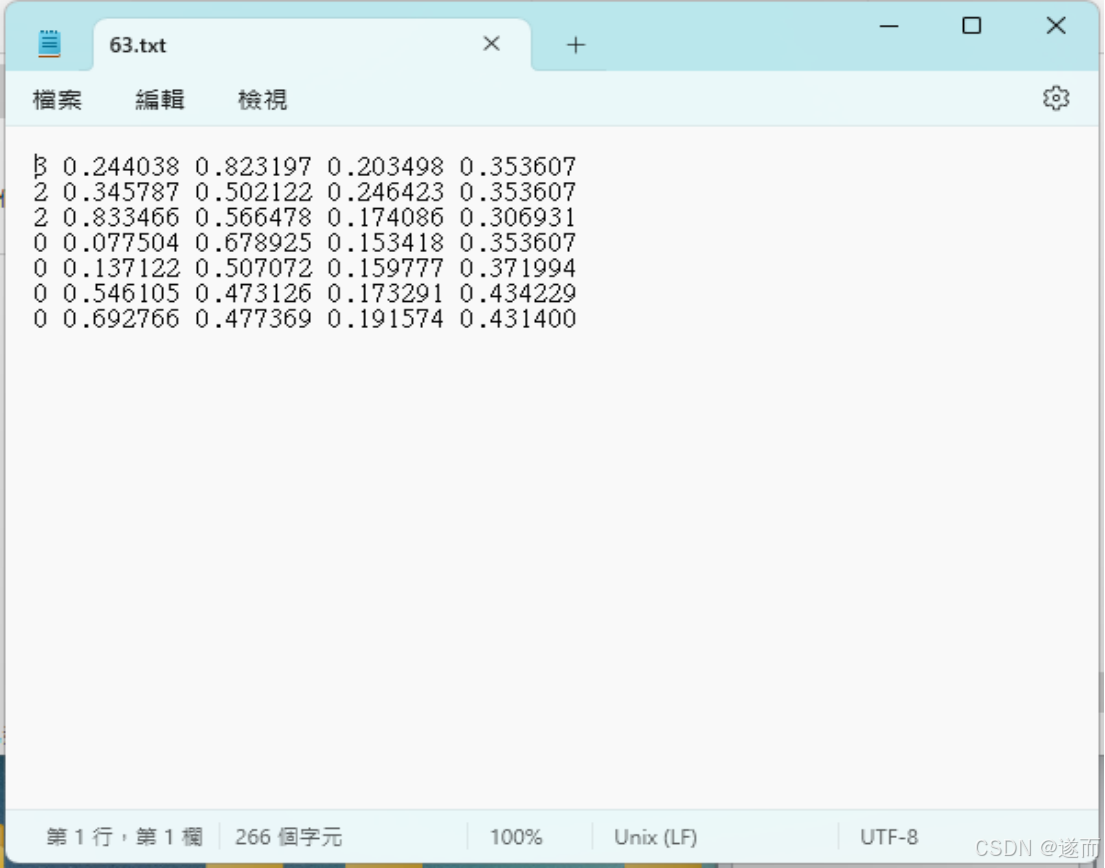
每一张图像对应一个 txt 标注文件,每一行对应图像的一个标注框。每一行有 5 列:类别代号、标注框横向的相对中心坐标 x、纵向的相对中心坐标 y、宽度 w、高度 h。这里为了能准确识别违规电器,在标注时若同一幅图片里有多件电器也分別標明了类别和坐标(图中类别 0 表示电热水壶)。
2数据增强处理
数据增强是深度学习模型训练中的一项重要技术,旨在通过对原始数据进行多种变换来增加数据集的多样性,从而提高模型的泛化能力。在这个过程中,我们可以利用 `enhance.py` 脚本对数据进行一系列的增强处理,包括但不限于:
1. 平移:通过对图像进行水平或垂直方向的平移,模拟不同的视角和位置,从而增加模型对物体位置变化的鲁棒性。
2. 旋转:随机旋转图像一定角度,使模型能够更好地识别旋转后的对象,提高其在不同方向上的识别能力。
3. 镜像反转:通过水平或垂直镜像翻转图像,增加数据集的多样性,特别是在某些对象具有对称性的情况下,这种变换尤为有效。
4. 改饱和度:调整图像的饱和度,可以使得图像的颜色更加丰富或淡化,有助于模型学习到不同光照和色彩条件下的特征。
5. 改亮度:通过改变图像的亮度,模拟在不同光照条件下的图像,为模型提供更广泛的学习场景。
6. 调色:对图像的颜色进行调整,比如改变色调或对比度,使得模型能够适应多种颜色表现,从而提高其对色彩变化的敏感度。
在进行这些增强处理时,我们还需要确保标注文件与图像变换保持一致。这样,标注信息才能准确反映出增强后数据的真实情况。例如,如果对图像进行了平移或旋转,那么对应的边界框或分割掩码也需要相应地调整。这一过程可以通过自动化脚本来实现,确保增强后的数据集在标签上的一致性。
通过以上多种方式的数据增强,我们可以显著扩大数据集的规模,提高模型的训练效果,进而提升其在实际应用中的表现。
代码框架如下(视具体情况修改):
import os
import cv2
import numpy as np
from shutil import copyfile
# 输入图片和标签文件夹路径
image_folder = r'C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\data\images\val'
label_folder = r'C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\data\labels\val'
# 输出增强后的图片和标签文件夹路径
output_image_folder = r'C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\data\images\val_enhancement'
output_label_folder = r'C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\data\labels\val_enhancement'
os.makedirs(output_image_folder, exist_ok=True)
os.makedirs(output_label_folder, exist_ok=True)
# 数据增强函数
def augment_image_and_label(img, label_path, augmentation_type):
h, w, _ = img.shape
label_data = []
if os.path.exists(label_path):
with open(label_path, 'r') as f:
label_data = [line.strip().split() for line in f.readlines()]
if augmentation_type == 'rotate':
angle = np.random.uniform(-15, 15)
rotation_matrix = cv2.getRotationMatrix2D((w // 2, h // 2), angle, 1)
img = cv2.warpAffine(img, rotation_matrix, (w, h))
# 更新标签:绕图像中心旋转
for label in label_data:
cls, cx, cy, bw, bh = map(float, label)
