







💓 博客主页:C-SDN花园GGbond
⏩ 文章专栏:玩转c语言
1.翻译环境和运⾏环境
1.1 翻译环境
在ANSI C的任何⼀种实现中,存在两个不同的环境。
第一种翻译环境:在这个环境下源代码被转换成可执行的机器指令。我们平时用VS等工具写出来的源代码都是由字符组成的,只有我们人才能读懂其中的意思,机器是不能直接读懂的,机器只能执行二进制指令,因此就需要把我们写的源文件变成机器指令。而我们写的以 .c 结尾的源文件就是经过翻译环境才得以变成以 .exe 结尾的可执行程序(里面包含的就是可执程序)
第2种是执⾏环境,它⽤于实际执⾏代码。
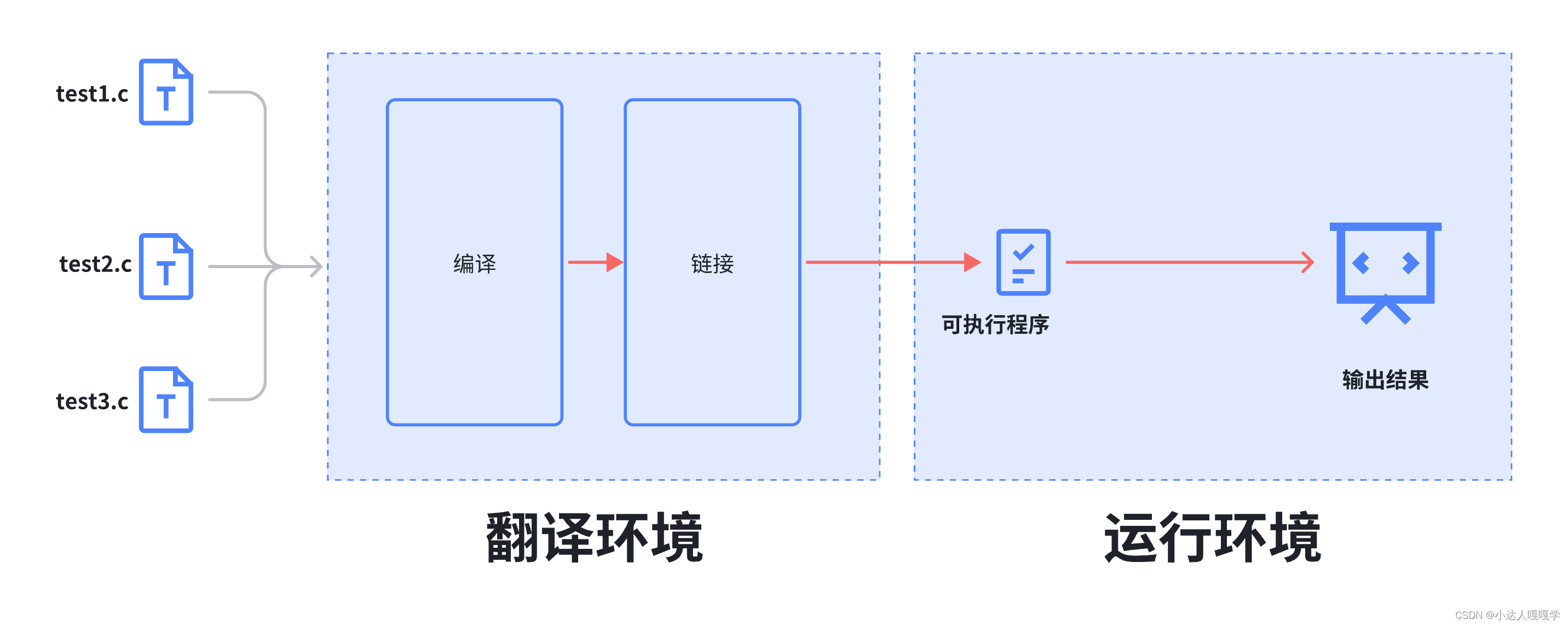
在VS中由源代码生成一个可执行程序的过程如下图所示:
