







DeepSeek vs. o3-mini:推理型大语言模型在机器翻译和文本摘要评估中的表现

原文链接:https://arxiv.org/pdf/2504.08120
在自然语言处理(NLP)领域,大语言模型(LLMs)的发展日新月异。推理型LLMs凭借强大的多步推理和逻辑推理能力,在复杂任务中取得了显著进展。然而,其在自然语言生成(NLG)评估任务中的有效性却尚未得到充分研究。本文围绕这一空白展开,系统对比了推理型LLMs与非推理型LLMs在机器翻译(MT)和文本摘要(TS)评估任务中的表现,为该领域的研究和应用提供了重要参考。
一图流:

一、研究背景与问题
推理型LLMs借助思维链(CoT)监督和强化学习等技术,在复杂逻辑和数学任务中表现优异。但推理并非总是有益,在某些任务中,CoT提示可能会降低模型性能。
在NLG评估方面,尽管基于LLM的评估指标已成为主流,但大多依赖非推理型LLMs,推理型LLMs在其中的作用鲜有人探究。
本研究聚焦于两个关键问题:一是推理模型在MT和TS评估中是否优于传统模型;二是模型蒸馏在降低计算成本的同时,能在多大程度上保留推理模型的评估能力。
二、相关工作
2.1 MT和TS的传统评估指标
早期MT评估指标注重系统翻译与参考翻译的表面相似性,如BLEU和METEOR,分别依赖n - gram重叠和编辑距离。为更好捕捉语义变化,MoverScore利用词嵌入和Word Mover’s Distance衡量翻译间的距离,BERTScore则通过计算BERT生成的上下文词嵌入来改进MT评估。此外,基于自然语言推理(NLI)的指标和训练指标也在MT评估中得到应用。
在TS评估中,ROUGE是基础指标,通过计算系统生成摘要与参考摘要的重叠度来评估,但在处理语义等价和事实一致性方面存在局限。为此,出现了基于内容的指标(如Pyramid和BE)以及语义指标(如SUPERT),SummEval等基准测试则进一步推动了TS评估指标的系统比较。
2.2 基于LLM的评估
“LLM - as - a - Judge”范式利用指令跟随型LLMs直接评估系统输出的流畅性、连贯性和事实一致性等维度。
在MT评估中,GEMBA通过提示LLMs评估单个翻译片段并聚合分数,在WMT22指标基准测试中取得优异成绩;AutoMQM在此基础上让LLMs检测和分类翻译错误,提供更具解释性和细粒度的反馈。
在TS评估中,G - Eval采用基于标准的框架和思维链提示,FineSurE则结合关键事实提取和验证,Eval4NLP在共享任务设置中对基于提示的LLM评估器进行了基准测试。
然而,这些工作大多使用非推理型LLMs,推理型LLMs的优势尚未明确。
2.3 评估指标的效率
随着基于LLM评估的计算成本不断上升,研究人员开始探索轻量级替代方案。
FrugalScore使用蒸馏和表示剪枝技术在不影响指标可靠性的前提下减小模型规模;EffEval研究了效率与性能之间的权衡,发现基于适配器的微调方法和紧凑架构是可行的;COMETINHO通过优化推理引入了高效的COMET变体,xCOMET - lite利用量化和蒸馏实现实时应用;PromptOptMe则通过优化提示减少令牌开销并保持评估准确性。
本研究在此基础上,进一步探究小型蒸馏推理模型在NLG评估中的有效性。
2.4 推理型LLMs
DeepSeek - R1和OpenAI o3 - mini等模型通过CoT提示和组相对策略优化(GRPO)等技术实现复杂的逐步推理,在数学和逻辑要求较高的任务中表现出色。
这些模型还通过CoT压缩、模型蒸馏和测试时缩放策略提高了效率和质量。但它们在NLG评估中的潜力尚未得到充分挖掘,现有方法常使用启发式CoT提示,未充分发挥推理型LLMs的优势。
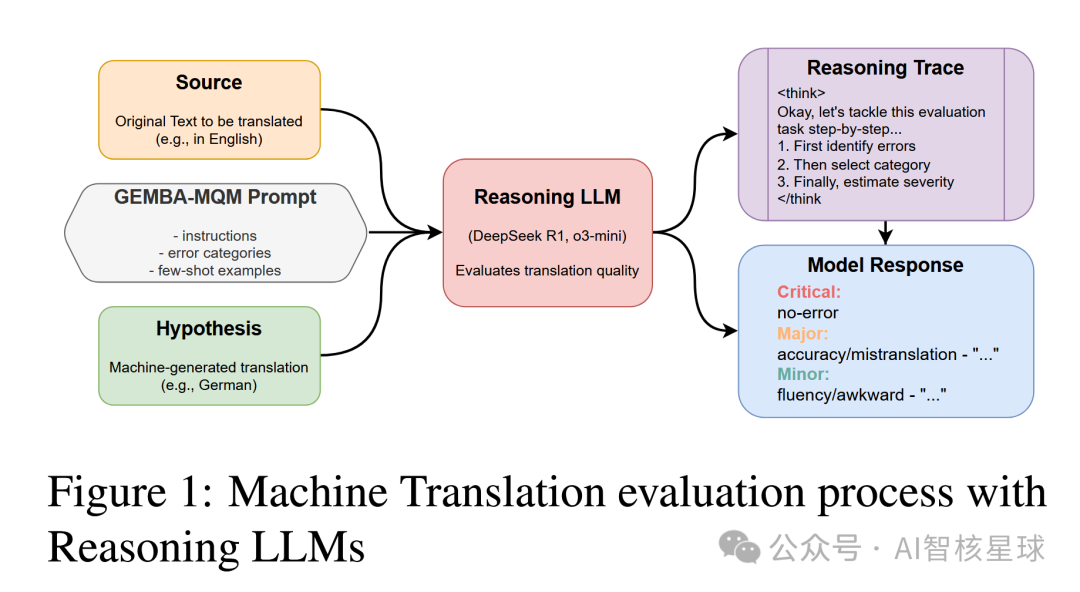
三、实验设置
3.1 评估框架
本研究聚焦于MT和TS评估这两个主要的NLG任务,采用已在近期基准测试中表现出色的基于提示的评估指标。