x, y = cx * w, cy * h
nx, ny = np.dot(rotation_matrix, np.array([x, y, 1]))[:2]
label[1], label[2] = nx / w, ny / h
elif augmentation_type == 'flip':
flip_code = np.random.choice([-1, 0, 1])
img = cv2.flip(img, flip_code)
# 更新标签:水平/垂直/对角线翻转
for label in label_data:
cls, cx, cy, bw, bh = map(float, label)
if flip_code == 1: # 水平翻转
label[1] = 1 - cx
elif flip_code == 0: # 垂直翻转
label[2] = 1 - cy
elif flip_code == -1: # 对角线翻转
label[1], label[2] = 1 - cx, 1 - cy
elif augmentation_type == 'brightness':
brightness_factor = np.random.uniform(0.5, 1.5)
img = cv2.convertScaleAbs(img, alpha=brightness_factor, beta=0)
elif augmentation_type == 'blur':
kernel_size = np.random.choice([3, 5, 7])
img = cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
elif augmentation_type == 'noise':
noise = np.random.normal(0, 25, img.shape).astype(np.uint8)
img = cv2.add(img, noise)
# 返回增强后的图片和更新的标签
return img, label_data
# 读取图片和标签文件
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.png', '.jpeg'))]
augmentation_types = ['rotate', 'flip', 'brightness', 'blur', 'noise']
augmentation_factor = 8 # 扩展8倍
# 重新编号计数器
counter = 1
for image_file in image_files:
# 构建完整的图片和标签路径
image_path = os.path.join(image_folder, image_file)
label_path = os.path.join(label_folder, os.path.splitext(image_file)[0] + '.txt')
# 读取图片
img = cv2.imread(image_path)
# 保存原图及标签(重新编号)
new_image_name = f'{counter:04d}.jpg'
new_label_name = f'{counter:04d}.txt'
cv2.imwrite(os.path.join(output_image_folder, new_image_name), img)
if os.path.exists(label_path):
copyfile(label_path, os.path.join(output_label_folder, new_label_name))
counter += 1
# 数据增强
for i in range(augmentation_factor - 1): # 每张图片生成7个增强样本
augmentation_type = np.random.choice(augmentation_types)
augmented_img, augmented_labels = augment_image_and_label(img.copy(), label_path, augmentation_type)
# 保存增强后的图片和标签
new_image_name = f'{counter:04d}.jpg'
new_label_name = f'{counter:04d}.txt'