1.2运行环境
执行环境是用于实际执行代码的。
2.详解翻译环境
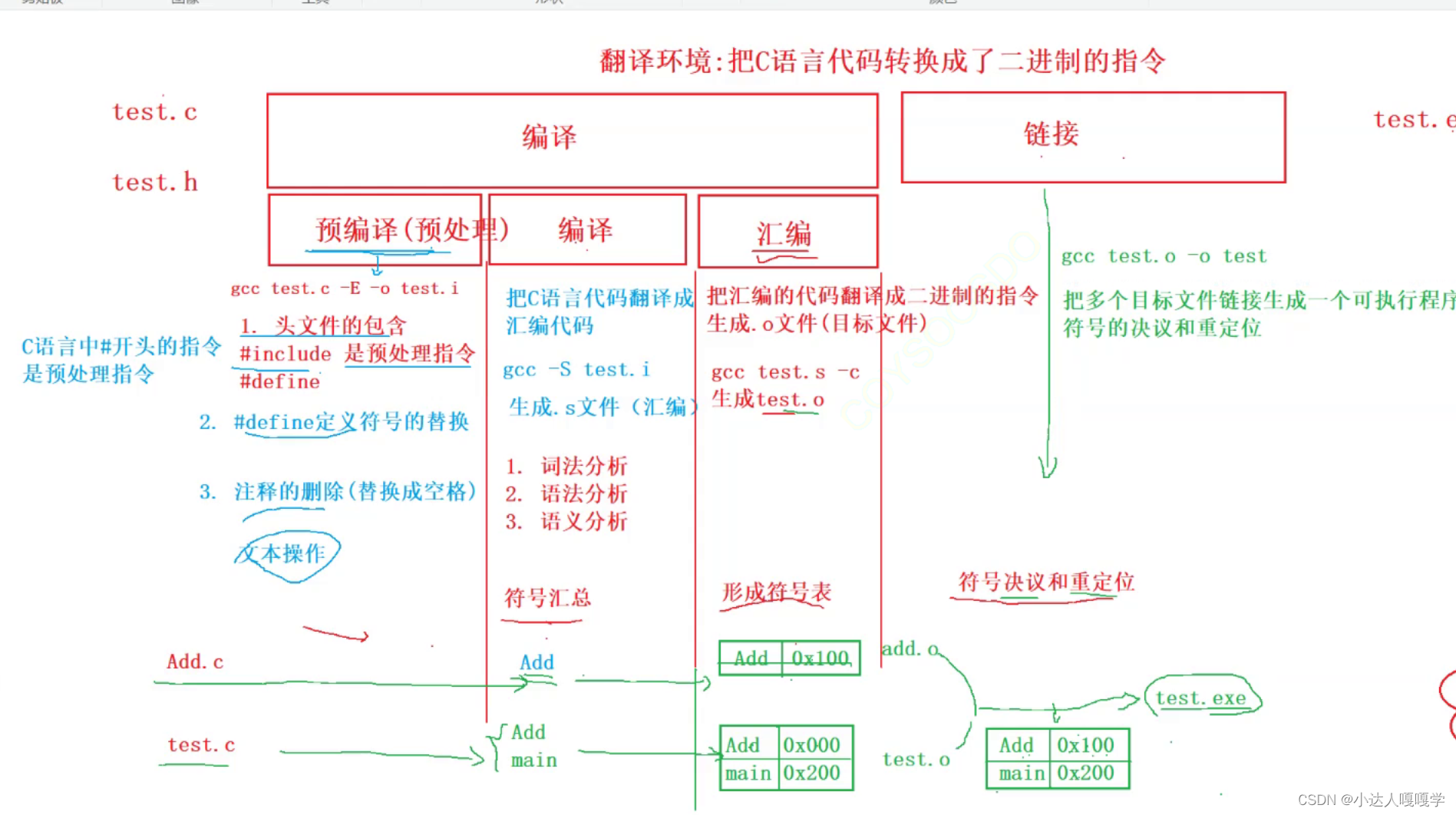
那翻译环境是怎么将源代码转换为可执⾏的机器指令的呢?这⾥我们就得展开开讲解⼀下翻译环境所做的事情。
其实翻译环境是由编译和链接两个⼤的过程组成的,⽽编译⼜可以分解成:预处理(也叫预编译)、编译、汇编三个过程。
!](https://img-blog.csdnimg.cn/direct/4b5db7c5825b4896b8481cfd113dd70d.png)
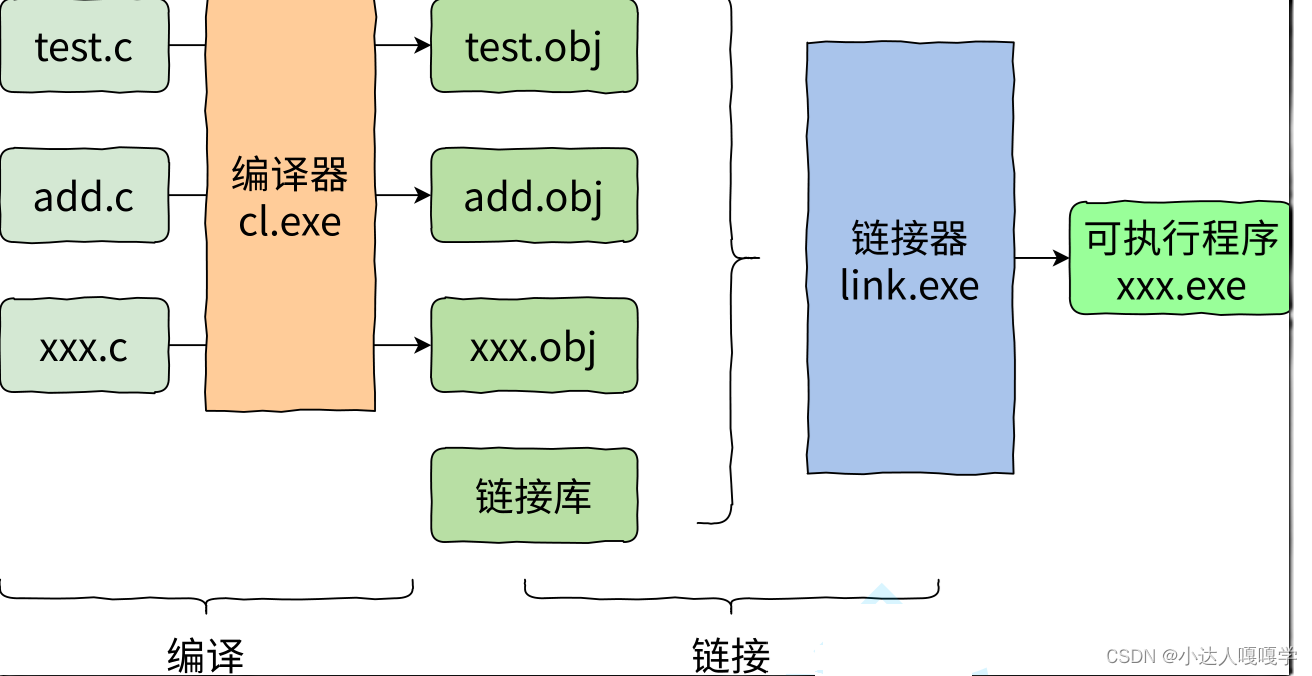
⼀个C语⾔的项⽬中可能有多个 .c ⽂件⼀起构建,那多个 .c ⽂件如何⽣成可执⾏程序呢?