在MT评估中,使用GEMBA - MQM指标。该指标通过提示LLMs检测翻译在准确性、流畅性和术语等维度的错误,并为每个错误分配严重程度分数,以此评估机器翻译的质量,在WMT22指标共享任务中展现出了卓越的性能。
对于TS评估,实施G - Eval方法。该方法从连贯性、一致性、相关性和流畅性等多个维度提示LLMs评估摘要,并提供明确的评估标准,要求模型生成数值分数和解释,非常适合用于测试推理能力对评估结果的影响。
3.2 数据集
MT评估使用WMT22指标共享任务数据集,该数据集包含多种语言对的翻译,以及源文本、参考翻译、系统翻译和人类在片段和系统层面的判断。
研究重点关注en - de、he - en和zh - en这三种语言对,以评估模型在不同语言结构下的性能。每个翻译都附带多维度质量指标(MQM)注释,便于对翻译质量进行精细评估。
TS评估采用SummEval数据集,其中包含16个不同摘要系统对100篇CNN/DailyMail数据集新闻文章生成的摘要的人类判断,每个摘要在连贯性、一致性、相关性和流畅性四个维度上进行评分,分数范围为1到5。
此外,还使用了Eval4NLP数据集,该数据集为摘要评估提供了另一个基准,且人类判断分数未在线发布,可避免数据污染,用于更客观地评估推理和非推理模型。
3.3 模型
为系统探究研究问题,本研究评估了三类模型:
-
SOTA推理型LLMs:包括DeepSeek - R1,它是DeepSeek的推理增强版本,通过强化学习和思维链机制进行微调,拥有600B参数,代表了当前推理架构的前沿水平;以及OpenAI o3 - mini变体,通过设置推理努力参数(高、中、低),研究推理强度对评估性能的影响。
-
推理模型的蒸馏变体:DeepSeek - R1 - Distill - Llama - 70B(基于Llama架构,70B参数)、DeepSeek - R1 - Distill - Qwen - 32B(基于Qwen架构,32B参数)和DeepSeek - R1 - Distill - Llama - 8B(基于Llama架构,8B参数),分别代表大规模、中规模和小规模部署的蒸馏模型。
-
非推理型LLMs(对照组):DeepSeek V3(DeepSeek - R1的非推理对应模型)、GPT - 4o - mini(GPT - 4家族的非推理变体)、Qwen - 2.5 32B(专注于通用能力的32B参数模型)、LLaMa - 3.3 70B和LLaMa - 3.1 8B(分别为大规模和小规模的通用LLM)。
这种模型选择涵盖了不同参数规模的推理和非推理模型,有助于全面分析模型能力差异以及蒸馏的影响。
3.4 评估协议
为确保公平比较,所有模型均使用相同的提示模板进行评估。对于GEMBA - MQM指标,遵循Kocmi和Federmann(2023a)描述的模板,指示模型识别翻译中的错误并据此对翻译进行评分;对于G - Eval,实施Liu等人(2023)详细介绍的提示策略,要求模型根据特定标准从多个维度评估摘要。
在MT评估的元评估中,计算模型分数与人类判断之间的片段级皮尔逊相关性系数,以及系统级成对准确率(衡量指标根据人类判断正确预测两个系统中哪个更好的频率)。
在TS评估中,计算模型评估与人类判断在四个维度(连贯性、一致性、相关性和流畅性)上的片段级肯德尔相关性。
四、实验结果
4.1 文本摘要评估
在SummEval和Eval4NLP数据集上进行的文本摘要评估结果显示(如下表所示):
| 模型名称 | 推理 | SummEval(平均) | Eval4NLP |
|---|---|---|---|
| DeepSeek R1 | 是 | 0.351 | 0.583 |
| DeepSeek V3 | 否 | 0.399 | 0.630 |
| R1 LLaMa 70B | 是 | 0.315 | 0.556 |
| LLaMa 3.3 70B | 否 | 0.375 | 0.624 |