cv2.imwrite(os.path.join(output_image_folder, new_image_name), augmented_img)
with open(os.path.join(output_label_folder, new_label_name), 'w') as f:
for label in augmented_labels:
f.write(' '.join(map(str, label)) + '\n')
counter += 1
print("数据增强完成,图片和标签已同步扩展并重新命名。")注意:使用脚本进行数据增强的时候必须保证图片数据集和标记文件的一一对应,这里建议使用自然数序列对图片进行命名,方便整理
3.数据集划分
对数据集进行划分,选择了 90%的数据进行训练和验证,10%的数据用于测试。最终目录结构如图所示。Images和 labels 文件夹分别存储原始图像以及经过上述转换后的标注文件。train、val和 test分别存储了训练集、校验集和测试集。
文件组织方式如下:
data/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
4.数据集配置文件及模型配置文件
数据集配置文件是用来描述数据集的结构、类别信息、数据路径等。YOLOv5使用YAML(YAML Ain't Markup Language)格式来编写这个配置文件。
在宿舍违规电器检测模型中,将其命名为:illegal_appliance.yaml 内容如下:
# 数据集配置文件
# 数据路径
train: C:/Users/alfre/AI_deeplearning/base/homework/mypj/yolov5-master/yolov5-master/data/images/train # 训练集路径
val: C:/Users/alfre/AI_deeplearning/base/homework/mypj/yolov5-master/yolov5-master/data/images/val # 验证集路径
# 数据集中的类别
nc: 4 # 类别数量
#names:
# - electric kettle
# - curling iron
# - electric skillet
# - electric hair drier
names: ['electric kettle','curling iron','electric skillet','electric hair drier']YOLOv5的模型配置文件用来定义神经网络架构。这些配置文件描述了模型的层次结构、参数设置以及网络的超参数。在YOLOv5中,通常会根据模型大小选择不同的配置文件,常见的有yolov5s.yaml(small)、yolov5m.yaml(medium)、yolov5l.yaml(large)等
5预训练模型的下载和迁移学习
Yolo v5 多个版本的预训练模型可以到 https://github.com/ultralytics/yolov5 下载
(含 train、detect、export 等多个程序):
git clone https://github.com/ultralytics/yolov5
下载Yolov5s.pt预训练模型,在命令行cmd下安装相应的支撑库:
cd yolov5
pip install –r requirements.txt
按照下面的命令训练、推理(检测)和校验。
-
使用pretrained/yolov5s对上述预处理后的训练数据集进行训练和校验
基于cpu进行训练的指令为:
python train.py --img 416 --batch-size 8 --epochs 100 --data "illegal_ appliance.yaml" --weights pretrained/yolov5s.pt --device cpu
python train.py 是执行训练脚本的命令。`train.py`是YOLOv5项目中用于训练模型的脚本。它包含了训练过程的所有设置和逻辑。
--img 416指定输入图像的尺寸为416x416像素。YOLOv5要求输入图像尺寸固定,而这个参数设置了图像的大小。通常,416或640是YOLOv5模型训练的常见选择。较小的尺寸(如416)会加快训练速度,但可能会影响精度。