• 多个.c⽂件单独经过编译器,编译处理⽣成对应的⽬标⽂件。
• 注:在Windows环境下的⽬标⽂件的后缀是 .obj ,Linux环境下⽬标⽂件的后缀是 .o
• 多个⽬标⽂件和链接库⼀起经过链接器处理⽣成最终的可执⾏程序。
• 链接库是指运⾏时库(它是⽀持程序运⾏的基本函数集合)或者第三⽅库。
如果再把编译器展开成3个过程,那就变成了下⾯的过程:
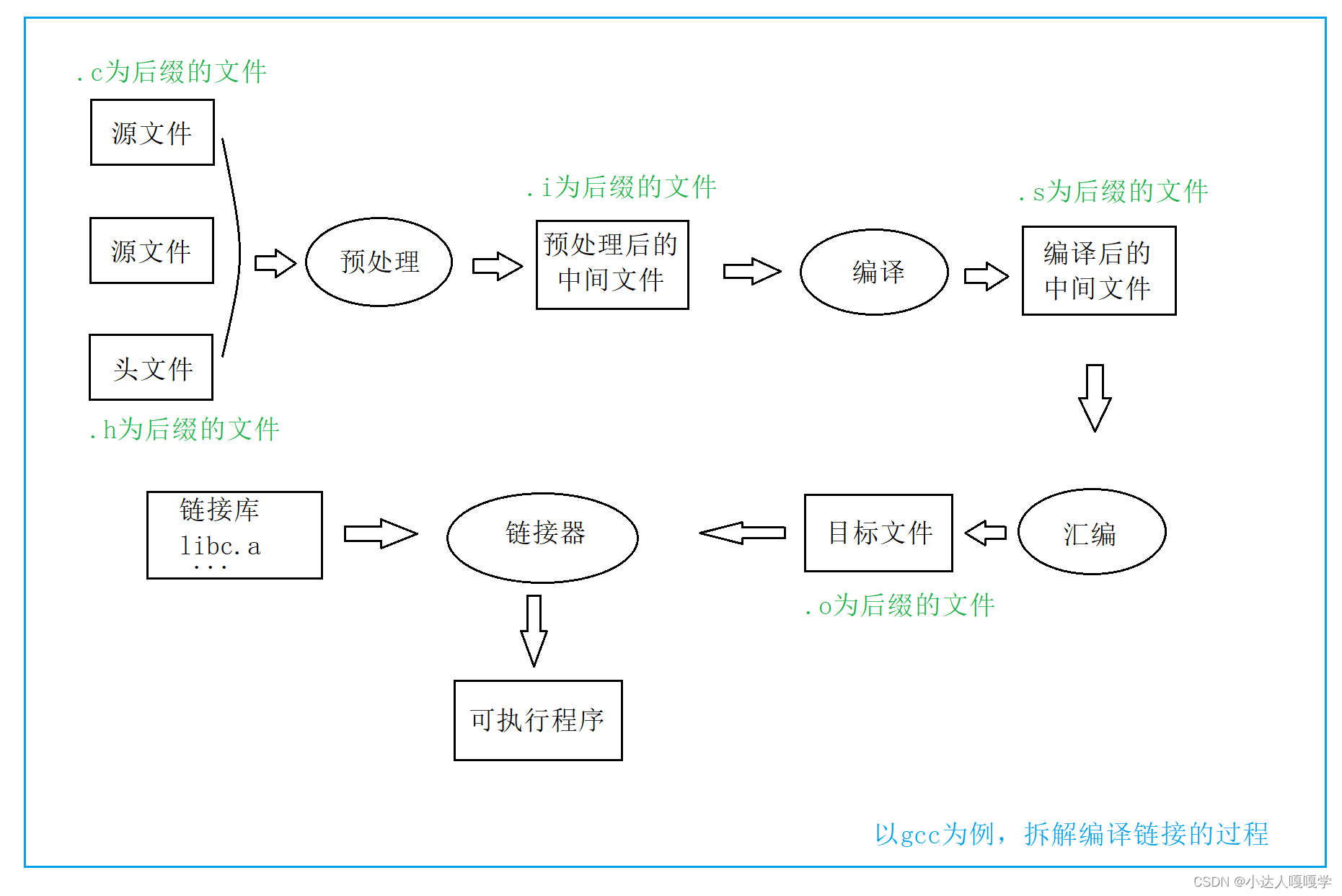
2.1预处理(预编译)
在预处理阶段,源⽂件和头⽂件会被处理成为.i为后缀的⽂件。
在 gcc 环境下想观察⼀下,对 test.c ⽂件预处理后的.i⽂件,命令如下:
1 gcc -E test.c -o test.i
预处理阶段主要处理那些源⽂件中#开始的预编译指令。⽐如:#include,#define,处理的规则如下:
• 将所有的 #define 删除,并展开所有的宏定义。
• 处理所有的条件编译指令,如: #if、#ifdef、#elif、#else、#endif 。
• 处理#include 预编译指令,将包含的头⽂件的内容插⼊到该预编译指令的位置。这个过程是递归进⾏的,也就是说被包含的头⽂件也可能包含其他⽂件。