| R1 Qwen 32B | 是 | 0.355 | 0.564 |
| Qwen2.5 32B | 否 | 0.393 | 0.619 |
| R1 LLaMa 8B | 是 | 0.174 | 0.368 |
| LLaMa 3.1 8B | 否 | 0.228 | 0.488 |
| OpenAI o3 - mini - high | 是 | 0.337 | 0.644 |
| OpenAI o3 - mini - low | 是 | 0.335 | 0.645 |
| OpenAI GPT - 4o - mini | 否 | 0.346 | 0.634 |
OpenAI的推理模型在不同推理努力设置下表现稳定,o3 - mini - high和o3 - mini - low在SummEval上的平均得分接近(分别为0.337和0.335),在Eval4NLP上取得了最高的总体分数(分别为0.644和0.645)。DeepSeek V3在所有测试模型中获得了SummEval的最高平均得分(0.399),在连贯性(0.462)、相关性(0.446)和流畅性(0.356)方面表现突出。
从推理与非推理模型的对比来看,在大多数模型家族中,非推理模型的表现优于推理模型。
例如,DeepSeek V3在SummEval平均得分(0.399对0.351)和Eval4NLP(0.630对0.583)上均超过DeepSeek R1;LLaMA 3.3 70B在这两个指标上也优于R1 LLaMA 70B;Qwen 2.5 32B同样在SummEval平均得分(0.393对0.355)和Eval4NLP(0.619对0.564)上胜过R1 Qwen 32B。
不过,推理模型在某些方面也有优势。DeepSeek R1在一致性指标上表现出色(0.565对0.331,相关性提高70%),表明其在事实准确性方面与人类判断的一致性更好;R1 Qwen 32B在一致性方面也比Qwen2.5 32B强20%(0.540对0.449);OpenAI o3 - mini模型在连贯性上比非推理的GPT - 4o - mini高出约50%(0.482对0.321)。
在比较DeepSeek R1与其蒸馏变体时发现,DeepSeek R1 - Distill - Qwen - 32B在SummEval平均得分上保持了原始模型的质量,在Eval4NLP上保留了97%的性能(0.564对0.583),且该蒸馏模型的参数仅为原始模型的1/21(32B对685B)。
但其他蒸馏版本(R1 LLaMa 70B和R1 LLaMa 8B)在SummEval数据集上的表现明显逊于原始模型,且在摘要评估的一致性方面优势丧失。不过,R1 LLaMA 70B在Eval4NLP数据集上仍保留了96%的原始模型性能(0.556对0.583)。
4.2 机器翻译评估
在WMT23数据集上进行的机器翻译评估结果如下表所示:
| 模型名称 | 推理 | en - de(段级Pearson’s ρ) | he - en(段级Pearson’s ρ) | zh - en(段级Pearson’s ρ) | 系统级准确率 |
|---|---|---|---|---|---|
| DeepSeek R1 | 是 | 0.364 | 0.398 | 0.441 | 0.908 |
| DeepSeek V3 | 否 | 0.490 | 0.394 | 0.512 | 0.904 |
| R1 LLaMa 70B | 是 | 0.421 | 0.365 | 0.451 | 0.932 |
| LLaMa 3.3 70B | 否 | 0.590 | 0.420 | 0.522 | 0.924 |
| R1 Qwen 32B | 是 | 0.388 | 0.338 | 0.465 | 0.920 |
| Qwen2.5 32B | 否 | 0.521 | 0.390 | 0.519 | 0.944 |