--batch-size 8指定训练时的批次大小(batch size)。批次大小决定了每次更新模型参数时使用的训练样本数。
每次训练时,模型会使用8张图像进行梯度更新。较大的批次可以加速训练,但需要更多的GPU内存。
--epochs 100指定训练的轮数。训练轮数(epochs)表示模型会遍历整个训练数据集的次数。
--data "illegal_appliance.yaml"指定数据集的配置文件。在YOLOv5中,数据集的配置文件通常是一个YAML文件,里面包含了数据集的路径、类别数、类别名称等信息。
"illegal_appliance.yaml"是一个YAML配置文件,定义了数据集的相关参数,例如训练集、验证集的路径,类别的数量和名称。你需要根据你的任务(如非法电器识别)编写或修改这个文件。
--weights pretrained/yolov5s.pt指定模型的预训练权重文件。使用预训练权重可以让模型从已有的知识开始训练,通常效果比从头开始训练要好。
cpu表示使用CPU进行训练。如果机器没有GPU,或者希望在CPU上进行训练,可以使用这个设置。使用GPU通常能显著加速训练,但如果只有CPU,训练可能会较慢。
如果在训练过程中遇到中断,并希望能够方便地接续训练,可以使用 --resume 参数,它允许你从中断的地方继续训练。YOLOv5 会自动加载保存的权重文件(例如 last.pt 或 best.pt),并继续从上次训练的状态开始。
指令如下:python train.py --data illegal_appliance.yaml --weights
runs/train/exp16/weights/last.pt --epochs 100 --batch-size 16 --img-size 416 --name exp16 --resume
-
使用detect.py对图片进行检测
terminal运行指令:python detect.py --weights runs/train/exp16/weights/best.pt --img 416 --source
"C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\data\images\valid" --device cpu
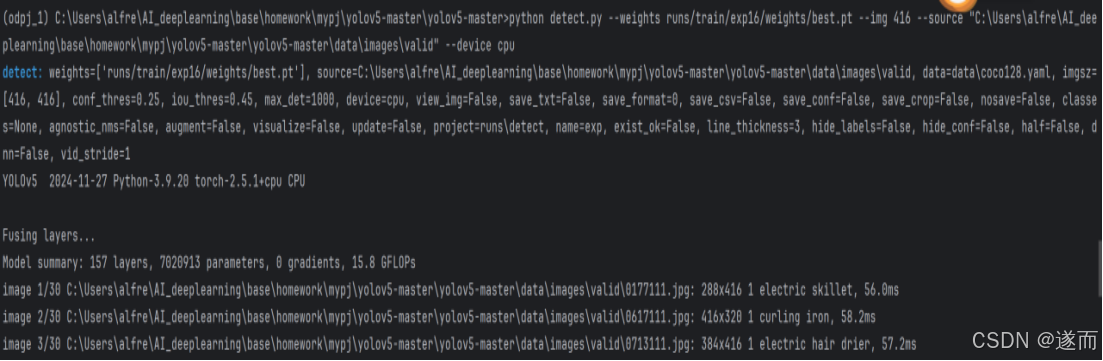
图 5 terminal运行detect.py文件完成图片检测
最终预测结果保存在run/detect/exp下
-
在训练完成后手动验证模型,可以使用 val.py 脚本
terminal运行指令:python val.py --weights
C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\runs\train\exp16\weights\best.pt --data illegal_appliance.yaml --img 416 --batch-size 16 --device cpu
 图 6验证集验证结果
图 6验证集验证结果
图 2 terminal运行指令执行val.py文件
 图 7验证产生文件
图 7验证产生文件
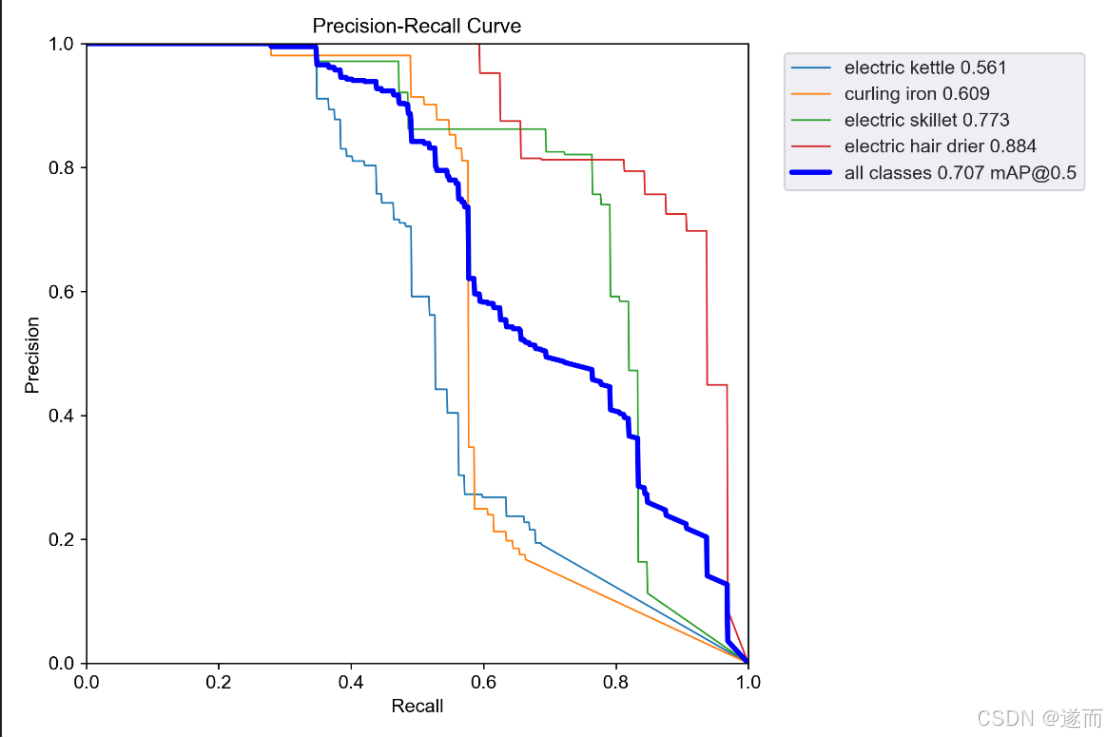 图 8 PR曲线
图 8 PR曲线
验证结果分析:各个类别的结果
Electric Kettle:
Precision: 0.752
Recall: 0.446
mAP@0.5: 0.561
mAP@0.5:0.95: 0.33 该类别的模型表现较弱,召回率较低,可能有很多漏检。精度较高,表明模型预测的电水壶多数是正确的,但仍有不少漏检。
Curling Iron:
Precision: 0.98
Recall: 0.471
mAP@0.5: 0.609
mAP@0.5:0.95: 0.415 卷发棒的精度非常高,但召回率较低,表示模型预测几乎所有为卷发棒的样本都正确,但有很多真实的卷发棒被漏掉。
Electric Skillet:
Precision: 0.82
Recall: 0.695
mAP@0.5: 0.773
mAP@0.5:0.95: 0.468 电热锅在这两个指标上表现较好,尤其是召回率较高,表明模型能识别出大多数电热锅,但也可能产生一些误报。
Electric Hair Dryer:
Precision: 0.591
Recall: 0.938
mAP@0.5: 0.884