• 删除所有的注释
• 添加⾏号和⽂件名标识,⽅便后续编译器⽣成调试信息等。
• 或保留所有的#pragma的编译器指令,编译器后续会使⽤。
经过预处理后的.i⽂件中不再包含宏定义,因为宏已经被展开。并且包含的头⽂件都被插⼊到.i⽂中。所以当我们⽆法知道宏定义或者头⽂件是否包含正确的时候,可以查看预处理后的.i⽂件来确认。
预编译结束接下来仍不是机器识别的二进制指令,那么就需要继续操作,那么接下来就是编译阶段
2.2编译
编译过程就是将预处理后的⽂件进⾏⼀系列的:词法分析、语法分析、语义分析,符号汇总(会把代码中涉及到的一些符号,例如:函数名、全局等的符号汇总下来),⽣成相应的汇编代码⽂件。
用下⾯代码进⾏编译来说明
array[index] = (index+4)*(2+6);
2.2.2词法分析:
将源代码程序被输⼊扫描器,扫描器的任务就是简单的进⾏词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字⾯量、特殊字符等)。
上⾯程序进⾏词法分析后得到了16个记号:

2.2.2 语法分析
接下来语法分析器,将对扫描产⽣的记号进⾏语法分析,从⽽产⽣语法树。这些语法树是以表达式为节点的树。
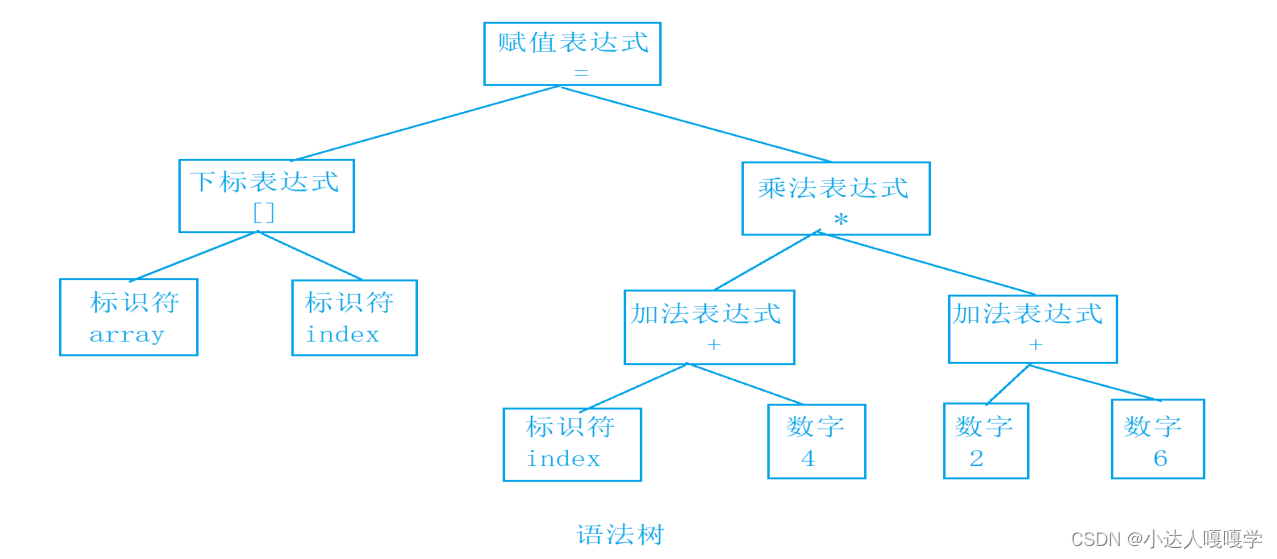
2.2.3 语义分析
由语义分析器来完成语义分析,即对表达式的语法层⾯分析。编译器所能做的分析是语义的静态分析。静态语义分析通常包括声明和类型的匹配,类型的转换等。这个阶段会报告错误的语法信息
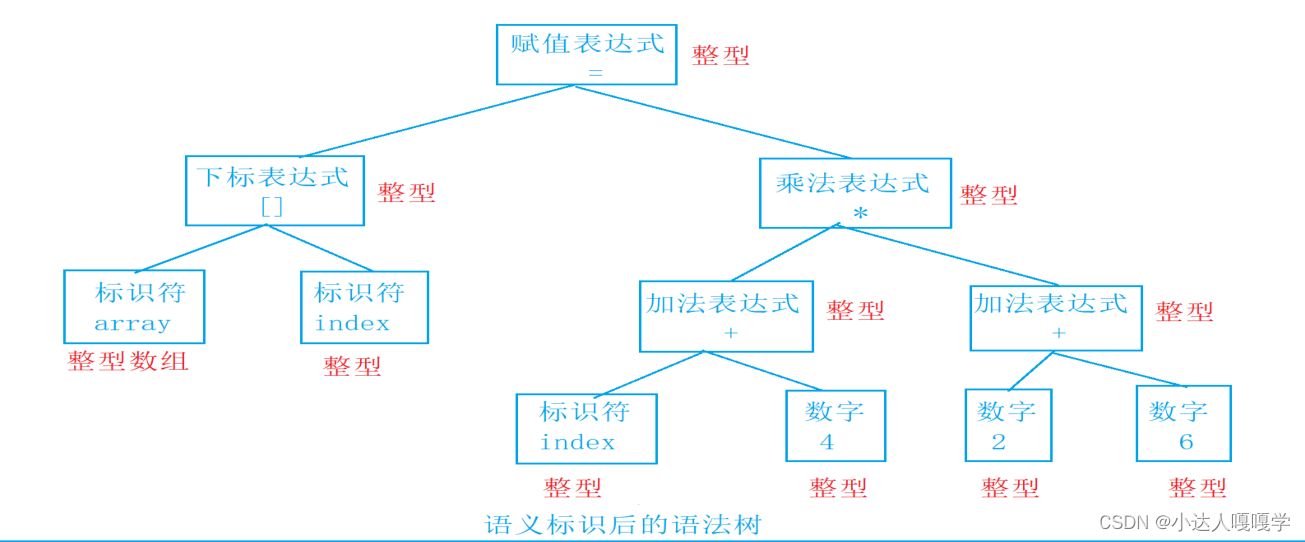
2.2.4 符号汇总
会把代码中涉及到的一些符号,例如:函数名、全局等的符号汇总下来
词法分析、语法分析、语义分析没有错误并且符号汇总之后就会⽣成相应的汇编代码⽂件。
2.3汇编
1.汇编器是将汇编代码转转变成机器可执⾏的指令,每⼀个汇编语句⼏乎都对应⼀条机器指令。就是根据汇编指令和机器指令的对照表⼀⼀的进⾏翻译,也不做指令优化。
2.汇编过程最重要的是形成符号表,这和编译阶段执行的符号汇总是相关联的,符号表把编译阶段汇总的符号与其地址对应起来形成了一张表,这张表就被叫做符号表。符号表在链接这个阶段还要被使用。
2.3.链接