| R1 LLaMa 8B | 是 | 0.310 | 0.325 | 0.410 | 0.915 |
| LLaMa 3.1 8B | 否 | 0.476 | 0.335 | 0.421 | 0.916 |
| OpenAI o3 - mini - high | 是 | 0.577 | 0.421 | 0.568 | 0.920 |
| OpenAI o3 - mini - medium | 是 | 0.517 | 0.404 | 0.505 | 0.928 |
| OpenAI o3 - mini - low | 是 | 0.471 | 0.413 | 0.491 | 0.928 |
| OpenAI GPT - 4o - mini | 否 | 0.410 | 0.435 | 0.487 | 0.928 |
OpenAI的模型在不同语言对中表现强劲,o3 - mini - high在en - de(0.577)和zh - en(0.568)语言对的段级相关性上达到最高。在OpenAI家族中,较高的推理努力设置通常对应更好的性能,尤其是在en - de和zh - en语言对中。有趣的是,GPT - 4o - mini在he - en语言对中表现相对较好(0.435),超过了其推理对应模型。在系统级准确率方面,OpenAI模型得分一致(o3 - mini变体为0.928),在对翻译系统进行排名时表现稳健。
与文本摘要评估的结果类似,在翻译评估任务中,非推理模型通常优于推理模型。DeepSeek V3在en - de(0.490对0.364)和zh - en(0.512对0.441)语言对中均超过DeepSeek R1,在he - en语言对中表现相当;R1 LLaMa 70B在所有语言对中与LLaMa 3.3 70B相比都有显著下降,尤其是在en - de(0.590对0.421)和he - en(0.420对0.365)语言对中;Qwen 2.5 32B在所有语言对中的相关性都高于R1 Qwen 32B,在en - de语言对中的差距最大(0.521对0.388)。例外的是OpenAI的o3 - mini - high,在en - de(0.577对0.410)和zh - en(0.568对0.487)两个语言对上的表现优于GPT - 4o - mini。
在系统级准确率方面,推理和非推理模型的差异不太明显。Qwen 2.5 32B达到了最高的系统级准确率(0.944),R1 LLaMa 70B(0.932)略优于其非推理对应模型(0.924)。蒸馏后的R1模型与全尺寸模型相比,性能明显下降。尽管LLaMa 3.1 8B的参数远少于LLaMa 3.3 70B,但在三个语言对中仍保持了适度的段级相关性(分别为0.476、0.335和0.421)。
五、推理分析
为深入研究显式推理与评估性能之间的关系,本研究分析了每个模型使用的推理令牌数量与各种评估指标之间的相关性。具体而言,计算了推理令牌计数与评估误差(模型预测分数与真实分数之间的绝对差值)以及模型分配分数之间的皮尔逊相关性。该分析在WMT23数据集的机器翻译评估任务上进行,结果如下表所示:
| 模型 | 误差相关性 | LLM分数相关性 |
|---|---|---|
| DeepSeek R1 | -0.0154 | 0.0199 |
| R1 LLaMa 70B | -0.0429 | -0.2083 |
| R1 Qwen 32B | -0.0039(不显著) | -0.1508 |
| o3 - mini - high | -0.1183 | -0.4742 |
| o3 - mini - medium | -0.1104 | -0.4148 |
在分析推理部分,除了上述相关性分析,还给出了推理过程的实例。以DeepSeek R1模型对WMT23数据集中英德语言对的翻译质量评估为例,展示了有效推理和无效推理的情况。
-