mAP@0.5:0.95: 0.513 电吹风的召回率非常高,表明模型能识别出几乎所有电吹风,但精度较低,可能导致大量的误报。
可能的解决改进方法有:
精度与召回的平衡: 可以通过调整模型的决策阈值来提高召回率,但可能会牺牲一些精度。
数据增强: 可以尝试其他增强训练数据的方法,或者使用更加均衡的数据集。
进一步优化: 可以考虑尝试不同的 YOLOv5 变种(如 YOLOv5x)或调整超参数(如学习率、批次大小等)来进一步提升模型性能
训练 100 轮,训练和校验性能如图 3 所示。查看检测结果,
如图 4 所示。
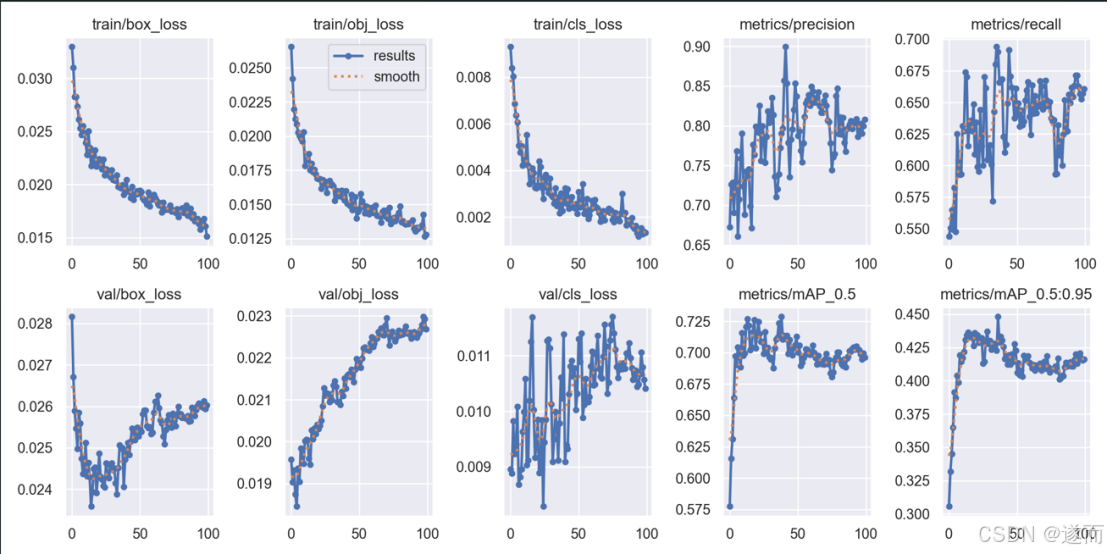 图9训练校验的结果的图片
图9训练校验的结果的图片
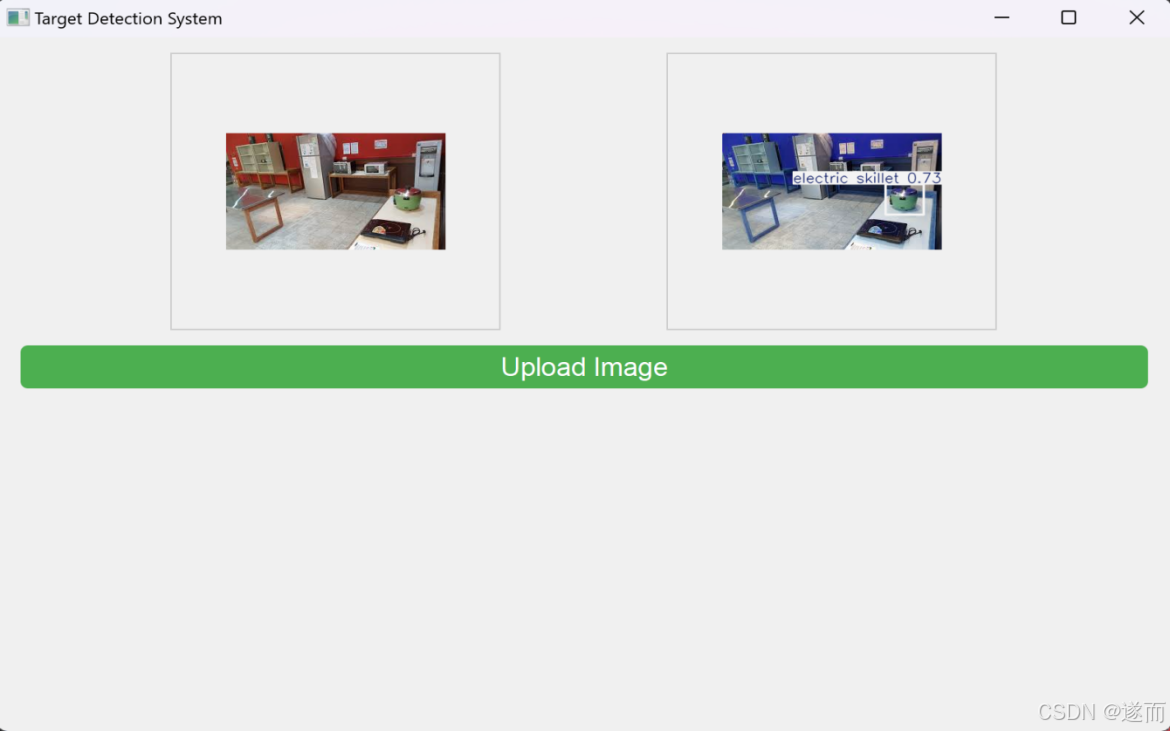
 图 10检测结果例1
图 10检测结果例1
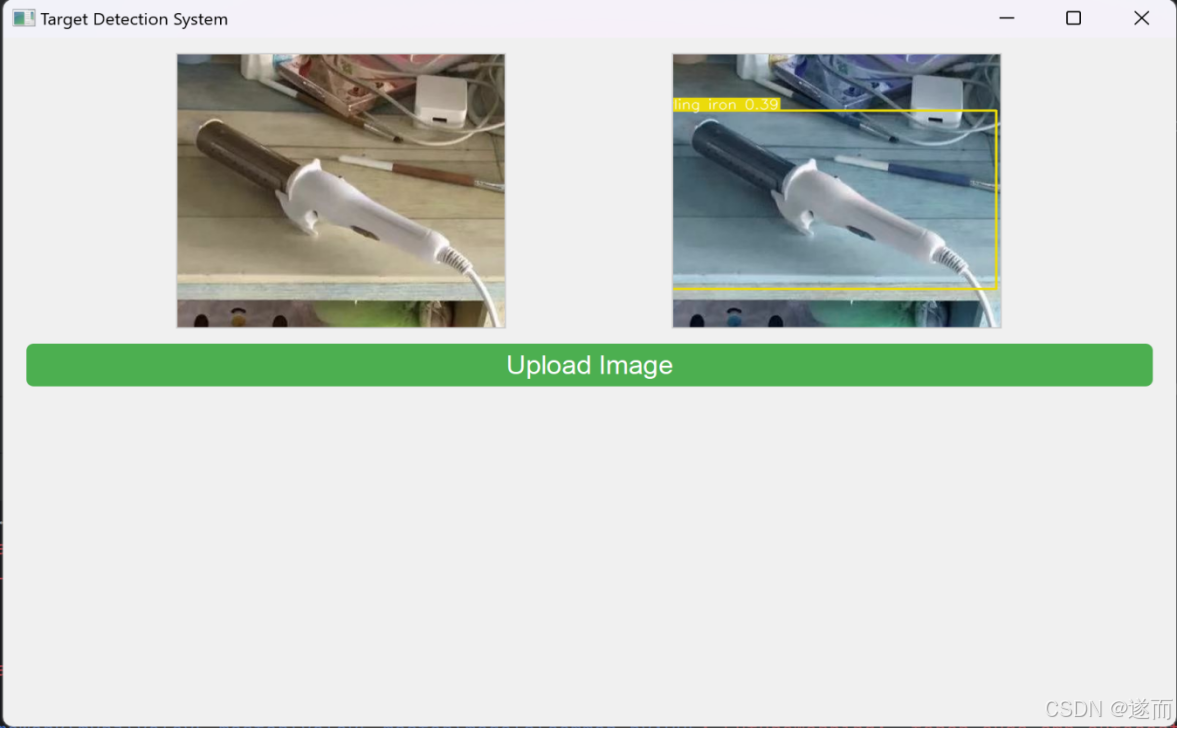
 图 11检测结果例2
图 11检测结果例2
 图 12检测结果例3
图 12检测结果例3
 图 13检测结果例4
图 13检测结果例4
在当前的实验中,模型在验证集上的准确率表现良好,但在实际测试中却出现了一些识别错误,尤其是将杯状物体误识别为电热水壶。这一现象的出现,主要是由于训练数据集相对较小,未能充分覆盖各种物体的多样性和变化,导致模型无法学习到足够的特征来区分这些相似的物体。
这种误识别问题可能源于几个因素:
1. 数据集规模不足:小规模数据集往往无法代表真实世界中的物体分布,特别是对于形状或外观相似的物体,模型可能会在训练过程中学习到错误的特征,从而在测试阶段产生偏差。
2. 类间相似性:杯状物体和电热水壶在形状和颜色上可能有相似之处,尤其是在不同的光照条件下,这种相似性更易导致识别错误。模型在这方面的区分能力不足,可能是因为缺乏足够的多样化样本。
为了改善这一问题,可以考虑以下几种策略:
1. 增大数据集:通过数据增强技术生成更多样本,或者收集更多的真实数据,尤其是那些包含杯状物体和电热水壶的图像。这将有助于模型学习到更丰富的特征,提高其在这类物体上的识别能力。
2. 标记误导物体:对于那些容易引起误识别的物体,可以在数据集中将它们标记为其他类。这种策略能够帮助模型在训练时明确区分这些相似物体,减少混淆,从而提升识别的准确性。
通过以上措施,可以进一步优化模型的性能,提升其在测试集上的准确率,确保其在实际应用中的可靠性和有效性。
3.把训练后的性能最佳模型(支持 TensoFlow、PyTorch 等框架)转化为标准的 ONNX 格式,
以便 Intel 的 OpenVINO、算能、腾讯等公司的平台转化加速推理。
python export.py --weights yolov5s.pt --include torchscript onnx
UI界面设计:
import sys
import torch
import cv2
from PyQt5.QtCore import pyqtSignal, QThread, Qt
from PyQt5.QtGui import QImage, QPixmap, QIcon, QFont
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QPushButton, QFileDialog, QVBoxLayout, QHBoxLayout, \
QDesktopWidget
# 需要导入的YOLOv5模块
from models.common import DetectMultiBackend
from utils.general import check_file, check_img_size, check_imshow, check_requirements, colorstr, non_max_suppression, \
scale_coords
from utils.torch_utils import select_device
class DetectThread(QThread):
update_image_signal = pyqtSignal(QImage)
error_signal = pyqtSignal(str)
def __init__(self, model, image_path):
super().__init__()
self.model = model