链接是⼀个复杂的过程,链接的时候需要把⼀堆⽂件链接在⼀起才⽣成可执⾏程序。链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤。
链接解决的是⼀个项⽬中多⽂件、多模块之间互相调⽤的问题。
链接阶段主要干了下面两件事:
1.合并段表(编译得到的目标文件都是一个独立的ELF文件)
2.符号表的合并和符号表的重定位
上面提到过,编译器对每个源文件是进行单独处理的,最终每个源文件都会得到一个目标文件,因此每个目标文件都会有一个符号表,以下面的程序为例:
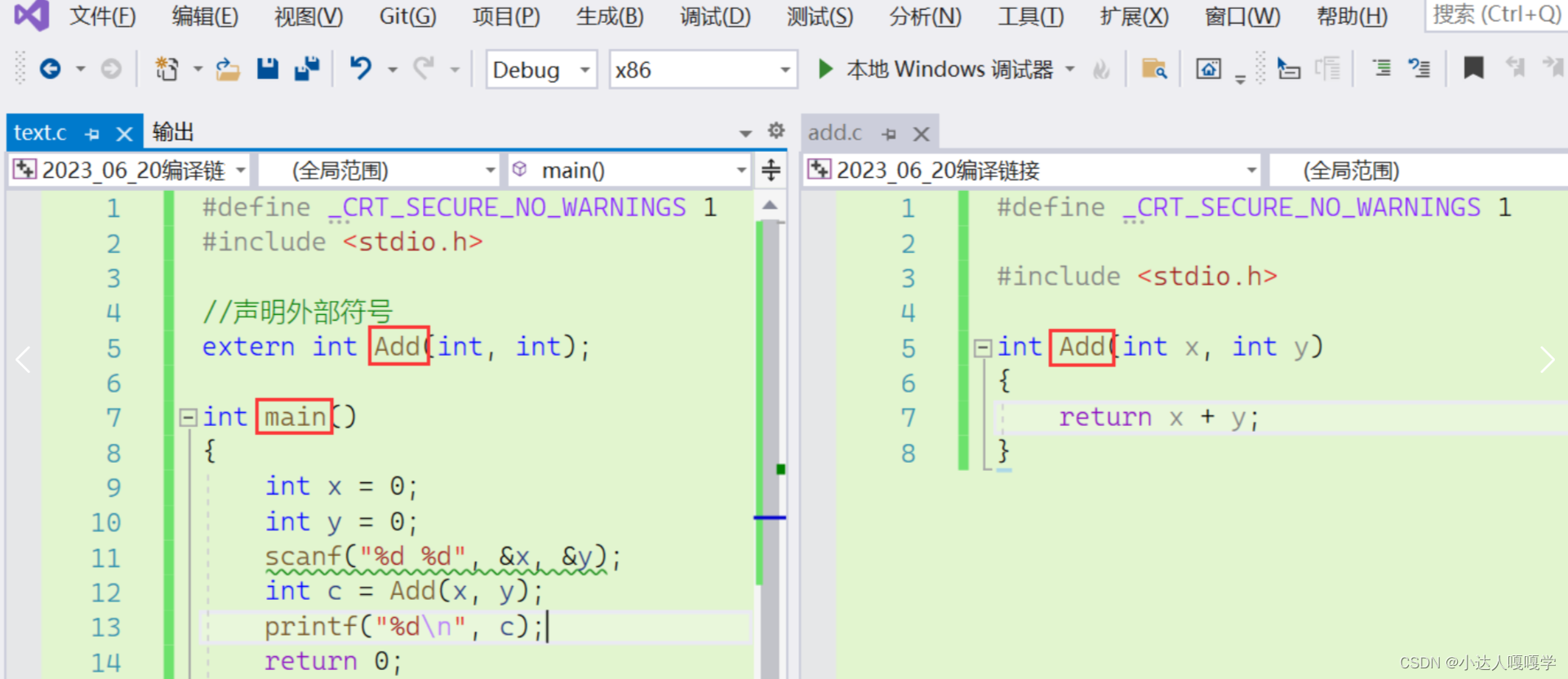
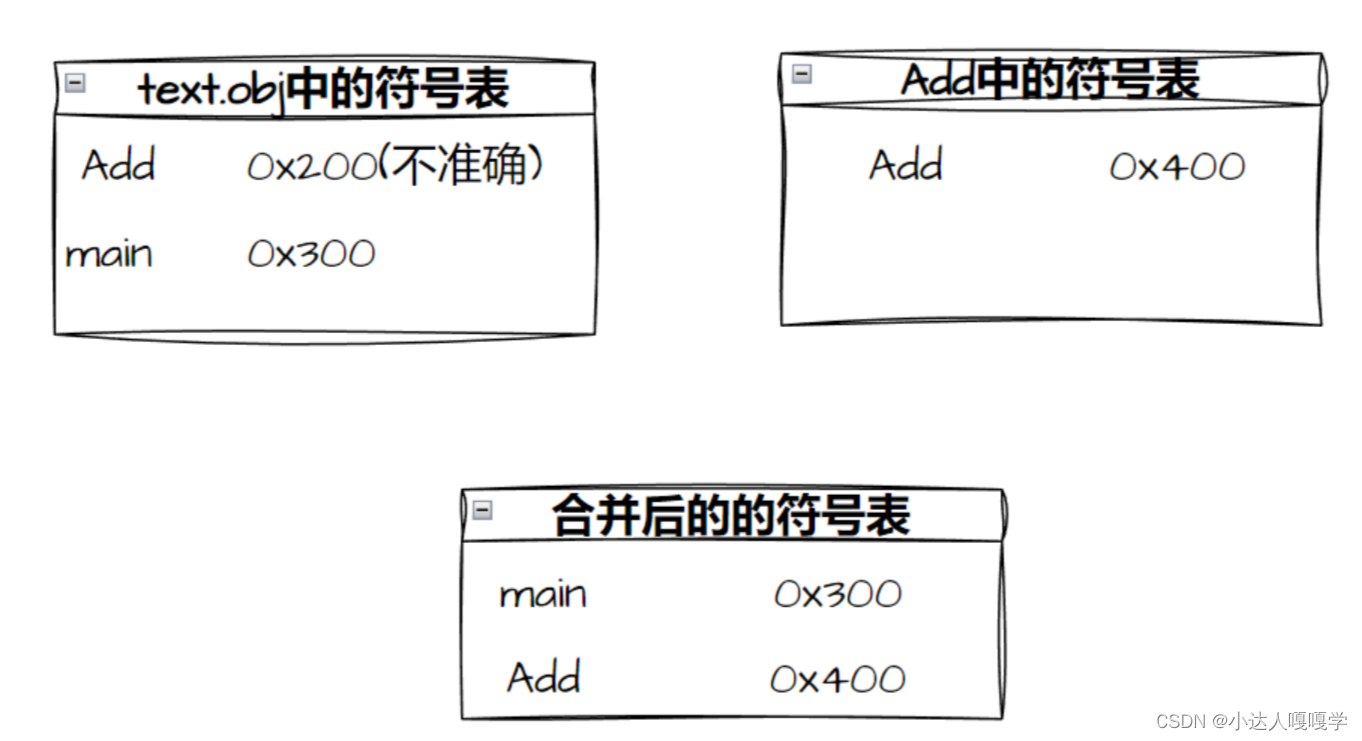
text.obj中的符号表记录了Add和main,add.obj中记录了Add,但实际上在text.c中没有Add函数的定义,所以text.obj中的符号表并不知道Add函数的真实地址,而add.obj中的符号表,则记录了Add函数的正确地址。在进行符号表合并的时候,两个表中都有Add和地址的对应关系,但text.obj中的对应关系一定是错误的,所以就会舍弃它,保留add.obj中正确的Add和地址的对应关系,同时mani和地址的对应关系也会被保留,最终的可执行程序中的符号表就是合并后的符号表。