有效推理示例:对于句子“Statistics Norway’s figures showed that foreigners were scattered all over the city’s districts, as Søndre Nordstrand, the borough furthest south in Oslo, had over 14,000 immigrants registered there.”的翻译“Statistiken Norwegens Zahlen zeigten, dass Ausländer in den Bezirken der Stadt verstreut waren, da Søndre Nordstrand, der Bezirk weiter südlich in Oslo, dort über 14.000 Einwanderer registriert hatte.”,模型能正确识别出 “Statistiken Norwegens” 是 “Statistics Norway” 的错误翻译(属于术语错误,为关键错误);“weiter südlich” 对 “furthest south” 的翻译错误(影响准确性,是主要错误) ;“fünftgrößten Ausländern” 对 “fifth most foreigners” 的错误翻译(也是主要错误)以及 “bildeten den Rest der zehn Bezirke” 表述有些生硬(属于次要的流畅性问题) 。
-
无效推理示例:在翻译 “(PERSON2) Because like the way I believe Martin does hislittle translation, so he translates more sentences at once and then picks only the centre one...” 为 “(PERSON2) Weil ich glaube, dass Martin seine <unverständlich/> kleine Übersetzung so macht, dass er mehrere Sätze auf einmal übersetzt und dann nur den mittleren auswählt...” 时,模型虽识别出 “kleine” 翻译 “little” 可能存在语义偏差(是主要的准确性错误),但在判断 “durchgeht” 的动词位置时出现错误。在 “und so das ganze Dokument durchgeht” 结构中,“und” 连接后应为主要从句,动词应在第二位,而模型翻译中 “durchgeht” 位置错误,本应是 “und so geht er das ganze Dokument durch” ,但模型将其归为主要错误的判断有些过度,实际上句子仍可理解,这体现了模型在推理过程中存在的问题 。
六、研究结论
6.1 主要发现
-
架构特异性表现:不同推理模型架构在NLG评估任务中的性能差异显著。DeepSeek - R1在翻译和摘要评估中,相较于其非推理版本DeepSeek V3,表现普遍较差;而OpenAI的o3 - mini模型在多个评估场景中,尤其是机器翻译评估,比其可能的非推理等效模型GPT - 4o - mini表现更优。这表明推理能力本身并不能保证评估质量的提升,模型架构的实现方式以及增强推理能力的训练方法起着关键作用。
-
DeepSeek的局限性:DeepSeek - R1在评估任务中的相对较差表现值得深入研究。尽管它通过强化学习专门训练以增强推理能力,但在翻译(如en - de语言对中,与人类判断的相关性为0.364,而DeepSeek V3为0.490;zh - en语言对中,0.441对比0.512)和摘要任务(如连贯性方面,0.381对比0.462;相关性方面,0.303对比0.446)中,与人类判断的相关性均低于DeepSeek V3。这种性能差距可能源于多语言训练数据不足,或者缺乏针对评估任务的特定微调。虽然DeepSeek - R1在摘要的某些一致性评估中表现出色(如0.565对比0.331,相关性提升70.7%),但其整体较弱的性能表明,它的推理方法可能与精细的NLG评估要求不太匹配,也可能意味着使用R1系列模型时,需要进一步调整评估提示。