self.image_path = image_path
def run(self):
try:
# 读取图像文件
img = cv2.imread(self.image_path)
if img is None:
self.error_signal.emit("Failed to load image.")
return
# 调整图片尺寸以符合模型要求
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = self.model(img) # 使用YOLOv5模型进行推理
# 获取检测结果图像
img_with_boxes = results.render()[0] # 渲染带框的图像
img_with_boxes = cv2.cvtColor(img_with_boxes, cv2.COLOR_BGR2RGB) # 转换为RGB格式
# 转换为QImage对象
height, width, channel = img_with_boxes.shape
bytes_per_line = 3 * width
qimage = QImage(img_with_boxes.data, width, height, bytes_per_line, QImage.Format_RGB888)
# 发射信号更新UI
self.update_image_signal.emit(qimage)
except Exception as e:
self.error_signal.emit(f"Error during detection: {e}")
# 主窗口
class MainWindow(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle('Target Detection System')
# 增大界面尺寸并使其居中
screen = QDesktopWidget().screenGeometry()
width = screen.width() // 2
height = screen.height() // 2
self.setGeometry(screen.left() + width // 2, screen.top() + height // 2, width, height)
self.setWindowIcon(QIcon("images/UI/lufei.png"))
self.device = 'cpu'
# 初始化模型
self.model = self.model_load(
weights=r"C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\runs\train\exp16\weights\best.pt",
device=self.device) # 请确保此路径有效
# 初始化UI界面
self.initUI()
def initUI(self):
"""初始化UI界面组件"""
# 设置背景颜色
self.setStyleSheet("background-color: #f0f0f0;")
# 设置布局
layout = QVBoxLayout()
# 创建一个水平布局用于显示图片
self.image_layout = QHBoxLayout()
# 显示原始图像的标签
self.original_image_label = QLabel(self)
self.original_image_label.setFixedSize(450, 400) # 调整图片显示区域尺寸
self.original_image_label.setAlignment(Qt.AlignCenter) # 设置图片居中显示
self.original_image_label.setStyleSheet("border: 2px solid #cccccc;") # 给图片加边框
self.image_layout.addWidget(self.original_image_label)
# 显示检测结果图像的标签
self.detected_image_label = QLabel(self)
self.detected_image_label.setFixedSize(450, 400) # 调整图片显示区域尺寸
self.detected_image_label.setAlignment(Qt.AlignCenter) # 设置图片居中显示