符号表记录了一些函数名、全局的符号和地址的对应关系,最终汇总符号表可以帮助我们实现跨文件函数调用,就像上面的程序,我们在text.c中通过extern关键字声明了外部符号Add,然后就可以在当前的源文件里去调用add.c中的Add函数,其实没有这条声明语句程序也能正常运行,因为就算声明了,text.obj中记录的也是一条无意义的地址对应关系,最终在汇总符号表的时候还是会被删除。但是注意:如果要使用另一个源文件中的全局变量,是一定要声明的,否则会报错。如果没有用extern去声明,在编译阶段进行语法分析的时候就会报错。这里函数和全局变量的差异仅仅是编译器自己对这两种情况的处理方式有所不同,正确的做法是只要使用了另一个源文件中的函数、全局变量等都要通过extern进行声明
再通过下面的程序理解:
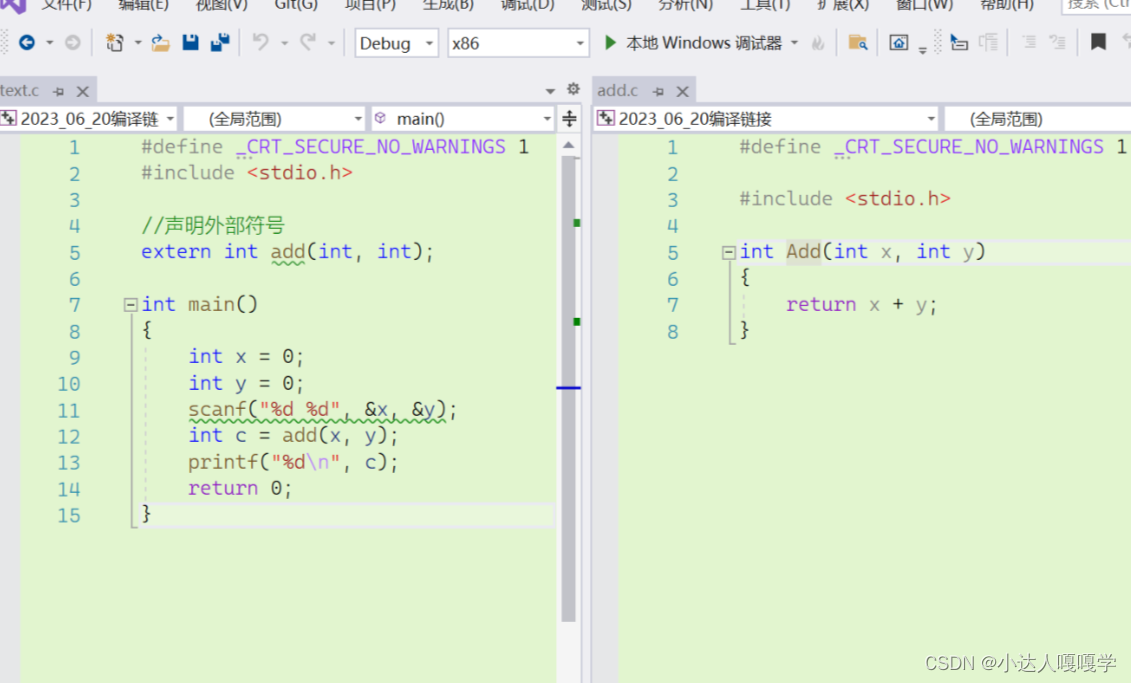
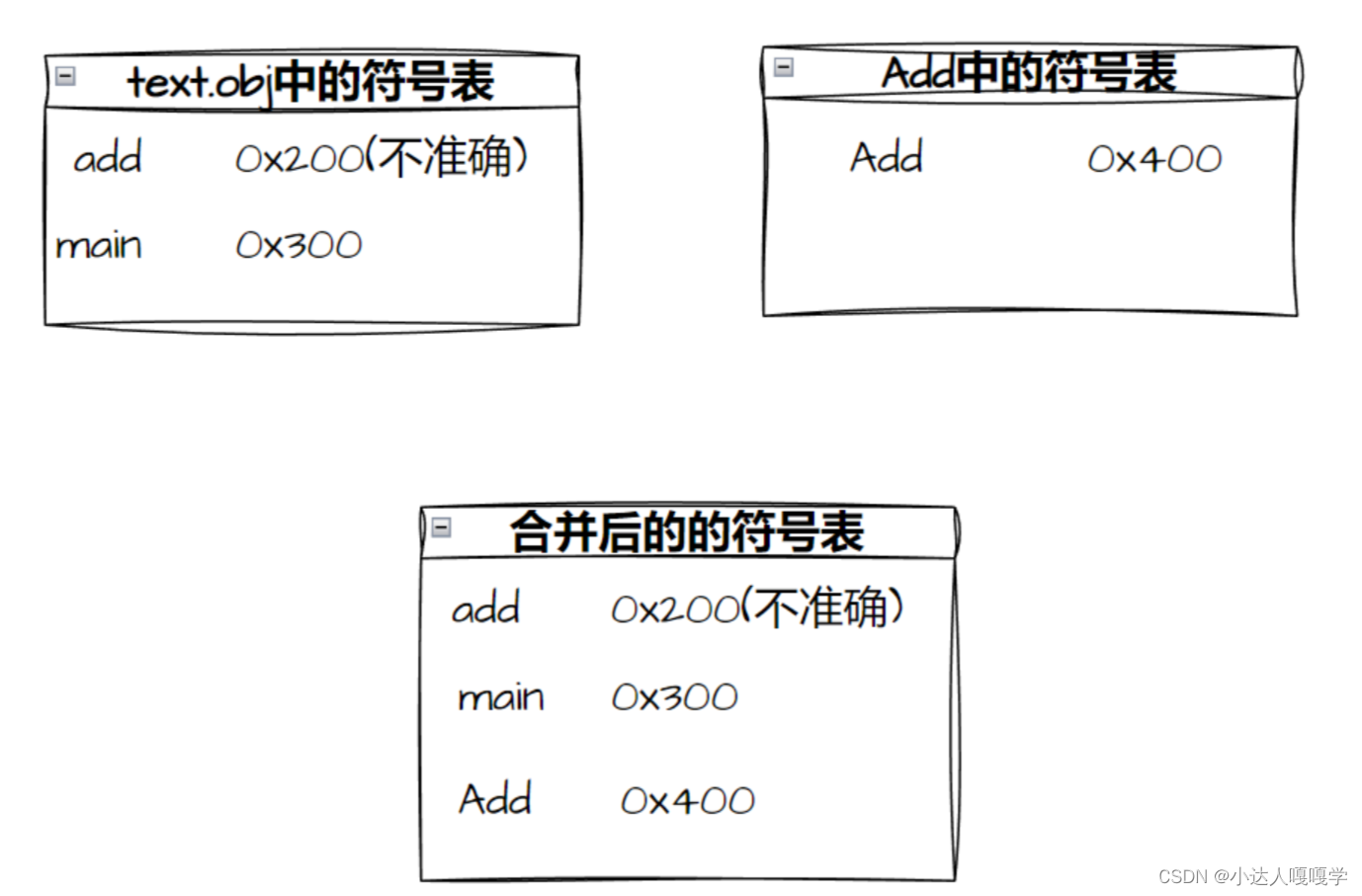