-
OpenAI o3 - mini的有效性:OpenAI的o3 - mini变体展现出卓越的评估能力。o3 - mini - high模型在en - de(0.577)和zh - en(0.568)翻译对中获得了最高的相关性分数,大幅超过非推理的GPT - 4o - mini(分别为0.410和0.487,提升约70%和16%)。相关性分析进一步支持了这一发现,o3 - mini - high在推理令牌计数与评估误差之间呈现最强的负相关( - 0.1183),表明更广泛的推理可能会带来更准确的评估,支持了测试时缩放假设。
-
蒸馏效果:研究结果表明,在为评估任务蒸馏推理能力方面,效果存在差异。与原始的DeepSeek - R1相比,R1 Qwen 32B保持了合理的性能,而较小的R1 LLaMa 8B在摘要评估中表现出显著的性能下降(平均相关性从0.351降至0.174)。这说明有效的评估相关推理的蒸馏需要足够的模型容量,较小的蒸馏模型可能会失去进行细致评估所需的关键能力。
-
任务特定推理需求:推理模型在不同任务中的差异表现表明,摘要和翻译评估可能需要不同的推理策略。OpenAI模型在翻译评估中具有优势,但在摘要任务中的优势并不明显。不同NLG任务对有效评估所需的推理性质可能有很大差异,翻译可能从o3 - mini模型采用的推理方法中受益更多。
6.2 对未来研究的启示
这些发现表明,虽然推理能力可以提高评估性能,但其效果在很大程度上取决于架构实现、任务特定的适配以及推理强度。未来的工作不应仅仅关注纳入推理能力,而应着重使推理方法与NLG评估任务的要求紧密对齐。这可能涉及专门的微调方案、针对特定任务的推理策略,或者对架构进行修改,以增强推理在比较评估中的应用。
同时,本研究也存在一定的局限性。例如,假设GPT - 4o - mini是与推理模型o3 - mini在能力和/或规模上最可能的非推理等效模型,但由于这两个模型的规模信息均未公开,该假设无法得到验证。此外,虽然o3 - mini的推理API允许指定推理强度(低、中、高),但DeepSeek R1及其蒸馏变体没有这样的选项。未来的研究可以通过在生成预定量的推理令牌后强制生成结束标记的方式,来研究R1在不同推理强度下的性能表现 。
关键问题
推理型LLMs在NLG评估任务中的表现为何会因模型架构而异?
答:不同模型架构的训练方式、推理机制以及对任务的适配性不同。如DeepSeek-R1虽专为推理任务设计,但可能在多语言训练数据或针对评估任务的微调上不足,导致在翻译和摘要评估中表现不如非推理版本;而OpenAI o3-mini模型可能在训练中融入了更适合评估任务的元素,推理强度增加时能提升性能。
蒸馏推理能力对不同规模模型在NLG评估任务中的影响有何不同?
答:对于中型模型(如R1 Qwen 32B),蒸馏能保持相对合理的性能,与原始模型相比,在SummEval平均得分和Eval4NLP得分上差异较小;但对于小型模型(如R1 LLaMa 8B),蒸馏会导致性能大幅下降,在SummEval平均得分从0.351降至0.174 。这表明有效蒸馏评估相关推理需要足够的模型容量,小型蒸馏模型可能会丢失精细评估所需的关键能力。
从实验结果看,未来如何改进推理LLMs在NLG评估任务中的应用?
答:一是针对不同任务的特点,设计专门的推理策略,使推理方法更好地与任务需求对齐;二是进行更有针对性的微调训练,比如增加多语言训练数据,优化评估任务相关的训练目标;三是探索更合理的模型架构,以提升推理能力在评估任务中的有效性,同时平衡模型的计算成本和性能表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