self.detected_image_label.setStyleSheet("border: 2px solid #cccccc;") # 给图片加边框
self.image_layout.addWidget(self.detected_image_label)
# 将图片显示布局添加到主布局
layout.addLayout(self.image_layout)
# 创建上传按钮并美化
self.upload_button = QPushButton('Upload Image', self)
self.upload_button.setFont(QFont('Arial', 14)) # 设置字体
self.upload_button.setStyleSheet("""
QPushButton {
background-color: #4CAF50;
color: white;
border-radius: 10px;
padding: 10px 20px;
margin: 10px;
}
QPushButton:hover {
background-color: #45a049;
}
""") # 美化按钮
self.upload_button.clicked.connect(self.upload_and_detect)
layout.addWidget(self.upload_button)
# 错误消息显示标签
self.error_label = QLabel(self)
self.error_label.setStyleSheet("color: red; font-size: 12px;")
layout.addWidget(self.error_label)
self.setLayout(layout)
def model_load(self, weights, device):
"""加载YOLOv5模型"""
model = torch.hub.load('ultralytics/yolov5', 'custom', path=weights) # 加载自定义训练模型
return model
def display_image(self, qimage, label):
"""更新UI中的图片显示"""
label.setPixmap(QPixmap.fromImage(qimage)) # 使用QPixmap更新UI显示的图片
def clear_previous_detection(self):
"""清理之前的检测结果"""
self.original_image_label.clear()
self.detected_image_label.clear()
def upload_and_detect(self):
"""上传图片并开始检测"""
file_path, _ = QFileDialog.getOpenFileName(self, '选择图片文件', '', 'Images (*.png *.jpg *.jpeg *.bmp *.tiff)')
if file_path:
self.clear_previous_detection() # 清理之前的检测结果
# 读取并显示原始图像
original_img = cv2.imread(file_path)
original_img_rgb = cv2.cvtColor(original_img, cv2.COLOR_BGR2RGB) # 确保转换为RGB格式
height, width, channel = original_img_rgb.shape
bytes_per_line = 3 * width
original_qimage = QImage(original_img_rgb.data, width, height, bytes_per_line, QImage.Format_RGB888)
# 使用QLabel显示图片并自动缩放
self.display_image(original_qimage, self.original_image_label)
# 在新线程中进行图像推理
self.detect_thread = DetectThread(self.model, file_path)
self.detect_thread.update_image_signal.connect(