text.obj中的符号表记录了一条add和地址的对应关系,最终会汇总到总的符号表当中,当然这个对应关系是不存在的,因为我们压根就没对add进行任何定义,最终到这个“虚假”的地址里面当然就什么都找不到,自然就报了“链接错误”
3. 运⾏环境
- 程序必须载⼊内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独⽴的环境中,程序的载⼊必须由⼿⼯安排,也可能是通过可执⾏代码置⼊只读内存来完成。
- 程序的执⾏便开始。接着便调⽤main函数。
- 开始执⾏程序代码。这个时候程序将使⽤⼀个运⾏时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使⽤静态(static)内存,存储于静态内存中的变量在程序的整个执⾏过程⼀直保留他们的值。
- 终⽌程序。正常终⽌main函数;也有可能是意外终⽌
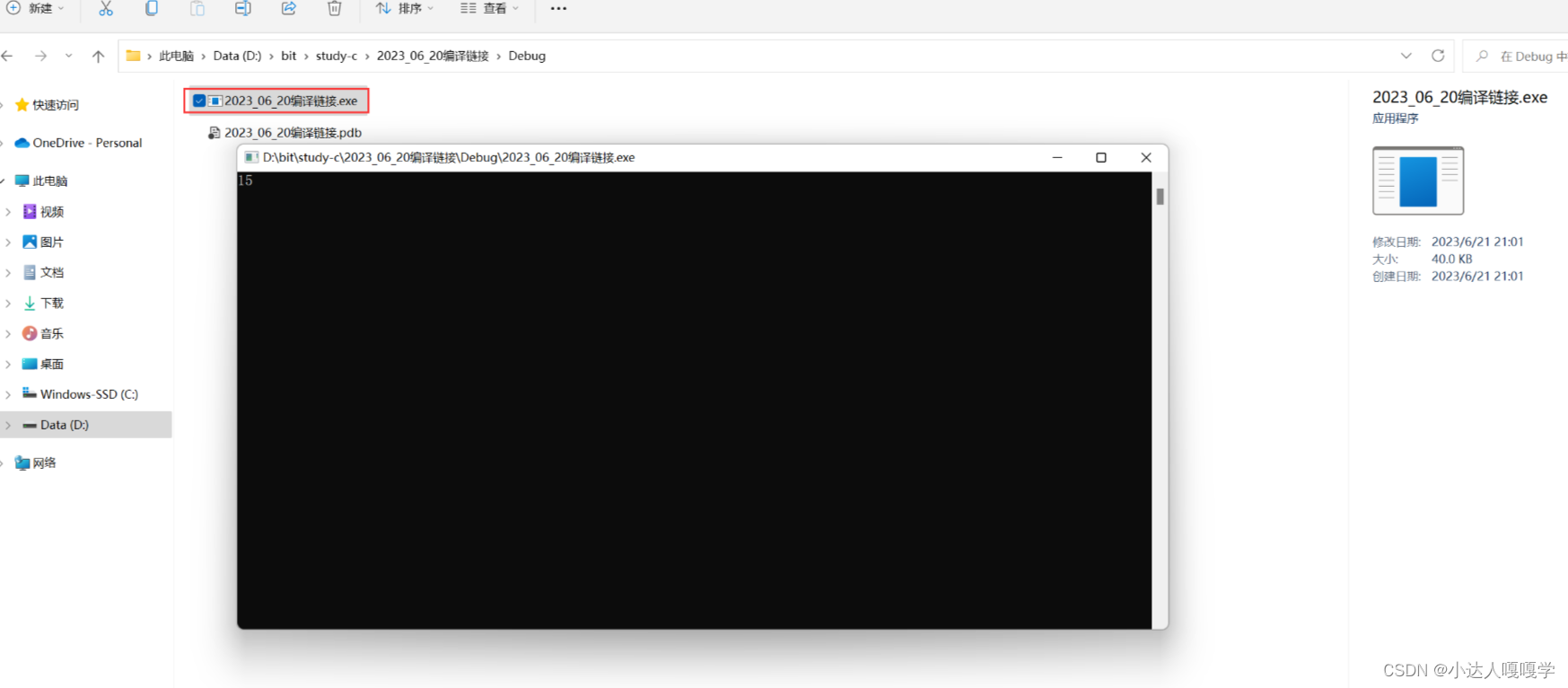
如上图,我们双击以.exe结尾的可执行文件就会进入到执行环境,此时程序已经被加载到内存中。
4.总结
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