lambda qimage: self.display_image(qimage, self.detected_image_label))
self.detect_thread.error_signal.connect(self.display_error)
self.detect_thread.start()
def display_error(self, error_message):
"""显示错误信息"""
self.error_label.setText(error_message)
# __init__ 方法
# 初始化主窗口,设置窗口标题和图标。
# 计算屏幕尺寸并设置窗口位置和大小,使其居中显示。
# 初始化YOLOv5模型。
# 调用 initUI 方法初始化用户界面。
# initUI 方法
# 设置窗口背景颜色。
# 创建垂直布局 layout 和水平布局 image_layout。
# 创建两个 QLabel 用于显示原始图像和检测结果图像,设置其样式和布局。
# 创建上传按钮 upload_button,设置其样式并连接点击事件到 upload_and_detect 方法。
# 添加错误消息显示标签 error_label。
# model_load 方法
# 加载YOLOv5模型,传入权重路径和设备类型。
# display_image 方法
# 更新指定 QLabel 的图片显示。
# clear_previous_detection 方法
# 清除之前显示的原始图像和检测结果图像。
# upload_and_detect 方法
# 打开文件对话框选择图片文件。
# 清除之前的检测结果。
# 读取并显示原始图像。
# 在新线程中进行图像推理,并更新检测结果图像。
# 处理并显示错误信息。
# display_error 方法
# 显示错误信息
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
6 添加语音提示
为更好实时呈现视频检测,我们在实现视频检测的基础上添加识别到目标时的提示音。该项目中,我们使用系统自带的声音。winsound 是 Windows 平台上内置的声音播放库,可以使用 winsound.MessageBeep() 函数播放系统声音,该函数支持不同类型的声音提示,例如 MB_OK、MB_ICONHAND 等。
我们可以定义一个简单的play_sound函数,并在检测到目标时使用该函数即可。
import winsound
def play_sound():
"""
播放系统自带的声音提示。
"""
# 使用默认的 'MB_OK' 声音
winsound.MessageBeep(winsound.MB_OK)
在detect.py中完成修改后,保存,我将其命名为detect_plus.py。执行以下命令:
Python detect_plus.py --weights "C:\Users\alfre\AI_deeplearning\base\homework\mypj\yolov5-master\yolov5-master\runs\train\exp16\weights\best.pt" --source 0 --view-img
即可在视频识别到目标物体的同时播放提示音。
7总结
在本项目中,我们采用了YOLO v5模型对宿舍中的违规电器进行检测。经过充分的训练,模型在训练集和测试集上均表现出较高的准确率,展现了其强大的目标识别能力。然而,在实际应用中,我们也发现了部分误识别和漏识别的情况。例如,一些杯状物品被误判为电热水壶,这种问题可能源于训练数据的多样性不足,或者特定环境下电器的外观特征变化导致的模型适应性差。
为提升模型的实际应用效果,我们做出了以下优化:首先,扩展训练数据集,增加更多种类的电器及不同环境因素的数据,以增强模型的泛化能力;其次,通过调整模型参数,优化其在不同场景下的表现,特别是在光照、角度、尺寸等变化较大的情况下;此外,引入先进的后处理技术,如非极大值抑制(NMS)等,以进一步减少误报率和漏报率,从而提高检测的精确度和鲁棒性。
另外,定期评估模型在实际应用中的表现,并根据反馈不断调整和改进,将是确保系统长期稳定可靠运行的关键。通过以上措施,我们期望能进一步提高模型在实际场景中的准确性和鲁棒性,从而为宿舍安全管理提供更加有效、可靠的技术支持


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









